让VLA暂时“看不见”,为什么反而能学得更好?上交×阿里团队给出全新解法
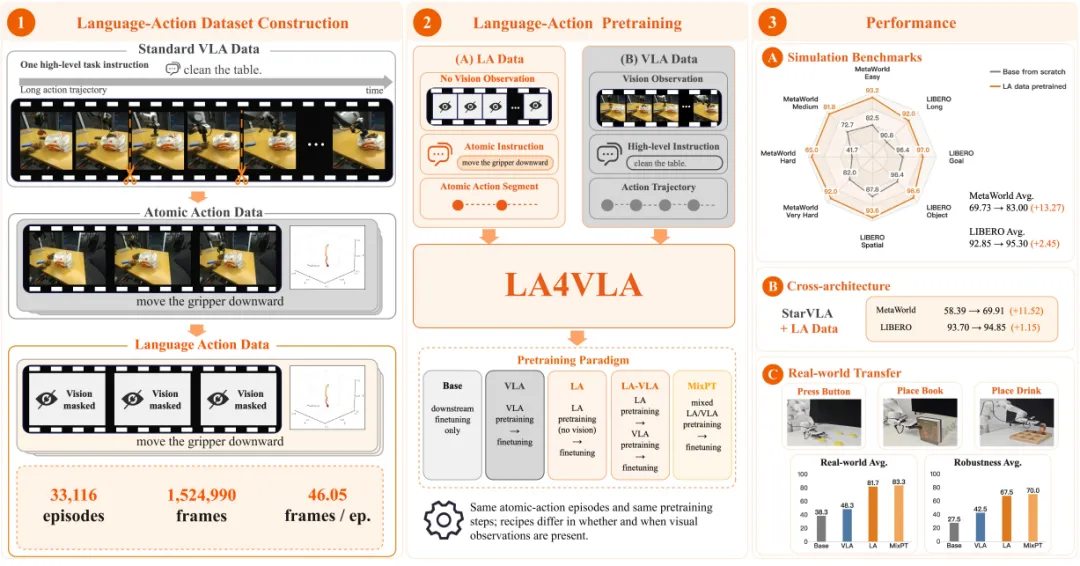
先让模型在没有视觉输入的情况下学习语言-动作关系,再把这种能力带回标准 VLA 训练和下游机器人操作中。
——暂时不看,是为了之后更好地看
目录
在机器人学习里,视觉几乎总是第一主角。
VLA 模型之所以受到关注,正是因为它可以把图像、语言和动作放到同一个模型中:看见当前场景,理解人类指令,然后输出机器人下一步应该执行的动作。
但问题也随之出现:
当一个模型在图像条件下完成了任务,我们能确定它是真的理解了语言指令吗?还是说,它只是从视觉输入中找到了更直接的动作线索?
近日上海交通大学、阿里巴巴等团队提出的 LA4VLA 关注的正是这个问题。
我们不是要让机器人最终不看世界,也不是要削弱视觉在机器人操作中的作用;相反,我们希望在视觉介入之前,先把“语言如何约束动作”这件事单独拎出来学习清楚。
重点关注三个问题
“
标准 VLA 训练中语言监督为什么可能被淹没?
LA4VLA 如何把 Language-Action Pretraining 从 VLA Pretraining 中解耦出来?
以及这种“先不看图”的训练方式,为什么能够提升仿真、真实机器人和视觉扰动下的表现?
01 为什么要重新审视 VLA 里的语言-动作学习?
典型的 VLA 预训练数据来自机器人示范。一条示范轨迹通常包含连续的视觉观测、机器人状态和动作序列,同时配有一条自然语言任务指令。
训练目标很直接:给定当前视觉输入和语言目标,预测对应的动作。
这种联合训练范式非常自然,也已经成为当前 VLA 模型的重要路线。不过,从监督信号的角度看,视觉、语言和动作并不是以同样的密度出现的。
在数据层面,视觉和动作是逐帧变化的;一条轨迹中可以产生大量 visual-action 或 state-action 对。
相比之下,语言往往只有一句高层任务描述,并且在整条轨迹中保持不变。
比如同样一句 “clean the table”,实际执行时可能包含靠近、抓取、抬起、移动和放置等多个局部动作阶段,但这些局部阶段和语言之间并没有被显式对齐。
在输入层面,不平衡也同样存在。图像通常会被编码成大量 visual tokens,而语言指令只占输入中的一小部分。
模型在训练中很容易优先利用图像中更密集、更直接的动作预测线索,而不是充分学习语言指令本身如何约束动作。
这意味着,一个 VLA 策略在标准输入下看起来可以响应语言指令,并不一定说明它已经建立了稳固的语言-动作关系。
一旦视觉输入被移除、替换,或者视觉线索和语言目标发生冲突,模型的动作预测就可能不再稳定地跟随语言。
LA4VLA 想强调的不是“视觉不重要”,而是:如果语言-动作监督始终被包在视觉主导的训练流程中,它很可能没有被充分学习。
02 诊断实验:当语言和视觉不一致,模型会跟谁走?
为了更直接地观察这个问题,我们设计了一个 instruction-conditioned direction following 诊断实验。
实验并不改变语言指令,而是只改变视觉输入,观察模型预测出的动作轨迹是否仍然沿着指令方向运动。
具体来说,我们选取方向明确的原子动作指令,例如“move upward to approach the target” 和 “move downward to approach the target”,并构造四种视觉输入设置:原始配对视觉、移除视觉、同场景不匹配视觉,以及来自相反方向动作片段的冲突视觉。
结果非常直观,在原始配对输入下,模型看起来表现不错:相反方向的指令能够产生分开的轨迹,端点也大致位于对应方向。
但当视觉输入被拿掉或替换后,方向区分迅速变弱,轨迹也变得混乱。
更关键的是视觉冲突设置。此时语言仍然要求模型朝某个方向运动,但视觉输入来自相反方向的动作片段。模型的预测并不是简单变得随机,而是明显偏向视觉所暗示的方向。
换句话说,当语言和视觉发生冲突时,标准 VLA 策略更容易“跟着视觉走”。
量化指标也与这一现象一致:
标准配对输入下看似良好的 direction following,在移除、替换或冲突视觉后显著下降;
在冲突设置中,模型甚至出现了明显的反向偏移。
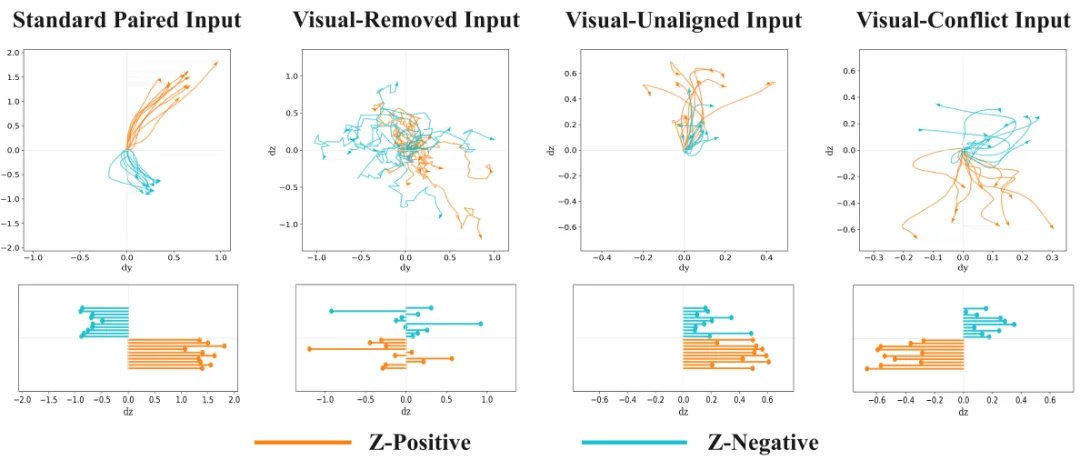
这个诊断实验直接引出了 LA4VLA 的动机:
与其始终让语言-动作监督和视觉观测绑定在一起,不如先把它单独暴露出来,让模型专门学习“语言如何对应动作”。
03 LA4VLA:先学语言如何约束动作,再回到视觉场景
基于上面的观察,LA4VLA 提出一种新的预训练视角:
将 Language-Action Pretraining 从标准 VLA Pretraining 中解耦出来。
在标准 VLA pretraining 中,模型同时接收视觉观测、语言指令和机器人状态,并预测动作,视觉 grounding 和动作学习从训练一开始就被绑定在一起。
这样可以学习视觉条件下的策略,但也可能让语言-动作关系被更密集的视觉-动作信号覆盖。
LA4VLA 则把其中的 Language-Action 部分单独拿出来。
在 LA pretraining 阶段,视觉输入被移除,模型只能根据语言指令和机器人状态预测连续动作轨迹。也就是说,模型暂时不能依赖图像中的目标位置、物体外观或场景布局,而必须关注语言本身对应怎样的动作模式。
这里的语言-动作监督并不是简单的动作类别标签。
我们不是只告诉模型某个片段属于 “lift” 或 “grasp”,而是让模型学习更完整的局部动作描述和连续动作轨迹之间的关系。例如:
“Lower the object downward toward the target while holding it” 对应持物状态下向目标方向下放;
“Transport the object to the right while holding it” 对应持物状态下向右移动;
“Open gripper to release and place the object onto the target surface” 对应释放并放置物体。
这些指令包含动作方向、夹爪状态、是否持物以及局部物理效果,但尽量避免绑定到某个具体物体外观、背景布局或场景目标。
因此,模型学到的不是某一张图中的操作,而是一类可跨任务、跨场景复用的语言-动作规律。
从这个角度看,LA4VLA 不是简单往 VLA 预训练里加数据,而是在重新定义一个可以单独使用、也可以和标准 VLA 训练互补的预训练信号。
04 LA-33K:把长轨迹拆成局部语言-动作片段
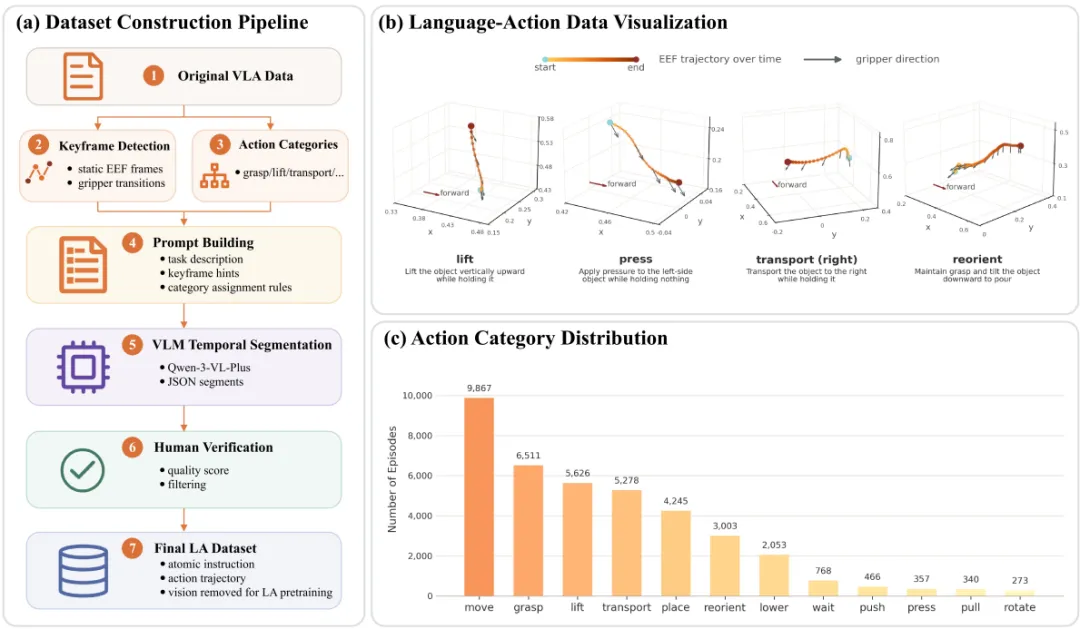
要进行独立的 LA pretraining,首先需要构造不依赖视觉输入的 Language-Action 数据。LA4VLA 并没有额外采集机器人示范,而是对已有 VLA demonstrations 进行重新组织。
一条完整的 VLA 轨迹通常只有一条高层任务指令,但轨迹内部实际上包含多个短时、局部的动作阶段。
我们将这些长轨迹切分为 atomic action segments,并为每个片段生成对应的低层动作描述。
这样,原本隐藏在完整示范中的 language-action supervision 就被显式提取出来。
构建流程包括关键帧检测、原子动作类别约束、VLM temporal segmentation 和人工核验。
最终得到的 LA episodes 覆盖 move、grasp、lift、transport、place、reorient、lower 等常见原子操作类别。
最终构建出的 LA-33K 包含 33,116 条经过人工核验的 Language-Action episodes,共 1,524,990 帧,平均每条 episode 为 46.05 帧。
相比原始 VLA 轨迹,这些片段更短、更局部,语言描述也更直接对齐到实际动作。
因此,LA-33K 的意义并不只是提供一个新数据集。更重要的是,它把原本被包裹在 VLA demonstrations 中的语言-动作监督变成了可以单独训练、单独分析、并与 VLA pretraining 组合使用的监督信号。
05 实验结果:不看图的预训练,能带来什么?
我们在 MetaWorld、LIBERO、跨架构设置和真实机器人任务上验证 LA4VLA。
整体结果可以从三个角度理解。
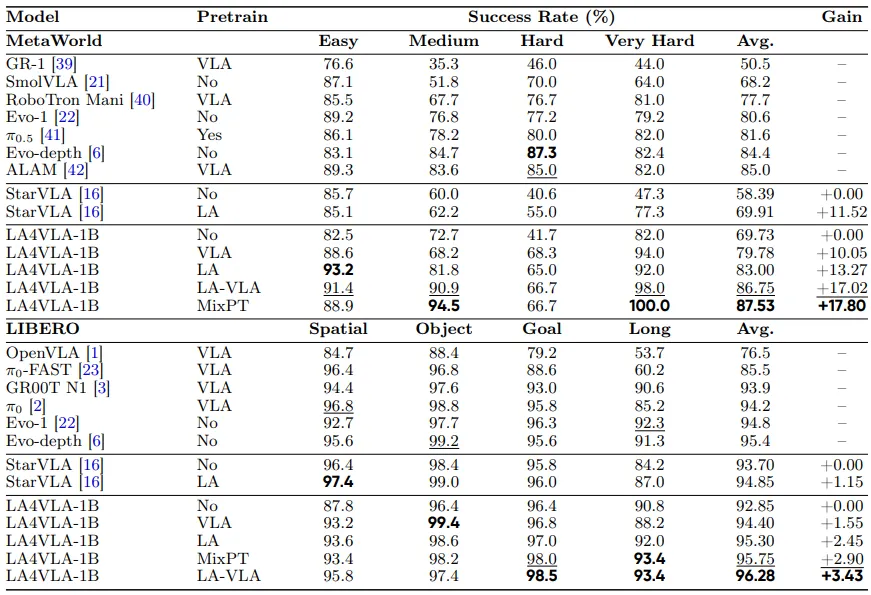
- 第一,单独 LA pretraining 已经是有效的。
在 LA4VLA-1B 上,MetaWorld 平均成功率从 69.73% 提升到 83.00%,提升 13.27 个百分点;
LIBERO 从 92.85% 提升到 95.30%,提升 2.45 个百分点。
这种收益并不只出现在一个模型上。
将同样的 LA pretraining protocol 应用于 StarVLA,也能带来提升:MetaWorld 从 58.39% 提升到 69.91%,LIBERO 从 93.70% 提升到 94.85%。
在真实机器人上,效果更加明显。
三个真实任务包括 Press Button、Place Book 和 Place Drink,平均成功率从 38.3% 提升到 81.7%。
这说明,即使预训练阶段没有视觉输入,模型学到的语言-动作规律仍然可以迁移到真实的视觉条件操作中。
- 第二,LA pretraining 优于 matched VLA pretraining。
在相同原子动作片段上,如果保留视觉输入做 VLA pretraining,MetaWorld 为 79.78%,LIBERO 为 94.40%;
而移除视觉输入做 LA pretraining 后,分别达到 83.00% 和 95.30%。这说明收益不是来自数据片段本身,而是来自更集中的语言-动作监督形式。
- 第三,LA 和 VLA supervision 可以互补。
在 MetaWorld 上,No pretrain 为 69.73%,LA 为 83.00%,LA-VLA 为 86.75%,MixPT 达到 87.53%;
在 LIBERO 上,No pretrain 为 92.85%,LA 为 95.30%,MixPT 为 95.75%,LA-VLA 达到 96.28%。
在视觉扰动下,平均成功率也从 No pretrain 的 27.5% 提升到 LA 的 67.5%,MixPT 进一步达到 70.0%。
这表明,先学习不依赖具体图像的语言-动作规律,再结合视觉 grounding,有助于提升策略在视觉变化下的稳定性。
一句话总结:Language-Action Pretraining 是一种独立有效的预训练信号;它可以单独带来提升,也可以和标准 VLA pretraining 形成互补。
06 模型内部发生了什么变化?
除了最终成功率,我们还进一步分析了 LA pretraining 对模型行为和内部表示的影响。
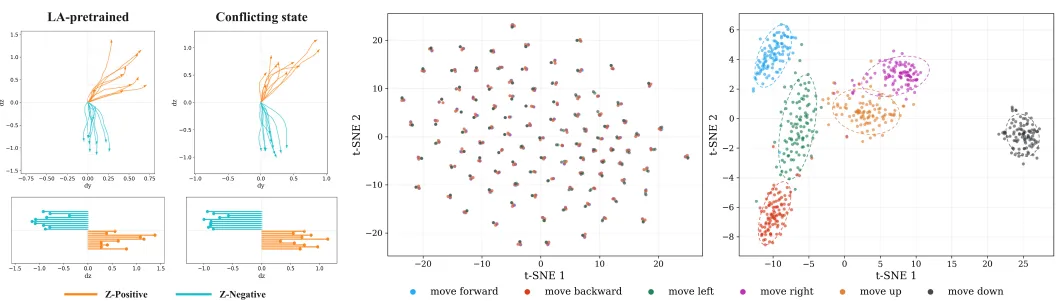
方向跟随结果显示,经过 LA pretraining 后,即使没有视觉输入,模型仍能根据语言指令预测出清晰分开的相反方向轨迹。动作方向不再容易被其他输入带偏,而是更稳定地跟随语言。
t-SNE 可视化也给出了类似信号。标准 VLA-trained policy 的内部表示中,不同方向指令往往混在一起;而 LA-pretrained policy 的表示会按照指令方向形成更清晰的聚类,相反方向也被分到不同区域。
这说明 LA pretraining 不只是提升了下游成功率,也让模型在动作预测前形成了更清晰的 instruction-conditioned representation。
换句话说,模型内部确实更好地学习到了语言和动作之间的对应关系。
07 核心贡献
总结来看,LA4VLA 的重点不是提出一个新的模型名称,也不只是构建一个新数据集,而是把 VLA 学习中的一个关键问题单独提出:
Language-Action Pretraining 能否从标准 VLA Pretraining 中解耦,并作为独立、有效、可互补的预训练范式?
- 提出 LA4VLA:一种 vision-agnostic language-action pretraining framework。它通过移除视觉输入,让模型在预训练阶段显式学习语言如何约束动作执行。
- 构建 LA-33K 数据集:包含 33,116 条经过人工核验的 Language-Action episodes,不需要额外采集机器人数据,而是从已有 VLA demonstrations 中提取原本隐含的语言-动作监督。
- 系统研究 LA supervision 的多种使用方式:包括 LA-only、sequential LA-to-VLA 和 mixed LA-VLA pretraining,验证其既可以单独使用,也可以与标准 VLA pretraining 互补。
- 在 MetaWorld、LIBERO、StarVLA 跨架构实验、真实机器人任务、视觉扰动鲁棒性实验,以及方向跟随和表示分析中验证方法有效性。
08 暂时不看,是为了之后更好地看
VLA 模型最终当然需要视觉。
机器人要在真实世界中完成任务,必须理解场景、物体、目标位置和环境变化。
LA4VLA 并不是要把视觉从机器人学习中拿走,而是希望在视觉进入模型之前,先让语言-动作关系得到更充分的学习。
如果训练一开始就把视觉、语言和动作完全耦合在一起,语言-动作监督可能会被更密集的视觉-动作信号淹没。
模型看起来能够执行语言指令,但在视觉变化或视觉冲突下,仍可能更倾向于跟随视觉。
LA4VLA 提供的思路是:先把 Language-Action Pretraining 从 VLA Pretraining 中解耦出来,让模型在没有视觉输入的情况下学习语言如何约束动作;再将这种语言-动作规律与视觉 grounding 结合起来,用于下游 VLA 策略学习。
Learning to Act without Seeing,最终是为了更好地 Seeing and Acting with Language。
论文标题:LA4VLA: Learning to Act without Seeing via Language-Action Pretraining
论文作者:Tao Lin, Yuxin Du, Yiran Mao, Zewei Ye, Yilei Zhong, Bing Cheng, Yiming Wang, Jiting Liu, Yang Tian, Junchi Yan, Feiran Wu, Zenan Meng, Hu Wei, Yuqian Fu, Gen Li, Bo Zhao
论文地址:https://arxiv.org/pdf/2606.27295

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 2
2 0
0- 0



 已为社区贡献152条内容
已为社区贡献152条内容

所有评论(0)