FATE:面向物理落地机器人课程学习具备主动修复功能且考虑可行性-觉察的闭环任务生成方法
26年3月来自清华和BIGAI的论文“FATE: Closed-Loop Feasibility-Aware Task Generation with Active Repair for Physically Grounded Robotic Curricula”。
近期,生成式仿真领域利用大语言模型(LLM)生成多样化的机器人任务课程;然而,这些开环范式往往产生语言上连贯但在物理上不可行的目标,其根源在于任务规范缺乏物理基础或目标设定不当。为解决这一关键局限,提出 FATE(Feasibility-Aware Task gEneration,即“可行性-觉察任务生成”),这是一个闭环、自校正的框架,将任务生成重新构想为一个迭代式的验证与优化过程。与将生成和验证步骤割裂开来的传统方法不同,FATE 将一个通用具身智体直接嵌入生成循环中,从而主动确保所生成课程的物理可行性。FATE 实施一套循序渐进的审核流程:首先验证静态场景属性(如物体affordance、布局兼容性),随后通过模拟具身交互来验证执行的可行性。该框架性能的关键在于,一旦检测到不可行任务,FATE 便会启动主动修复模块,自主调整场景配置或策略规范,将原本无法执行的方案转化为物理上可行的任务实例。大量实验证明,FATE 不仅能生成语义多样且具备物理可行性的任务课程,还能显著降低执行失败率,优于当前最先进的生成式基准方法。
具身人工智能(Embodied AI)的研究范式正从静态环境转向开放式、程序化生成的世界(Wang et al., 2023a;b)。基于大语言模型(LLM)的开环生成器虽能产生多样化的任务提案,但其中许多因静态层面的不一致性(如指令与场景不匹配、违反物体affordance或前提条件不满足)而无法实现。即便初始设定合理,任务仍可能在执行阶段因机器人可达性限制、接触不稳定或规划/学习失效而失败。因此,不受约束的开环机制往往会产生无效数据并浪费计算资源。
基于上述观察,必须将任务设定的合理性(即任务设置与现实世界常识的一致性)和任务目标的可执行性(即通过机器人交互实现目标的可行性)充分纳入闭环任务生成流程中。这种整合确保了生成的任务不仅保持语言连贯性,还能符合物理现实(即实现物理落地),从而克服了开环生成方式的根本局限。
为应对这一挑战,提出将可行性视为一个涵盖静态感知与动态执行的分层约束满足问题。具体而言,视觉上的合理性并不等同于可解性;一个连贯的场景可能因目标不可达或隐蔽的碰撞问题而导致失败。因此,针对图1所示的两种不同失效模式进行处理:静态幻觉(几何或语义层面的违规)与动态偏差(执行过程中的运动学或交互失败)。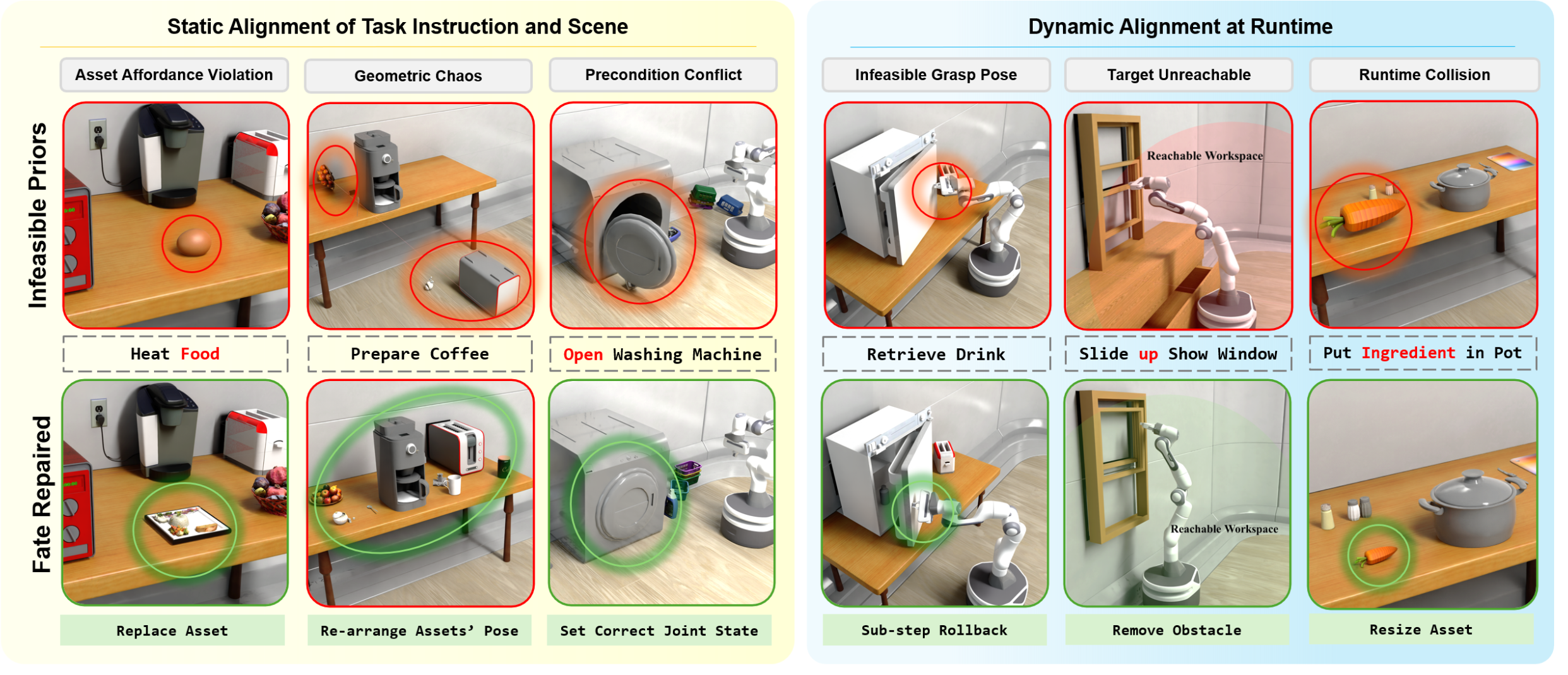
本文提出 FATE(一种考虑可行性的任务生成框架),该框架采用“人在环”机制,通过解耦策略实现分层级的可行性对齐:首先将任务提案投影到静态有效的流形上,随后利用执行过程中的反馈对任务进行精细化调整。具体而言,静态对齐算子首先修正感知层面的冲突(如物体间的相互穿透);随后,动态对齐审计模块监控执行过程,并迭代调整求解器参数以解决运行时故障。这一过程将任务生成从随机采样转变为闭环的课程学习模式。
1. 考虑可行性的任务
机器人任务不仅仅是语义指令,而是一个由语言意图、物理环境和受限解空间构成的耦合系统。
2. 可行策略与任务可行性
具身任务中的有效性并非非黑即白,而是基于测度论的。只有当解空间在智体的探索能力范围内具有非零测度(即占据非微不足道的体积)时,该任务才具有实际可行性。
3. 问题陈述:考虑可行性的任务生成
将生成过程建模为从任务空间上的任务分布 P_G(由任务生成器 G 产生)进行采样。核心挑战在于,高多样性生成器 P_G 的支撑集(由未经核实的任务提案构成)通常会大幅超出满足 μ(τ) > δ_min 的物理可行区域。
FATE 的目标在于:不仅仅是从 PG_ 中进行采样,而是构建一种精细化机制,在弥合这一差距的同时,既不丧失生成的多样性,也不偏离用户的意图。
形式上,寻求一个将任务假设投影到可行域的映射 A : τ → τ。最优算子是一个约束最小化问题的解。
如图 2所示分层可行性对齐过程的可视化。优化轨迹在联合任务空间 τ = (I, S, Π) 中演变。(左)静态对齐 (A_perc):Ante-Auditor 通过离散修复操作(如 RESCALE)修正场景 (S) 与指令 (I) 之间的不兼容性,将初始状态 τ_init 投影到感知有效的流形上。(右)动态对齐 A_exec):针对策略 (Π),系统利用语义反馈和动态 API(如 INJECT REWARD)优化求解器配置,引导任务从失败状态(红色轨迹)进入可行空间(绿色多面体)。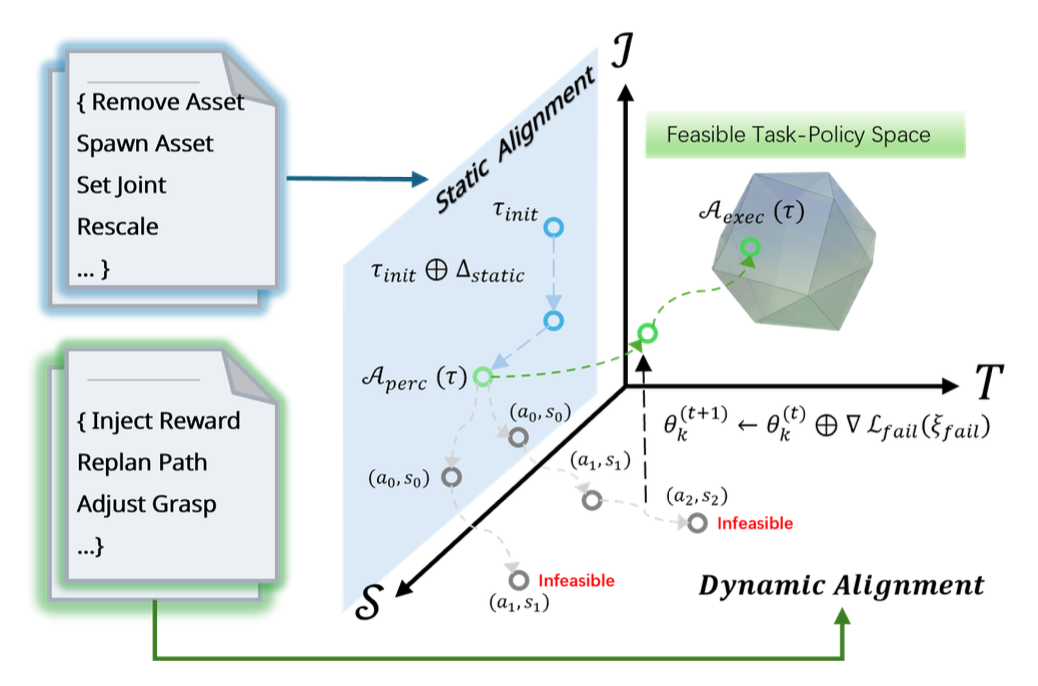
1. 可行性对齐算子
为了弥合可行性差距,正式构一个映射 A : T → T,称为“可行性对齐算子”。与随机重采样不同,该算子作为一种构造性流形投影发挥作用,将一个未落地的假设 τ ∼ P_G 转换为物理上有效的实例 τ∗,同时最小化语义偏差。
鉴于物理约束具有层次性,将 A 在结构上分解为感知子算子(A_perc)与执行子算子(A_exec)的顺序组合。这种分解确保了任务首先被映射到几何有效子空间,随后被投影至动态交集之上。
将对齐算子 A 表述为一种“构造性残差注入”(Constructive Residual Injection)。目标并非进行随机重采样,而是合成一个任务残差 ∆τ,将当前任务 τ 投影到由任务可行性测度 μ(τ) 所定义的可行域内。
形式化地,在每次迭代中,该算子寻求一个最优更新 ∆τ*,以最大化可行性似然。
由于计算精确的 μ(τ) 难以实现,利用各阶段特定的替代指标来具体化这一目标:在第一阶段最大化静态有效性评分 μˆ_static,并在第二阶段最小化执行失败率。
2. 基于执行原语的策略规范
为了实例化受限策略流形 Ω_π,FATE 将全局指令 I 分解为一系列原子原语 Π = {π_1, . . . , π_K }。采用混合求解器策略,以应对导航和操作阶段截然不同的拓扑需求:
几何-觉察导航(MPC)。对于非接触阶段(例如,移动至目标位置),利用模型预测控制(MPC)。该求解器优化轨迹以最小化与子目标的距离,同时严格遵守基于场景 S 导出的碰撞约束。该求解器公开决定运动保守性的几何参数(例如,障碍物膨胀半径)。
高-接触操作(RL)。对于交互阶段(例如,抓取或开启),采用Soft AC(SAC)算法。为了促进稀疏奖励环境下的学习,多模态大语言模型(MLLM)合成一个由权重 θ_rew 参数化的基于势能成形函数(potential-based shaping function)。这使得系统能够通过塑造优化形(optimization landscape),引导智体向语义关键点移动。
审计器接口。至关重要的是,这些原语并非静态的黑盒,而是参数化模块 π(· | θ)。它们提供一个可调节的配置空间(包括 MPC 约束和 RL 奖励权重),作为动态对齐算子(A_exec)的控制接口。这种设计使审计器能够通过主动调整求解器逻辑来解决执行失败问题——实际上是执行语义策略梯度更新——而不仅仅是重新采样任务。
3. 阶段 I:基于感知投影的静态对齐
第一阶段(记为 A_perc)充当感知层面的“把关者”,将初始任务假设投影到感知有效的区域内。静态一致性——即语义指令 I 与场景配置 S 之间的对齐——是实现动态可执行性的必要条件。
审计:检测“幻觉”。为了在无需进行高昂仿真成本的情况下估算可行性度量 μ(τ),Ante-Auditor 采用静态可行性检查 μˆ_static。该检查充当逻辑过滤器,用于验证四项一致性条件:(i) 可达性;(ii) 交互affordance匹配;(iii) 物理合理性;以及 (iv) 形态兼容性。若未能满足其中任何一项条件,即意味着该任务在根本上无法实现(μ(τ) ≈ 0),从而立即触发修复流程。
修复:场景投影。在检测到违规时,操作员合成一个静态残差 ∆τ_static,以修正场景或指令。将最优静态修复定义为使感知有效性代理(proxy)指标 μˆ_static 最大化的修复。在实际操作中,∆τ_static 由两部分组成:场景重构(例如,对资产 M_j 进行重缩放 M_j → M’_j 或移动不可触及的物体)和指令细化(例如,放宽过于具体的动词限制)。通过求解该静态修复,A_perc 确保该提议在仿真前具备物理上的可行性。
4. 阶段 II:基于语义策略梯度的动态对齐
尽管静态对齐能保证几何上的有效性,但它无法预见由复杂的接触动力学或控制器不稳定性引发的失效。第二阶段(即执行对齐阶段 A_exec)通过确保策略规范 Π 的收敛,在运行时解决“可行性缺口”(Feasibility Gap)问题。
审计:监控偏差。步进式审计器(In-step Auditor)负责监控基元序列 {π_k} 的执行情况。若智体未能在预定时间跨度内实现预期的状态变化,或者求解器(MPC/RL)未能找到有效解,该任务即被标记为“动态偏差”(Dynamic Divergence)。常见的失效模式包括:高扭矩抓取失败、碰撞导致的死锁、稀疏奖励下的停滞,以及仅在物理交互过程中显现的潜在几何不兼容问题(例如极小的装配公差)。
修复:执行精化。动态失效表明,针对当前场景,策略规范 Ω_π 的设定不当。为解决这一问题,FATE 触发回滚(rollback)操作,并根据失效轨迹 ξ_fail 合成动态残差 ∆τ_dynamic。该更新充当一种语义策略梯度(Semantic Policy Gradient),其中“审计器”(Auditor)既可以修改物理场景(例如,通过缩放物体来调整几何形态,从而降低插入难度),也可以调整求解器逻辑(例如,通过引入稠密奖励塑造项来进行逻辑微调)。通过这些迭代更新,FATE 将发散的轨迹拉回至可行域 Φ_τ 内。
如下是FATE的算法总结:
1. 实验设置
尽管该系统与具体框架无关,但选择在 NVIDIA Isaac Sim 中进行实现,以便利用精确的接触物理特性来处理具身智体(embodied brain)所需的视觉-统计输入。用 RidgebackFranka(一种配备 7 自由度机械臂的全向移动底盘机器人)对长程任务进行评估,此类任务要求导航与操作的协同配合;实验中使用来自 Objaverse 和 PartNet-Mobility 的资产。采用混合执行策略:利用 BIT* 进行无碰撞导航,利用 SAC 进行涉及频繁接触的操作。策略网络和 Q 网络均采用多层感知机(MLP)架构,包含 [256, 256] 大小的隐层,并使用 Adam 优化器进行训练。
2. 生成多样性
指标与基线。为了量化生成多样性,采用语义和视觉指标。用 Self-BLEU-4 和 S-BERT 相似度来衡量语言冗余度,得分越低表示多样性越高。为了捕捉结构差异,通过 ViT 和 CLIP 嵌入在不同场景间的余弦相似度来评估视觉多样性,从而确保形态上的广泛性。将本方法与以下基线进行对比:(1) 专家设计的基准(如 RLBench、ManiSkill2、Behavior-100),代表人工策划的标准;(2) GenSim-V2,这是一个缺乏可行性反馈的最先进开环基线。
3. 任务可行性
指标与基线。为了量化可行性差距的缩小程度,采用可行任务率(FTR)指标,即在验证流程下评估任务 τ 是否可行(即满足 μ(τ) > δ_min)。将 FTR 分解为两个子指标:首先,场景有效性率(SVR)通过 BLIP-2 语义一致性和几何检查来衡量感知对齐情况;其次,执行有效性率(EVR)利用仿真预言机(Simulation Oracle)评估动态可行性,通过 MPC 和 RL 求解器验证物理执行过程是否成功。将 FATE 与“基础版”(无审核机制)的下限基线以及最先进的 GenSim-V2 进行对比。
4. 审计准确性
指标与基准。FATE 框架的可靠性取决于审计器(Auditor)准确估算可行性指标 μ(τ) > δ_min 的能力。审计器通过检查语义问题、几何约束和动态问题这三个特定方面的故障来识别不可行任务(如图 1 所示)。为了量化这种可靠性,用 F1 分数(基于人工标注的真值数据集)来衡量审计器的效能。该指标直接反映判别器在识别各类故障时的准确性,同时最大限度地减少误报(false positives)。
5. 修复效能
指标定义。为了衡量主动修复闭环的贡献,定义修复成功率(Repair Success Rate, RSR)。该指标计算的是:一个初始不可行的任务假设(即 μ(τ) > δ_min)在经过修改后成功映射到可行区域的条件概率。针对三个不同阶段评估 RSR:Ante-Repair(静态场景调整)、Primitive-Repair(运行时逻辑修正)和 RL-Repair(学习参数微调)。较高的 RSR 表明,该系统不仅仅是充当过滤器(剔除不可行数据),而是积极地将提议分布投影到可行性流形上。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 6
6 0
0- 0



 已为社区贡献352条内容
已为社区贡献352条内容

所有评论(0)