Python后端开发之旅(一)——连接数据库
Python后端开发之旅(一)——连接数据库
- 常见的语法糖
- 连接数据库
- Web 应用开发入门对比——Flask & Django
常见的语法糖
常用的内置对象

python 没有 double 类型
Python 中使用的浮点数类型是 float ,它代表双精度浮点数,具有双精度的浮点数精度
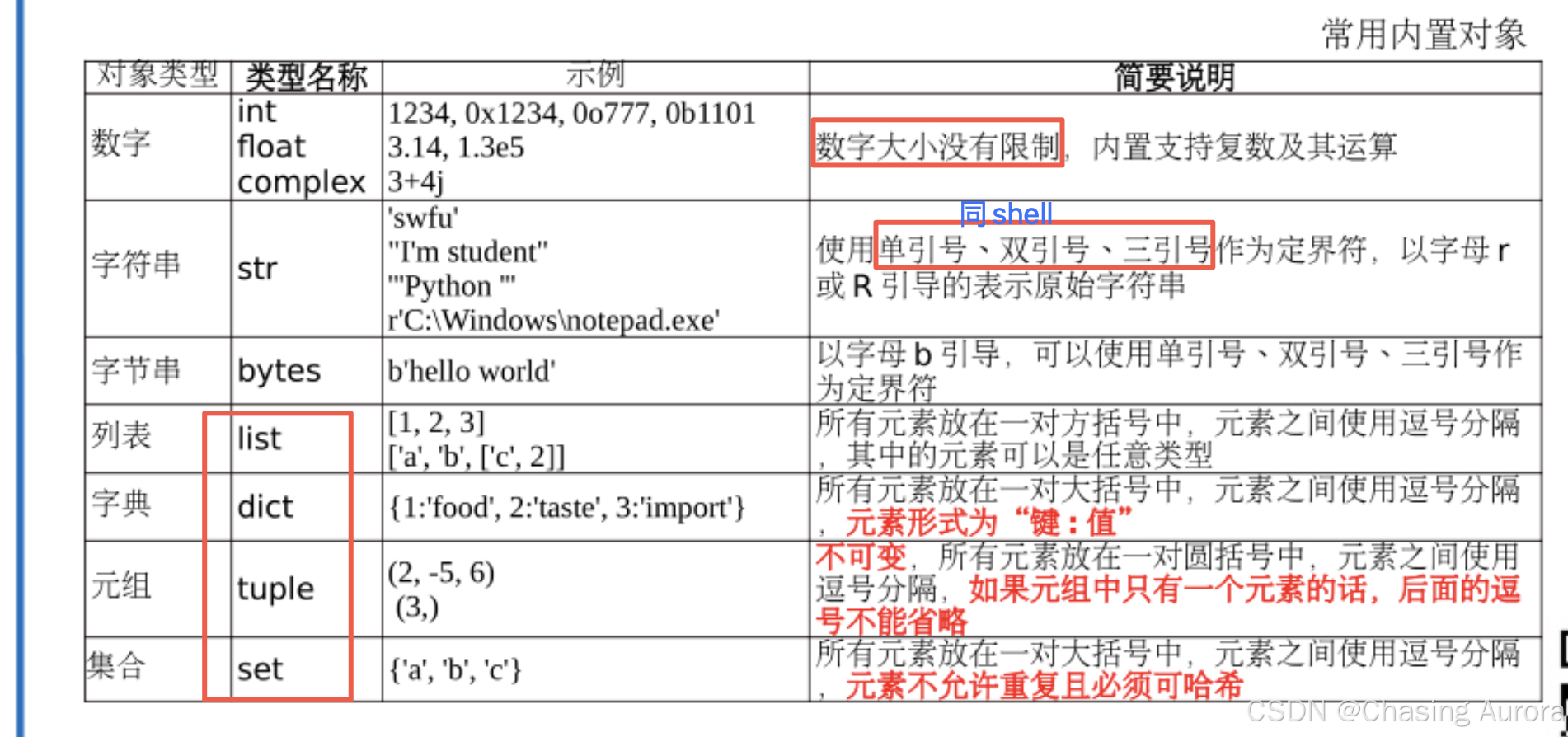
range、map、zip、filter、enumerate等迭代器对象是Python中比较常用的内置对象,支持某些与容器类对象类似的用法,统称为可迭代对象

重要对象 (除了reduce是函数())
一定会 包含索引的,就是index,从0开始计数






元组 和 列表的异同



类型转化



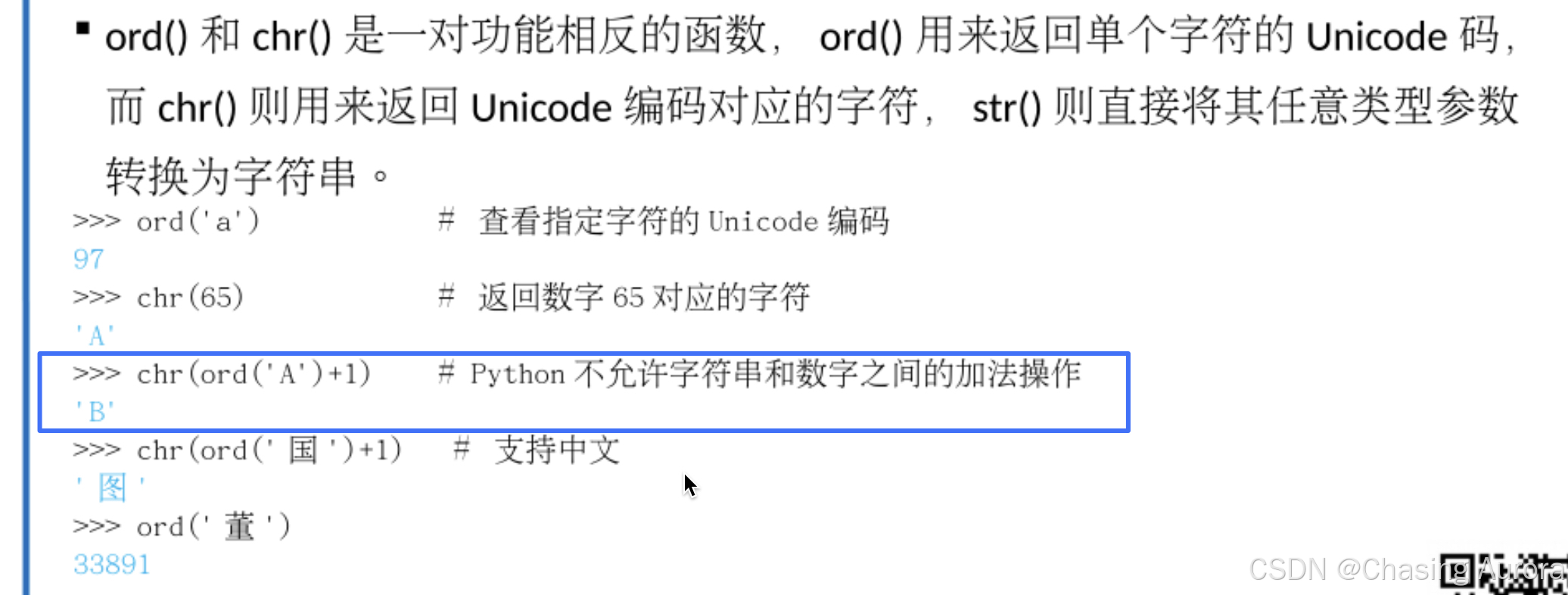

排序和逆序


生成器对象
生成器表达式




生成器函数

yield 是 Python 中的一个关键字,用于定义一个生成器函数(generator function)。
它和 return 类似,但有一个关键区别:
return返回值后函数结束yield返回值后,函数暂停并记住当前位置,下次调用时从这里继续
💡 基本语法
def my_generator():
yield 1
yield 2
yield 3
使用方式:
gen = my_generator()
print(next(gen)) # 输出: 1
print(next(gen)) # 输出: 2
print(next(gen)) # 输出: 3
# print(next(gen)) # StopIteration 错误
⚠️ 每次
next()调用会执行到下一个yield,然后暂停。
🌟 实际应用场景:处理大数据流
def count_up_to(n):
for i in range(n):
yield i
# 只有需要时才计算
for num in count_up_to(5):
print(num) # 输出: 0, 1, 2, 3, 4
✅ 优点:节省内存!不需要一次性生成整个列表。
对比传统方式:
# ❌ 内存占用高 (O(n))
def count_up_to_list(n):
return list(range(n))
nums = count_up_to_list(1000000)
# ✅ 内存高效 (O(1))
for num in count_up_to(1000000):
pass # 每次只生成一个数
✅ 生成器(Generator)和迭代器(Iterator)是什么?
📌 迭代器(Iterator)定义:
- 可以被
next()调用的对象 - 实现了
__iter__()和__next__()方法 - 一次产生一个值,直到耗尽
my_list = [1, 2, 3]
iterator = iter(my_list) # 转换为迭代器
print(next(iterator)) # 1
print(next(iterator)) # 2
print(next(iterator)) # 3
# print(next(iterator)) # StopIteration
✅ 所有可迭代对象(如 list, tuple, str)都可以通过
iter()转为迭代器
📌 生成器(Generator) 定义:
- 使用
yield的函数 → 生成器函数 - 用于处理大数据流,调用它不会立即执行,而是返回一个生成器对象
- 懒惰求值(Lazy Evaluation)
- 只在需要时生成数据
- 极致节省内存
def gen():
yield 1
yield 2
yield 3
g = gen() # g 是生成器对象
print(type(g)) # <class 'generator'>
✅ types.GeneratorType 是什么?
types.GeneratorType 是 Python 标准库中 types 模块定义的一个 类型对象,用来表示“生成器”的类型
import types
def my_gen():
yield 1
g = my_gen()
print(type(g)) # <class 'generator'>
print(isinstance(g, types.GeneratorType)) # True
print(isinstance(g, int)) # False
🛠️ 其他相关类型(Python 3.x)
| 类型 | 描述 |
|---|---|
types.GeneratorType |
生成器的类型 |
types.CoroutineType |
协程的类型(async/await) |
types.FunctionType |
普通函数的类型 |
types.MethodType |
方法的类型 |
def fibonacci():
a, b = 0, 1
while True:
yield a
a, b = b, a + b
fib = fibonacci()
# 生成器对象
print(type(fib)) # <class 'generator'>
print(isinstance(fib, types.GeneratorType)) # True
print(isinstance(fib, abc.Iterator)) # True,生成器属于迭代器
# 使用
print(next(fib)) # 0
print(next(fib)) # 1
print(next(fib)) # 1
print(next(fib)) # 2
- 内存优化:处理大文件、流数据、无限序列
- 代码简洁:用
yield替代复杂的循环 - 延迟计算:只在需要时才生成数据

流程控制—— break、continue、pass 的區別
-
break:強制跳出 ❮整個❯ 迴圈
-
continue:強制跳出 ❮本次❯ 迴圈,繼續進入下一圈
-
pass:不做任何事情,所有的程式都將繼續
- pass 就像是 To do 的概念,在寫程式的時候,有時候想的比實際寫出來的速度快,但還沒有實作出來,空著內容不寫又會產生語法錯誤🤦♂️
- 這時就會使用 pass 來替代,當作是個指標,提醒自己之後要來完成
装饰器
不改变函数自身代码的情况下,动态地增加功能
看ku
def decorator(func):
def wrapper(*args, **kwargs): # 都会定义这个 方法
# 在函数调用之前执行的代码
result = func(*args, **kwargs)
# 在函数调用之后执行的代码
return result
return wrapper
🌟 什么是 with 语句?
with 是 Python 中一个非常优雅且安全的上下文管理器(Context Manager),主要用于自动处理资源的“打开”和“关闭”,比如文件、数据库连接、锁等。
它的核心思想是:
“进入时做点事,退出时自动清理。”
这样能避免忘记手动关闭资源,防止内存泄漏或文件损坏等问题。
🔧 基本语法:
with 表达式 as 变量:
# 执行代码块
表达式:必须返回一个支持上下文管理器的对象(如文件对象)as 变量:可选,用于接收表达式的结果(比如文件对象)
✅ 示例 1:操作文件
# 不推荐的方式(容易忘记关闭)
file = open('test.txt', 'w')
file.write('Hello, World!')
file.close()
# 推荐的方式:使用 with
with open('test.txt', 'w') as f:
f.write('Hello, World!')
# 自动关闭文件,不需要写 close()
✅ 优点:
- 文件会自动关闭,即使代码出错(如异常抛出)
- 更简洁、更安全
✅ 示例 2:使用数据库连接
import sqlite3
with sqlite3.connect('example.db') as conn:
cursor = conn.cursor()
cursor.execute("SELECT * FROM users")
results = cursor.fetchall()
# 连接会自动关闭,无需手动 commit 或 close
✅ 示例 3:使用线程锁(threading.Lock)
import threading
lock = threading.Lock()
with lock:
# 任何需要加锁的代码放这里
print("临界区")
# lock 自动释放,即使发生异常
📦 with 的工作原理(底层机制)
with 背后依赖两个方法:
__enter__(): 进入with块时调用 → 通常是“打开资源”__exit__(): 离开with块时调用(无论是否出错)→ 通常是“关闭资源”
这些方法由上下文管理器对象提供(如文件、数据库连接、锁等)。
✅ 自定义上下文管理器(进阶)
你可以用类来定义自己的 with 语句:
class MyContext:
def __enter__(self):
print("进入上下文")
return self # 可以返回任意值
def __exit__(self, exc_type, exc_val, exc_tb):
print("离开上下文")
# 如果发生异常,exc_type 不为 None
# 返回 False 表示继续抛出异常;True 表示忽略异常
return False
# 使用
with MyContext() as ctx:
print("在上下文中执行")
内部类和函数
嵌套函数(nested function)或内部函数(inner function)
- 可以在一个函数内部定义另一个函数,这种做法称为嵌套函数(
nested function)或内部函数(inner function) - 嵌套函数可以帮助将某些功能逻辑封装在一个局部范围内,使得这些逻辑对外部不可见,仅在父函数的上下文中使用。这种做法有助于减少全局命名空间的污染,避免命名冲突
- 内部函数可以访问外部函数的局部变量和参数
- 在外部函数 之外 无法调用到 内部函数,只有在外部函数 内才可以调用到
- 注意仍然 定义在调用之前
嵌套类 或 内部类
- 为什么会使用呢?
- 把两个或者多个类打包在一起。假设你有两个类Car和Engine。每一个Car都需要一个Engine,但是每一个Engine不会在没有Car的时候被使用。因此我们可以让Engine成为Car的内部类。这有助于我们保存代码
- 可以使用self关键词来访问内部类
- 内部类不能直接用外部类的属性和方法,还得加上类名
日志框架
一份 Python logging 配置有下面四个部分组成:
- Loggers
- Handlers
- 过滤器Filter
- Formatters
流程:创建logging.getLogger-创建:logging.handler–handler.setLevel–logging.Formatter/handler.setFormatter–logger.addHandler
按日回滚
info_handler = logging.handlers.TimedRotatingFileHandler(log_path + ".log",
when="D",
backupCount=7)
每天午夜时分,日志系统会自动:
- ✅ 重命名当前 liantiao_ai.log → liantiao_ai.log.2025-12-20
- ✅ 创建新的空文件 liantiao_ai.log
- ✅ 删除超过7天的旧日志文件
Filter
在日志记录从 logger 传到 handler 的过程中,使用 Filter 来做额外的控制。
默认情况下,只要级别匹配,任何日志消息都会被处理。不过,也可以通过添加 filter 来给日志处理的过程增加额外条件,例如,可以添加一个 filter 只允许某个特定来源的 ERROR 消息输出。
Filter 还被用来在日志输出之前对日志记录做修改。例如,可以写一个 filter,当满足一定条件时,把日志记录从 ERROR 降到 WARNING 级别。
Filter 在 logger 和 handler 中都可以添加;多个 filter 可以链接起来使用,来做多重过滤操作。
为 logger 命名
对 logging.getLogger() 的调用会获取(必要时会创建)一个 logger 的实例。不同的 logger 实例用名字来区分。这个名字是为了在配置的时候指定 logger。
按照惯例,logger 的名字通常是包含该 logger 的 Python 模块名,即 __name__。这样可以基于模块来过滤和处理日志请求。不过,如果你有其他的方式来组织你的日志消息,可以为 logger 提供点号分割的名字来标识它:
# Get an instance of a specific named logger
logger = logging.getLogger('project.interesting.stuff')
这种 logger 的名字,用点号分隔的路径定义了一种层次结构。project.interesting 这个 logger 是 project.interesting.stuff logger 的上级;而 project logger 是 project.interesting logger 的上级。
为什么这种层级结构是重要的呢?因为 logger 可以设置为将日志的请求传播给上级。这样就可以在 logger 树结构的顶层定义一组单独的 handler,来捕获所有下层的日志请求。
在 project 命名空间中定义的 logger handler 将会捕获 project.interesting 和 project.interesting.stuff 这两个 logger 中的所有日志请求。
可以基于 logger 来控制传播的行为。 如果你不希望某个 logger 传播给上级,可以关闭它,比如:
def configure_sqlalchemy_logging():
""" 控制sqlalchemy日志输出 """
sa_logger = logging.getLogger('sqlalchemy.engine')
sa_logger.setLevel(logging.WARNING) # 控制 SQLAlchemy 输出级别
sa_logger.handlers.clear() # 避免重复输出
sa_logger.propagate = False # 防止冒泡到 root logger
- ✅ 不输出任何日志(因为清空了所有处理器)
- ✅ 不传播到根日志器(不会出现在控制台或其他地方)
示例:同时输出到控制台和文件
import logging
# 创建logger
logger = logging.getLogger('my_app')
logger.setLevel(logging.DEBUG)
# 控制台处理器
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
# 文件处理器
file_handler = logging.FileHandler('debug.log')
file_handler.setLevel(logging.DEBUG)
# 添加处理器到logger
logger.addHandler(console_handler)
logger.addHandler(file_handler)
# 使用
logger.debug('调试信息') # 只写入文件
logger.info('普通信息') # 输出到控制台+文件
logger.error('错误信息') # 输出到控制台+文件
函数参数解包(Unpacking)机制
✅ 定义:
“解包”是指把一个集合类对象(如元组、列表、字典)中的元素拆分成多个独立值,或者反过来,把多个值打包成一个集合。
它本质上是“展开”或“收集”的过程。
✅ 举个例子理解
# 解包:把列表的元素拆开
a, b, c = [1, 2, 3]
print(a) # 输出 1
这里就是“解包”—— 把 [1,2,3] 解包成三个变量。
对应地,也有“打包”:
# 打包:把多个值合并为一个元组
x = 1, 2, 3
print(x) # (1, 2, 3)
1️⃣ *args 是什么?怎么用?
✅ 定义:*args 是一个可变位置参数(positional arguments),用于接收任意数量的位置参数,并将其打包成一个 元组。
“args” 是任意命名(比如
*nums也行),但习惯叫*args
✅ 示例
def sum_all(*args):
return sum(args)
print(sum_all(1, 2, 3)) # 6
print(sum_all(10, 20)) # 30
print(sum_all()) # 0 (空元组)
📌 关键点:
*args接收的是位置参数- 参数会被自动打包成一个 元组(tuple)
✅ 更灵活的使用方式
def greet(name, *messages):
print(f"Hello {name}!")
for msg in messages:
print(msg)
greet("Alice", "How are you?", "Nice to meet you!")
# 输出:
# Hello Alice!
# How are you?
# Nice to meet you!
2️⃣ **kwargs 是什么?怎么用?
✅ 定义:**kwargs 是一个可变关键字参数(keyword arguments),用于接收任意数量的关键字参数,并将其打包成一个 字典。
“kwargs” 是 “keyword arguments” 的缩写(也可以叫
**other)
✅ 示例
def print_info(**kwargs):
for key, value in kwargs.items():
print(f"{key}: {value}")
print_info(name="Bob", age=25, city="Beijing")
# 输出:
# name: Bob
# age: 25
# city: Beijing
📌 关键点:
**kwargs接收的是带名字的参数(如name="Alice")- 被打包成一个字典(dict)
✅ 结合 *args 和 **kwargs
def func(*args, **kwargs):
print("Positional args:", args)
print("Keyword args:", kwargs)
func(1, 2, 3, name="Alice", age=30)
# 输出:
# Positional args: (1, 2, 3)
# Keyword args: {'name': 'Alice', 'age': 30}
3️⃣ 其他形式的“解包”语法
除了函数参数里的 *args 和 **kwargs作为打包,Python 还支持在赋值和调用时进行解包!
✅ 1. 函数调用时的解包(星号解包)
🟢 *:解包可迭代对象(如列表、元组)作为位置参数
def add(a, b, c):
return a + b + c
nums = [1, 2, 3]
result = add(*nums) # 相当于 add(1, 2, 3)
print(result) # 6
🟢 **:解包字典作为关键字参数
def greet(name, age):
print(f"{name} is {age} years old")
info = {"name": "Alice", "age": 25}
greet(**info) # 相当于 greet(name="Alice", age=25)
✅ 2. 赋值时的解包(增强版 unpacking)
🟢 解包列表/元组到多个变量
a, b, c = [1, 2, 3]
print(a, b, c) # 1 2 3
# 可以用 * 收集剩余部分
first, *rest = [1, 2, 3, 4, 5]
print(first) # 1
print(rest) # [2, 3, 4, 5]
🟢 在循环中解包
pairs = [(1, "a"), (2, "b"), (3, "c")]
for num, letter in pairs:
print(num, letter)
✅ 3. 字典解包(**)
data = {"name": "Alice", "age": 25}
new_data = {"city": "Beijing", **data}
print(new_data) # {'city': 'Beijing', 'name': 'Alice', 'age': 25}
👉 就像“拼接”两个字典,用 ** 解包原字典
✅ 4. * 与 ** 在函数定义中的作用总结
| 符号 | 用途 | 说明 |
|---|---|---|
*args |
接收任意位置参数 | 包装成元组 |
**kwargs |
接收任意关键字参数 | 包装成字典 |
* |
解包列表/元组 | 传递为多个位置参数 |
** |
解包字典 | 传递为多个关键字参数 |
4️⃣ 终极总结图
┌───────────────┐
│ 解包 (Unpack) │
└───────────────┘
▲
┌─────────────┐
│ 打包 (Pack)│
└─────────────┘
↓ ↑
┌─────────────────┐ ┌─────────────────┐
│ *args → tuple │ │ list/tuple → * │
└─────────────────┘ └─────────────────┘
↓ ↑
┌─────────────────┐ ┌─────────────────┐
│ **kwargs → dict │ │ dict → ** │
└─────────────────┘ └─────────────────┘
魔法方法
is 和 == 的区别
- is 表示的是对象标示符(object identity),而 == 表示的是相等(equality)
- is 的作用是用来检查对象的标示符是否一致,也就是比较两个对象在内存中的地址是否一样
- 我们在检查 a is b 的时候,其实相当于检查
id(a) == id(b)
- 我们在检查 a is b 的时候,其实相当于检查
==是用来检查两个对象是否相等- 检查
a == b的时候,实际是调用了对象 a 的 eq() 方法,a == b 相当于a.__eq__(b) - 和
java的是相反的,java中==是判断内存当中的地址的,但是pyhton中的是判断内容了,is才是判断地址了
- 检查
- 一般情况下,如果
a is b返回True的话,即 a 和 b 指向同一块内存地址的话,a == b也返回True,即 a 和 b 的值也相等
连接数据库
🔹 一、Python 连接数据库的通用流程
- 安装数据库驱动(Driver)
- 创建连接对象(Connection)
- 创建游标对象(Cursor)
- 执行 SQL 语句(查询/插入/更新等
- 提交事务(如果需要)
- 关闭连接
✅ 案例 1:使用 sqlite3(小型内置模块,无需安装)
SQLite 是轻量级数据库,适合学习和小型项目。
📦 步骤 1:导入模块
import sqlite3
📦 步骤 2:建立连接(会自动创建文件)
# 连接到 SQLite 数据库(如果不存在则创建)
conn = sqlite3.connect('example.db')
📦 步骤 3:创建游标
cursor = conn.cursor()
📦 步骤 4:执行 SQL(建表)
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
age INTEGER
)
''')
📦 步骤 5:插入数据
cursor.execute("INSERT INTO users (name, age) VALUES (?, ?)", ('Alice', 25))
cursor.execute("INSERT INTO users (name, age) VALUES (?, ?)", ('Bob', 30))
使用
?占位符防止 SQL 注入!
📦 步骤 6:提交事务
conn.commit()
📦 步骤 7:查询数据
cursor.execute("SELECT * FROM users")
rows = cursor.fetchall()
for row in rows:
print(row)
📁 最终输出:
(1, 'Alice', 25)
(2, 'Bob', 30)
📦 步骤 8:关闭连接
cursor.close()
conn.close()
✅ 案例 2:连接 MySQL(需要安装驱动)
MySQL 更适合生产环境。
📦 步骤 1:安装驱动
pip install mysql-connector-python # 或者 PyMySQL
推荐:
mysql-connector-python是官方驱动
替代:PyMySQL更轻量,兼容性好
📦 步骤 2:连接 MySQL
import mysql.connector
# 连接参数(根据你的 MySQL 配置修改)
config = {
'host': 'localhost',
'user': 'root',
'password': 'your_password',
'database': 'test_db'
}
try:
conn = mysql.connector.connect(**config)
cursor = conn.cursor()
# 创建表
cursor.execute('''
CREATE TABLE IF NOT EXISTS employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
salary INT
)
''')
# 插入数据
cursor.execute("INSERT INTO employees (name, salary) VALUES (%s, %s)", ('John', 5000))
cursor.execute("INSERT INTO employees (name, salary) VALUES (%s, %s)", ('Jane', 6000))
# 提交
conn.commit()
# 查询
cursor.execute("SELECT * FROM employees")
rows = cursor.fetchall()
for row in rows:
print(row)
except mysql.connector.Error as err:
print(f"Error: {err}")
finally:
if conn.is_connected():
cursor.close()
conn.close()
✅ 注意事项(MySQL)
- 确保 MySQL 服务正在运行
- 账号有权限访问数据库
- 如果没安装
mysql-connector-python,请先安装 - 使用
%s占位符防注入
✅ 案例 3:使用 PyMySQL(替代方案)
pip install PyMySQL
import pymysql
conn = pymysql.connect(
host='localhost',
user='root',
password='your_password',
database='test_db',
charset='utf8mb4'
)
cursor = conn.cursor()
cursor.execute("CREATE TABLE IF NOT EXISTS products (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), price FLOAT)")
cursor.execute("INSERT INTO products (name, price) VALUES (%s, %s)", ('Laptop', 999.99))
conn.commit()
cursor.execute("SELECT * FROM products")
print(cursor.fetchall())
cursor.close()
conn.close()
✅ 案例 4:连接 PostgreSQL(使用 psycopg2)
pip install psycopg2-binary
import psycopg2
conn = psycopg2.connect(
host="localhost",
database="mydb",
user="postgres",
password="password"
)
cursor = conn.cursor()
cursor.execute("CREATE TABLE IF NOT EXISTS books (id SERIAL PRIMARY KEY, title VARCHAR(100))")
cursor.execute("INSERT INTO books (title) VALUES (%s)", ['The Great Gatsby'])
conn.commit()
cursor.execute("SELECT * FROM books")
print(cursor.fetchall())
cursor.close()
conn.close()
✅ 案例 5:连接 MongoDB(使用 pymongo)
MongoDB 是 NoSQL 数据库,适合 JSON 格式存储。
pip install pymongo
from pymongo import MongoClient
# 连接本地 MongoDB
client = MongoClient('mongodb://localhost:27017/')
db = client['testdb']
collection = db['users']
# 插入文档
user = {"name": "Charlie", "age": 28}
collection.insert_one(user)
# 查询
result = collection.find_one({"name": "Charlie"})
print(result)
🔹 二、重要概念总结
| 技术 | 类型 | 特点 |
|---|---|---|
sqlite3 |
内置 | 不用安装,适合学习和小项目 |
mysql-connector-python |
官方驱动 | 功能完整,稳定 |
PyMySQL |
第三方 | 轻量,纯 Python 实现 |
psycopg2 |
PostgreSQL | 最佳选择 |
pymongo |
MongoDB | 支持文档型数据库 |
🔹 三、最佳实践建议
- ✅ 使用 参数化查询(
?或%s)防止 SQL 注入 - ✅ 始终使用
try-except-finally捕获错误并关闭连接 - ✅ 使用 上下文管理器 自动关闭连接(推荐!)
import sqlite3
with sqlite3.connect('example.db') as conn:
cursor = conn.cursor()
cursor.execute("SELECT * FROM users")
rows = cursor.fetchall()
# 自动提交和关闭
🔹 四、进阶技巧
✅ 1. 使用 ORM(对象关系映射)
比如 SQLAlchemy 或 Django ORM,可以更方便地操作数据库。
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(50))
engine = create_engine('sqlite:///example.db')
Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)
session = Session()
# 添加用户
user = User(name='Alice')
session.add(user)
session.commit()
# 查询
users = session.query(User).all()
🔹 五、常见错误 & 解决方案
| 错误 | 原因 | 解决方法 |
|---|---|---|
ModuleNotFoundError: No module named 'mysql.connector' |
没安装驱动 | pip install mysql-connector-python |
OperationalError: (2003, "Can't connect to MySQL server") |
主机或端口错 | 检查 host, port, user, pwd |
ProgrammingError: You have an error in your SQL syntax |
SQL 语法错误 | 检查引号、括号、字段名 |
TypeError: can't concat str to bytes |
编码问题 | 加 charset='utf8mb4'(MySQL) |
可视化插件——❤️
Web 应用开发入门对比——Flask & Django
✅ Flask —— 轻量、灵活、适合初学者和小型项目
✅ Django —— 全功能、大而全、适合中大型项目
🔹 一、Python Web 开发基本流程(通用)
- 安装 Python 和虚拟环境
- 安装 Web 框架(Flask 或 Django)
- 创建项目结构
- 编写视图函数(View)或路由(Route)
- 设计模板(HTML)或返回 JSON
- 启动服务器,测试访问
✅ 案例 1:用 Flask 开发一个简单的 Web 应用
📦 步骤 1:安装 Flask
pip install flask
📦 步骤 2:创建一个文件 app.py
from flask import Flask, render_template, request
# 创建 Flask 应用实例
app = Flask(__name__)
# 路由:访问根路径 / 显示欢迎页面
@app.route('/')
def home():
return "<h1>Hello from Flask!</h1>"
# 路由:显示一个 HTML 页面
@app.route('/hello/<name>')
def greet(name):
return f"<h1>Hello, {name}!</h1>"
# 路由:处理表单提交
@app.route('/form', methods=['GET', 'POST'])
def form():
if request.method == 'POST':
name = request.form['name']
return f"Hello, {name}! Your form was submitted."
return '''
<form method="post">
Name: <input type="text" name="name"><br>
<input type="submit" value="Submit">
</form>
'''
# 路由:渲染 HTML 模板
@app.route('/template')
def show_template():
return render_template('index.html')
if __name__ == '__main__':
app.run(debug=True)
📦 步骤 3:创建模板目录 templates/,并添加 index.html
project/
├── app.py
└── templates/
└── index.html
<!-- templates/index.html -->
<!DOCTYPE html>
<html>
<head>
<title>Flask Template</title>
</head>
<body>
<h1>Welcome to Flask!</h1>
<p>This is a dynamic page.</p>
</body>
</html>
📦 步骤 4:运行应用
python app.py
访问:
http://localhost:5000/http://localhost:5000/hello/Alicehttp://localhost:5000/form
✅ 案例 2:用 Django 开发一个简单的 Web 应用
📦 步骤 1:安装 Django
pip install django
📦 步骤 2:创建项目(注意不是应用)
django-admin startproject myproject
cd myproject
这会生成结构:
myproject/
├── manage.py
└── myproject/
├── __init__.py
├── settings.py
├── urls.py
└── wsgi.py
📦 步骤 3:创建第一个应用
python manage.py startapp myapp
更新 myproject/settings.py,加入应用:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'myapp', # 添加你的应用
]
📦 步骤 4:创建视图(View)
编辑 myapp/views.py
from django.shortcuts import render
from django.http import HttpResponse
def home(request):
return HttpResponse("<h1>Hello from Django!</h1>")
def greet(request, name):
return HttpResponse(f"<h1>Hello, {name}!</h1>")
def form(request):
if request.method == 'POST':
name = request.POST['name']
return HttpResponse(f"Hello, {name}! Form submitted.")
return """
<form method="post">
Name: <input type="text" name="name"><br>
<input type="submit" value="Submit">
</form>
"""
📦 步骤 5:配置 URL 路由
编辑 myapp/urls.py
from django.urls import path
from . import views
urlpatterns = [
path('', views.home, name='home'),
path('hello/<str:name>/', views.greet, name='greet'),
path('form/', views.form, name='form'),
]
然后在 myproject/urls.py 中包含它:项目中包含应用
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('myapp.urls')), # 包含 myapp 的路由
]
📦 步骤 6:创建模板目录(可选)
创建 myapp/templates/,然后在 myproject/settings.py 中设置模板路径:
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [BASE_DIR / 'myapp/templates'], # 添加模板路径
'APP_DIRS': True,
...
},
]
创建 myapp/templates/index.html:
<!-- templates/index.html -->
<!DOCTYPE html>
<html>
<head>
<title>Django Template</title>
</head>
<body>
<h1>Welcome to Django!</h1>
</body>
</html>
📦 步骤 7:运行开发服务器
python manage.py runserver
访问:
http://localhost:8000/http://localhost:8000/hello/Alice/http://localhost:8000/form/
🔍 对比 Flask vs Django
| 特性 | Flask | Django |
|---|---|---|
| 类型 | 微框架(Micro Framework) | 全栈框架(Full Stack) |
| 灵活性 | 高,自由度强 | 低,有固定结构 |
| 学习曲线 | 简单,适合新手 | 较陡,但功能强大 |
| 内建功能 | 基本路由 + 模板 | ORM、Admin、Auth、Session、CSRF 等 |
| 是否需要额外库 | 是(需手动添加) | 否(自带) |
| 适合场景 | 小型 API、工具类服务 | 大型网站、博客、电商等 |
🔧 常见扩展技巧
✅ 1. 返回 JSON(前后端分离必备)
Flask 示例:
from flask import jsonify
@app.route('/api/users')
def api_users():
users = [{"id": 1, "name": "Alice"}, {"id": 2, "name": "Bob"}]
return jsonify(users)
Django 示例:
from django.http import JsonResponse
def api_users(request):
users = [{"id": 1, "name": "Alice"}, {"id": 2, "name": "Bob"}]
return JsonResponse(users, safe=False)
✅ 2. 使用数据库(以 SQLite 为例)
Flask + SQLAlchemy
pip install flask-sqlalchemy
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///app.db'
db = SQLAlchemy(app)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50), nullable=False)
# 创建表
with app.app_context():
db.create_all()
Django 自带 ORM
# myapp/models.py
from django.db import models
class User(models.Model):
name = models.CharField(max_length=50)
然后执行迁移:
python manage.py makemigrations
python manage.py migrate
✅ 3. 动态模板展示数据
Flask 示例:
@app.route('/users')
def users():
users = ['Alice', 'Bob', 'Charlie']
return render_template('users.html', users=users)
模板 users.html:
<h1>Users</h1>
<ul>
{% for user in users %}
<li>{{ user }}</li>
{% endfor %}
</ul>
Django 示例类似(使用 {{ }} 和 {% %})
🎯 总结 & 建议

| 目标 | 推荐工具 |
|---|---|
| 快速学 Web 开发 | ✅ Flask |
| 构建复杂网站 | ✅ Django |
| 开发 REST API | ✅ Flask + Marshmallow / Django REST Framework |
| 数据分析 + Web 展示 | ✅ Flask + Plotly / Dash |
💡 一句话口诀记忆
- Flask:轻巧灵活,像“乐高积木”一样拼接功能
- Django:功能齐全,像“一体化厨房”直接开火做饭
- Web 开发三步走:路由 → 视图 → 模板/JSON
- 安全第一:防止 SQL 注入、XSS、CSRF

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)