python机器学习:深入浅出 Python 机器学习:数据生成
基于头歌的数据生成。
第一关:生成分类数据集
机器学习中的分类问题的基本结构:分类问题和回归问题
分类问题:一个事物有n个特征,我们该通过什么样的方法将其划分到m类中。其中这n个特征和这m个类别都是由人来定义的,而这个划分方法的大框架也是由人来指定,但是方法的细节却是由机器通过预先设计好的算法在给定的训练数据集上学习得来的。
所以所谓的机器学习,其实学习的只是划分方法的细节而已。而事物的特征,类别,以及大方法的框架却都是由人来划分的。所以说在机器学习中,最重要的问题就是如何划分事物的特征,确定事物的类别 (学习框架的选择相比之下会容易许多)。这也是计算机科学的根本问题,即如何将现实世界的事物抽象为计算机可表示的模型。大家在学习机器学习或算法之类的课程时往往会沉迷于其中的算法细节,如书本在讲述机器学习算法时都是将特征与类别确定好了的,只需要去跑算法就好了,但往往会忘记最重要的事情。
不过万幸,scikit-learn 中有着内置的,非常完善的数据生成和加载机制。我们这一节先来讲述最简单的数据生成方法: make_blobs。
make_blobs方法的原型如下:
sklearn.datasets.make_blobs(n_samples,n_features,centers,cluster_std,center_box,shuffle,random_state)
其中各个参数的含义如下:
n_samples:一个整数或一个整数数组,当输入为一个整数时,表示将要生成的数据总量。当输入为一个整数数组时,表示需要为每一类生成的数据量。默认值为100。n_features:一个整数,表示特征的数量。默认值为2。centers:生成的数据中心的数量。(即生成的种类数)可以是None或者一个整数或者是一个整数数组。当centers为None且n_samples为整数时,会生成3个中心。当n_samples为整数数组时,centers必须为与n_samples一样长度的整数数组。默认值为Nonecluster_std:一个浮点数,表示数据之间的标准差,默认值为1.0。center_box:一个浮点数对,表示生成的每一类的中心的下限与上限。默认值为(-10.0, 10.0)。shuffle:一个布尔值,表示是否要打乱生成的数据。默认为True。random_state:None或者一个整数,当输入为一个整数时,表示这次生成数据过程的随机因子。换句话说,如果两次调用make_blobs生成数据时,如果random_state是同一个整数,且其他参数都相同,则生成的数据是一样的。
make_blobs的返回值由两部分组成,第1部分是一个n_samples*n_features的矩阵,表示数据的特征部分,第2部分是一个长度为n_samples的向量,表示数据的类别部分。

易错点:刚开始的时候取两位小数点,忘记用numpy的统计学函数了。
第二关:生成回归数据集
回归问题可以这样不严谨地进行描述:一个事物有n个特征,我们该通过什么样的方法预测出这个事物所对应的值(不一定是标量,可以是1维2维任意维的量),但是这个维度需要预先设定好。
我们可以看到回归问题与分类问题是很像的,事物都需要n个特征进行描述,分类问题需要设计事物属于的m个类别,回归问题也需要设定事物所对应的值的维度。同时他们也都需要人来设定这个方法的大框架,需要机器根据某种方法去学习这个方法的细节。
所以回归问题和分类问题在结构上是非常像的。所以事实上大多数用于分类的算法都可以稍加修改后应用到回归问题上,反过来也成立。
在 scikit-learn 中生成用于回归数据的方法是make_regression方法。
make_regression方法的参数比较复杂,我们将在下一节和用于产生分类数据的另一个方法一起讲述。
所以我们会先讲述一下它比较常用的参数:n_samples,n_features,random_state,大家还有印象的话,应该还记得上一节中讲述的方法也有这几个参数。在make_regression方法中,这些参数的含义和上一节中是一样的。
另外还有一个比较重要的参数是: n_targets,表示输出值的维度,默认情况下是1,即默认情况下输出标量。
make_regression方法的返回值类似于make_blobs,区别是第二个输出不是类型,而是值。同时还有一个区别是,当make_regression的coef参数为真时,make_regression的第三个返回值是一个数组,表示用于生成数据的线性模型的参数。
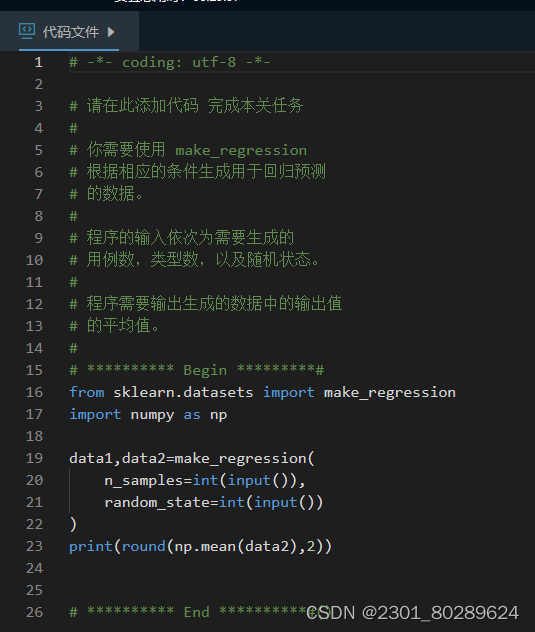
易错点:数据在哪里呢?
第三关:给数据添加噪音
如何生成带有噪音的数据和生成数据的其他参数
在第一节中我们介绍了make_blobs方法,可以生成简单的用于分类的数据集。在第二节,我们介绍了make_regression方法,可以生成用于回归的数据集。但是在当时我们留了一个小引子,没有介绍完make_regression方法的全部参数。在这一节我们会介绍另外一个生成分类数据的方法,make_classification,同时也会介绍make_regression方法中没有介绍完毕的参数。
首先我们先来看看make_classsification和make_regression方法的原型:
make_classification(n_samples,n_features,n_informative,n_redundant,n_repeated,n_classes,n_clusters_per_class,weights,flip_y,class_sep,hypercube,shift,scale,shuffle,random_state)make_regression(n_samples,n_features,n_informative,n_targets,n_repeated,n_bias,effective_rank ,tail_strength ,noise,shuffle,coef,random_state)
其中名字相同的参数的含义是一样的:
n_samples: 一个整数表示将要生成的数据总量。默认值为100。n_features: 一个整数,表示特征的数量。在make_classification中默认值为20,在make_regression中默认值为100。n_informative: 一个整数,表示特征中比较重要的特征的数量(即可以提供更多信息量的特征数量)。在make_classification中默认值为2,在make_regression中默认值为10。n_redundant: 一个整数,表示特征中冗余特征的数量(即不能提供更多信息量的特征数量)。在make_classification中默认值为2。n_repeated: 一个整数,表示特征中重复特征的数量。可以模拟实际问题中因为数据提取不好造成的数据重复问题。在make_classification中默认值为0。n_classes: 一个整数,表示分类问题中的目标类型的数量。在make_classification中默认值为2。n_clusters_per_class:一个整数,表示分类问题中每类拥有的数据簇的数量。在make_classification中默认值为2。weights: 浮点数的列表,表示每一类数据占总数据的比重。注意当列表中所有浮点数的值之和大于1时,可能会产生意想不到的结果。在make_classification中默认值为None。flip_y:一个浮点数,表示噪音值。这个数越大就会使分类更困难。在make_classification中默认值为0.01。class_sep:一个浮点数,表示类与类之间的间距。这个值越大就会使分类更容易。在make_classification中默认值为0.01。hypercube: 一个布尔值,当为真时,表示数据簇是从超立方体(想象一下问题空间,二维问题就是正方形,三维就是立方体,更高维就是超立方体了)的顶点开始产生的。否则就表示数据簇是从随机的多平面体的顶点上生成的。说得更直白一些的话,当这个值为真时,生成的数据会更均匀一些。在make_classification中默认值为True。shift:一个浮点数或一个长度为n_features的浮点数组或者None。表示将特征值通过某个值进行平移,不然生成的特征值就分布在0点的周围了。在make_classification中默认值为0.0。scale:一个浮点数或一个长度为n_features的浮点数组或者None。表示将特征值与某个值相乘后的结果赋值给这个特征值,注意是先发生shift再scale,学过线性代数的同学肯定一下子就可以发现这就是对特征值做一个一维线性变换。在make_classification中默认值为1.0。n_targets:表示回归问题中输出值的维度。默认为1。bias:一个浮点数,默认为0.0。这个值为0.0时,表示生成的数据都是在线性模型上的,这个值越大,表示生成的数据就远离线性模型。effective_rank:整数或None,当是一个整数时,表示决定使用线性组合解释输入值的向量的数目,用于模拟实际中的数据。当为None时,表示模型产生的数据会满足高斯分布。在make_regression中默认值为None。tail_strength:一个0.0到1.0之间的浮点数,当effective_rank参数不为None时,生效。表示生成的数据的尾部的厚度。在make_regression中默认值为0.5。noise:浮点数,输出的噪音值。默认值为0.0。shuffle: 一个布尔值,表示是否要打乱生成的数据。在make_regression中默认为True。coef:一个布尔值,表示是否要输出产生数据的线性模型的参数。在make_regression中默认为False。random_state:None或者一个整数,当输入为一个整数时,表示这次生成数据过程的随机因子。换句话说,如果两次生成数据时,如果random_state是同一个整数,且其他参数都相同,则生成的数据是一样的。
make_regression的返回结果在上一节中描述过。make_classification的返回结果与make_blobs相同。
虽然介绍的参数很多,但实际中我们需要使用的参数并没有那么多,不够随着我们需求的变化,我们也要学会使用不同的参数来产生我们想要的结果。在这一方面并没有什么很现成的经验,需要大家多多实践来总结。
编程要求
根据提示,在右侧编辑器补充代码,使用 make_classificication 根据相应的条件生成用于分类的数据,并输出生成的数据中特征数据的平均值 (保留两位小数)。
程序的输入为5行,每行一个整数,第1行表示要生成的数据数,第2行表示要生成的种类数,第3行表示随机状态,第4行表示需要添加的噪音值,第5行表示带有信息值的特征数。
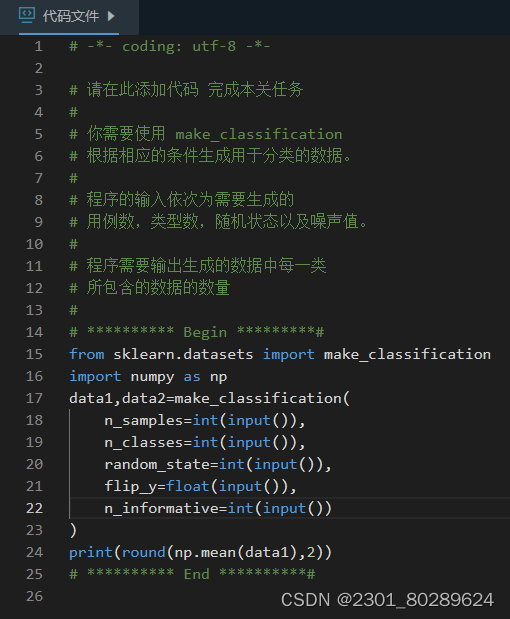
易错点:什么噪音?字太多,烦烦烦(还是耐心看代码好)
第四关:使用内置数据集
为了完成本关任务,你需要掌握:
- 如何加载 scikit-learn 内置数据集。
- 如何将数据集划分为训练数据集和测试数据集。
如何加载 scikit-learn 内置数据集
我们之前已经描述过数据在机器学习中是多么的重要,也在前3节中介绍了生成分类数据和回归数据的方法。但是无论我们生成的数据怎么好,心里也还是会打鼓,不免觉得自己生成的数据不一定有效。
为了解决类似的这种情况,scikit-learn本身就内置了不少数据集供大家使用。这些内置的数据集分为两类:在线数据集和离线数据集。在线数据集的规模很大,当使用时需要预先从网上下载,离线数据集的规模就小很多了,当你按照完scikit-learn之后这些数据就被自动下载下来了,离线数据集也叫玩具数据集。教材中使用的真实数据集也基本是玩具数据集。
接下来我们介绍一下scikit-learn中有那些玩具数据集:
| 加载方法 | 描述 |
|---|---|
load_boston |
波士顿房价数据集,用于回归 |
load_breast_cancer |
肺癌数据集,用于分类 |
load_diabetes |
债务数据集,用于回归 |
load_digits |
数位数据集,用于分类 |
load_files |
文本数据集 |
load_iris |
鸢尾花数据集,用于分类 |
load_linnerud |
用于多分类 |
load_sample_image |
加载一张图片 |
load_sample_images |
加载多张图片 |
load_svmlight_file |
加载svmlight / libsvm格式的文件 |
load_wine |
加载酒数据集,用于分类 |
可以看到玩具数据集中的所有方法都以load开头,而在线数据集则以fetch开头,不过这里不过多介绍。
这些我在后面标注了用于分类/回归的加载数据集的方法,除了load_digits之外(它还有一个参数n_class表示类别的数量),他们都只有一个参数,return_X_y,表示数据集的返回形式。
当return_X_y为真时,他们的返回值要么和make_blobs一样,要么和make_regression一样,都是X_y形式的。
但当return_X_y为假时(默认值即为假),他们的返回形式是一个像Python的字典一样的对象,Bunch。Bunch对象有以下那么几个属性,data表示生成的特征数据矩阵。target表示生成的输出值(在回归问题中为类别的标号),DESCR表示数据集的描述,在分类问题中还有target_names和features_names两个属性用于描述标签和特征。另外在较新的版本(0.20以上)中,还有filename,data_filename以及target_filename等属性描述数据文件在计算机中的物理位置。
我们可以这样子使用Bunch数据集:
data=load_wine()data['data'] # 表示特征data['target'] #表示标签或输出data.data #表示特征data.target #表示标签或输出
如何将数据集划分为训练数据集和测试数据集
虽然讲了很久怎么样生成和加载数据集,但还是没有说明怎么样使用数据集。一般而言,对于分类任务和回归任务而言,我们都需要一个训练数据集去训练我们的模型(也就是机器学习中所说的学习过程),另外还需要一个测试数据集去测试我们的模型,不然也不知道我们学习出来的模型好还是不好。
对于一个数据集,怎么样划分训练数据集和测试数据集也是一个大学问。不过作为初学者,我们暂时先不必要知道太多的细节。我们暂时只需要知道怎么样解决这个问题就好了。
一个简单实用的办法是使用train_test_split方法(位于sklearn.model_selection模块),这个方法的原型如下:
train_test_split(*arrays,test_size,train_size,random_state,shuffle,stratify)
random_state和shuffle都见过很多次了,就不多介绍了,其他参数的含义如下:
*arrays:表示待分割的数据。test_size:浮点数或整数或None,当这个数为浮点数时,表示测试集占总数据的比例,当这个值为整数时,表示测试集中的数据数。当这个值为None时,表示测试集是训练集的补集。默认值为0.25。train_size:浮点数或整数或None,当这个数为浮点数时,表示训练集占总数据的比例,当这个值为整数时,表示训练集中的数据数。当这个值为None时,表示训练集是测试集的补集。默认值为None。stratify: 数组或None,当shuffle为真时使用,表示按数组的值进行分层抽样。- 返回值: 长度为
2*len(arrays)的列表。表示分割后的数据。
典型的使用方法如下:
data=load_wine()X_train, X_test, Y_train, Y_test = train_test_split(data['data'], data['target'])
编程要求
根据提示,在右侧编辑器补充代码,使用酒数据集根据不同的测试集的比例生成训练数据集合测试数据集,并计算他们各自的方差。
输入:一个浮点数,表示测试集的比例。 输出:两行,每行一个浮点数,表示训练集的特征的方差和测试集的特征的方差(保留一位小数)。
要求:train_test_split的random_state参数需要设置为1。
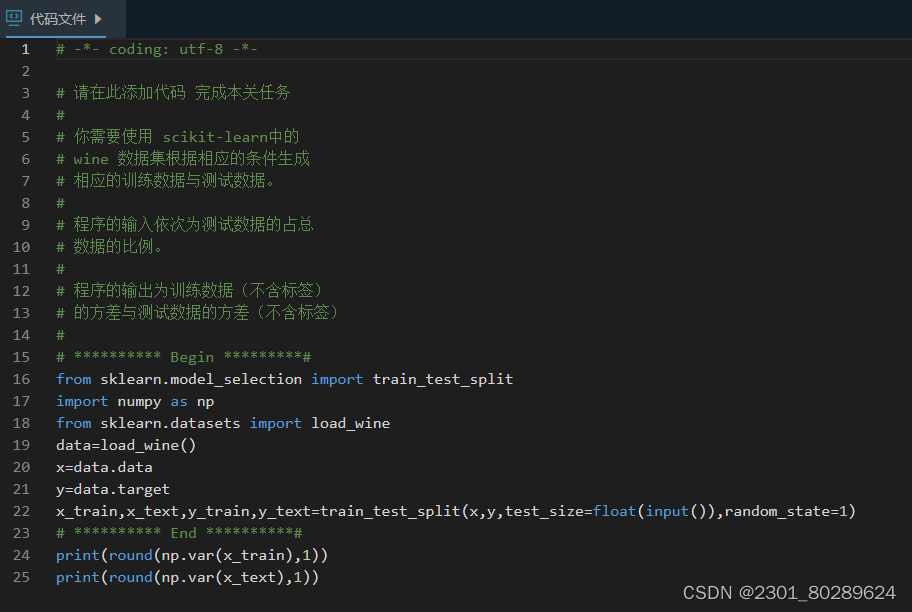
train_test_split出现啦,好好厘清记忆以便后期用到。内置数据集还挺好的,不过引用要记得从datasets获取。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)