Docker容器监控(Prometheus+Grafana)续集+Node Exporter、Process Exporter 和 cAdvisor以及实现飞书机器人推送告警消息
一、前言
在之前的《Docker容器监控(Prometheus+Grafana)》中(https://blog.csdn.net/weixin_61576086/article/details/150528171?fromshare=blogdetail&sharetype=blogdetail&sharerId=150528171&sharerefer=PC&sharesource=weixin_61576086&sharefrom=from_link),我们搭建了基础的监控系统。本文将深入介绍三个关键组件:Node Exporter(主机监控)、Process Exporter(进程监控)和cAdvisor(容器监控),帮助您构建更全面的Docker环境监控体系。
1、Node Exporter:主机级监控利器
1.1. 核心功能
Node Exporter是Prometheus官方提供的主机指标采集器,专为Linux系统设计,通过暴露HTTP接口提供:
- CPU:使用率、负载、中断等
- 内存:总量、使用量、缓存/缓冲区
- 磁盘:I/O、空间使用、inode状态
- 网络:接口流量、错误统计
- 系统:运行时间、文件描述符、内核信息
1.2. 为什么需要它?
虽然Docker引擎提供部分主机信息,但:
- 深度不足(如缺少磁盘I/O详情)
- 不支持自定义指标
- 与Prometheus生态无缝集成
1.3. 典型监控场景示例
# docker-compose.yml 示例
services:
node-exporter:
image: prom/node-exporter:latest
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host|etc)($$|/)'
ports:
- "9100:9100"关键配置说明:
- 挂载关键系统目录以采集指标
- 通过
--collector参数启用/禁用采集器 - 默认监听
9100端口
2、Process Exporter:进程级监控专家
2.1. 核心价值
当需要监控特定进程时(如Nginx、MySQL),Process Exporter能:
- 按名称/命令行匹配进程
- 采集CPU/内存/线程数等指标
- 支持正则表达式匹配
2.2. 与Node Exporter的区别
| 特性 | Node Exporter | Process Exporter |
|---|---|---|
| 监控粒度 | 主机级 | 进程级 |
| 典型指标 | 系统负载 | 进程内存占用 |
| 适用场景 | 基础设施监控 | 应用性能分析 |
2.3. 部署示例
services:
process-exporter:
image: ncabatoff/process-exporter:latest
volumes:
- /proc:/host/proc:ro
command:
- '-procfs=/host/proc'
- '-config.path=/config/proc-config.yml'
ports:
- "9256:9256"配置文件示例 (proc-config.yml):
process_names:
- name: "{{.Comm}}"
cmdline:
- 'nginx'
- name: "mysql"
cmdline:
- 'mysqld'3、cAdvisor:容器监控标配
3.1. 为什么选择cAdvisor?
Google开源的cAdvisor专为容器设计:
- 原生支持:Docker/Kubernetes容器指标
- 资源隔离:精确统计每个容器的CPU/内存/网络
- 历史数据:内置短期存储(默认1分钟)
- 拓扑发现:自动识别容器间关系
3.2. 与Docker Stats的区别
| 特性 | Docker Stats | cAdvisor |
|---|---|---|
| 数据持久化 | ❌ 无 | ✅ 支持Prometheus |
| 指标维度 | 基础 | 丰富(含文件系统) |
| 历史分析 | ❌ 实时 | ✅ 支持时间序列 |
3.3. 部署方案示例
services:
cadvisor:
image: google/cadvisor:latest
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
ports:
- "8080:8080"
command:
- '-docker_only=true' # 仅监控Docker容器关键指标示例:
container_cpu_user_seconds_totalcontainer_memory_usage_bytescontainer_network_receive_bytes_total
上面前言部分可以说都是废话,下面正式开始
二、开始部署工作
部署node-exporter
拉取镜像
当时本人在拉官网镜像时拉不了,所以在国内其他镜像网站进行拉取
docker pull docker.1ms.run/prom/node-exporter再启动容器
docker run -d \
--name=node-exporter \
--restart=unless-stopped \
--net="host" \
--pid="host" \
-v "/:/host:ro,rslave" \
docker.1ms.run/prom/node-exporter:latest \
--path.rootfs=/host命令参数详解:
-
--name=node-exporter: 为容器命名。 -
--restart=unless-stopped: 容器意外退出时自动重启。 -
--net="host": 使用主机网络模式。这是关键,让 Node Exporter 直接暴露在主机的网络上,Prometheus 可以直接通过主机IP:9100来抓取。 -
--pid="host": 访问主机的进程命名空间。这样它才能收集到整个系统的进程信息,而不是容器内的进程。 -
-v "/:/host:ro,rslave": 将主机的根目录/以只读模式挂载到容器的/host目录。-
ro: 只读,防止容器意外修改主机文件,这是重要的安全措施。 -
rslave: 使挂载遵循递归传播,确保挂载点信息正确。
-
-
--path.rootfs=/host: 告诉容器内的 Node Exporter,它要监控的系统的根目录在容器的/host路径下。
验证部署:
访问 http://你的服务器IP:9100/metrics (例如 http://192.168.11.123:9100/metrics),你应该能看到大量的主机监控指标。
部署cAdvisor
拉取镜像
docker pull google/cadvisor启动容器
docker run -d \
-p 8080:8080 \
-v /:/rootfs:ro \
-v /var/run:/var/run:rw \
-v /sys:/sys:ro \
-v /var/lib/docker/:/var/lib/docker:ro \
google/cadvisor:latest- 访问路径:
http://宿主机IP:8080
如果端口被使用,可以指定其他端口使用如下:
docker run -d \
--name=cadvisor \
-p 9100:9100 \ # 宿主机端口映射到容器9100
-v /:/rootfs:ro \
-v /var/run:/var/run:rw \
-v /sys:/sys:ro \
-v /var/lib/docker/:/var/lib/docker:ro \
google/cadvisor:latest \
--port=9100 # 显式指定容器内部端口为9100- 访问路径:
http://宿主机IP:9100
部署Process Exporter
拉取镜像
docker pull docker.1ms.run/ncabatoff/process-exporter编写process-exporter配置文件config.yml
process_names:
- name: "nginx"
cmdline:
- 'nginx'
- name: "mysql"
cmdline:
- 'mysqld'
- name: "redis"
cmdline:
- 'redis-server'
- name: "docker"
cmdline:
- 'dockerd'
- name: "ssh"
cmdline:
- 'sshd'
- name: "prometheus"
cmdline:
- 'prometheus'
- name: "grafana"
cmdline:
- 'grafana'
- name: "alertmanager"
cmdline:
- 'alertmanager'
- name: "java_app"
cmdline:
- 'java'
- name: "{{.Comm}}"
cmdline:
- '.+'启动容器
docker run -d \
--name process-exporter \
-p 9256:9256 \
-v /proc:/host/proc:ro \
-v /data/monitor/process-exporter/config.yml:/config.yml:ro \
--privileged \
docker.1ms.run/ncabatoff/process-exporter:latest \
-procfs /host/proc -config.path /config.yml参数解释:
-
-v /proc:/host/proc:ro:将宿主机的/proc目录挂载到容器的/host/proc,只读。 -
-v /data/monitor/process-exporter/config.yml:/config.yml:ro:挂载配置文件。 -
-procfs /host/proc:指定proc文件系统的路径(容器内路径)。 -
-config.path /config.yml:指定配置文件的路径(容器内路径)。
三、告警处理的“智能中枢”——Alertmanager
Alertmanager 是 Prometheus 生态中的核心告警管理组件,负责接收、处理并路由来自 Prometheus 的告警通知,确保关键问题被高效、可靠地传递给运维团队,同时避免告警风暴和冗余通知。
与 Prometheus 的协同工作流程
- 告警生成:Prometheus 根据配置的规则(如
CPU使用率 > 90%)生成告警事件。 - 告警发送:Prometheus 通过 HTTP API 将告警推送至 Alertmanager。
- 告警处理:Alertmanager 执行去重、分组、路由等操作。
- 通知发送:根据路由规则,通过邮件、Slack 等渠道发送通知。
- 日志记录:记录所有告警处理过程,便于审计与故障排查。
部署Alertmanager
编写配置文件alertmanager.yml
global:
resolve_timeout: 5m
route:
group_by: ['alertname', 'cluster', 'service']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'feishu-webhook'
receivers:
- name: 'feishu-webhook'
webhook_configs:
- url: 'http://192.168.11.123:9095/webhook'
send_resolved: true配置文件中加了飞书的消息推送token,具体可往下看第四部分
启动容器:
docker run -d --name=alertmanager -e TZ=Asia/Shanghai -p 9093:9093 -v /data/monitor/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml prom/alertmanager:latest总结
Alertmanager 是现代化监控系统的“告警大脑”,通过去重、分组、路由等功能,将海量告警转化为可操作的通知,帮助运维团队快速定位问题并采取行动。其与 Prometheus 的深度集成,使其成为云原生环境中不可或缺的告警管理工具
四、告警推送到飞书上
获取群机器人的Webhook 地址
飞书上创建告警推送群,添加群机器人,打开设置
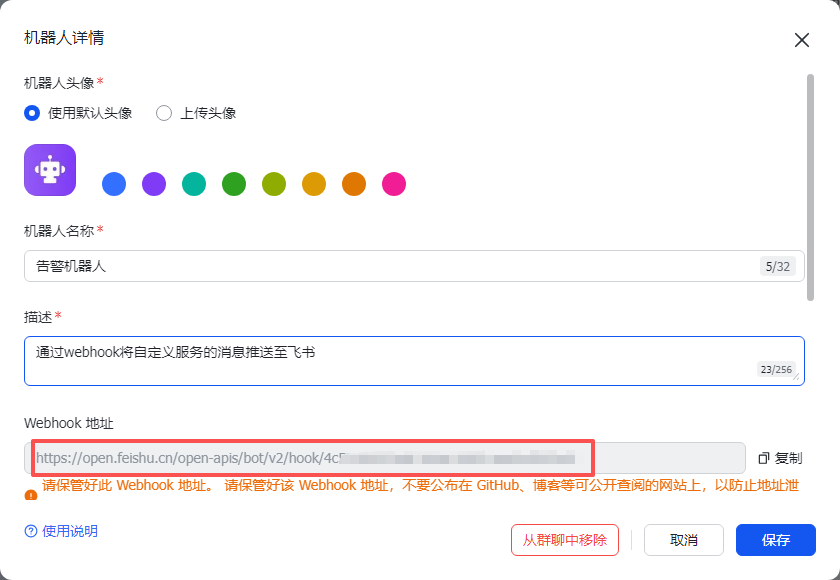
发现问题
我直接把飞书机器人Webhook 地址加到alertmanager.yml配置文件中,发现消息无论如何都是发不过来飞书。
最终发现飞书可能对 Webhook 的格式有特定要求。Alertmanager 默认的 Webhook 格式可能不兼容飞书。
这需要部署一个额外的服务来转换 Alertmanager 的 Webhook 格式为飞书兼容的格式。
部署飞书适配器
编写feishu-adapter.py脚本
注意里面的机器人webhook地址
from flask import Flask, request, jsonify
import requests
import os
import json
import logging
from datetime import datetime
# 设置日志
logging.basicConfig(level=logging.INFO) # 修改日志级别为INFO
logger = logging.getLogger(__name__)
app = Flask(__name__)
FEISHU_WEBHOOK_URL = os.getenv('FEISHU_WEBHOOK_URL', 'https://open.feishu.cn/open-apis/bot/v2/hook/自己的机器人Webhook 地址')
def create_feishu_card(alert):
"""创建飞书交互式卡片消息"""
status = alert.get('status', 'firing')
labels = alert.get('labels', {})
annotations = alert.get('annotations', {})
alertname = labels.get('alertname', 'Unknown Alert')
instance = labels.get('instance', 'Unknown Instance')
severity = labels.get('severity', 'unknown')
job = labels.get('job', '')
summary = annotations.get('summary', 'No summary provided')
description = annotations.get('description', 'No description provided')
generatorURL = alert.get('generatorURL', '')
# 根据状态和严重程度设置颜色
if status == "resolved":
color = "green"
status_text = "✅ 告警恢复"
elif severity == "critical":
color = "red"
status_text = "🚨 紧急告警"
elif severity == "warning":
color = "orange"
status_text = "⚠️ 警告告警"
else:
color = "blue"
status_text = "ℹ️ 信息告警"
# 构建飞书卡片消息
card = {
"msg_type": "interactive",
"card": {
"config": {
"wide_screen_mode": True,
"enable_forward": True
},
"header": {
"title": {
"tag": "plain_text",
"content": f"{status_text}: {alertname}"
},
"template": color
},
"elements": [
{
"tag": "div",
"text": {
"tag": "lark_md",
"content": f"**状态**: {status}\n**严重程度**: {severity}\n**实例**: {instance}\n**任务**: {job}"
}
},
{
"tag": "div",
"text": {
"tag": "lark_md",
"content": f"**摘要**: {summary}"
}
},
{
"tag": "div",
"text": {
"tag": "lark_md",
"content": f"**描述**: {description}"
}
},
{
"tag": "hr"
},
{
"tag": "note",
"elements": [
{
"tag": "plain_text",
"content": f"触发时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"
}
]
}
]
}
}
return card
@app.route('/webhook', methods=['POST'])
def webhook():
try:
# 获取请求数据
if request.content_type == 'application/json':
data = request.get_json()
else:
data = request.get_data(as_text=True)
try:
data = json.loads(data)
except json.JSONDecodeError:
logger.error(f"Failed to parse request data: {data}")
return jsonify({"error": "Invalid JSON data"}), 400
logger.debug(f"Received data: {json.dumps(data, indent=2)}")
# 提取告警信息
alerts = data.get('alerts', [])
if not alerts:
logger.warning("No alerts in payload")
return jsonify({"error": "No alerts in payload"}), 400
# 为每个告警构建飞书消息
for alert in alerts:
feishu_msg = create_feishu_card(alert)
logger.debug(f"Sending to Feishu: {json.dumps(feishu_msg, indent=2)}")
# 发送到飞书
try:
response = requests.post(
FEISHU_WEBHOOK_URL,
json=feishu_msg,
timeout=10
)
logger.debug(f"Feishu response: {response.status_code}, {response.text}")
if response.status_code != 200:
logger.error(f"Failed to send message to Feishu: {response.text}")
except Exception as e:
logger.error(f"Error sending to Feishu: {str(e)}")
return jsonify({"status": "success"})
except Exception as e:
logger.error(f"Error processing webhook: {str(e)}")
return jsonify({"error": str(e)}), 500
@app.route('/health', methods=['GET'])
def health():
return jsonify({"status": "healthy"})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=9095, debug=True)编写Dockerfile文件构建docker容器
FROM python:3.9-slim
WORKDIR /app
COPY feishu-adapter.py .
RUN pip install flask requests
# 设置环境变量
ENV TZ=Asia/Shanghai
CMD ["python", "feishu-adapter.py"]
构建并启动容器
docker build -t feishu-adapter .
docker run -d --name feishu-adapter -p 9095:9095 -e FEISHU_WEBHOOK_URL="https://open.feishu.cn/open-apis/bot/v2/hook/换成自己的机器人Webhook" feishu-adapter五、添加告警规则
编写alert.yml告警规则
groups:
# ----------------------------------------------------------
# 1. 容器级停机/删除检测(基于指标消失 + 启动时间)
# ----------------------------------------------------------
- name: container_disappeared
rules:
# 1-A. 精确到“曾经存在、现在消失”的容器
# 利用 24h 内最后一次 container_start_time_seconds,
# 如果它对应的 container_last_seen 已不存在,则认为容器已停止/删除。
#
- alert: ContainerDisappeared
expr: |
(
last_over_time(container_start_time_seconds{name!="",name!="cadvisor"}[1d])
unless on(name) container_last_seen{name!="",name!="cadvisor"}
)
for: 1m
labels:
severity: warning
annotations:
summary: "容器已停止或删除: {{ $labels.name }}"
description: "容器 {{ $labels.name }} 已停止或删除,超过 1 分钟未再出现"
# ----------------------------------------------------------
# 2. 节点级 cAdvisor 失联检测
# ----------------------------------------------------------
- name: cadvisor_down
rules:
# 2-A. cAdvisor job 失联(假设每个节点均通过 cadvisor:8080/metrics 抓取)
- alert: CadvisorDown
expr: up{job="docker"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "cAdvisor 失联: {{ $labels.instance }}"
description: "实例 {{ $labels.instance }} 上的 cAdvisor 已停止上报,可能导致容器监控缺失"
# 3. 主机级别监控告警 (Node Exporter)
- name: host-monitoring
rules:
- alert: InstanceDown
expr: up{job="node-exporter"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Node Exporter下线 ({{ $labels.instance }})"
description: "Node Exporter 任务 {{ $labels.job }} 的采集目标 {{ $labels.instance }} 已下线超过 1 分钟,监控数据丢失。"
- alert: DiskSpaceLow
expr: (node_filesystem_avail_bytes{mountpoint!="/boot"} * 100) / node_filesystem_size_bytes{mountpoint!="/boot"} < 10
for: 10m
labels:
severity: warning
annotations:
summary: "磁盘空间不足 ({{ $labels.instance }}, {{ $labels.mountpoint }})"
description: "实例 {{ $labels.instance }} 的挂载点 {{ $labels.mountpoint }} 剩余空间不足10%。"
- alert: MemoryUsageHigh
expr: (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100 > 90
for: 5m
labels:
severity: warning
annotations:
summary: "内存使用过高 ({{ $labels.instance }})"
description: "实例 {{ $labels.instance }} 的内存使用率持续超过90%。"
- alert: DiskIOLatencyHigh
expr: (rate(node_disk_read_time_seconds_total[2m]) + rate(node_disk_write_time_seconds_total[2m])) / (rate(node_disk_reads_completed_total[2m]) + rate(node_disk_writes_completed_total[2m]) + 1e-9) > 0.1
for: 5m
labels:
severity: warning
annotations:
summary: "磁盘IO延迟过高 ({{ $labels.instance }}, {{ $labels.device }})"
description: "实例 {{ $labels.instance }} 的磁盘 {{ $labels.device }} 平均IO延迟超过 100ms。"
- alert: HighIOWait
expr: rate(node_cpu_seconds_total{mode="iowait"}[2m]) * 100 > 20
for: 5m
labels:
severity: warning
annotations:
summary: "CPU IO等待时间过高 ({{ $labels.instance }})"
description: "实例 {{ $labels.instance }} 的CPU花费超过20%的时间在等待磁盘IO操作上。"
- alert: CriticalCPUUsage
expr: 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 90
for: 3m
labels:
severity: critical
annotations:
summary: "CPU使用率严重过高 ({{ $labels.instance }})"
description: "实例 {{ $labels.instance }} 的CPU使用率持续3分钟超过90%,当前值为 {{ $value | humanize }}%。"
# 4. 进程监控告警 (Process Exporter)
- name: process_alerts
rules:
# 业务应用宕机告警
- alert: BusinessAppDown
expr: namedprocess_namegroup_num_procs{groupname=~".*\\.jar"} == 0
for: 1m
labels:
severity: critical
category: business
annotations:
summary: "业务应用停止: {{ $labels.groupname }}"
description: "业务应用 {{ $labels.groupname }} 已停止运行超过1分钟,请立即检查!"
# 2. 类启动应用宕机告警(新增)
- alert: ClassAppDown
expr: namedprocess_namegroup_num_procs{groupname=~"java_class_.*"} == 0
for: 1m
labels:
severity: critical
category: business
annotations:
summary: "类应用停止: {{ $labels.groupname }}"
description: "类启动应用 {{ $labels.groupname }} 已停止运行超过1分钟,请立即检查!"编写Prometheus配置文件
把监控的那些地址和端口号加上去
prometheus.yml
注意里面的ip号要写成自己的ip和监听的端口
global:
scrape_interval: 15s
alerting:
alertmanagers:
- api_version: v2
static_configs:
- targets: ["192.*.1*.*:9093"]
rule_files:
- "alert.yml"
scrape_configs:
- job_name: 'docker'
static_configs:
- targets: ['192.*.1*.*:9323']
labels:
- targets: ['11*.7*.9*.8*:9100']
labels:
- job_name: 'processes'
static_configs:
- targets: ['192.*.1*.*:9256']
labels:
- targets: ['192.*.1*.*:9256']
labels:
- targets: ['192.*.1*.*:9256']
labels:
- job_name: 'node-exporter'
static_configs:
- targets: ['192.*.1*.*:9100']
labels:
instance: 'server-123'
- targets: ['11*.7*.9*.8*:19100']
labels:
instance: 'server-kqy'
- targets: ['192.*.1*.*:9100']
labels:
instance: 'server-178'重启Prometheus是的配置生效
docker restart prometheus一开始是这样子启动的,已经把告警规则和配置文件挂载进去了
docker run -d --name prometheus -p 9090:9090 -v /data/monitor/prometheus:/data -v /data/monitor/prometheus/alert.yml:/etc/prometheus/alert.yml -v /data/monitor/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml -e TZ=Asia/Shanghai prom/prometheus --web.enable-lifecycle --config.file=/etc/prometheus/prometheus.yml六、最后总结——构建完整的 Docker 容器监控与告警体系
本文通过 Node Exporter、Process Exporter、cAdvisor 三大核心组件,结合 Prometheus + Grafana + Alertmanager,构建了一套完整的 Docker 容器监控与告警系统,覆盖从主机、进程到容器的全维度监控,并通过飞书机器人实现告警实时推送。以下是关键总结:
1. 监控组件分工与价值
| 组件 | 监控粒度 | 核心功能 | 典型场景 |
|---|---|---|---|
| Node Exporter | 主机级 | 采集 CPU、内存、磁盘、网络等系统指标 | 基础设施健康检查、资源瓶颈分析 |
| Process Exporter | 进程级 | 按名称/命令行匹配进程,监控进程的 CPU、内存、线程数等 | 关键服务(Nginx/MySQL)性能分析 |
| cAdvisor | 容器级 | 实时监控容器资源使用(CPU/内存/网络/磁盘),支持 Prometheus 格式数据输出 | 容器化应用资源隔离、性能调优 |
2. 部署关键点总结
2.1 组件部署优化
- Node Exporter
- 使用
--net="host"和--pid="host"提升数据采集权限,避免权限不足导致的指标缺失。 - 通过
-v "/:/host:ro,rslave"挂载根目录,确保文件系统指标完整采集。
- 使用
- cAdvisor
- 显式指定端口(如
--port=9100)避免与 Node Exporter 冲突。 - 挂载
/var/lib/docker目录以监控容器镜像和磁盘占用。
- 显式指定端口(如
- Process Exporter
- 通过
config.yml定义进程匹配规则(支持正则表达式),灵活监控自定义进程。 - 使用
--privileged权限确保访问/proc目录。
- 通过
2.2 告警处理核心
- Alertmanager
- 通过
group_by实现告警分组,避免告警风暴。 - 配置
repeat_interval控制告警重发频率,减少冗余通知。 - 集成飞书机器人需通过适配器转换 Webhook 格式,确保兼容性。
- 通过
- 告警规则设计
- 容器级:检测容器消失(
container_disappeared)或 cAdvisor 失联(cadvisor_down)。 - 主机级:监控磁盘空间(
DiskSpaceLow)、内存使用(MemoryUsageHigh)等。 - 进程级:可扩展监控关键进程的存活状态或资源占用。
- 容器级:检测容器消失(
3. 完整监控流程
- 数据采集
- Node Exporter/Process Exporter/cAdvisor 分别采集主机、进程、容器指标。
- Prometheus 定期抓取各 Exporter 的
/metrics接口。
- 告警触发
- Prometheus 根据
alert.yml规则生成告警事件(如 CPU 使用率 > 90%)。 - 告警推送至 Alertmanager 进行去重、分组和路由。
- Prometheus 根据
- 通知推送
- Alertmanager 通过 Webhook 调用飞书适配器,将告警转换为飞书卡片格式。
- 飞书机器人将格式化后的消息发送至指定群组。
- 可视化分析
- Grafana 配置数据源为 Prometheus,创建仪表盘展示关键指标(如容器 CPU 使用率、磁盘 I/O)。
4. 常见问题与解决方案
| 问题 | 解决方案 |
|---|---|
| Node Exporter 指标缺失 | 检查挂载目录权限(如 /proc、/sys),确保 --net="host" 和 --pid="host" |
| cAdvisor 与 Node Exporter 端口冲突 | 显式指定 cAdvisor 端口(如 --port=9100) |
| 飞书告警未推送 | 部署适配器转换 Webhook 格式,检查飞书机器人 Webhook URL 是否正确 |
| Prometheus 未加载告警规则 | 确认 prometheus.yml 中 rule_files 路径正确,重启 Prometheus 生效 |
5. 扩展建议
- 高可用部署
- Prometheus 和 Alertmanager 支持集群模式,避免单点故障。
- 使用
thanos或cortex实现长期数据存储和查询。
- 自动化运维
- 结合
Ansible或Kubernetes Operator实现监控组件的自动化部署和配置管理。 - 通过
Prometheus Alertmanager Webhook触发自动化修复脚本(如重启容器)。
- 结合
- 多渠道告警
- 扩展 Alertmanager 接收器,支持邮件、Slack、企业微信等多通道通知
结语
本文构建的监控系统实现了 从数据采集到告警推送 的全链路自动化,帮助运维团队快速定位问题并采取行动。通过灵活配置告警规则和通知策略,可适应不同业务场景的需求。未来可进一步探索 AI 异常检测 和 自动化扩缩容,提升监控系统的智能化水平。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 53
53 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)