基于深度学习的垃圾分类系统研究
目录
一、 研究目的
本研究的核心目的在于设计并实现一套高效、精准、可落地的基于深度学习的智能垃圾分类系统。随着中国“无废城市”建设和“双碳”目标的持续推进,传统依赖人工判断的垃圾分类方式暴露出效率低下、标准不一、成本高昂等诸多弊端。本研究旨在通过引入前沿的人工智能技术,特别是深度卷积神经网络(CNN)模型,来攻克这些难题。具体目的包括:首先,致力于研发一个高精度的垃圾图像识别模型。通过收集和构建大规模、多场景的垃圾图像数据集,并利用迁移学习、数据增强等先进技术对如ResNet、EfficientNet等成熟模型进行微调与优化,目标是使模型在复杂环境下(如光照变化、遮挡、背景干扰)对生活垃圾的识别准确率达到95%以上,并能有效区分易混淆品类(如塑料袋与其他塑料制品)。其次,旨在打造一个一体化的软件应用平台。该平台不仅提供核心的图像识别功能,还需集成用户管理、历史记录查询、垃圾分类知识库等模块,形成一个从识别到教育再到数据管理的完整闭环,提升用户体验。最终,本研究希望通过此系统的实际应用,验证深度学习技术在环保领域的实用价值,为城市智慧环卫体系的构建提供关键技术支撑与示范案例,推动垃圾分类从“人治”向“智治”转变。
二、 研究意义
本研究的意义深远,主要体现在技术、社会、经济和环境四个层面。在技术层面,它将深度学习这一尖端技术应用于具体的民生与环境工程问题,是计算机视觉与环保科学的一次深度交叉融合。这不仅推动了AI技术在实际场景中的落地与迭代,例如针对细粒度图像分类、小样本学习等挑战提出解决方案,还为相关领域(如工业品检测、医疗影像分析)提供了可借鉴的技术路径和实践经验。在社会层面,该系统能极大地降低公众参与垃圾分类的门槛和认知负担。用户只需用手机拍照即可获得准确的分类结果,这显著提升了居民的分类意愿和正确率,有助于培养全民环保习惯,形成良好的社会风尚,从而直接支持国家垃圾分类政策的有效施行。从经济角度看,系统的推广应用能够降低社区、环卫部门在宣传、指导和二次分拣环节的人力成本投入,长远来看,提升的垃圾分类效率有助于提高资源回收利用率,变废为宝,创造循环经济价值。在环境层面,精准的垃圾分类是垃圾减量化、资源化、无害化处理的前提。本系统通过技术手段保障了从源头进行正确分类,减少了错分垃圾对环境的污染(如有害垃圾的不当处理),促进了资源的循环利用,为实现可持续发展与“美丽中国”的宏伟蓝图贡献了切实的科技力量。
三、 研究内容
1. 需求分析
-
用户需求分析:
-
便捷识别需求:普通用户希望摆脱记忆复杂分类规则的困扰,通过最直观的拍照方式,快速、准确地获知垃圾的具体类别。
-
知识学习需求:用户不仅想知道“是什么”,还想了解“为什么”,系统应能提供详细的分类依据和环保知识,起到宣传教育作用。
-
历史追溯需求:用户可能需要回顾自己以往的查询记录,用于个人记账、环保行为统计或纠正过去的错误认知。
-
系统易用性需求:操作界面应简洁明了,识别响应速度快,流程清晰,适用于不同年龄段的用户。
-
-
功能需求详细描述:
-
用户身份管理:系统需支持用户的注册、登录和个人信息(如昵称、头像)管理功能。
-
核心图像识别:用户可通过手机相机拍摄或从相册上传垃圾图片,系统后台的深度学习模型需在数秒内完成分析,并返回最可能的垃圾类别、置信度及投放指导。
-
分类知识查询:提供一个包含所有可识别垃圾类别及其详细分类标准、投放要求的百科知识库,支持文本搜索。
-
识别历史记录:系统自动保存用户每一次的识别请求(包括图片、识别结果、时间戳),并允许用户查看和删除。
-
系统管理后台:管理员需要能够管理用户账号、管理(增删改查)垃圾类别数据、查看系统整体的识别数据统计,并可能需要对上传的图片进行审核或用于模型再训练。
-
2. 可行性分析
-
经济可行性:本项目开发成本相对可控。硬件上,模型训练初期可能需要GPU服务器(可采用云服务按需租用),部署阶段可使用性价比较高的云服务器。软件方面,主要技术栈(Python, TensorFlow/PyTorch, MySQL, Spring Boot等)均为开源免费。后期维护成本主要在于服务器和带宽费用。而其潜在收益巨大,包括节省的市政管理成本、提升回收产业效率带来的经济价值,以及可能通过政府项目资助或广告合作实现的商业回报,因此经济上可行。
-
社会可行性:本项目高度契合国家关于垃圾分类和人工智能发展的战略方向,社会接受度高。它解决了公众在日常生活中遇到的实际困难,有利于提升社会文明程度和环境保护意识,不存在伦理或法律上的重大风险,具有极强的社会可行性和正外部性。
-
技术可行性:当前深度学习技术在图像识别领域已非常成熟,ImageNet等竞赛中的模型准确率已超过人类水平。开源框架(TensorFlow, PyTorch)和预训练模型提供了强大的技术基础。移动应用开发(如Android、iOS、小程序)和Web后端开发技术也已标准化。云计算平台提供了便捷的模型部署和运维方案。因此,从算法实现到系统集成,技术链条完整且成熟,技术可行性高。
3. 功能分析
基于上述需求,系统主要功能模块划分如下:
-
用户管理模块:实现注册、登录、登出、个人信息修改功能。
-
垃圾识别模块:实现图片上传/拍摄、图像预处理、调用深度学习模型API、结果显示(类别、置信度、投放指南)功能。
-
知识库模块:实现垃圾分类标准的浏览、按关键词搜索功能。
-
历史记录模块:实现用户个人识别历史的列表展示、详情查看、按条件筛选和删除功能。
-
系统管理模块:
-
用户管理:管理员对普通用户账户进行查询、禁用等操作。
-
类别管理:对垃圾类别信息进行增删改查。
-
数据统计:查看系统总识别次数、各类别识别占比等统计数据。
-
四、 数据库表设计
根据功能分析,设计以下数据库表:
| 字段名 (英语) | 说明 (中文) | 大小 | 类型 | 主外键 | 备注 |
|---|---|---|---|---|---|
| 表名: user (用户表) | |||||
user_id |
用户唯一ID | INT |
主键 | 自增 | |
username |
用户名 | 50 | VARCHAR(50) |
唯一,用于登录 | |
password_hash |
加密后的密码 | 255 | VARCHAR(255) |
存储BCrypt加密串 | |
email |
邮箱 | 100 | VARCHAR(100) |
唯一 | |
nickname |
昵称 | 50 | VARCHAR(50) |
||
avatar_url |
头像链接 | 255 | VARCHAR(255) |
可空 | |
create_time |
创建时间 | DATETIME |
默认当前时间 | ||
update_time |
更新时间 | DATETIME |
自动更新 | ||
| 表名: garbage_category (垃圾类别表) | |||||
category_id |
类别唯一ID | INT |
主键 | 自增 | |
category_name |
类别名称 | 20 | VARCHAR(20) |
如:可回收物、有害垃圾等 | |
description |
类别描述 | 500 | VARCHAR(500) |
该类别的定义和投放要求 | |
icon_url |
类别图标链接 | 255 | VARCHAR(255) |
可空 | |
| 表名: garbage_item (垃圾物品表) | |||||
item_id |
物品唯一ID | INT |
主键 | 自增 | |
item_name |
物品标准名称 | 100 | VARCHAR(100) |
如:报纸、充电电池 | |
category_id |
所属类别ID | INT |
外键 | 关联 garbage_category.category_id |
|
disposal_guide |
投放指南 | 500 | VARCHAR(500) |
具体的投放注意事项 | |
| 表名: recognition_history (识别历史表) | |||||
history_id |
历史记录唯一ID | INT |
主键 | 自增 | |
user_id |
用户ID | INT |
外键 | 关联 user.user_id |
|
image_url |
识别图片存储路径 | 255 | VARCHAR(255) |
||
recognized_item_id |
识别出的物品ID | INT |
外键 | 关联 garbage_item.item_id |
|
confidence |
识别置信度 | DECIMAL(5,4) |
如 0.9567 | ||
create_time |
识别时间 | DATETIME |
默认当前时间 |
-- 创建数据库
CREATE DATABASE IF NOT EXISTS garbage_classification_system DEFAULT CHARSET utf8mb4 COLLATE utf8mb4_unicode_ci;
USE garbage_classification_system;
-- 用户表
CREATE TABLE `user` (
`user_id` INT AUTO_INCREMENT PRIMARY KEY,
`username` VARCHAR(50) NOT NULL UNIQUE,
`password_hash` VARCHAR(255) NOT NULL,
`email` VARCHAR(100) UNIQUE,
`nickname` VARCHAR(50),
`avatar_url` VARCHAR(255),
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP,
`update_time` DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
-- 垃圾类别表
CREATE TABLE `garbage_category` (
`category_id` INT AUTO_INCREMENT PRIMARY KEY,
`category_name` VARCHAR(20) NOT NULL,
`description` VARCHAR(500),
`icon_url` VARCHAR(255)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
-- 垃圾物品表
CREATE TABLE `garbage_item` (
`item_id` INT AUTO_INCREMENT PRIMARY KEY,
`item_name` VARCHAR(100) NOT NULL,
`category_id` INT NOT NULL,
`disposal_guide` VARCHAR(500),
FOREIGN KEY (`category_id`) REFERENCES `garbage_category` (`category_id`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
-- 识别历史表
CREATE TABLE `recognition_history` (
`history_id` INT AUTO_INCREMENT PRIMARY KEY,
`user_id` INT NOT NULL,
`image_url` VARCHAR(255) NOT NULL,
`recognized_item_id` INT NOT NULL,
`confidence` DECIMAL(5,4) NOT NULL,
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (`user_id`) REFERENCES `user` (`user_id`) ON DELETE CASCADE,
FOREIGN KEY (`recognized_item_id`) REFERENCES `garbage_item` (`item_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
-- 可选:为常用查询字段添加索引以提高性能
CREATE INDEX idx_recognition_history_user_id ON `recognition_history` (`user_id`);
CREATE INDEX idx_recognition_history_create_time ON `recognition_history` (`create_time`);
CREATE INDEX idx_garbage_item_category_id ON `garbage_item` (`category_id`);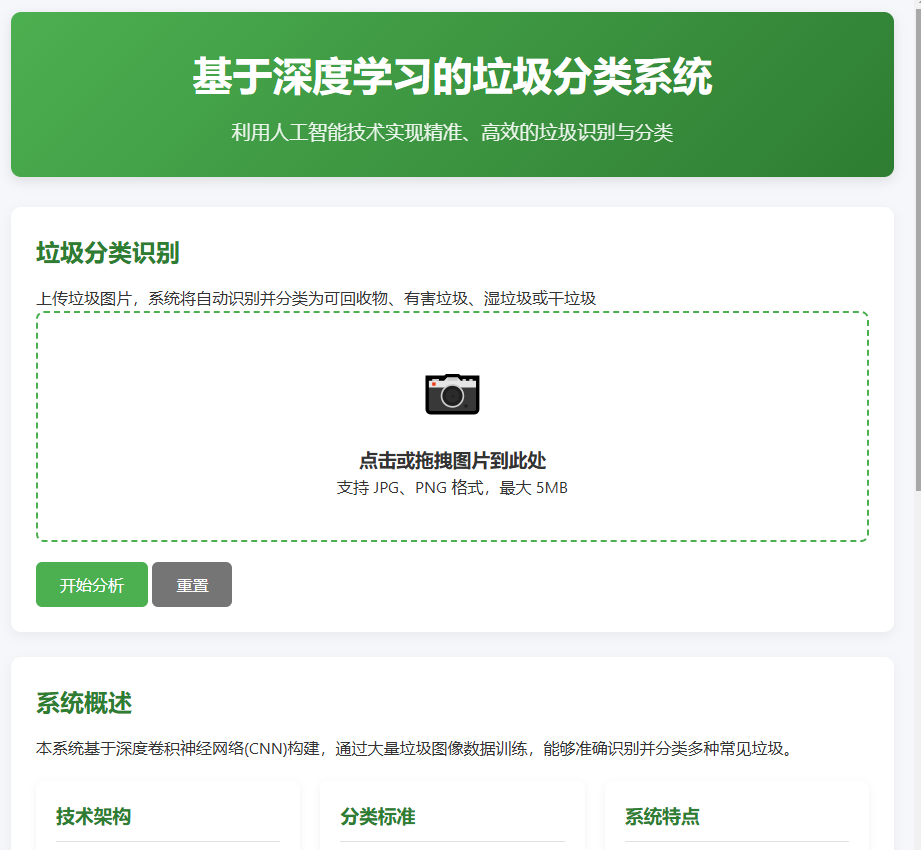

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 14
14 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)