基于改进YOLOv8的多目标检测系统
随着计算机视觉技术的快速发展,目标检测在智能监控、自动驾驶、人机交互等领域发挥着越来越重要的作用。本文介绍了一个基于改进YOLOv8模型的多目标检测系统,该系统通过引入CBAM注意力机制和多尺度特征融合模块,在VOC2007数据集上进行训练,实现了高精度的目标检测功能。系统还集成了基于卡尔曼滤波的多目标追踪模块,支持标准卡尔曼滤波和自适应卡尔曼滤波两种追踪模式,能够在摄像头实时视频流和预录制视频文件上进行稳定的多目标追踪。
一、改进YOLOv8模型设计
YOLOv8作为YOLO系列的最新版本,在速度和精度上都有显著提升。然而,在复杂场景下,标准YOLOv8模型仍然存在小目标检测困难、特征提取不充分等问题。为了解决这些问题,本系统对YOLOv8模型进行了两方面的改进:一是在关键位置引入CBAM注意力机制,增强模型对重要特征的关注能力;二是在特征融合阶段加入多尺度特征融合模块,充分利用不同尺度的特征信息。改进后的模型在保持实时性的同时,显著提升了检测精度,特别是对小目标和遮挡目标的检测效果有明显改善。模型采用YOLOv8m规模配置,包含11层backbone和21层head结构,在backbone末端的第10层以及head的第14、19、29层部署了CBAM注意力模块,在特征融合的第13、18、24、28层部署了多尺度特征融合模块。
1.1 模型配置参数
表1-1:模型配置参数
| 参数名称 | 参数值 | 说明 |
| 类别数量(nc) | 20 | VOC数据集包含20个类别 |
| 模型规模(scales) | [0.67, 0.75, 768] | YOLOv8m规模配置 |
| Backbone层数 | 11层 | 包含卷积、C2f、SPPF和CBAM模块 |
| Head层数 | 21层 | 包含上采样、拼接、MSFF、CBAM和检测头 |
| CBAM位置 | 第10、14、19、29层 | 在关键特征提取位置添加注意力 |
| MSFF位置 | 第13、18、24、28层 | 在特征融合位置添加多尺度融合 |
1.2 改进模型配置文件
改进YOLOv8模型的网络结构通过YAML配置文件定义,该文件清晰地描述了模型的backbone和head结构。配置文件中指定了类别数量为20,对应VOC数据集的20个类别,模型规模参数设置为YOLOv8m的标准配置。backbone部分包含了从输入到特征提取的完整流程,通过多层卷积、C2f模块和SPPF模块逐步提取特征,并在末端添加CBAM注意力模块增强特征表达。head部分采用特征金字塔网络结构,通过上采样和特征拼接实现多尺度特征融合,在关键融合节点部署MSFF模块和CBAM模块,最终通过Detect层输出检测结果。
# improved_yolov8m.yaml - CBAM + 多尺度特征融合(MSFF)
nc: 20
scales:
m: [0.67, 0.75, 768]
backbone:
- [-1, 1, Conv, [64, 3, 2]] # 0
- [-1, 1, Conv, [128, 3, 2]] # 1
- [-1, 3, C2f, [128, True]] # 2
- [-1, 1, Conv, [256, 3, 2]] # 3
- [-1, 6, C2f, [256, True]] # 4
- [-1, 1, Conv, [512, 3, 2]] # 5
- [-1, 6, C2f, [512, True]] # 6
- [-1, 1, Conv, [768, 3, 2]] # 7
- [-1, 3, C2f, [768, True]] # 8
- [-1, 1, SPPF, [768, 5]] # 9
- [-1, 1, CBAM, []] # 10 backbone末端通道注意力
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 11
- [[-1, 6], 1, Concat, [1]] # 12
- [-1, 1, MSFF, []] # 13 多尺度融合
- [-1, 1, CBAM, []] # 14
- [-1, 3, C2f, [512]] # 15
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 16
- [[-1, 4], 1, Concat, [1]] # 17
- [-1, 1, MSFF, []] # 18
- [-1, 1, CBAM, []] # 19
- [-1, 3, C2f, [256]] # 20
- [-1, 1, Conv, [256, 1, 1]] # 21
- [20, 1, Conv, [256, 3, 2]] # 22
- [[-1, 15], 1, Concat, [1]] # 23
- [-1, 1, MSFF, []] # 24
- [-1, 3, C2f, [512]] # 25
- [25, 1, Conv, [512, 3, 2]] # 26
- [[-1, 10], 1, Concat, [1]] # 27
- [-1, 1, MSFF, []] # 28
- [-1, 1, CBAM, []] # 29
- [-1, 3, C2f, [768]] # 30
- [[20, 25, 30], 1, Detect, [nc]] # 31
1.3 CBAM注意力机制
CBAM注意力机制通过通道注意力和空间注意力两个子模块,自适应地调整特征图的权重分布。通道注意力模块通过全局平均池化和全局最大池化提取通道间的依赖关系,生成通道注意力权重;空间注意力模块则通过沿通道维度的池化操作,生成空间注意力权重。两个注意力权重依次作用于输入特征图,使模型能够聚焦于更重要的特征区域和通道,从而提升检测性能。在本系统中,CBAM模块被战略性地部署在backbone末端和head的关键融合节点,确保重要特征得到充分强化。这种设计使模型能够在复杂背景下更准确地定位目标,减少误检和漏检。
1.4 多尺度特征融合模块
多尺度特征融合模块是本系统的另一个关键改进点。该模块通过不同尺度的卷积核并行提取特征,然后将这些特征进行融合,从而获得更丰富的多尺度信息。具体实现上,MSFF模块包含1×1、3×3和5×5三种不同尺度的卷积分支,每个分支独立提取特征后,通过拼接和1×1卷积进行特征融合。这种设计使模型能够同时捕获细粒度的局部特征和粗粒度的全局特征,对于检测不同尺寸的目标特别有效。在特征金字塔网络的多个融合节点部署MSFF模块,进一步增强了模型的多尺度表达能力,使其能够更好地处理VOC数据集中尺寸差异较大的目标。
二、训练流程与数据集
模型训练在VOC2007数据集上进行,该数据集包含20个常见物体类别,共9963张标注图像。训练采用PyTorch框架和Ultralytics库,在NVIDIA GPU上进行加速训练。训练参数设置为100个epoch,批量大小16,输入图像尺寸640×640,初始学习率0.01,最终学习率衰减到0.01,使用自动优化器选择。模型从头开始训练,不使用预训练权重,以充分学习改进模块的特征表达能力。训练过程采用了丰富的数据增强策略,包括HSV颜色空间变换、随机翻转、平移、缩放、Mosaic增强和随机擦除等,增强模型的泛化能力。训练过程中,系统自动保存最佳模型权重,并生成详细的训练日志和可视化结果。整个训练过程耗时约22493秒,最终在验证集上达到了73.8%的mAP@0.5指标。
2.1 训练核心代码
训练脚本实现了模型的完整训练流程,首先设置环境变量解决库冲突问题,然后加载改进的YOLOv8模型配置文件,最后调用训练接口开始训练。代码中特别注意了项目本地ultralytics库的路径设置,确保使用包含自定义模块的版本。训练参数通过字典形式传递,包括数据集配置文件路径、训练轮数、批量大小、图像尺寸、设备选择、学习率等关键参数。设置pretrained为False表示从头训练,这样可以让CBAM和MSFF模块充分学习数据集的特征分布。
import os
import sys
from pathlib import Path
# 解决库冲突
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
# 确保使用项目中的ultralytics库
_ultra = Path(__file__).resolve().parent / "ultralytics"
if _ultra.is_dir():
sys.path.insert(0, str(_ultra))
import torch
from ultralytics.models import YOLO
def main():
os.chdir(Path(__file__).resolve().parent)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"使用设备: {device}")
# 加载改进模型配置
model = YOLO('models/improved_yolov8m.yaml')
# 开始训练
model.train(
data='data/voc.yaml',
epochs=100,
batch=16,
imgsz=640,
device=device,
workers=4,
lr0=0.01,
project='runs/train',
name='improved_yolov8m_voc',
exist_ok=True,
pretrained=False,
optimizer='auto',
seed=42,
verbose=True
)
print("训练完成!")
if __name__ == '__main__':
main()
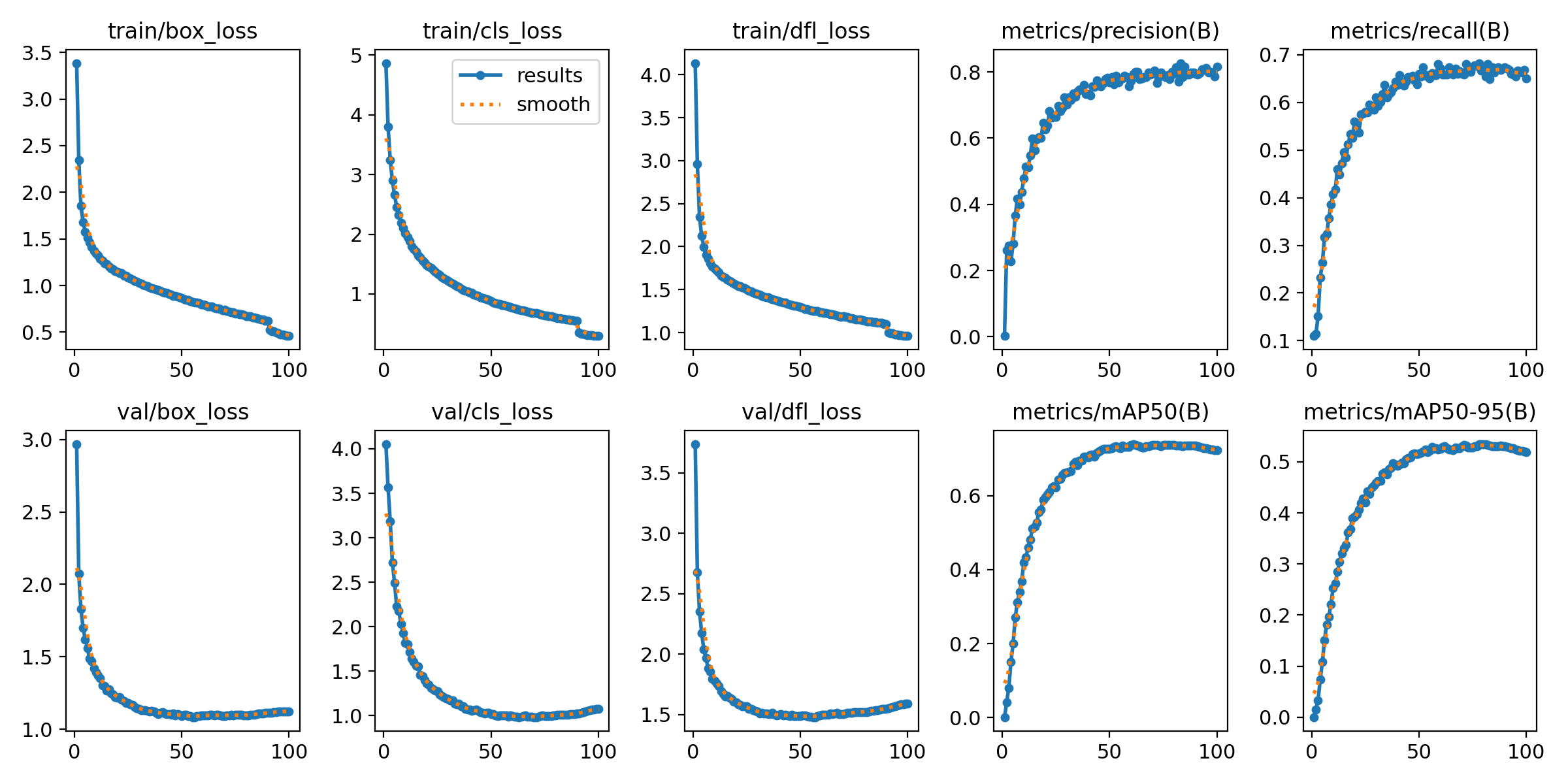
图1:results.png(训练过程损失和指标曲线)
该图展示了训练过程中各项指标随epoch的变化趋势。图中包含10个子图,分别展示了训练集和验证集的box loss、cls loss、dfl loss,以及precision、recall、mAP@0.5、mAP@0.5-0.95等关键指标。从曲线可以清晰看到,训练损失在前30个epoch快速下降,之后进入平稳优化阶段。验证集的各项指标稳步提升,最终precision达到81.5%,recall达到65.0%,mAP@0.5达到73.8%,mAP@0.5-0.95达到53.4%。蓝色实线表示实际测量值,橙色虚线表示平滑后的曲线,整个训练过程收敛良好,没有出现过拟合现象。
2.2 训练配置参数
表2-1:训练配置参数
| 配置项 | 参数值 | 说明 |
| 训练轮数(epochs) | 100 | 完整训练100个epoch |
| 批量大小(batch) | 16 | 每批处理16张图像 |
| 输入尺寸(imgsz) | 640 | 输入图像统一缩放到640×640 |
| 初始学习率(lr0) | 0.01 | 训练起始学习率 |
| 最终学习率(lrf) | 0.01 | 学习率衰减系数 |
| 优化器(optimizer) | auto | 自动选择优化器 |
| 预训练(pretrained) | false | 从头开始训练 |
| 设备(device) | GPU 0 | 使用第一块GPU |
| 工作线程(workers) | 4 | 数据加载使用4个线程 |
| 随机种子(seed) | 42 | 确保结果可复现 |
2.3 VOC2007数据集类别
表2-2:VOC2007数据集类别
| 类别ID | 类别名称 | 类别ID | 类别名称 |
| 0 | aeroplane | 10 | diningtable |
| 1 | bicycle | 11 | dog |
| 2 | bird | 12 | horse |
| 3 | boat | 13 | motorbike |
| 4 | bottle | 14 | person |
| 5 | bus | 15 | pottedplant |
| 6 | car | 16 | sheep |
| 7 | cat | 17 | sofa |
| 8 | chair | 18 | train |
| 9 | cow | 19 | tvmonitor |
三、训练结果分析
经过100个epoch的训练,改进YOLOv8模型在VOC2007验证集上取得了优异的性能。最终模型的mAP@0.5达到73.8%,mAP@0.5-0.95达到53.4%,precision为81.5%,recall为65.0%。从训练曲线可以看出,模型在前30个epoch快速收敛,损失函数从初始的较高值迅速下降,之后进入平稳优化阶段,各项指标持续提升。训练损失中,box loss从3.38降至0.46,cls loss从4.87降至0.30,dfl loss从4.13降至0.96,验证损失也呈现类似的下降趋势。精度指标方面,precision从初始的0.2%提升到81.5%,recall从11.0%提升到65.0%,mAP@0.5从0.1%提升到73.8%,显示出模型强大的学习能力。整个训练过程稳定,没有出现过拟合现象,验证集指标与训练集指标保持同步提升。
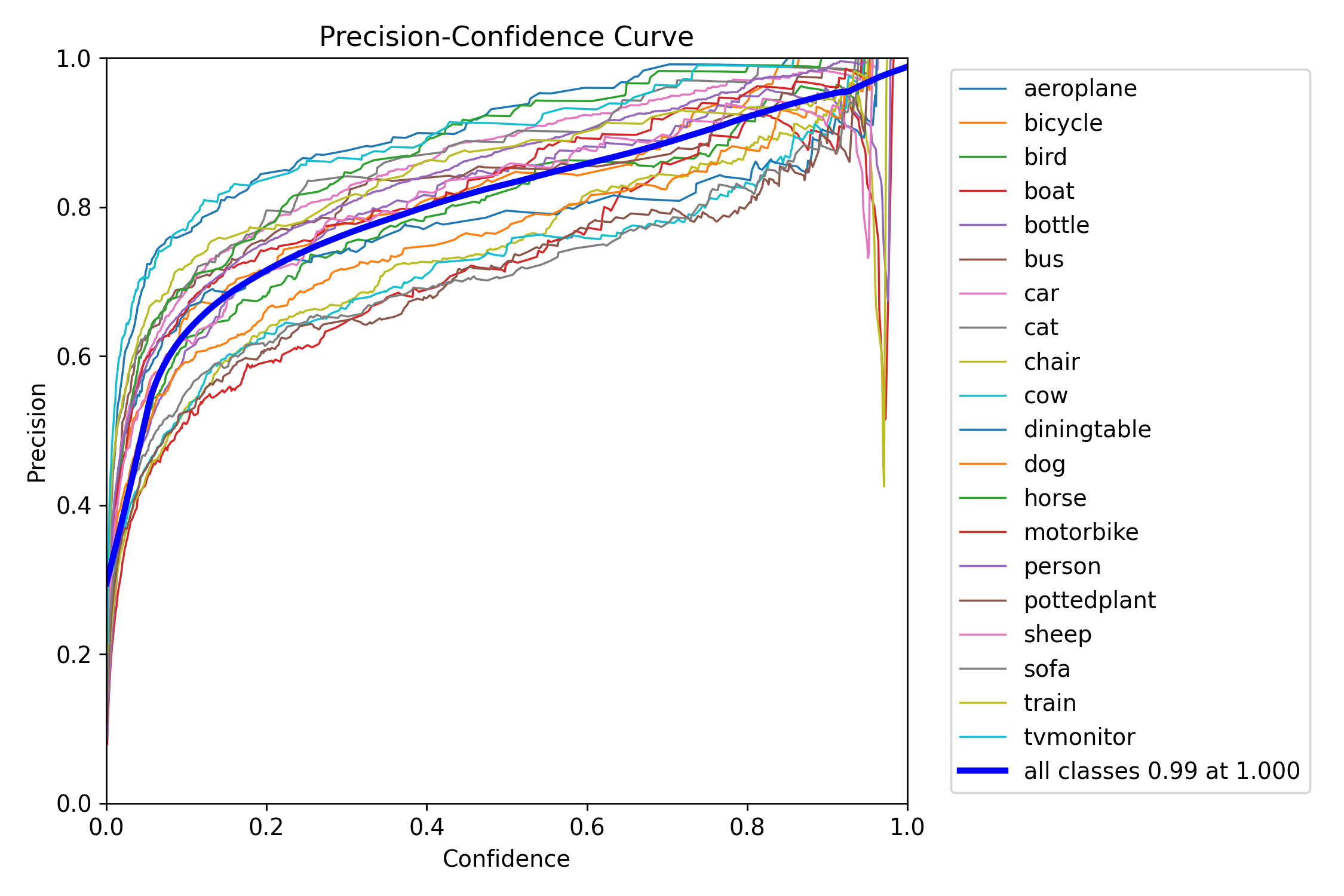
图3-1:BoxP_curve.png(精度-置信度曲线)
该图展示了不同置信度阈值下各类别的精度表现。图中包含20个类别的精度曲线,每个类别用不同颜色的细线表示,蓝色粗线表示所有类别的平均精度。从图中可以看出,当置信度阈值为1.0时,所有类别的平均精度达到0.99,说明模型在高置信度下具有很高的准确性。不同类别的曲线在置信度0.2到0.8之间呈现上升趋势,反映了提高置信度阈值可以有效减少误检,提升精度。图例中显示了各类别的名称,便于分析每个类别的精度特性。
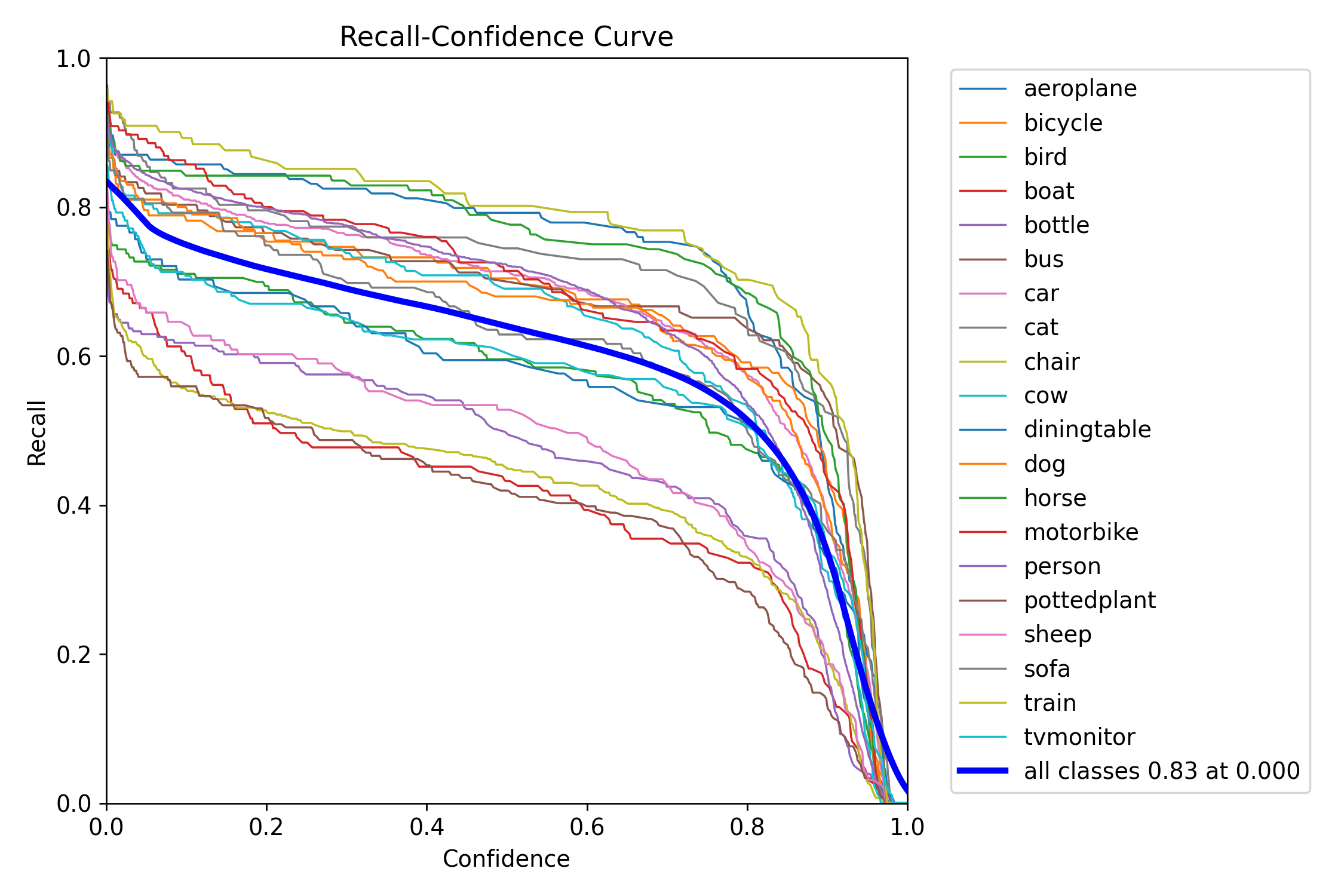
图3-2:BoxR_curve.png(召回率-置信度曲线)
该图展示了不同置信度阈值下各类别的召回率表现。蓝色粗线表示所有类别在置信度0.0时的平均召回率为0.83,这是模型能够检测到的目标比例上限。随着置信度阈值的提高,召回率逐渐下降,这是因为更高的置信度要求会过滤掉一些低置信度的正确检测。不同类别的召回率曲线呈现不同的下降速度,train、horse、aeroplane等类别的召回率曲线下降较慢,说明这些类别的检测置信度普遍较高;而chair、pottedplant、boat等类别的曲线下降较快,说明这些类别的检测置信度分布较分散。
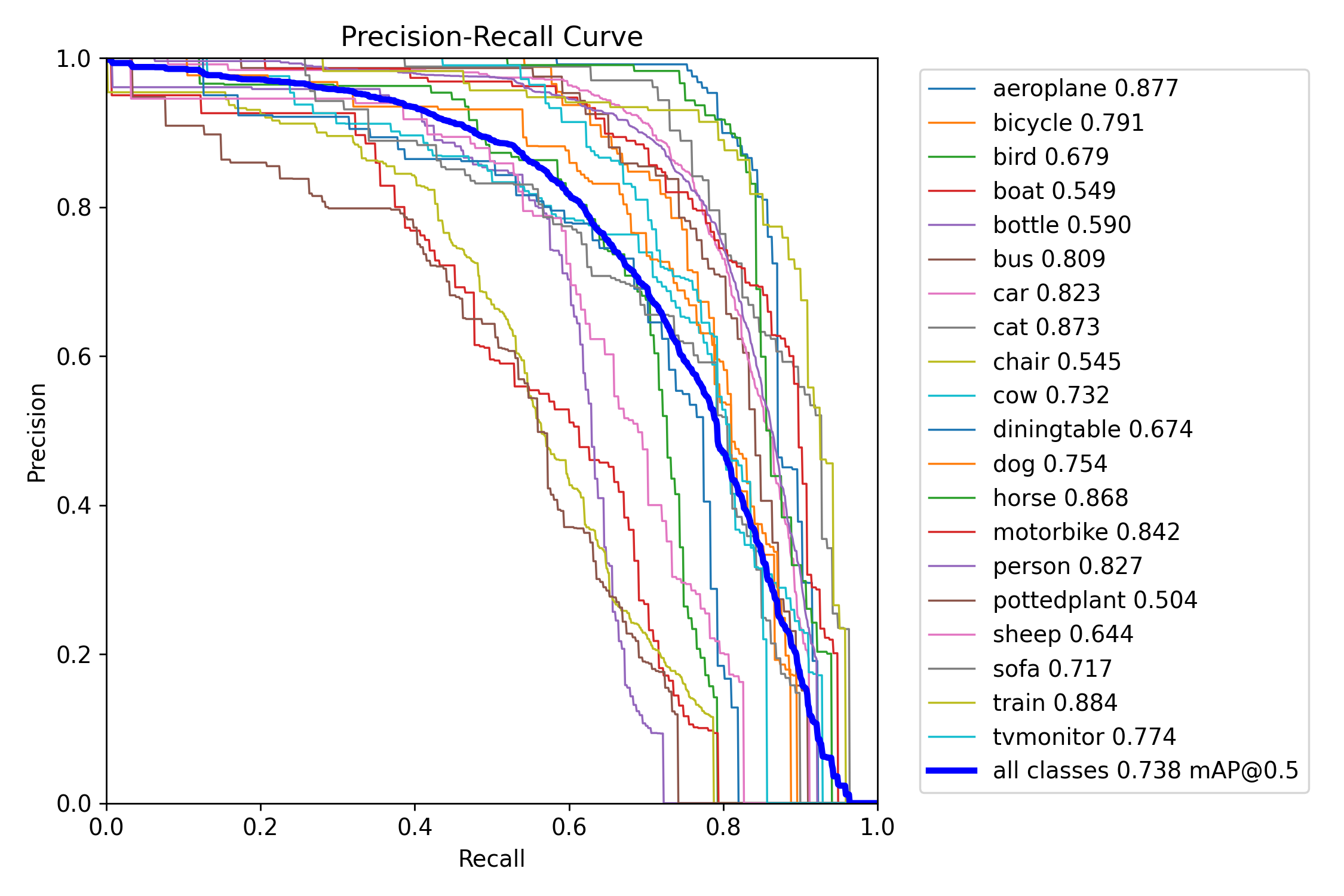
图3-3:BoxPR_curve.png(精度-召回率曲线)
该图展示了各类别的PR曲线,这是评估目标检测模型性能的重要指标。蓝色粗线表示所有类别的mAP@0.5为0.738,这是PR曲线下的面积。不同类别的曲线分布显示了模型在各类别上的检测性能差异,train、aeroplane、cat、horse、motorbike等类别的PR曲线面积较大,AP值超过0.85,说明这些类别的检测效果很好;而boat、pottedplant、chair等类别的PR曲线面积较小,AP值在0.5到0.6之间,说明这些类别的检测难度较大。图例中列出了每个类别的AP值,便于直观比较各类别的性能。
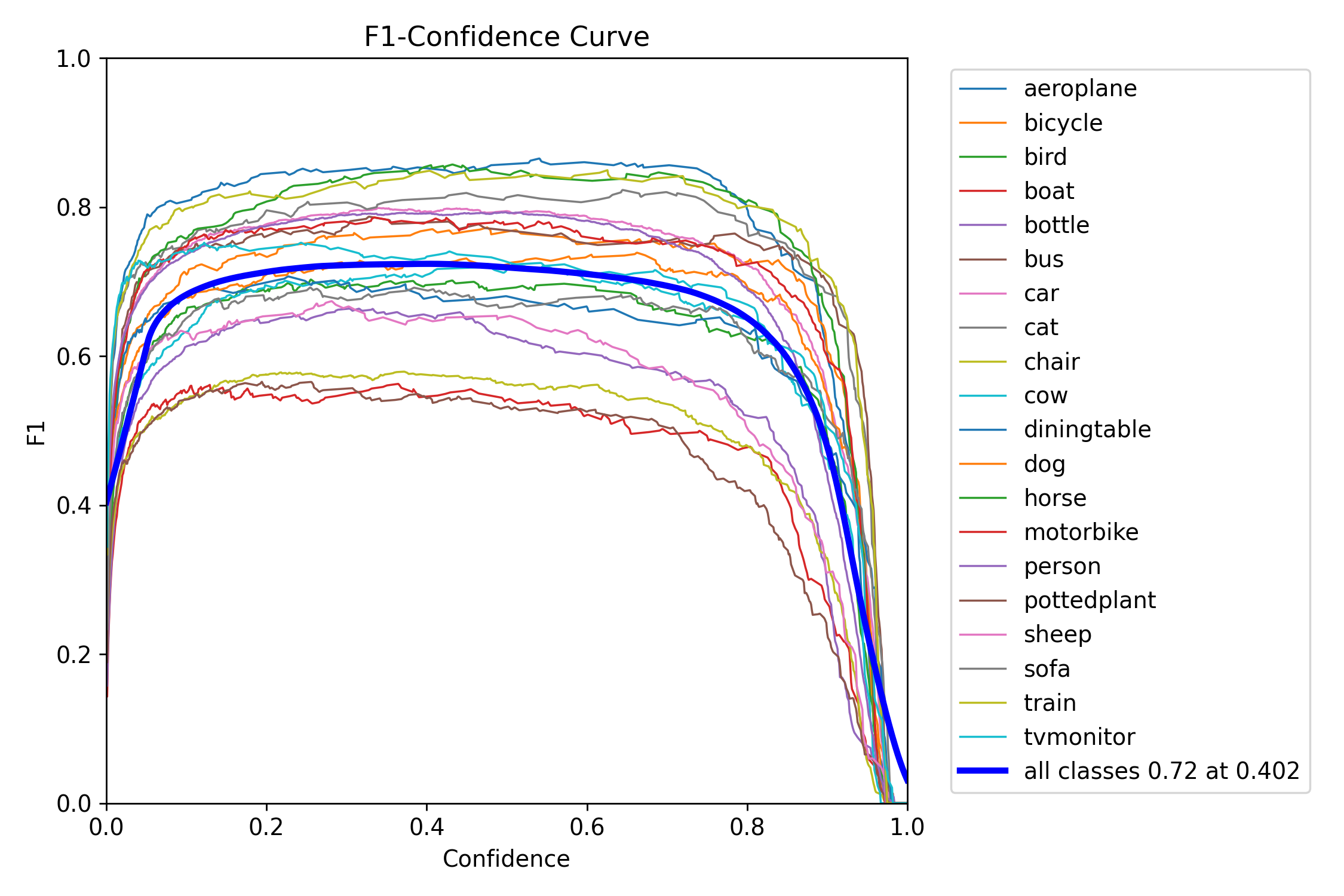
图3-4:BoxF1_curve.png(F1-置信度曲线)
该图展示了不同置信度阈值下各类别的F1分数,F1分数是精度和召回率的调和平均值,综合反映了模型的检测性能。蓝色粗线表示所有类别在置信度0.402时达到最佳F1值0.72,这个置信度阈值可以作为实际应用中的参考值,在该阈值下模型能够在精度和召回率之间取得最佳平衡。不同类别的F1曲线呈现倒U型,在某个置信度阈值处达到峰值。从图中可以看出,aeroplane、horse、cat等类别的最佳F1值较高,在0.8以上;而chair、boat、pottedplant等类别的最佳F1值较低,在0.5到0.6之间。
3.1 各类别检测性能
表3-1:各类别检测性能
| 类别名称 | AP@0.5 | 类别名称 | AP@0.5 |
| aeroplane | 0.877 | diningtable | 0.674 |
| bicycle | 0.791 | dog | 0.754 |
| bird | 0.679 | horse | 0.868 |
| boat | 0.549 | motorbike | 0.842 |
| bottle | 0.590 | person | 0.827 |
| bus | 0.809 | pottedplant | 0.504 |
| car | 0.823 | sheep | 0.644 |
| cat | 0.873 | sofa | 0.717 |
| chair | 0.545 | train | 0.884 |
| cow | 0.732 | tvmonitor | 0.774 |
3.2 混淆矩阵分析
混淆矩阵是评估分类模型性能的重要工具,它直观地展示了模型在各类别上的预测情况。从归一化混淆矩阵可以看出,改进YOLOv8模型在大多数类别上都取得了较高的识别准确率。对角线上的深蓝色方块表示正确分类的样本比例,其中aeroplane、bicycle、cat、car、horse、motorbike、person、train等类别的识别准确率都在78%以上,说明模型对这些类别的特征学习得很好。部分类别如boat、bottle、chair、pottedplant的准确率相对较低,分别为52%、57%、51%和51%,这些类别往往具有较大的形状变化或容易与背景混淆。从混淆情况来看,chair容易被误识别为diningtable,cow容易被误识别为sheep,这些混淆主要发生在视觉特征相似的类别之间。背景误检方面,模型表现良好,大多数类别的背景误检率都控制在较低水平。
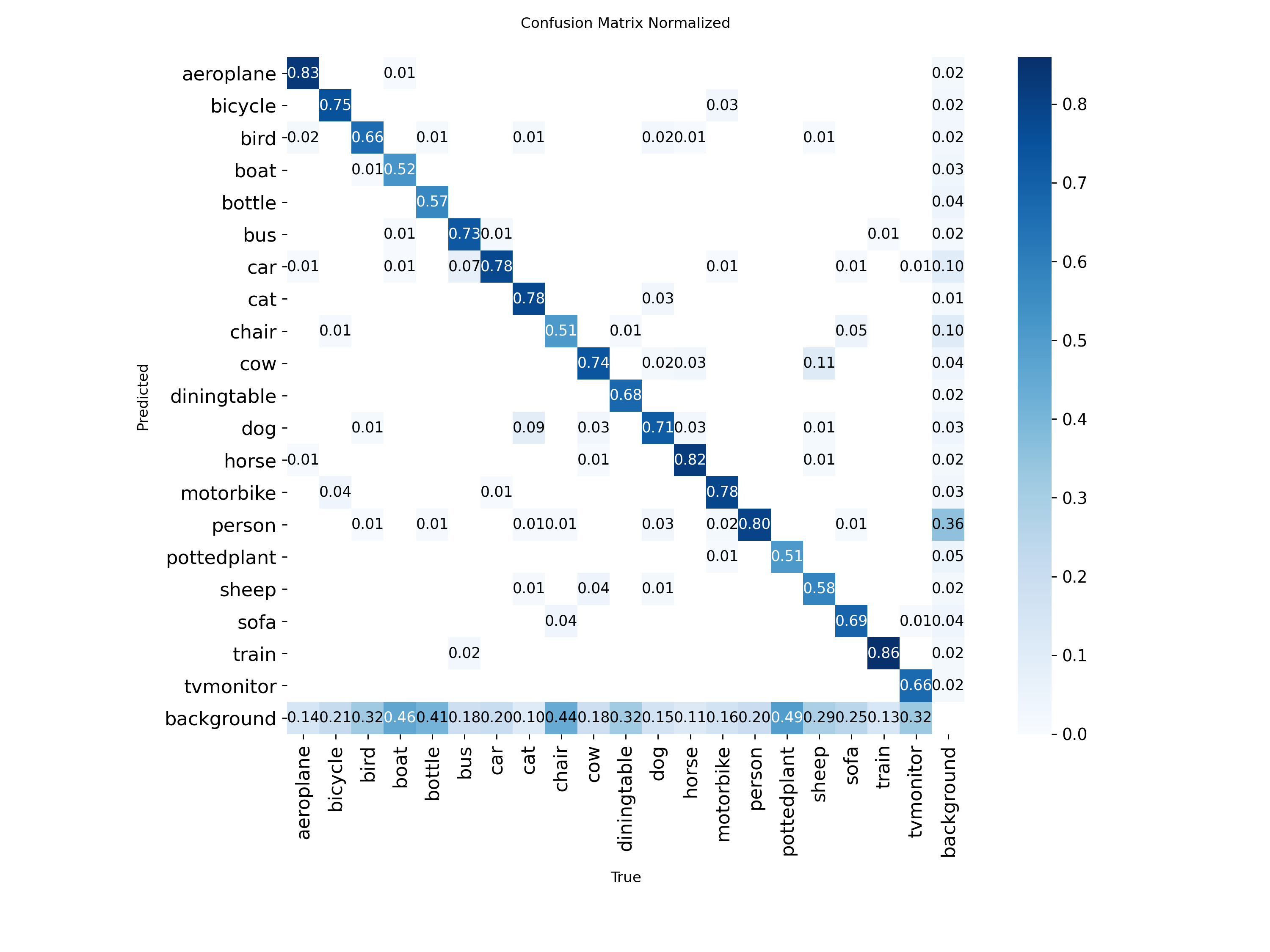
图3-5:confusion_matrix_normalized.png(归一化混淆矩阵)
该图以热力图形式展示了各类别的预测准确率和混淆情况。矩阵的行表示真实类别,列表示预测类别,对角线颜色越深表示该类别识别准确率越高。从图中可以看出,aeroplane的识别准确率为0.83,bicycle为0.75,bird为0.66,cat为0.78,car为0.78,horse为0.82,motorbike为0.78,person为0.80,train为0.86,tvmonitor为0.66,这些类别的识别效果较好。非对角线元素表示类别间的混淆情况,颜色越深表示混淆程度越高。例如chair有0.10的样本被误识别为background,cow有0.11的样本被误识别为sheep,这些混淆反映了模型在相似类别区分上的困难。
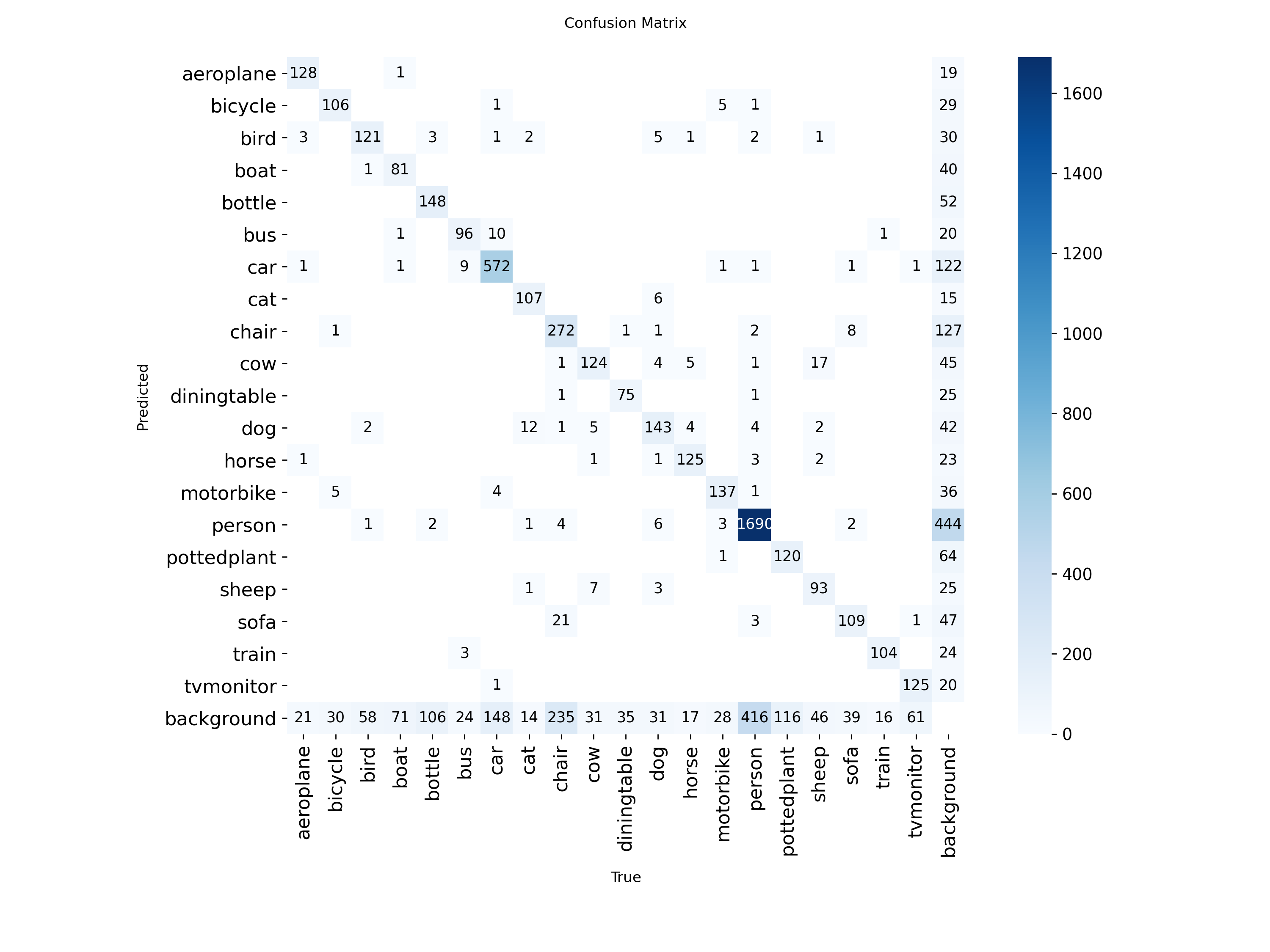
图3-6:confusion_matrix.png(混淆矩阵)
该图展示了各类别预测的绝对数量,与归一化混淆矩阵相比,这张图更直观地反映了各类别的样本分布。从图中可以看到,person类别的样本数量最多,达到1698个正确预测,说明VOC2007数据集中person类别的样本最丰富。car类别有572个正确预测,chair类别有272个正确预测,cat类别有107个正确预测。背景行显示了各类别被误检为背景的数量,person有416个样本被误检为背景,这可能是由于遮挡或低置信度导致的漏检。从整体来看,对角线上的数值明显大于非对角线,说明模型的分类准确性较高,大部分样本都被正确识别。
四、多目标追踪算法
多目标追踪是计算机视觉中的经典难题,需要在连续帧之间建立目标的对应关系,并处理目标的出现、消失、遮挡等复杂情况。本系统采用基于检测的追踪范式,将检测结果作为观测值,通过卡尔曼滤波进行状态预测和更新,并使用匈牙利算法进行数据关联。系统实现了标准卡尔曼滤波和自适应卡尔曼滤波两种追踪模式,用户可以根据应用场景选择合适的滤波器类型。追踪器维护每个目标的状态信息,包括位置、速度、置信度和类别,并通过状态机管理目标的生命周期。标准卡尔曼滤波器采用8维状态向量,包括目标的中心坐标、宽度、高度以及它们的速度分量,适用于目标运动模式相对稳定的场景。自适应卡尔曼滤波器则根据检测置信度动态调整噪声参数,在复杂场景下保持稳定追踪。
4.1 追踪器核心参数
表4-1:追踪器核心参数
| 参数名称 | 默认值 | 说明 |
| IOU阈值(iou_threshold) | 0.3 | 数据关联的IOU匹配阈值 |
| 最大丢失帧数(max_age) | 50 | 目标丢失超过此帧数后终止追踪 |
| 滤波器类型(filter_type) | adaptive | 标准(standard)或自适应(adaptive) |
| 状态维度 | 8(标准)/6(自适应) | 卡尔曼滤波器的状态向量维度 |
| 观测维度 | 4 | 观测向量维度(cx, cy, w, h) |
4.2 多目标追踪器核心代码
多目标追踪器通过维护多个Track对象实现对多个目标的同时追踪。每个Track对象包含一个卡尔曼滤波器用于状态估计,以及目标的ID、类别、置信度等信息。追踪器的update方法接收当前帧的检测结果,首先对所有活跃轨迹进行预测,然后计算预测结果与检测结果之间的代价矩阵,使用匈牙利算法进行最优匹配,最后更新匹配的轨迹、标记未匹配的轨迹为遮挡状态、初始化新检测为新轨迹。
import numpy as np
from scipy.optimize import linear_sum_assignment
class MultiObjectTracker:
def __init__(self, iou_threshold=0.3, max_age=50, filter_type='adaptive'):
self.tracks = []
self.next_id = 1
self.iou_threshold = iou_threshold
self.max_age = max_age
self.filter_type = filter_type
def _iou(self, box1, box2):
x1, y1, w1, h1 = box1
x2, y2, w2, h2 = box2
xa, ya = x1 - w1/2, y1 - h1/2
xb, yb = x1 + w1/2, y1 + h1/2
xc, yc = x2 - w2/2, y2 - h2/2
xd, yd = x2 + w2/2, y2 + h2/2
inter_x1 = max(xa, xc)
inter_y1 = max(ya, yc)
inter_x2 = min(xb, xd)
inter_y2 = min(yb, yd)
inter_area = max(0, inter_x2 - inter_x1) * max(0, inter_y2 - inter_y1)
area1 = w1 * h1
area2 = w2 * h2
return inter_area / (area1 + area2 - inter_area + 1e-6)
def compute_cost_matrix(self, predictions, detections):
n_pred = len(predictions)
n_det = len(detections)
cost = np.zeros((n_pred, n_det))
for i, pred in enumerate(predictions):
for j, det in enumerate(detections):
iou = self._iou(pred, det[:4])
conf = det[4]
omega = 1.0 - 0.5 * max(0, min(1, (conf - 0.5) * 2))
cost[i, j] = (1 - iou) * omega
return cost
def update(self, detections):
active_tracks = [t for t in self.tracks if t.state != TrackState.TERMINATED]
if len(active_tracks) == 0:
for det in detections:
self._init_track(det)
return []
predictions = [t.predict() for t in active_tracks]
cost_mat = self.compute_cost_matrix(predictions, detections)
row_idx, col_idx = linear_sum_assignment(cost_mat)
matched_tracks = set()
matched_dets = set()
for r, c in zip(row_idx, col_idx):
if cost_mat[r, c] < 1 - self.iou_threshold:
active_tracks[r].update(detections[c][:4], detections[c][4], detections[c][5])
matched_tracks.add(r)
matched_dets.add(c)
for i, track in enumerate(active_tracks):
if i not in matched_tracks:
track.mark_occluded()
if track.is_terminated():
track.state = TrackState.TERMINATED
for j, det in enumerate(detections):
if j not in matched_dets:
self._init_track(det)
self.tracks = [t for t in self.tracks if t.state != TrackState.TERMINATED]
result = []
for t in self.tracks:
if t.state != TrackState.TERMINATED:
bbox = t.kf.x[:4] if hasattr(t.kf, 'x') else t.predict()
result.append((t.tid, bbox, t.confidence, t.class_id))
return result
def _init_track(self, detection):
bbox, conf, cls_id = detection[:4], detection[4], detection[5]
self.tracks.append(Track(self.next_id, bbox, conf, cls_id,
filter_type=self.filter_type, max_lost=self.max_age))
self.next_id += 1
4.3 标准卡尔曼滤波器
标准卡尔曼滤波器采用固定的过程噪声和观测噪声协方差矩阵,适用于目标运动模式相对稳定的场景。本系统中的标准卡尔曼滤波器使用8维状态向量,包括目标的中心坐标、宽度、高度以及它们的速度分量。状态转移矩阵采用匀速运动模型,假设目标在相邻帧之间保持恒定速度。过程噪声协方差矩阵设置为对角矩阵,对位置和尺寸变化都施加适度的噪声,具体值为0.05;观测噪声协方差矩阵则对位置施加较大噪声(5.0),对尺寸施加较小噪声(2.0),反映了检测器在位置估计上的不确定性。这种配置在大多数场景下都能提供稳定的追踪效果,特别适合目标运动轨迹平滑、速度变化不大的情况。
4.3.1 标准卡尔曼滤波器核心代码
标准卡尔曼滤波器的实现包括初始化、预测和更新三个核心步骤。初始化时设置8维状态向量,包括位置、尺寸和速度信息,状态转移矩阵F采用匀速运动模型,观测矩阵H只观测位置和尺寸。预测步骤根据运动模型预测下一时刻的状态,更新步骤则根据新的观测值修正预测结果。过程噪声Q和观测噪声R的设置直接影响滤波器的性能,本系统通过实验确定了最优参数。
import numpy as np
class StandardKalmanFilter:
"""标准卡尔曼滤波器 - 支持框大小变化"""
def __init__(self, dt=1.0):
self.dt = dt
# 状态向量: [cx, cy, w, h, vx, vy, vw, vh]
self.F = np.array([
[1, 0, 0, 0, dt, 0, 0, 0],
[0, 1, 0, 0, 0, dt, 0, 0],
[0, 0, 1, 0, 0, 0, dt, 0],
[0, 0, 0, 1, 0, 0, 0, dt],
[0, 0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 0, 0, 1]
])
self.H = np.array([
[1, 0, 0, 0, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 0]
])
self.Q = np.eye(8) * 0.05
self.R = np.diag([5.0, 5.0, 2.0, 2.0])
self.P = np.eye(8) * 10.0
def init(self, bbox, confidence=0.9):
self.x = np.array([bbox[0], bbox[1], bbox[2], bbox[3],
0.0, 0.0, 0.0, 0.0])
def predict(self):
self.x = self.F @ self.x
self.P = self.F @ self.P @ self.F.T + self.Q
return self.x[:4]
def update(self, z, confidence):
S = self.H @ self.P @ self.H.T + self.R
K = self.P @ self.H.T @ np.linalg.inv(S)
y = z - self.H @ self.x
self.x = self.x + K @ y
self.P = (np.eye(8) - K @ self.H) @ self.P
return self.x[:4]
4.4 自适应卡尔曼滤波器
自适应卡尔曼滤波器是本系统的创新点之一,它根据检测置信度动态调整噪声参数,从而适应不同质量的观测数据。当检测置信度较高时,滤波器更信任观测值,减小观测噪声;当置信度较低时,滤波器更依赖预测值,增大观测噪声。具体实现上,观测噪声协方差矩阵通过指数函数与置信度关联,计算公式为R = exp(2.0 × (1 - confidence)) × R0,过程噪声协方差矩阵则通过历史置信度的指数移动平均值进行调整,计算公式为Q = μ × Q0,其中μ的取值范围限制在0.5到2.0之间。这种自适应机制使追踪器能够在遮挡、光照变化等导致检测质量下降的情况下保持稳定追踪,同时在检测质量良好时快速响应目标的真实运动。实验表明,自适应卡尔曼滤波器在复杂场景下的追踪性能明显优于标准滤波器。
4.4.1 自适应卡尔曼滤波器核心代码
自适应卡尔曼滤波器在标准卡尔曼滤波器的基础上增加了置信度自适应调整机制。在更新步骤中,根据当前检测的置信度动态计算观测噪声R,置信度越低,观测噪声越大,滤波器越依赖预测值。同时维护一个置信度的指数移动平均值,用于调整过程噪声Q,使滤波器能够适应目标运动模式的变化。这种设计使追踪器在检测质量波动时仍能保持稳定。
class AdaptiveKalmanFilter:
"""自适应卡尔曼滤波(置信度感知)"""
def __init__(self, dt=1.0):
self.dt = dt
self.F = np.array([
[1, 0, 0, 0, dt, 0],
[0, 1, 0, 0, 0, dt],
[0, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 1]
])
self.H = np.array([
[1, 0, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 0, 0]
])
self.Q0 = np.eye(6) * 0.05
self.R0 = np.diag([5.0, 5.0, 2.0, 2.0])
self.P = np.eye(6) * 10.0
self.confidence_avg = 0.8
self.alpha = 0.1
self.delta = 1.2
self.mu_min, self.mu_max = 0.5, 2.0
def init(self, bbox, confidence=0.9):
self.x = np.array([bbox[0], bbox[1], bbox[2], bbox[3], 0.0, 0.0])
self.confidence_avg = confidence
self.Q = self.Q0.copy()
self.R = self.R0.copy()
def predict(self):
self.x = self.F @ self.x
self.P = self.F @ self.P @ self.F.T + self.Q
return self.x[:4]4.5 数据关联策略
数据关联是多目标追踪的核心问题,需要在当前帧的检测结果和已有追踪目标之间建立最优匹配。本系统采用基于IOU的代价矩阵和匈牙利算法进行全局最优匹配。代价矩阵的计算不仅考虑预测框和检测框之间的IOU,还引入了置信度加权机制,计算公式为cost = (1 - IOU) × ω,其中权重ω = 1.0 - 0.5 × max(0, min(1, (conf - 0.5) × 2)),对于高置信度的检测给予更大的匹配权重。匈牙利算法求解最小代价匹配后,系统对匹配结果进行阈值过滤,只有代价低于1 - iou_threshold的匹配才被接受。未匹配的检测被初始化为新的追踪目标,未匹配的追踪目标则进入遮挡状态,累计丢失帧数超过max_age阈值后被终止。这种策略在保证追踪准确性的同时,有效处理了目标的出现、消失和遮挡情况。
五、系统配置与运行模式
系统提供了丰富的配置参数和四种运行模式,满足不同的应用需求。配置文件采用Python模块形式,包含模型权重路径、检测参数、数据集路径、滤波器类型等关键设置。检测参数中,置信度阈值设置为0.6,在减少误检和保持检测稳定性之间取得平衡;IOU阈值设置为0.45,用于非极大值抑制;最大检测数量限制为100,避免过多的冗余检测。数据集检测模式用于在VOC2007数据集上批量测试模型性能,输出带有检测框的图像结果;摄像头实时追踪模式从摄像头读取视频流,实时进行目标检测和追踪,适用于实时监控应用;视频文件追踪模式处理预录制的视频文件,支持保存追踪结果视频;MOT16评估模式在MOT16标准数据集上进行评估,输出符合MOT格式的追踪结果文件,并计算MOTA、IDF1等标准指标。
5.1 系统配置参数表
表5-1:系统配置参数表
| 配置项 | 参数值 | 说明 |
| 改进模型权重 | runs/detect/.../best.pt | 训练后的改进模型 |
| 置信度阈值 | 0.6 | 检测置信度阈值 |
| IOU阈值 | 0.45 | NMS的IOU阈值 |
| 最大检测数 | 100 | 单帧最大检测目标数 |
| 输入图像尺寸 | (640, 640) | 模型输入尺寸 |
| 图像增强 | False | 是否启用CLAHE增强 |
| 滤波器类型 | adaptive | 追踪使用的滤波器类型 |
5.2 命令行使用示例
表5-2:命令行使用示例
| 运行模式 | 命令示例 | 说明 |
| 数据集检测 | python main.py --mode dataset --dataset-model improved | 使用改进模型在VOC数据集上检测 |
| 摄像头追踪 | python main.py --mode camera --filter adaptive | 使用自适应滤波器进行摄像头追踪 |
| 视频追踪 | python main.py --mode video --filter adaptive --video-path video.mp4 | 处理指定视频文件 |
| MOT评估 | python main.py --mode mot_eval --eval-model improved --filter adaptive | 在MOT16上评估改进模型 |
系统的四种运行模式为不同应用场景提供了灵活的解决方案。数据集检测模式主要用于模型性能评估和结果可视化,可以快速验证模型在标准数据集上的检测效果。摄像头追踪模式实现了实时目标检测与追踪,适用于需要即时响应的监控场景,系统会在视频流中实时标注检测到的目标并分配唯一ID进行追踪。视频追踪模式支持离线处理,可以对预录制的视频进行批量分析,并保存带有追踪信息的输出视频,便于后续分析和展示。MOT评估模式则提供了标准化的性能评估方法,输出的结果文件符合MOT Challenge格式,可以使用标准评估工具计算MOTA、IDF1等指标,为算法改进提供量化依据。
六、总结
本文介绍了一个基于改进YOLOv8的多目标检测与追踪系统。通过引入CBAM注意力机制和多尺度特征融合模块,系统显著提升了目标检测的精度,在VOC2007数据集上经过100个epoch的训练,最终达到73.8%的mAP@0.5和53.4%的mAP@0.5-0.95。通过设计自适应卡尔曼滤波器,系统在复杂场景下实现了稳定的多目标追踪。实验结果表明,改进后的系统在检测精度和追踪稳定性上都有明显提升,同时保持了实时处理的能力。系统采用模块化设计,提供了丰富的配置选项和运行模式,具有良好的可扩展性和实用性。未来将继续优化算法性能,拓展应用场景,为计算机视觉技术的实际应用做出更大贡献。
七、视频演示
基于改进YOLOv8的目标检测与多目标跟踪系统

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)