搭建CNN、LSTM、CNN-LSTM和CNN-LSTM-Attention训练EEG数据
概述
本文对比了四种深度学习模型:CNN、LSTM、CNN-LSTM和CNN-LSTM-Attention。所有模型接收相同的输入形状:(batch_size, 1, 9, 500),数据集来自清华大学开源SSVEP脑电数据,其中:
-
1:EEG信号的通道维度(单通道表示)
-
9:实际EEG通道数(电极数)
-
500:时间采样点数
1. CNN模型:空间-时间特征提取器
架构设计
python
CNN架构流程: 输入(1,9,500) → Conv1(32@1×5) → Conv2(32@9×1) → Pool1(1×4) → Conv3(64@1×5) → Pool2(1×4) → Conv4(128@1×5) → Pool3(1×2) → Flatten → FC(512) → Output(40)
关键特点
-
时间卷积优先:
Conv1使用(1,5)卷积核,沿时间维度提取局部特征 -
空间卷积分离:
Conv2使用(9,1)卷积核,跨9个EEG通道提取空间模式 -
分层池化:通过
AvgPool2d逐步压缩时间维度(500→125→31→15) -
批归一化+ELU激活:每层后接批归一化和ELU激活函数,加速收敛
设计理念
该CNN采用"时间→空间→时间"的混合卷积策略,模仿了EEG信号处理中先提取时间特征再分析空间相关性的传统方法。
# 定义卷积神经网络模型
class CNN(nn.Module):
"""
EEG分类CNN网络
输入形状: (batch_size, 1, 9, 500)
输出: 40个类别的概率
"""
#Nt是取数据的采样点大小
def __init__(self, num_classes=40, Nt=Nt):
super(CNN, self).__init__()
# 第一个卷积块
self.conv1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=(1, 5), padding=(0, 2)),
nn.BatchNorm2d(32),
nn.ELU(inplace=True),
nn.Dropout(0.3)
)
# 第二个卷积块 - 空间卷积
self.conv2 = nn.Sequential(
nn.Conv2d(32, 32, kernel_size=(9, 1), padding=(0, 0)),
nn.BatchNorm2d(32),
nn.ELU(inplace=True),
nn.Dropout(0.3),
nn.AvgPool2d(kernel_size=(1, 4))
)
# 第三个卷积块
self.conv3 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=(1, 5), padding=(0, 2)),
nn.BatchNorm2d(64),
nn.ELU(inplace=True),
nn.Dropout(0.3),
nn.AvgPool2d(kernel_size=(1, 4))
)
# 第四个卷积块
self.conv4 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=(1, 5), padding=(0, 2)),
nn.BatchNorm2d(128),
nn.ELU(inplace=True),
nn.Dropout(0.3),
nn.AvgPool2d(kernel_size=(1, 2))
)
# 计算全连接层输入尺寸
# 经过conv2后: (1, 500) -> (1, 125) [500/4]
# 经过conv3后: (1, 125) -> (1, 31) [125/4]
# 经过conv4后: (1, 31) -> (1, 15) [31/2]
# 最终: 128 * 1 * 15 = 1920
# 全连接层
self.fc = nn.Sequential(
nn.Linear(128 * 1 * (Nt//32), 512),
nn.ELU(inplace=True),
nn.Dropout(0.5),
nn.Linear(512, num_classes)
)
def forward(self, x):
# x形状: (batch, 1, 9, 500)
x = self.conv1(x) # -> (batch, 32, 9, 500)
x = self.conv2(x) # -> (batch, 32, 1, 125)
x = self.conv3(x) # -> (batch, 64, 1, 31)
x = self.conv4(x) # -> (batch, 128, 1, 15)
# 展平
x = x.view(x.size(0), -1) # -> (batch, 128*1*15)
x = self.fc(x) # -> (batch, 40)
return x2. LSTM模型:纯时序建模
架构设计
python
LSTM架构流程: 输入(1,9,500) → 重塑(500,9) → LSTM(2层,128单元) → 取最后时间步 → BN → FC(64) → FC(40) → 输出
关键特点
-
输入重塑:将
(batch,1,9,500)转换为(batch,500,9),适应LSTM的(seq_len, feature)格式 -
双向非对称:使用单向LSTM,专注于前向时间依赖
-
最后时间步:仅使用LSTM最后一个时间步的输出进行分类,假设序列末尾包含最丰富的判别信息
-
简单高效:参数量较少,训练速度快
设计理念
LSTM模型专注于SSVEP信号的长程时序依赖性,适合处理具有明显时间动态特性的脑电信号。
import torch.nn as nn
class LSTM(nn.Module):
def __init__(self, input_size=9, hidden_size=128, num_layers=2, num_classes=40, dropout=0.25):
"""
用于EEG分类的LSTM网络
参数:
- input_size: 输入特征维度 (通道数)
- hidden_size: LSTM隐藏层维度
- num_layers: LSTM层数
- num_classes: 分类类别数
- dropout: dropout比率
"""
super(LSTM, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.num_classes = num_classes
# LSTM层
self.lstm = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
dropout=dropout if num_layers > 1 else 0,
bidirectional=False
)
# 全连接层
self.fc1 = nn.Linear(hidden_size, 64)
self.dropout = nn.Dropout(dropout)
self.fc2 = nn.Linear(64, num_classes)
# 激活函数
self.relu = nn.ReLU()
# 批归一化
self.bn = nn.BatchNorm1d(hidden_size)
def forward(self, x):
"""
前向传播
参数:
- x: 输入数据, shape: (batch_size, 1, channels, time_points)
返回:
- 分类结果
"""
# 调整输入形状: (batch, 1, channels, time) -> (batch, time, channels)
batch_size = x.size(0)
x = x.squeeze(1) # 移除维度1: (batch, channels, time)
x = x.permute(0, 2, 1) # (batch, time, channels)
# LSTM层
lstm_out, (hidden, cell) = self.lstm(x)
# 取最后一个时间步的输出
lstm_out = lstm_out[:, -1, :] # (batch, hidden_size)
# 批归一化
lstm_out = self.bn(lstm_out)
# 全连接层
out = self.fc1(lstm_out)
out = self.relu(out)
out = self.dropout(out)
out = self.fc2(out)
return out3. CNN-LSTM模型:空间-时间联合建模
架构设计
python
CNN-LSTM混合架构流程: 输入 → CNN块[Conv(32@1×25)→Conv(32@9×1)→Conv(64@1×15)→Pool]×2 → 自适应池化(32时间步) → LSTM(双向,2层,128单元) → FC(256→128) → FC(40) → 输出
关键特点
-
大卷积核:
Conv1使用(1,25)的大卷积核,捕获更长的时间模式 -
自适应池化:使用
AdaptiveAvgPool2d将CNN输出统一为32个时间步,确保LSTM输入长度一致 -
双向LSTM:使用双向LSTM捕获前后时间依赖
-
早融合策略:CNN作为特征提取器,LSTM作为时序建模器,实现端到端训练
设计理念
CNN-LSTM采用"空间特征提取→时间序列建模"的两阶段策略,充分利用了CNN在局部特征提取和LSTM在时序建模方面的优势。
import torch.nn as nn
import torch.nn.functional as F
class CNN_LSTM(nn.Module):
"""
用于SSVEP分类的CNN-LSTM混合网络
输入形状: (batch_size, 1, 9, 500)
"""
def __init__(self, num_classes=40, dropout_rate=0.25):
super(CNN_LSTM, self).__init__()
# CNN部分:提取空间和时间特征
self.conv1 = nn.Conv2d(1, 32, kernel_size=(1, 25), padding=(0, 12))
self.bn1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(32, 32, kernel_size=(9, 1))
self.bn2 = nn.BatchNorm2d(32)
self.conv3 = nn.Conv2d(32, 64, kernel_size=(1, 15), padding=(0, 7))
self.bn3 = nn.BatchNorm2d(64)
self.pool1 = nn.MaxPool2d(kernel_size=(1, 4))
self.dropout1 = nn.Dropout2d(dropout_rate)
self.conv4 = nn.Conv2d(64, 64, kernel_size=(1, 15), padding=(0, 7))
self.bn4 = nn.BatchNorm2d(64)
self.pool2 = nn.MaxPool2d(kernel_size=(1, 4))
self.dropout2 = nn.Dropout2d(dropout_rate)
# 自适应池化层,将CNN输出固定为固定长度的时间序列
self.adaptive_pool = nn.AdaptiveAvgPool2d((1, 32))
# LSTM部分:处理时间序列特征
self.lstm = nn.LSTM(
input_size=64, # 输入特征维度
hidden_size=128, # LSTM隐藏单元数
num_layers=2, # LSTM层数
batch_first=True,
bidirectional=True, # 双向LSTM
dropout=dropout_rate if 2 > 1 else 0
)
# 全连接层
self.fc1 = nn.Linear(256, 128) # 双向LSTM输出是2*hidden_size
self.bn_fc = nn.BatchNorm1d(128)
self.dropout_fc = nn.Dropout(dropout_rate)
self.fc2 = nn.Linear(128, num_classes)
# 初始化权重
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
# x shape: (batch_size, 1, 9, 500)
# CNN特征提取
x = F.elu(self.bn1(self.conv1(x)))
x = F.elu(self.bn2(self.conv2(x)))
x = self.pool1(F.elu(self.bn3(self.conv3(x))))
x = self.dropout1(x)
x = self.pool2(F.elu(self.bn4(self.conv4(x))))
x = self.dropout2(x)
# 调整形状为LSTM输入: (batch_size, time_steps, features)
# 使用自适应池化确保时间步固定
x = self.adaptive_pool(x) # (batch_size, 64, 1, 32)
x = x.squeeze(2) # (batch_size, 64, 32)
x = x.permute(0, 2, 1) # (batch_size, 32, 64)
# LSTM处理时间序列
lstm_out, (h_n, c_n) = self.lstm(x)
# 使用最后一个时间步的输出
# 对于双向LSTM,使用最后一个时间步的前向和后向隐藏状态
lstm_out = lstm_out[:, -1, :] # (batch_size, 256)
# 全连接层分类
x = F.elu(self.bn_fc(self.fc1(lstm_out)))
x = self.dropout_fc(x)
x = self.fc2(x)
return x4. CNN-LSTM-Attention模型:注意力增强的混合架构
架构设计
python
CNN-LSTM-Attention架构流程: 输入 → 深度CNN[5层卷积,特征维度1→32→64→128→256→128] → 重塑为(31,128) → LSTM(双向,2层,64单元) → 多头注意力(4头) → 层归一化+残差连接 → 通道注意力+时间注意力 → 特征融合(256→128) → FC(40) → 输出
关键特点
-
深度CNN特征提取器
-
5层卷积,每层有特定作用(时间特征、空间特征、频域特征等)
-
使用ELU激活函数,避免ReLU的神经元死亡问题
-
-
多头注意力机制
python
self.multihead_attn = nn.MultiheadAttention( embed_dim=128, num_heads=4, # 4头注意力 dropout=0.25, batch_first=True )-
4头注意力并行处理不同特征子空间
-
残差连接和层归一化提升训练稳定性
-
-
双注意力融合
-
通道注意力:关注不同EEG通道的重要性
-
时间注意力:关注关键时间片段
-
两者特征拼接后通过融合网络整合
-
-
先进的训练技巧
-
Xavier和正交初始化
-
批归一化和层归一化结合
-
Dropout防止过拟合
-
设计理念
CNN-LSTM-Attention是三者中最复杂的模型,通过注意力机制让模型"学会"关注SSVEP信号中最具判别性的时空特征,实现了从特征提取到特征选择的全自动过程。
import torch
import torch.nn as nn
import torch.nn.functional as F
class CNN_LSTM_Attention(nn.Module):
"""
用于SSVEP分类的CNN-LSTM-Attention网络
输入形状: (batch_size, 1, 9, 500)
"""
def __init__(self, num_classes=40, dropout_rate=0.25, num_heads=4):
super(CNN_LSTM_Attention, self).__init__()
# ==================== CNN特征提取部分 ====================
# 第一层:时间特征提取(大卷积核捕获长期时间模式)
self.conv1_time = nn.Conv2d(1, 32, kernel_size=(1, 50), padding=(0, 25))
self.bn1 = nn.BatchNorm2d(32)
# 第二层:空间特征提取(跨通道卷积)
self.conv2_spatial = nn.Conv2d(32, 64, kernel_size=(9, 1))
self.bn2 = nn.BatchNorm2d(64)
# 第三层:深度时间特征提取
self.conv3_time = nn.Conv2d(64, 128, kernel_size=(1, 25), padding=(0, 12))
self.bn3 = nn.BatchNorm2d(128)
self.pool1 = nn.MaxPool2d(kernel_size=(1, 4))
# 第四层:频域特征增强
self.conv4_freq = nn.Conv2d(128, 256, kernel_size=(1, 15), padding=(0, 7))
self.bn4 = nn.BatchNorm2d(256)
self.pool2 = nn.MaxPool2d(kernel_size=(1, 4))
# 第五层:特征融合
self.conv5_fuse = nn.Conv2d(256, 128, kernel_size=(1, 1))
self.bn5 = nn.BatchNorm2d(128)
# ==================== LSTM时序建模部分 ====================
# 双向LSTM提取时序依赖
self.lstm = nn.LSTM(
input_size=128, # 输入特征维度
hidden_size=64, # 隐藏单元数
num_layers=2, # LSTM层数
batch_first=True, # 输入格式为(batch, seq, feature)
bidirectional=True, # 双向LSTM
dropout=dropout_rate
)
# ==================== 多头注意力机制 ====================
self.num_heads = num_heads
self.attention_dim = 128 # LSTM双向输出维度
# 多头注意力层
self.multihead_attn = nn.MultiheadAttention(
embed_dim=self.attention_dim,
num_heads=num_heads,
dropout=dropout_rate,
batch_first=True
)
# 层归一化
self.ln1 = nn.LayerNorm(self.attention_dim)
self.ln2 = nn.LayerNorm(self.attention_dim)
# 前馈网络
self.ffn = nn.Sequential(
nn.Linear(self.attention_dim, 256),
nn.ReLU(),
nn.Dropout(dropout_rate),
nn.Linear(256, self.attention_dim)
)
# ==================== 分类头 ====================
# 通道注意力(对CNN特征)
self.channel_attention = ChannelAttention(128)
# 时间注意力(对LSTM输出)
self.time_attention = TimeAttention(self.attention_dim)
# 特征融合层
self.fusion = nn.Sequential(
nn.Linear(self.attention_dim * 2, 256),
nn.BatchNorm1d(256),
nn.ELU(),
nn.Dropout(dropout_rate),
nn.Linear(256, 128),
nn.BatchNorm1d(128),
nn.ELU(),
nn.Dropout(dropout_rate)
)
# 最终分类层
self.classifier = nn.Linear(128, num_classes)
# ==================== 初始化权重 ====================
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_normal_(m.weight)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LSTM):
for name, param in m.named_parameters():
if 'weight' in name:
nn.init.orthogonal_(param)
elif 'bias' in name:
nn.init.constant_(param, 0)
def forward(self, x):
# x形状: (batch, 1, 9, 500)
# ==================== 1. CNN特征提取 ====================
# 时间特征提取
c1 = F.elu(self.bn1(self.conv1_time(x))) # (batch, 32, 9, 500)
# 空间特征提取
c2 = F.elu(self.bn2(self.conv2_spatial(c1))) # (batch, 64, 1, 500)
# 深度时间特征
c3 = F.elu(self.bn3(self.conv3_time(c2))) # (batch, 128, 1, 500)
c3 = self.pool1(c3) # (batch, 128, 1, 125)
# 频域特征增强
c4 = F.elu(self.bn4(self.conv4_freq(c3))) # (batch, 256, 1, 125)
c4 = self.pool2(c4) # (batch, 256, 1, 31)
# 特征融合
cnn_features = F.elu(self.bn5(self.conv5_fuse(c4))) # (batch, 128, 1, 31)
# ==================== 2. LSTM时序建模 ====================
# 调整形状为LSTM输入: (batch, time_steps, features)
lstm_input = cnn_features.squeeze(2) # (batch, 128, 31)
lstm_input = lstm_input.permute(0, 2, 1) # (batch, 31, 128)
# LSTM处理
lstm_out, (h_n, c_n) = self.lstm(lstm_input) # lstm_out: (batch, 31, 128)
# ==================== 3. 多头注意力机制 ====================
# 多头注意力
attn_output, attn_weights = self.multihead_attn(
lstm_out, lstm_out, lstm_out
) # attn_output: (batch, 31, 128)
# 残差连接和层归一化
lstm_out = self.ln1(lstm_out + attn_output)
# 前馈网络
ffn_output = self.ffn(lstm_out)
# 残差连接和层归一化
lstm_out = self.ln2(lstm_out + ffn_output) # (batch, 31, 128)
# ==================== 4. 多尺度注意力融合 ====================
# 通道注意力(CNN特征)
cnn_attn = self.channel_attention(cnn_features) # (batch, 128, 1, 31)
cnn_attn_pool = F.adaptive_avg_pool2d(cnn_attn, (1, 1)) # (batch, 128, 1, 1)
cnn_attn_feat = cnn_attn_pool.squeeze() # (batch, 128)
# 时间注意力(LSTM特征)
time_attn_feat = self.time_attention(lstm_out) # (batch, 128)
# ==================== 5. 特征融合和分类 ====================
# 拼接CNN和LSTM的注意力特征
fused_features = torch.cat([cnn_attn_feat, time_attn_feat], dim=1) # (batch, 256)
# 特征融合
final_features = self.fusion(fused_features) # (batch, 128)
# 分类
output = self.classifier(final_features) # (batch, num_classes)
return output
class ChannelAttention(nn.Module):
"""通道注意力模块"""
def __init__(self, channels, reduction_ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channels, channels // reduction_ratio),
nn.ReLU(inplace=True),
nn.Linear(channels // reduction_ratio, channels),
nn.Sigmoid()
)
def forward(self, x):
# x形状: (batch, channels, height, width)
b, c, _, _ = x.size()
avg_out = self.avg_pool(x).view(b, c)
max_out = self.max_pool(x).view(b, c)
avg_attention = self.fc(avg_out).view(b, c, 1, 1)
max_attention = self.fc(max_out).view(b, c, 1, 1)
channel_attention = avg_attention + max_attention
return x * channel_attention
class TimeAttention(nn.Module):
"""时间注意力模块"""
def __init__(self, feature_dim):
super(TimeAttention, self).__init__()
self.attention = nn.Sequential(
nn.Linear(feature_dim, feature_dim // 2),
nn.Tanh(),
nn.Linear(feature_dim // 2, 1)
)
def forward(self, x):
# x形状: (batch, time_steps, features)
attention_weights = self.attention(x) # (batch, time_steps, 1)
attention_weights = F.softmax(attention_weights, dim=1)
# 加权求和
weighted_features = (x * attention_weights).sum(dim=1) # (batch, features)
return weighted_features5.对比结果
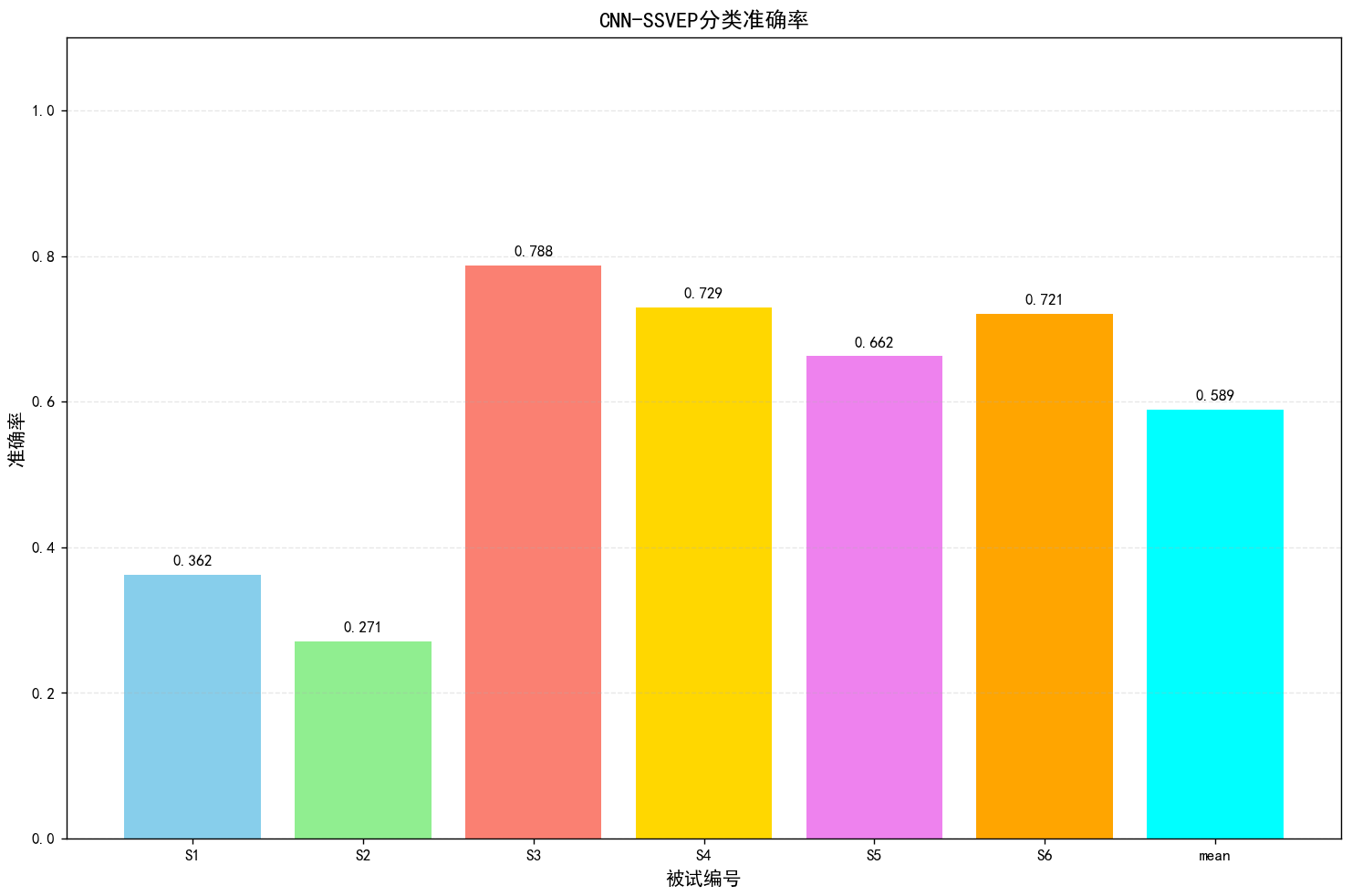
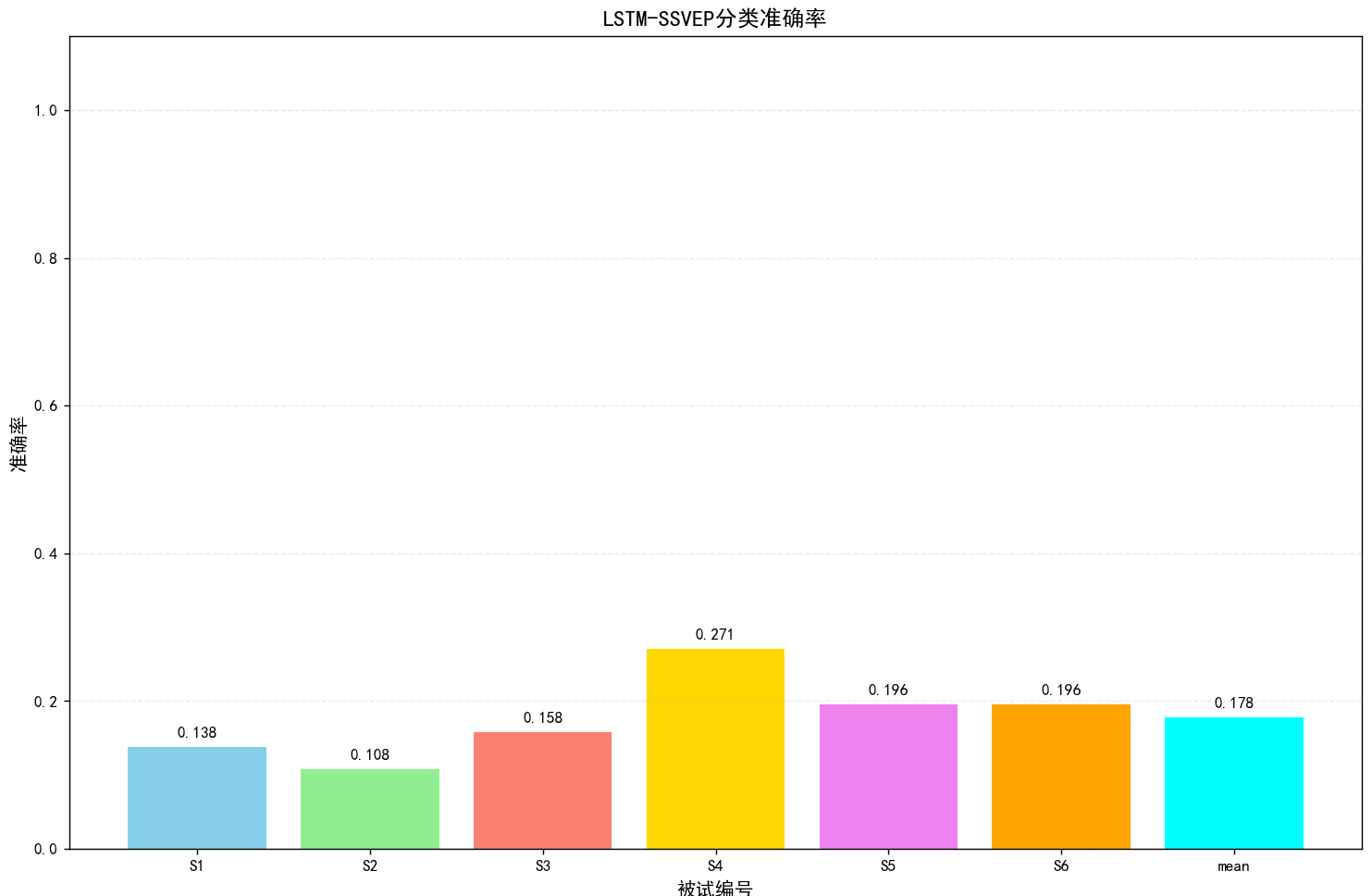
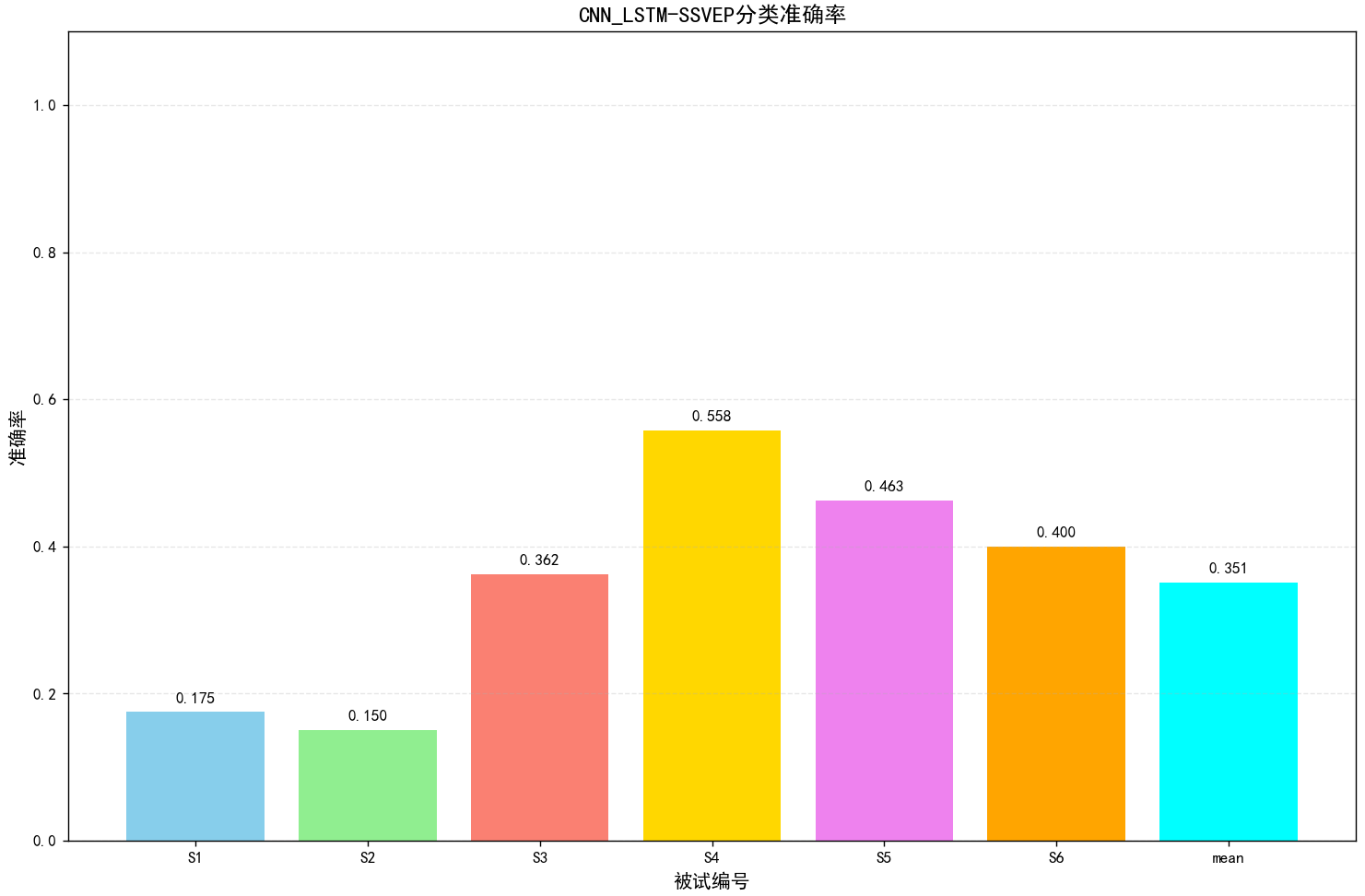
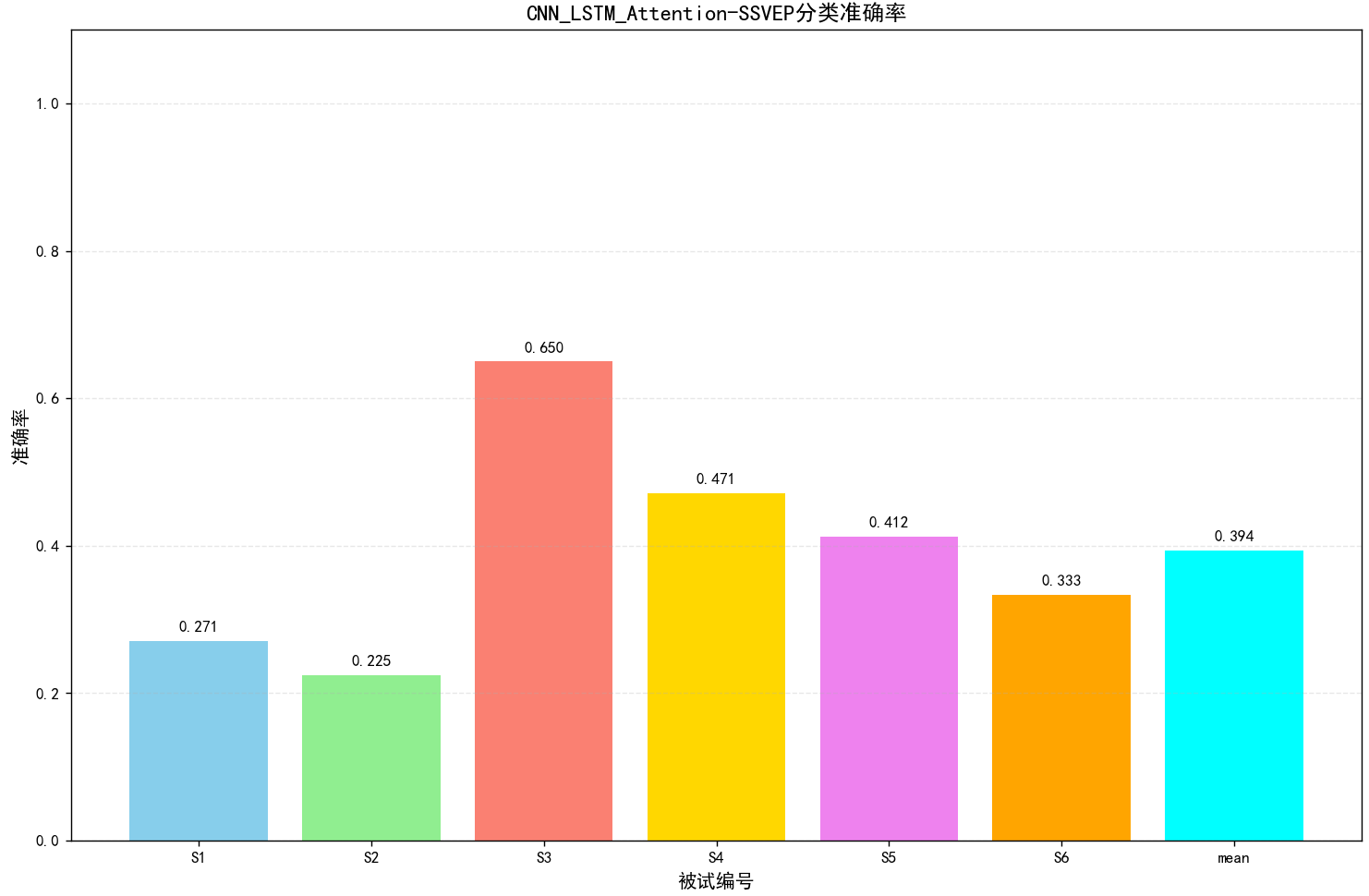
6.完整项目
Train文件下面对应的是4个模型的训练代码,Dataset文件是数据加载代码
完整项目已包含6个被试的数据:SSVEP_DL_Classfier-main.zip
链接: https://pan.baidu.com/s/15djc-ntzGmObOncCcdvInA?pwd=rpus 提取码: rpus

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 34
34 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)