UC Berkeley | 只用单目RGB视频,就能搞定机器人灵巧动作?

从“互联网视频”到“真实灵巧手执行”的端到端数据生成管道
——只用单目 RGB 搞定 4D 手物追踪
目录
路线2:单目轻量几何映射方案(DexImit、VideoManip)
上图来自于伯克利团队发布的Do as I Do完整转换框架。
仅依靠普通单目人类RGB视频,无需深度、动捕、专用传感设备,就能重建完整手物交互三维运动,并映射至多自由度灵巧机械臂,输出可直接真机运行的操控数据。
01 赛道横向分层:三类视频转动作方案真实定位
截至2026年,从人类视频生成机器人灵巧数据的技术路线可清晰分为三类,Do as I Do属于通用单目无附加硬件赛道,差异化优势与短板一目了然。

▲野生互联网视频物体跟踪人工偏好对比(本文 vs FoundationPose)
路线1:依赖专用传感输入方案(H2Sim2Robot)
需要激光雷达、深度相机配套采集视频,重建精度高,但数据采集门槛极高,无法利用现成网络素材,仅适合实验室定点数据生产,规模化拓展能力基本为零,工程落地价值有限。
路线2:单目轻量几何映射方案(DexImit、VideoManip)
仅依靠基础3D模型做手部关键点检测,直接坐标平移映射机器人,无动力学校验,优点推理速度快;但遮挡、快速动作下重建误差会被放大,真机执行时频繁出现碰撞、抓空,野生互联网视频鲁棒性极差,仅适合干净无遮挡短片段。
路线3:Do as I Do 重建+动力学双层统一框架
全程仅单目RGB输入,兼容自拍、网络剪辑、生成视频多类素材:
- 第一层引导式扩散跟踪稳定时序手物三维轨迹;
- 第二层带预热、扰动采样的物理优化做跨具身重定向,加入接触约束规避穿模、打滑。

▲重建 - 重定向 - 真机部署端到端完整管线
定量层面:在150段野生互联网视频人工评测中,67%片段本方法重建效果优于最强基线FoundationPose;标准DexYCB、HOI4D数据集F-10指标领先同类方法。

▲Do as I Do 整体流程总览,单目视频到灵巧机器人动作全链路
但对比工业级遥操作数据,该框架生成轨迹仍存在抓取力度、微小滑移控制缺陷,更适合做预训练扩充素材,无法替代高精度遥操作核心数据集。
02 Do as I Do 双阶段完整技术流水线
过往算法相当于“看图复刻人手坐标”,只看外表不考虑机器人能不能抓;
Do as I Do是先看懂人和物体的三维互动逻辑(手物三维重建),再结合机械手物理限制重新规划一套合规动作(动力学感知动作重定向)。
第一阶段:引导式扩散时序重建模块
传统SAM3D单帧建模每一帧独立生成物体网格,前后帧姿态不连贯,运动模糊、手部遮挡时轨迹剧烈漂移。
因此研究改进了跟踪逻辑,固定单帧提取的物体标准网格,仅用扩散模型迭代更新每帧6自由度位姿,同时引入2D点跟踪自适应调整引导强度αₚ,物体转动幅度越大,时序约束权重越高,抑制跳变。
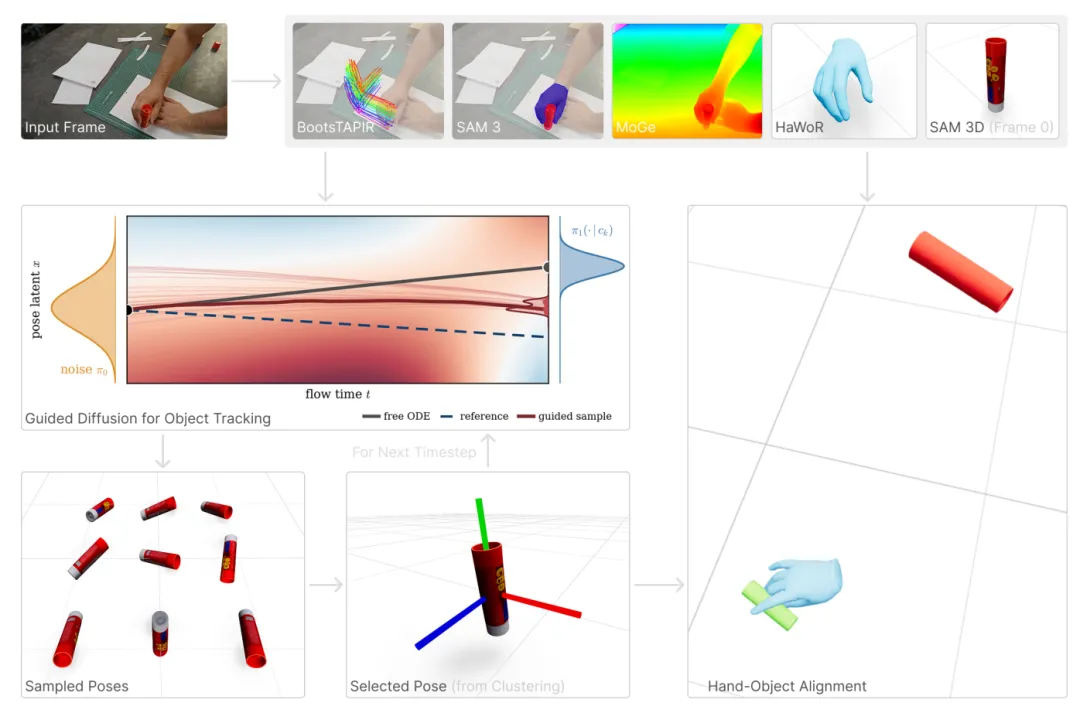
▲引导式扩散时序重建完整模块流程图
为降低推理开销,不使用高代价似然打分筛选多组位姿样本,改用加权SE(3)距离聚类筛选最优轨迹,速度提升30倍且精度几乎无损;
重建完成后通过深度点云对齐人手与物体尺度,消除单目尺度歧义,输出全局统一度量空间的4D手物交互序列。
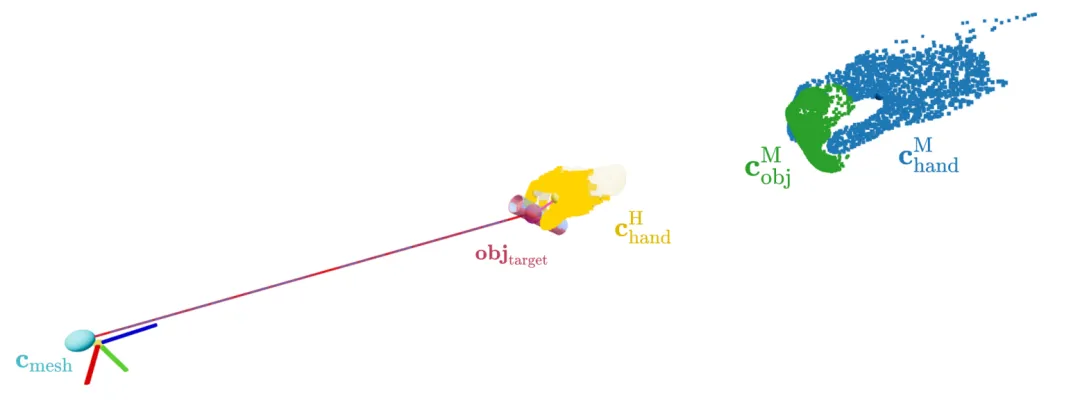
▲手物三维尺度匹配几何计算示意图
仅单目输入就能处理 ego/外视两类视频,把原本只能用深度设备完成的时序重建放到普通RGB素材上,大幅拓宽数据源范围。
第二阶段:带鲁棒优化的物理重定向
单纯坐标映射忽略机器人关节极限、碰撞、接触力,为此框架基于MuJoCo Warp仿真搭建采样优化管线,三大创新点解决轨迹真机不可行问题。

▲重定向三大创新效果图
优化初始阶段增加空握预热区间,允许机械手先调整姿态再执行抓取,规避视频初始位置偏差导致直接抓空;
随机力扰动采样:轨迹采样时叠加外力、力矩噪声,优化出抗轻微干扰的稳定抓取姿态,减少真机滑移;
过渡惩罚损失:区分物体悬空/放置两种状态,手无接触时增加损失项,强制算法学习贴合抓取动作。
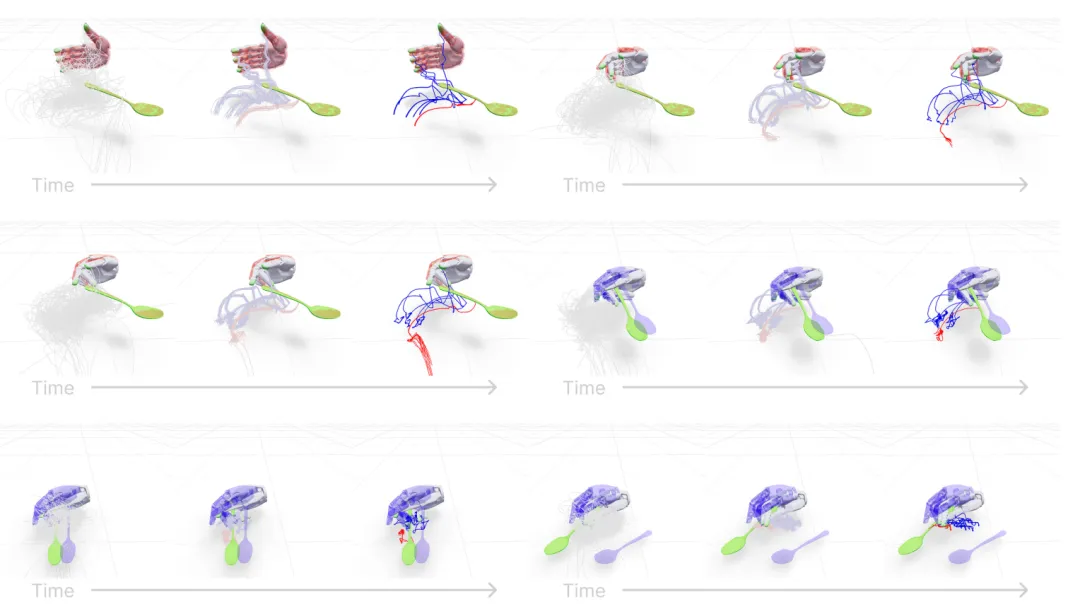
▲仿真采样优化轨迹可视化(机器人指尖 / 物体收敛轨迹)
整体采用MPPI采样优化器,每规划窗口评估1024条候选轨迹,兼顾跟踪精度与物理可行性,最终输出双臂UR3e搭配Sharpa灵巧手完整关节动作序列,可直接下发真机执行。
配套数据产出与实践指南
研究基于2000段100DOH互联网视频做统计分析,给出行业通用视频筛选实操手册:
仅有约4%网络视频可产出高质量可用机器人轨迹,绝大多数片段存在物体出框、无有效交互、镜头频繁切换等问题。
框架输出产物包含同步RGB、机械手关节轨迹、物体6D姿态、语言描述标签,格式兼容主流VLA灵巧手模型(EgoScale、T-Rex等),可直接作为中期微调扩充数据,降低真机遥操作采集量。

▲10 类真实机器人落地操作实拍序列
03 行业价值与天然落地局限
现有落地价值
首次实现纯单目通用视频全自动转化灵巧操作轨迹,不用动捕、深度、VR设备,互联网海量日常视频具备机器人训练复用价值;
低成本预训练素材供给:适合高校、初创团队缺少昂贵遥操作设备的研发场景,用网络视频先做大模型基础视觉动作先验,减少真机采集成本;
标准化可复用管线:重建、重定向模块解耦,可单独嵌入现有VLA数据处理流程,兼容主流双臂灵巧手硬件。
框架固有短板
物体材质限制:整套重建与仿真流程仅适配刚性物体,布料、软管、硅胶等可形变物品无法精准建模,柔性操作场景完全失效;
感知依赖局限:仅依靠视觉做交互推理,无触觉信息,生成轨迹缺少力度区分,捏鸡蛋、挤牙膏这类力控精细任务表现较差;
环境简化:重建只建模手与目标物体,忽略桌面杂物、墙体等周边障碍物,真机运行易发生碰撞;
仿真与现实鸿沟:优化仅在仿真内完成,真实机器人传感器噪声、关节间隙未纳入优化,仿真最优轨迹落地仍需要微调。
04 只用单目 RGB 搞定 4D 手物追踪
Do as I Do跳出“必须专用设备采集机器人数据”的固有思维,用「时序稳定单目重建+动力学感知跨具身重定向」两步式管线,把海量闲置人类RGB视频转化为可真机运行的灵巧操作数据,为具身智能低成本数据扩张提供可行方案。
但同时需要注意的是该框架是数据预处理工具,而非完整机器人操作策略,刚性物体、无遮挡简单场景优势突出,柔性、多障碍、高精度力控任务仍存在明显短板。
未来或结合触觉感知、全局场景重建,能进一步缩小视频演示与机器人实操的能力差距。
Ref
论文标题:Do as I Do: Dexterous Manipulation Data from Everyday Human Videos
论文地址:https://arxiv.org/pdf/2606.19333
项目主页:https://do-as-i-do.com

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献154条内容
已为社区贡献154条内容

所有评论(0)