YOLO26实战教学:从零开始训练自定义数据集
YOLO26实战教学:从零开始训练自定义数据集
你是否也想快速上手最新的YOLO26模型,用自己的数据集训练一个专属的目标检测器?但又被复杂的环境配置、依赖安装和代码调试劝退?
别担心。本文将带你使用最新YOLO26官方版训练与推理镜像,从零开始完成一次完整的自定义数据集训练全流程。无需手动装环境、不用查报错、不折腾CUDA版本,开箱即用,小白也能10分钟跑通第一个模型。
我们一步步来,手把手教你激活环境、准备数据、修改配置、启动训练,并最终下载属于你的模型文件。整个过程清晰明了,适合刚入门目标检测的开发者、学生或项目实践者。
1. 镜像环境说明
这个镜像不是普通封装,而是基于 YOLO26 官方代码库(ultralytics) 深度定制的完整开发环境。它预装了所有必要的依赖项,省去了繁琐的配置过程,真正做到“一键启动,马上训练”。
核心环境信息如下:
- 核心框架:
pytorch == 1.10.0 - CUDA版本:
12.1 - Python版本:
3.9.5 - 主要依赖:
torchvision==0.11.0,torchaudio==0.10.0,cudatoolkit=11.3,numpy,opencv-python,pandas,matplotlib,tqdm,seaborn等常用科学计算与视觉处理库
这意味着你不需要再为版本冲突、驱动不兼容等问题头疼。只要镜像一启动,就能直接进入训练状态。
此外,镜像中还内置了常用的YOLO26系列权重文件(如 yolo26n.pt),放在根目录下,开箱即用,节省大量下载时间。
2. 快速上手
启动镜像后,你会看到类似下面的界面:
默认情况下,代码位于 /root/ultralytics-8.4.2 目录下。为了方便后续修改和持久化保存,建议先将其复制到工作区。
2.1 激活环境与切换工作目录
首先,激活名为 yolo 的 Conda 环境:
conda activate yolo
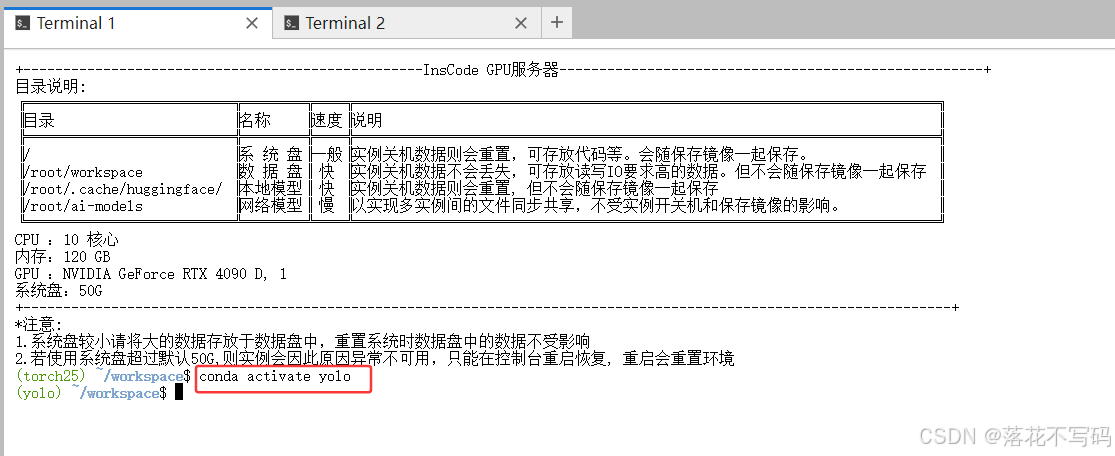
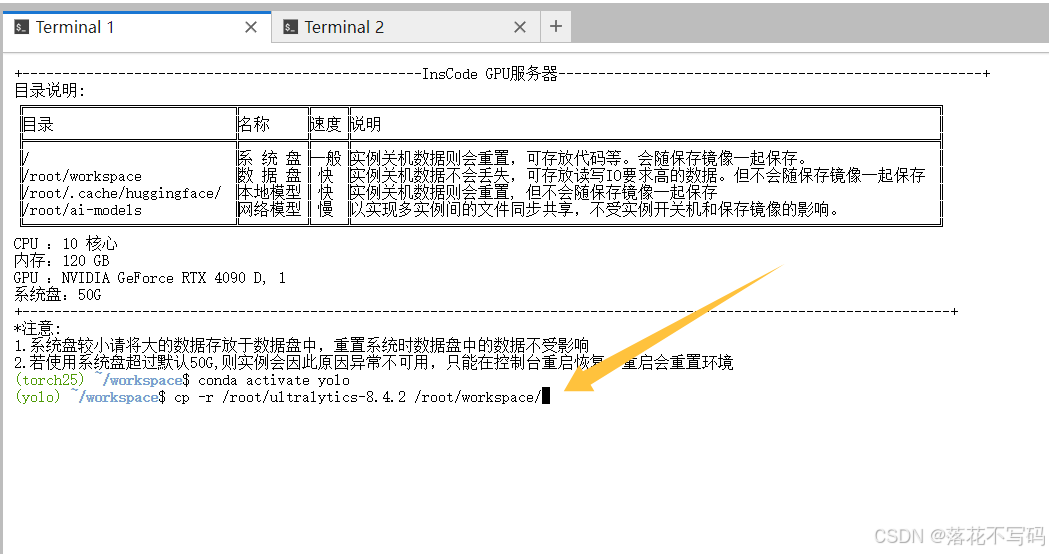
接着,将原始代码复制到数据盘的工作目录中,避免系统盘被清空导致代码丢失:
cp -r /root/ultralytics-8.4.2 /root/workspace/
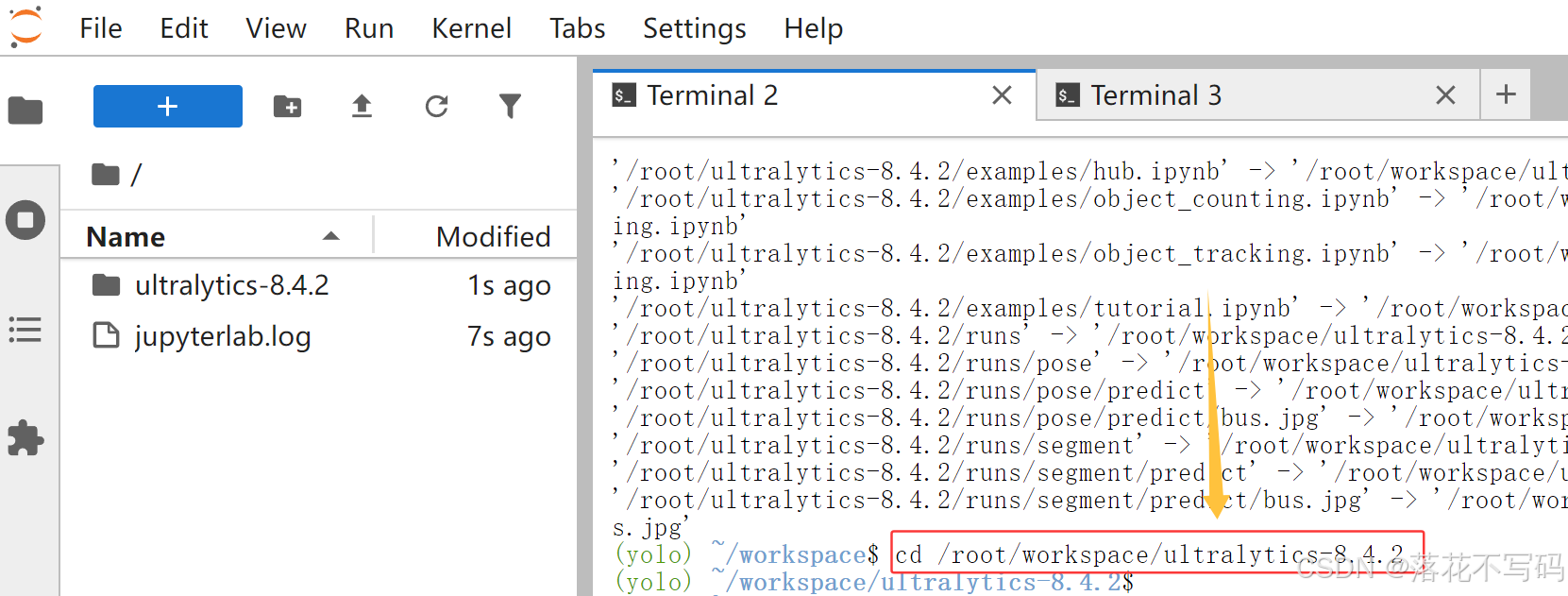
然后进入新目录:
cd /root/workspace/ultralytics-8.4.2
现在你就可以自由编辑代码而不用担心数据丢失了。

2.2 模型推理
在正式训练前,先来测试一下模型的推理能力,看看它能不能正常识别图像中的目标。
打开 detect.py 文件,写入以下代码:
# -*- coding: utf-8 -*-
"""
@Auth :落花不写码
@File :detect.py
@IDE :PyCharm
@Motto :学习新思想,争做新青年
"""
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
model = YOLO(model=r'yolo26n-pose.pt')
model.predict(source=r'./ultralytics/assets/zidane.jpg',
save=True,
show=False,
)
参数说明:
- model参数:这里填的是模型权重路径。你可以选择不同的预训练模型,比如
yolo26n.pt、yolo26s.pt等。 - source参数:指定输入源。可以是本地图片路径、视频文件,或者摄像头编号(如
0表示调用摄像头)。 - save参数:设为
True时,会自动保存推理结果到runs/detect/predict/目录下。 - show参数:是否弹窗显示结果。服务器环境下通常设为
False。
运行命令:
python detect.py
执行完成后,终端会输出检测结果概览,包括类别、置信度等信息。生成的图片也会保存在指定路径中,供你查看效果。
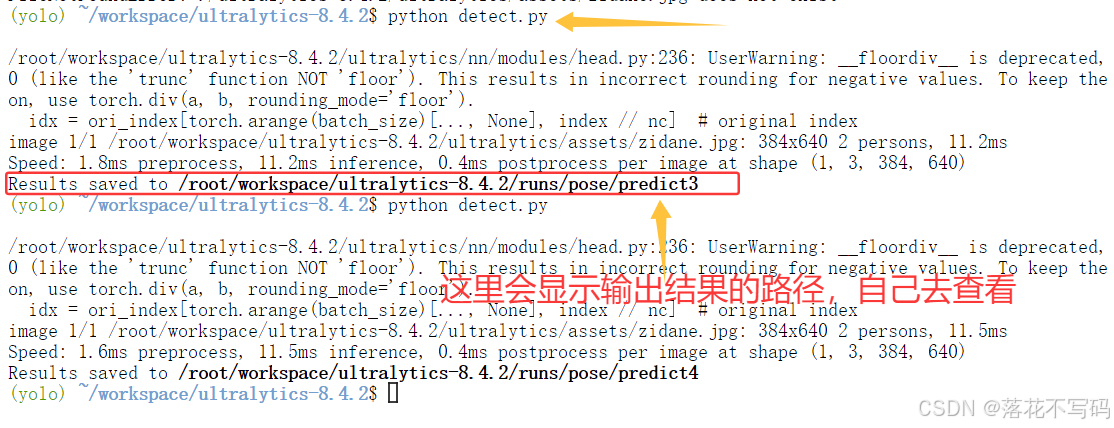
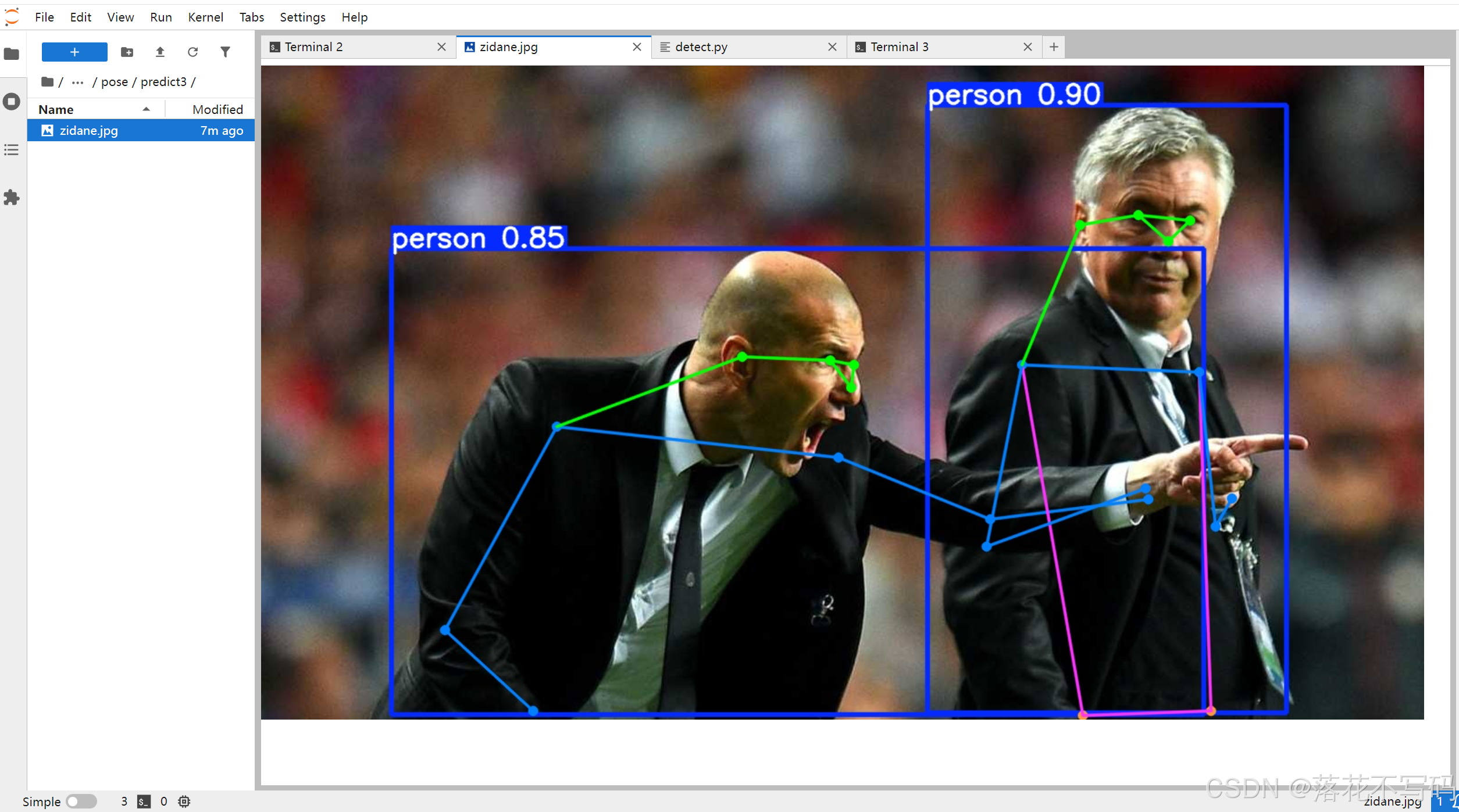
推理结果会在终端打印出来,同时保存图像文件,方便后续分析。
2.3 模型训练
接下来就是重头戏——用自己的数据集训练模型。
准备数据集
你需要提前准备好符合 YOLO 格式的数据集。结构应如下:
dataset/
├── images/
│ ├── train/
│ └── val/
├── labels/
│ ├── train/
│ └── val/
└── data.yaml
其中每张图片对应一个 .txt 标注文件,格式为:class_id center_x center_y width height(归一化坐标)。
配置 data.yaml
上传数据集后,在项目根目录创建或修改 data.yaml 文件,内容示例如下:
train: ./dataset/images/train
val: ./dataset/images/val
nc: 80 # 类别数量
names: ['person', 'bicycle', 'car', ...] # 类别名称列表
确保路径正确指向你的训练和验证集。
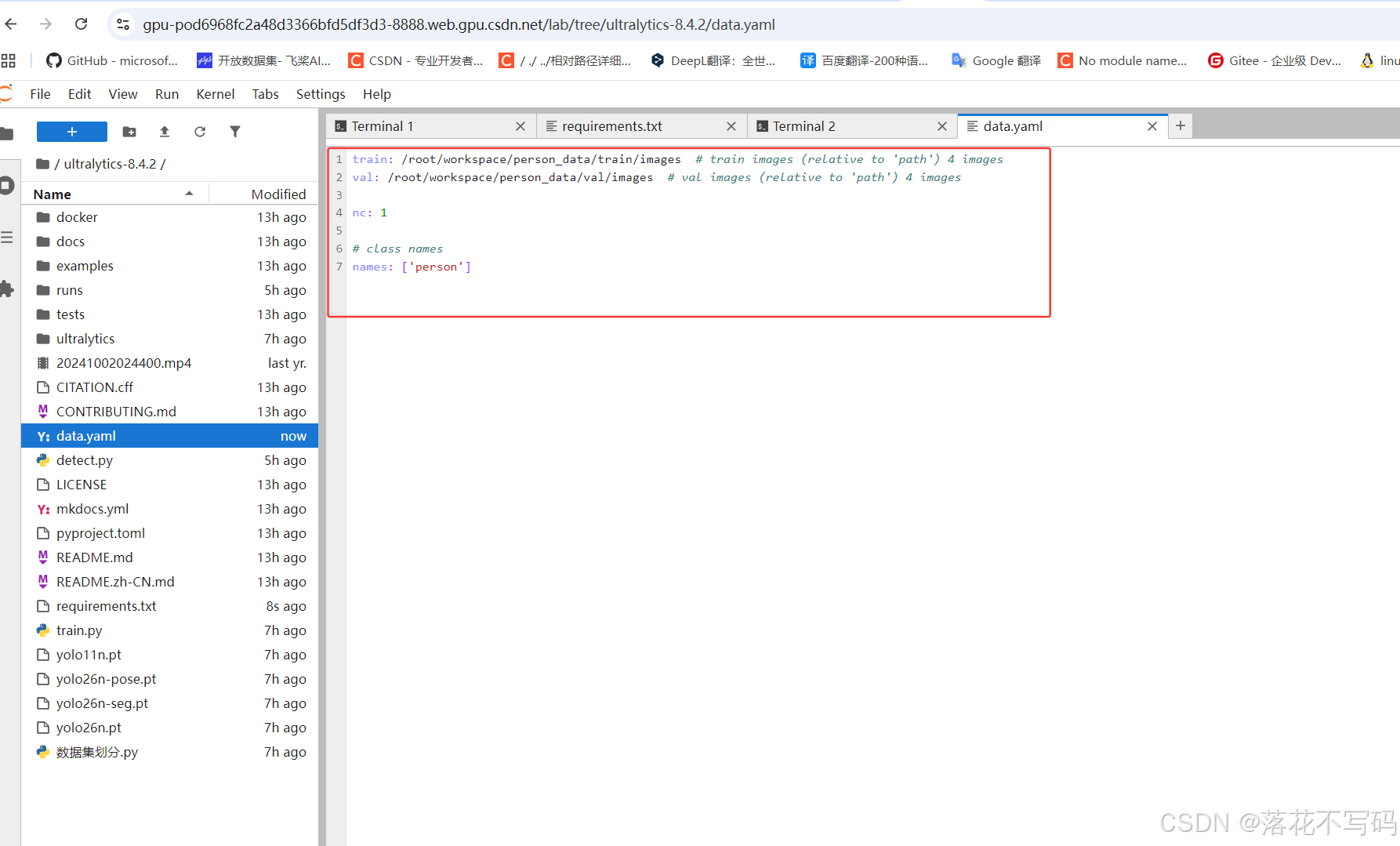
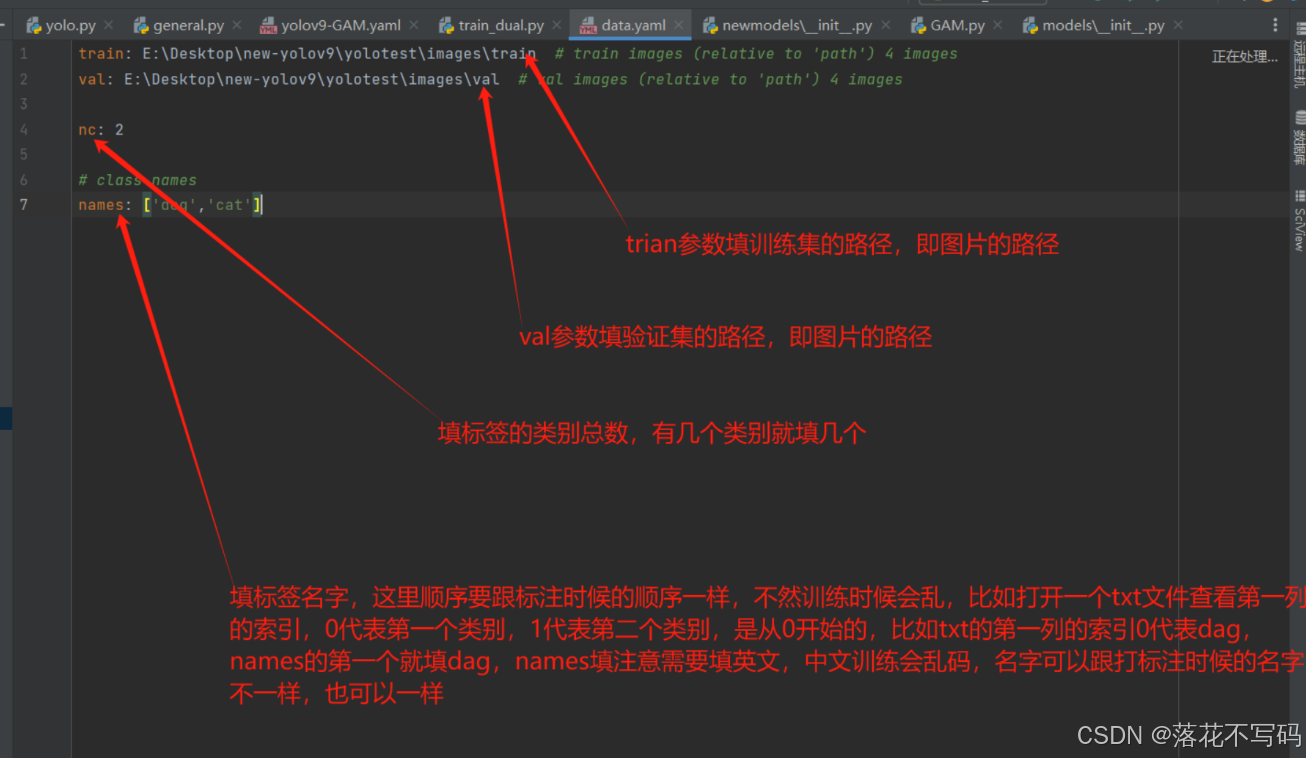
修改 train.py
接下来编写训练脚本。以下是推荐的 train.py 示例代码:
# -*- coding: utf-8 -*-
"""
@Auth :落花不写码
@File :train.py
@IDE :PyCharm
@Motto :学习新思想,争做新青年
"""
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 加载模型结构
model = YOLO(model='/root/workspace/ultralytics-8.4.2/ultralytics/cfg/models/26/yolo26.yaml')
# 加载预训练权重(可选)
model.load('yolo26n.pt') # 初次训练可加载,若做消融实验建议不加载
# 开始训练
model.train(data=r'data.yaml',
imgsz=640, # 输入图像尺寸
epochs=200, # 训练轮数
batch=128, # 批次大小
workers=8, # 数据加载线程数
device='0', # 使用GPU 0
optimizer='SGD', # 优化器类型
close_mosaic=10, # 最后10轮关闭Mosaic增强
resume=False, # 不从中断处继续
project='runs/train',
name='exp', # 实验名称
single_cls=False, # 是否单类别训练
cache=False, # 是否缓存数据到内存
)
启动训练
保存文件后,在终端运行:
python train.py
训练日志会实时输出,包括损失值、mAP指标、学习率等关键信息。
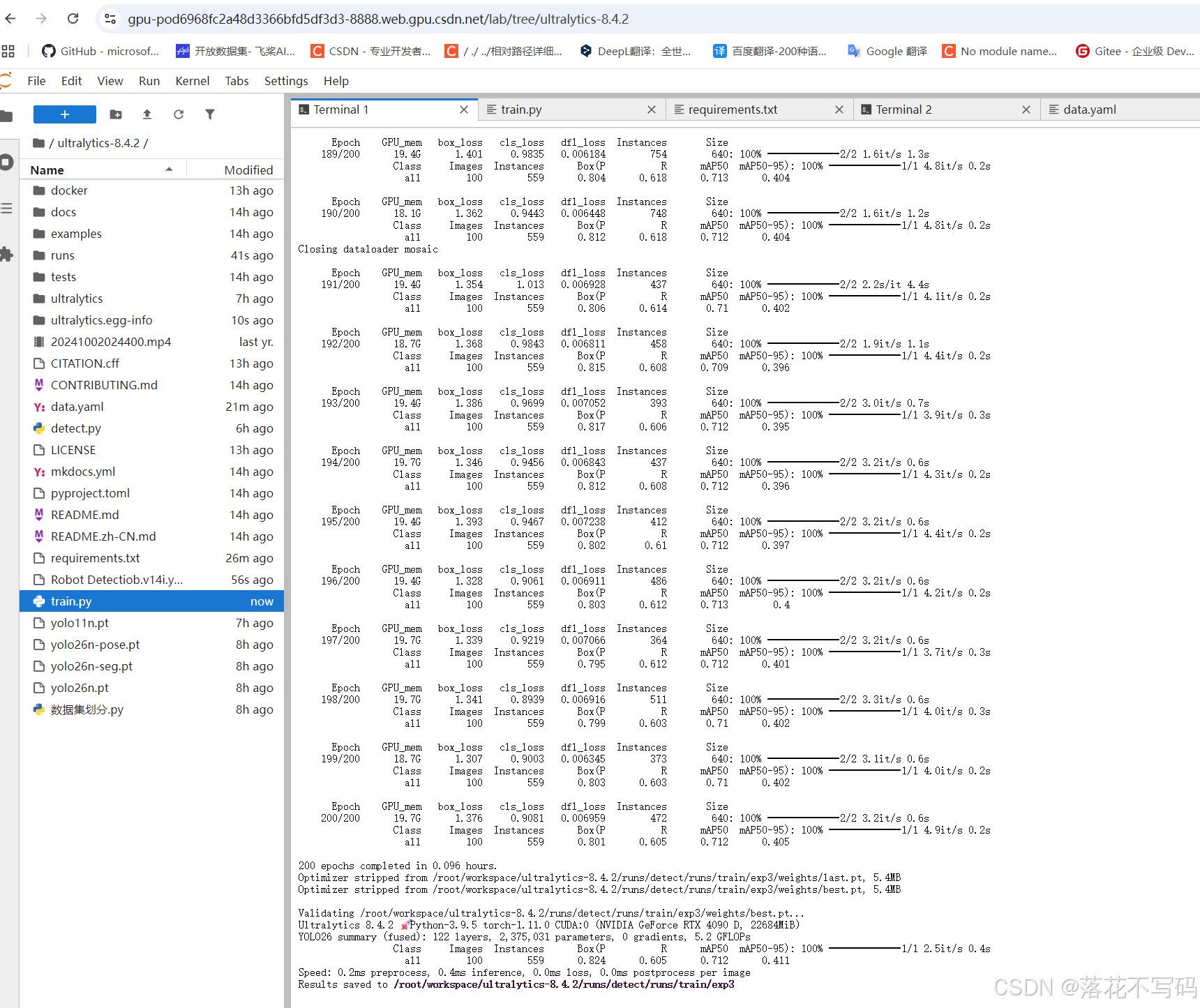
训练过程中,最佳模型会自动保存在 runs/train/exp/weights/best.pt,最后一次的模型保存为 last.pt。
2.4 下载训练结果
训练结束后,你可以通过工具(如 Xftp)将模型文件下载到本地使用。
操作非常简单:
- 打开Xftp连接服务器
- 在右侧找到
runs/train/exp/weights/文件夹 - 将
best.pt或last.pt文件双击下载,或拖拽到左侧本地目录
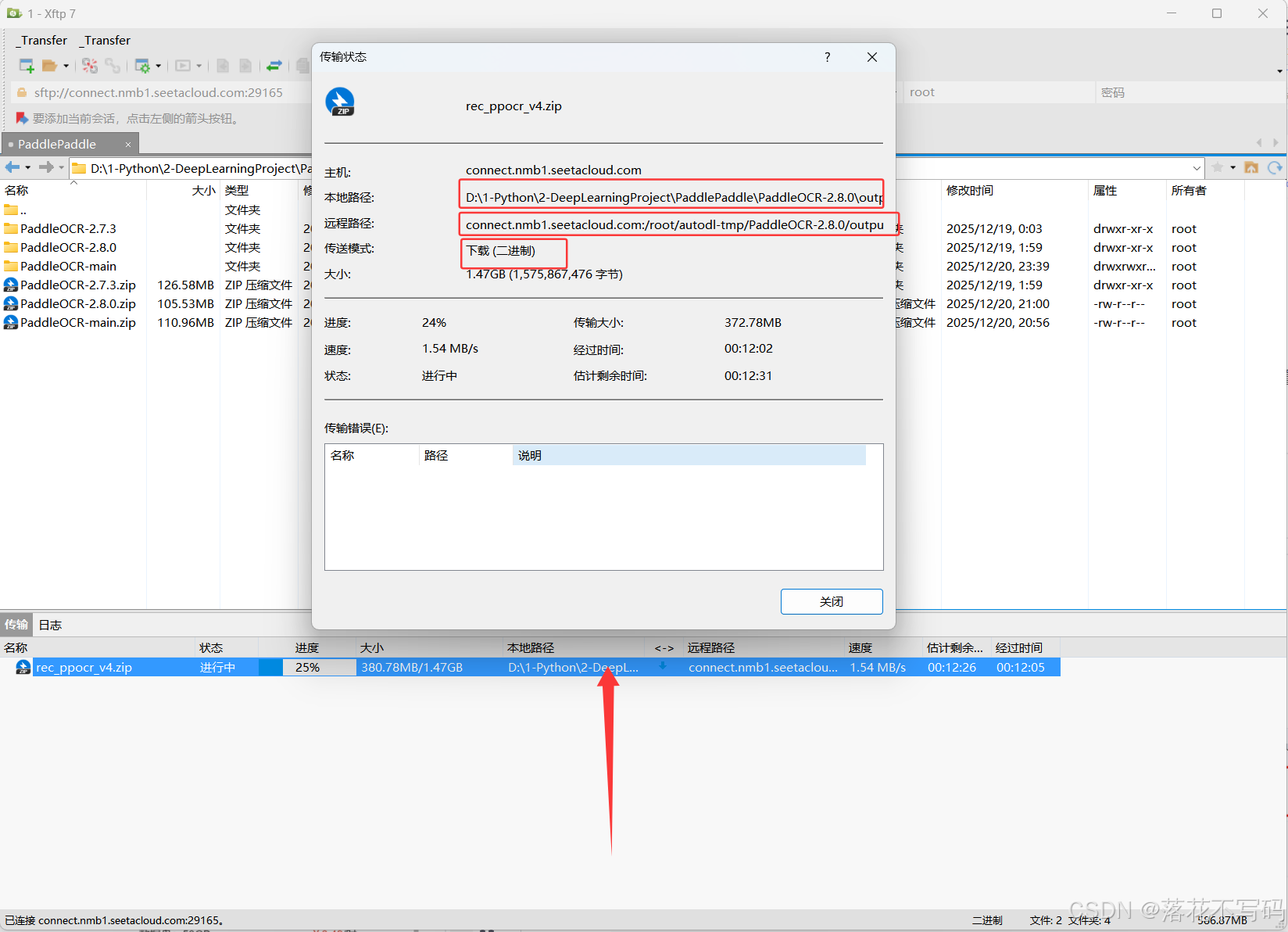
建议对大文件先压缩再传输,提升下载效率。上传数据集的操作也是同理,只需反向拖拽即可。
3. 已包含权重文件
为了避免用户反复下载耗时的预训练模型,该镜像已在根目录预置了多个常用权重文件:
yolo26n.ptyolo26s.ptyolo26m.ptyolo26l.ptyolo26x.ptyolo26n-pose.pt(姿态估计专用)
这些文件可以直接在代码中通过相对路径调用,无需额外下载。
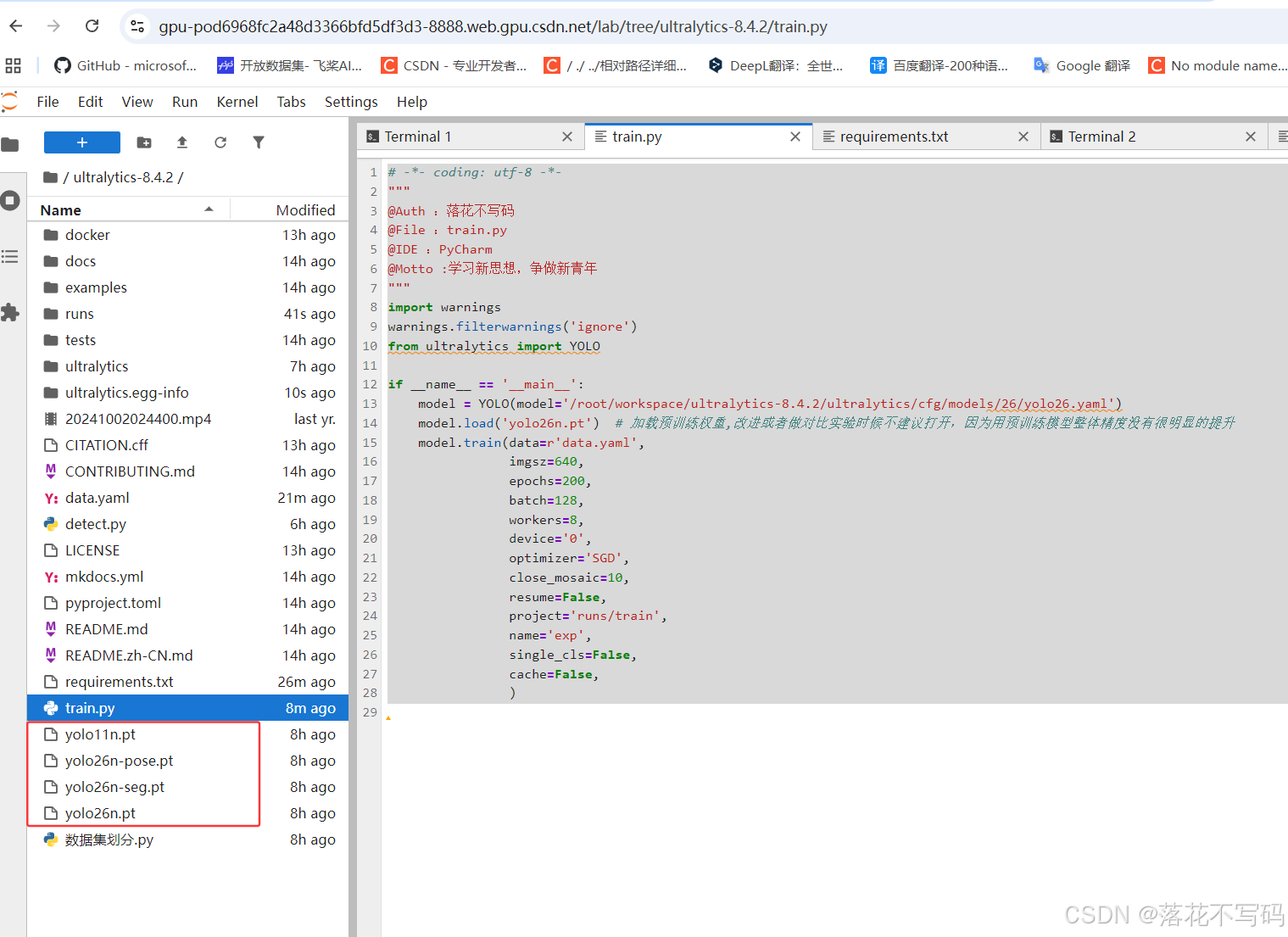
这大大提升了实验效率,尤其适合需要频繁对比不同骨干网络性能的场景。
4. 常见问题
尽管镜像已经高度集成,但在实际使用中仍可能遇到一些小问题。以下是高频疑问及解决方案:
-
Q:为什么训练时报错找不到数据?
A:请检查data.yaml中的路径是否正确,建议使用绝对路径或相对于当前工作目录的相对路径。 -
Q:训练时GPU没被调用怎么办?
A:确认已执行conda activate yolo,并检查device='0'是否正确。可通过nvidia-smi查看GPU状态。 -
Q:训练中断了能续训吗?
A:可以!只需将resume=True,并指定上次训练生成的weights/last.pt路径即可恢复训练。 -
Q:batch size 设置多少合适?
A:根据显存调整。如果出现OOM(内存溢出),尝试降低batch值,或启用--autobatch功能让系统自动调节。 -
Q:如何评估模型效果?
A:训练完成后,使用val.py脚本对验证集进行评估,查看 mAP@0.5 等核心指标。
5. 总结
通过这篇实战教程,你应该已经掌握了如何利用 YOLO26官方训练与推理镜像 快速完成以下任务:
- 激活专用环境并复制代码到安全目录
- 使用预训练模型进行图像推理测试
- 配置自己的数据集并编写
data.yaml - 编写训练脚本并启动模型训练
- 下载训练好的模型用于本地部署
整个流程简洁高效,特别适合希望快速验证想法、开展课程设计、参加竞赛或搭建原型系统的同学和开发者。
更重要的是,这套方法具有很强的可复用性。无论你是做目标检测、实例分割还是姿态估计,都可以在此基础上快速迁移适配。
下一步,你可以尝试:
- 调整超参数优化模型表现
- 使用更大的模型(如 yolo26l)提升精度
- 添加自定义数据增强策略
- 将模型导出为 ONNX 或 TensorRT 格式用于生产环境
技术的进步从来不是一蹴而就,但每一次动手实践,都是离专家更近一步。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 27
27 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)