数据集之鸢尾花数据集(Iris Dataset)
·
鸢尾花数据集(Iris Dataset)是数据科学与机器学习领域中最著名的经典数据集之一,由统计学家 Ronald Fisher 在1936年首次提出,用于展示线性判别分析的应用。鸢尾花数据集因其简单性和易于理解的特性,常被用于教学和研究中。
数据集概览
1. 数据结构
鸢尾花数据集共有 150条记录,每条记录代表一朵鸢尾花的测量数据,包括以下五个属性:
| 属性名称 | 描述 | 数据类型 |
|---|---|---|
| Sepal Length | 萼片长度(单位:厘米) | 数值型 |
| Sepal Width | 萼片宽度(单位:厘米) | 数值型 |
| Petal Length | 花瓣长度(单位:厘米) | 数值型 |
| Petal Width | 花瓣宽度(单位:厘米) | 数值型 |
| Species | 鸢尾花的种类(目标标签) | 分类型 |
2. 分类标签
鸢尾花数据集包含三种鸢尾花的分类标签,每种类型各有50条记录:
- Setosa:山鸢尾
- Versicolor:杂色鸢尾
- Virginica:维吉尼亚鸢尾
3. 数据特点
- 数据集是平衡的,每个类别包含的样本数相同。
- 特征数据具有一定的区分性,但不同类别之间存在一定程度的重叠。
- 它是一个典型的 多分类问题 数据集,适用于分类算法的研究和验证。
数据集用途
鸢尾花数据集在以下领域中被广泛应用:
-
机器学习模型的实验与评估
- 适合用于分类模型(如决策树、SVM、k-NN、逻辑回归等)的测试。
- 可用于比较不同分类算法的性能。
-
数据可视化
- 通过散点图、箱线图等可视化手段,观察特征分布及类别之间的差异。
- 二维和三维投影展示类别的分布情况。
-
统计学习和特征分析
- 用于讲解线性判别分析(LDA)和主成分分析(PCA)。
- 适合学习如何进行特征工程和降维。
-
教学与入门实践
- 简单易懂,非常适合初学者学习数据处理、分析和建模的完整流程。
鸢尾花数据集的可视化
-
二维可视化:
使用散点图展示萼片长度、花瓣长度等特征之间的关系。不同种类的鸢尾花可以用颜色区分。import seaborn as sns import matplotlib.pyplot as plt from sklearn.datasets import load_iris import pandas as pd iris = load_iris() data = pd.DataFrame(data=iris.data, columns=iris.feature_names) data['species'] = iris.target data['species'] = data['species'].map({0: 'setosa', 1: 'versicolor', 2: 'virginica'}) sns.pairplot(data, hue='species') plt.show()
结果展示:
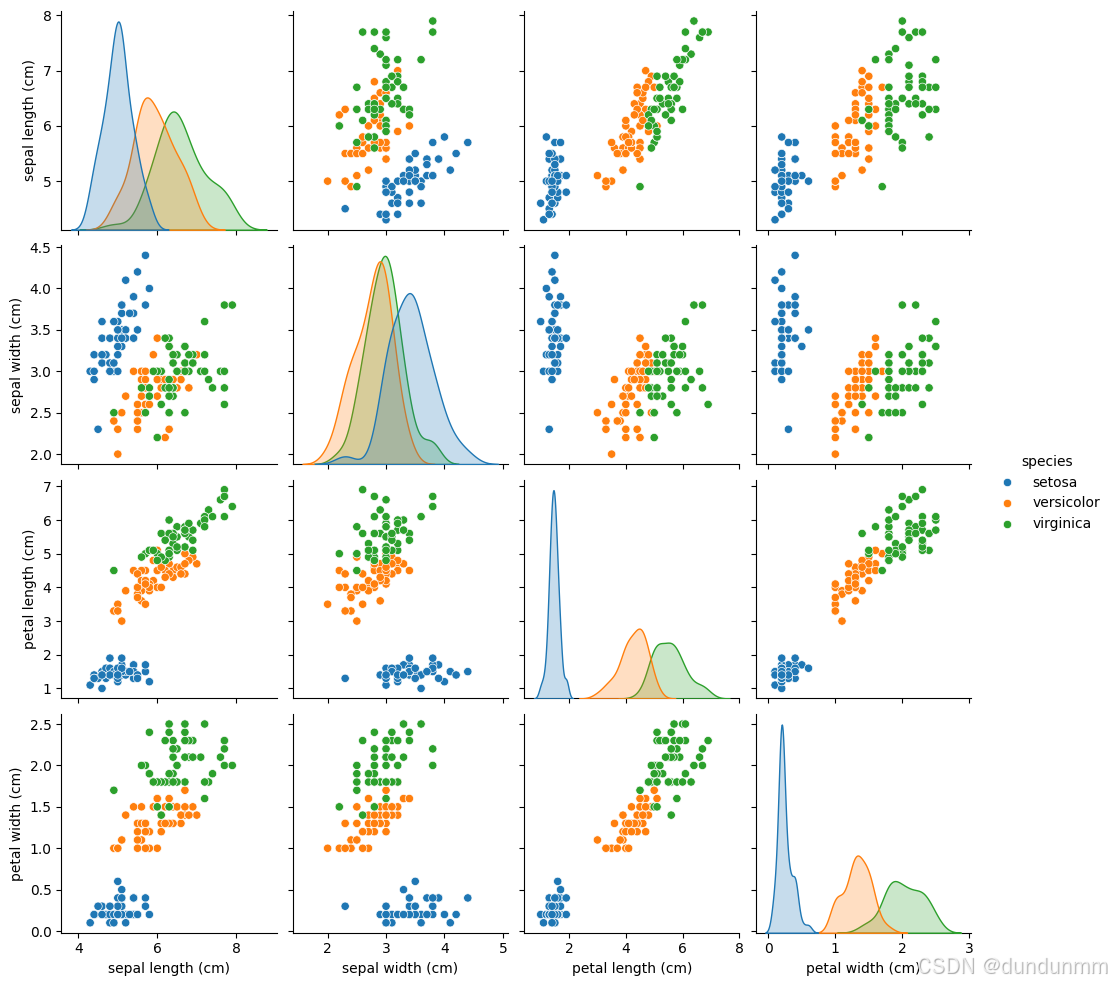
-
三维可视化:
使用特征(如 Petal Length, Petal Width, Sepal Length)绘制三维散点图,观察三类鸢尾花的分布差异。
获取鸢尾花数据集
鸢尾花数据集可以通过以下方式轻松获取:
- Scikit-learn 提供的内置数据集:
from sklearn.datasets import load_iris iris = load_iris() print(iris.data) # 特征数据 print(iris.target) # 分类标签 - UCI 机器学习库:
- 可通过 UCI Machine Learning Repository 下载数据集文件。
鸢尾花数据集的优点
- 小而精:数据集小(150条记录),适合快速运行和学习。
- 易于可视化:只有4个特征,便于二维或三维可视化。
- 丰富的分类信息:多分类问题,适合入门分类任务。
鸢尾花数据集以其简单性和实用性,为数据科学与机器学习的学习和研究提供了重要帮助,是入门不可或缺的经典数据集。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 16
16 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)