GeoSem-WAM:几何与语义-觉察的世界动作模型
26年6月来自港科大(深圳)、港大、中科大和北京人形机器人中心的论文“GeoSem-WAM: Geometry- and Semantic-Aware World Action Models”。
近期的世界动作模型(WAMs)在具身决策方面展现出了卓越的能力。然而,其有效性究竟源于推理过程中的显式未来想象,还是源于预测训练所驱动的表征学习,目前尚无定论。现有证据表明,其主要优势在于学习鲁棒的潜表征,而非在测试阶段生成未来的观测图像。尽管如此,现有的 WAMs 主要依赖于基于 RGB 的未来预测,这种方式对复杂环境的结构和空间理解较为有限。为解决这一问题,提出一种结构化世界建模框架,通过几何与语义监督来增强潜表征。除了 RGB 图像的未来预测外,模型还引入针对未来几何与语义表征的两个辅助预测分支,从而能够在统一的潜空间内同时捕捉场景动态、空间几何结构及语义上下文。至关重要的是,方法避免在测试阶段进行显式的未来轨迹推演或视频生成,从而保持了高效的推理性能。
如图 1 所示该方法的架构图(训练和推理):
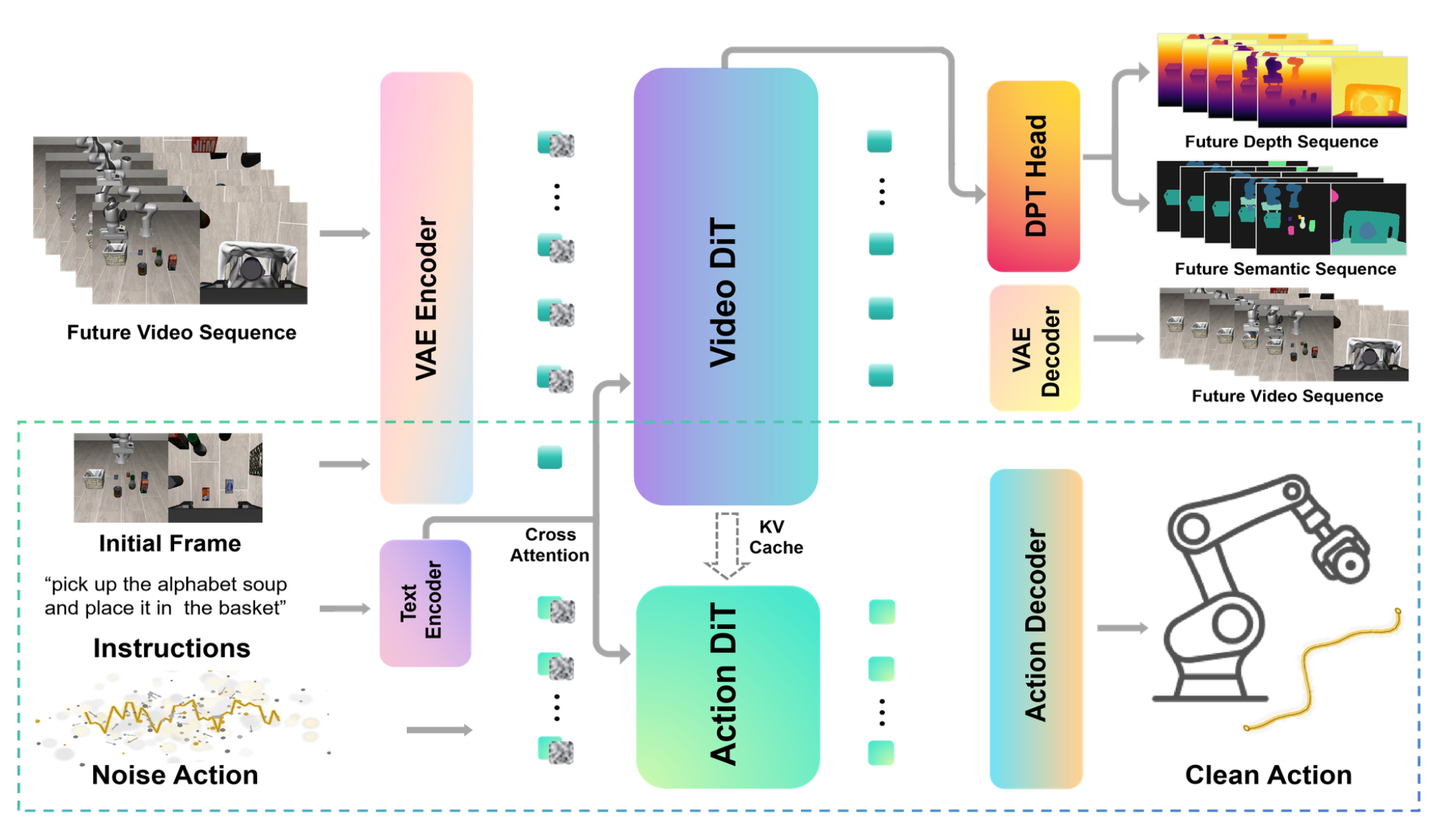
GeoSem-WAM 构建于 Wan2.2-5B [35] 的视频扩散 Transformer (DiT) 之上,该模型充当了世界建模的主干网络。此外,该模型还复用了同一模型中的预训练文本编码器和视频 VAE:任务指令通过原生的 T5 编码器进行编码,并经由交叉注意机制传递给所有 Token;而视觉观测则通过预训练的 VAE 转换为潜视频 Token。在此主干网络的基础上,引入一个专门用于生成动作序列块(action chunk)的“动作专家 DiT”——其架构与主干网络相似,但在规模上有所不同。此外,还集成 DPT 风格 [36] 的几何预测分支和语义分割分支。整个模型采用 Transformer 混合(MoT)架构,并在视频分支与动作分支之间共享注意机制。虚线框标示模型在推理阶段的输入内容及网络架构。
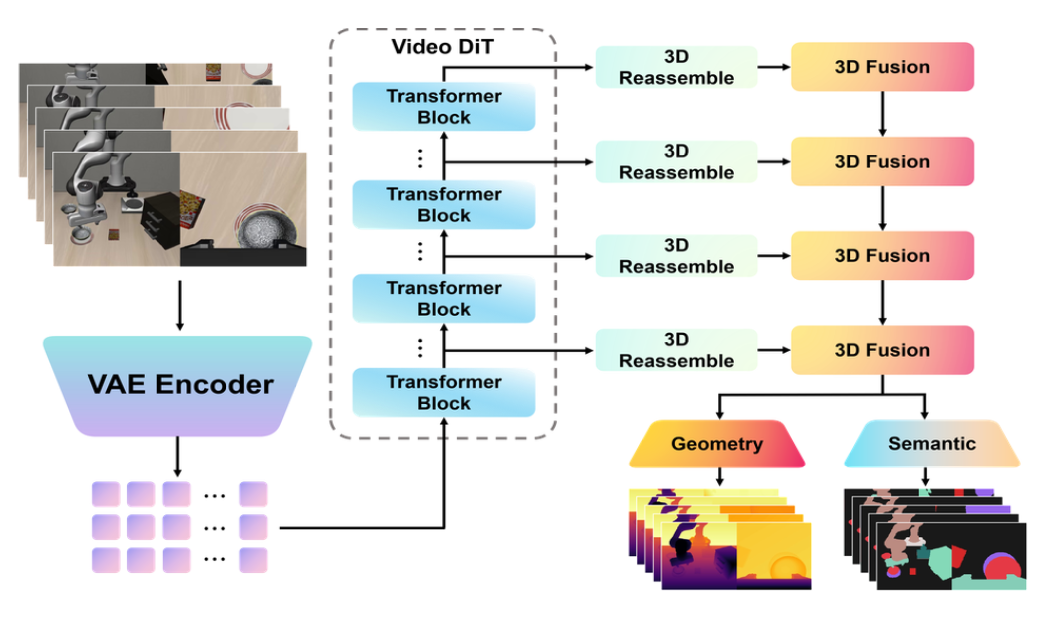
为了促使学习到的世界表征同时编码几何结构与对象级语义,对视频潜(latent)Token 引入密集辅助监督。采用 DPT 风格 [36] 的密集预测头来实现这一辅助分支。该 DPT 风格的预测头聚合了来自多个 Transformer 模块的中间视频 Token。这些多层级特征经过投影、融合与解码,转化为密集的空间预测结果,从而使辅助监督能够同时利用低层空间细节与高层语义抽象信息。
如图 2 展示了该 DPT 风格密集预测分支的详细结构。具体而言,输入视频首先通过 VAE 编码器转换为 Token;在这些 Token 经由多个 Transformer 阶段处理后,架构将各阶段的 Token 重新组合为多分辨率、类图像的表征;随后,这些表征通过融合模块进行逐步融合与上采样,并最终由几何与语义预测头解码,生成细粒度的预测结果。为了更好地适应视频输入,将原有的重组与融合模块扩展为 3D 重组模块与 3D 融合模块。
如图 5 所示仿真环境与多模态观测概览。(I) Libero 基准任务:(a) Libero-Goal,(b) Libero-Object,© Libero-Spatial 和 (d) Libero-10。各任务均展示了 RGB 观测图像 (1, 2),并配有相应的深度图 (3) 和语义分割掩码 (4)。(II) RoboTwin 基准任务:(a) 整洁环境和 (b) 随机环境。代表性任务包括按响门铃、移动罐子/壶、移动订书机/垫板、抓取双瓶以及放置手机支架,并提供成对的 RGB、深度及语义观测数据。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献346条内容
已为社区贡献346条内容

所有评论(0)