机器学习入门(六)线性回归,损失函数,梯度下降
MSE(以MSE为主介绍)、RMSE、MAE
-
MSE (均方误差,Mean-Square Error, MSE):
-
解释:均方误差越小越好,因为MSE是误差的平方,较大的错误会被惩罚得更严重。MSE (均方误差, Mean Squared Error): 计算所有预测误差的平方和的均值,对于线性回归来说,MSE是最常用的损失函数。它对大误差非常敏感。
-
优点:非常常用,特别适合正态分布误差的情况。
-
缺点:对异常值非常敏感。如果数据中存在异常点,MSE可能会变得非常大。
-
公式:
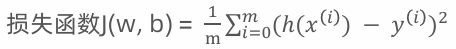
-
-
RMSE (均方根误差, Root Mean Squared Error):
-
解释:RMSE是MSE的平方根,它和数据的原始单位相同,因此比MSE更容易解释。
-
优点:由于具有与数据单位相同的维度,RMSE更容易直观理解。
-
缺点:仍然对异常值敏感。
-
公式:
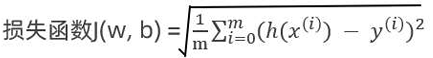
-
-
MAE (平均绝对误差, Mean Absolute Error , MAE):
-
解释:平均绝对误差对异常值的敏感度较低,因此它适合在数据中包含异常点的情况下使用。计算预测值与实际值之差的绝对值的平均,较为简单,不对大误差有过多的惩罚。
-
优点:较为简单,易于理解,不会因为异常值的存在而出现大的波动。
-
缺点:相对于MSE,它不对大误差进行惩罚,可能不适用于所有情况。
-
公式:
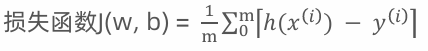
-
MSE 普通最小二乘法
矩阵普通最小二乘法(同一个问题的不同解法)https://blog.csdn.net/qq_35496811/article/details/155598949?spm=1001.2014.3001.5502
数据(简化为3个学生,2个特征):
| 学生 | 学习时长(x₁) | 作业分(x₂) | 真实成绩(y) |
|---|---|---|---|
| A | 10小时 | 80分 | 85分 |
| B | 20小时 | 90分 | 95分 |
| C | 15小时 | 85分 | 90分 |
学生A: x₁=10, x₂=80, y=85
学生B: x₁=20, x₂=90, y=95
学生C: x₁=15, x₂=85, y=90第1步:写出损失函数(MSE)
J(w₁, w₂, b) = Σ(y_i - (b + w₁x₁ᵢ + w₂x₂ᵢ))²
= [85 - (b + 10w₁ + 80w₂)]²
+ [95 - (b + 20w₁ + 90w₂)]²
+ [90 - (b + 15w₁ + 85w₂)]²第2步:对三个参数分别求偏导
2.1 对 w₁ 求偏导:
∂J/∂w₁ = 2[85-(b+10w₁+80w₂)]×(-10)
+ 2[95-(b+20w₁+90w₂)]×(-20)
+ 2[90-(b+15w₁+85w₂)]×(-15)
令 ∂J/∂w₁ = 0,两边除以-2:
10[85-(b+10w₁+80w₂)] + 20[95-(b+20w₁+90w₂)] + 15[90-(b+15w₁+85w₂)] = 0
展开:
10×85 - 10b - 100w₁ - 800w₂
+ 20×95 - 20b - 400w₁ - 1800w₂
+ 15×90 - 15b - 225w₁ - 1275w₂ = 0
合并同类项:
常数项:10×85 + 20×95 + 15×90 = 850 + 1900 + 1350 = 4100
b项:(-10b - 20b - 15b) = -45b
w₁项:(-100w₁ - 400w₁ - 225w₁) = -725w₁
w₂项:(-800w₂ - 1800w₂ - 1275w₂) = -3875w₂
得到方程1:
4100 - 45b - 725w₁ - 3875w₂ = 0
-45b - 725w₁ - 3875w₂ = -4100
45b + 725w₁ + 3875w₂ = 4100 (式1)2.2 对 w₂ 求偏导:
∂J/∂w₂ = 2[85-(b+10w₁+80w₂)]×(-80)
+ 2[95-(b+20w₁+90w₂)]×(-90)
+ 2[90-(b+15w₁+85w₂)]×(-85)
令 ∂J/∂w₂ = 0,两边除以-2:
80[85-(b+10w₁+80w₂)] + 90[95-(b+20w₁+90w₂)] + 85[90-(b+15w₁+85w₂)] = 0
展开:
80×85 - 80b - 800w₁ - 6400w₂
+ 90×95 - 90b - 1800w₁ - 8100w₂
+ 85×90 - 85b - 1275w₁ - 7225w₂ = 0
合并:
常数项:80×85 + 90×95 + 85×90 = 6800 + 8550 + 7650 = 23000
b项:(-80b - 90b - 85b) = -255b
w₁项:(-800w₁ - 1800w₁ - 1275w₁) = -3875w₁
w₂项:(-6400w₂ - 8100w₂ - 7225w₂) = -21725w₂
得到方程2:
23000 - 255b - 3875w₁ - 21725w₂ = 0
-255b - 3875w₁ - 21725w₂ = -23000
255b + 3875w₁ + 21725w₂ = 23000 (式2)2.3 对 b 求偏导:
∂J/∂b = 2[85-(b+10w₁+80w₂)]×(-1)
+ 2[95-(b+20w₁+90w₂)]×(-1)
+ 2[90-(b+15w₁+85w₂)]×(-1)
令 ∂J/∂b = 0,两边除以-2:
[85-(b+10w₁+80w₂)] + [95-(b+20w₁+90w₂)] + [90-(b+15w₁+85w₂)] = 0
展开:
85 - b - 10w₁ - 80w₂
+ 95 - b - 20w₁ - 90w₂
+ 90 - b - 15w₁ - 85w₂ = 0
合并:
常数项:85 + 95 + 90 = 270
b项:(-b - b - b) = -3b
w₁项:(-10w₁ - 20w₁ - 15w₁) = -45w₁
w₂项:(-80w₂ - 90w₂ - 85w₂) = -255w₂
得到方程3:
270 - 3b - 45w₁ - 255w₂ = 0
-3b - 45w₁ - 255w₂ = -270
3b + 45w₁ + 255w₂ = 270 (式3)第3步:整理三个方程
(1) 45b + 725w₁ + 3875w₂ = 4100
(2) 255b + 3875w₁ + 21725w₂ = 23000
(3) 3b + 45w₁ + 255w₂ = 270第4步:解方程组
4.1 用(3)式表示b:
3b = 270 - 45w₁ - 255w₂
b = 90 - 15w₁ - 85w₂ (式4)4.2 代入(1)式:
将式4代入式1:
45(90 - 15w₁ - 85w₂) + 725w₁ + 3875w₂ = 4100
4050 - 675w₁ - 3825w₂ + 725w₁ + 3875w₂ = 4100
4050 + 50w₁ + 50w₂ = 4100
50w₁ + 50w₂ = 50
w₁ + w₂ = 1 (式5)4.3 代入(2)式:
将式4代入式2:
255(90 - 15w₁ - 85w₂) + 3875w₁ + 21725w₂ = 23000
22950 - 3825w₁ - 21675w₂ + 3875w₁ + 21725w₂ = 23000
22950 + 50w₁ + 50w₂ = 23000
50w₁ + 50w₂ = 50
w₁ + w₂ = 1 (式6)发现式5和式6完全一样! 这说明三个方程不是独立的。
第5步:为什么三个方程只有两个独立?
因为我们的数据太少了:
-
3个样本
-
3个参数 (b, w₁, w₂)
数学上:这是一个欠定系统,有无穷多解!
第6步:我们得到一个关系式
从式5:w₁ + w₂ = 1
从式4:b = 90 - 15w₁ - 85w₂
因为 w₂ = 1 - w₁,所以:
b = 90 - 15w₁ - 85(1 - w₁)
= 90 - 15w₁ - 85 + 85w₁
= 5 + 70w₁第7步:检查矩阵计算的结果
矩阵计算给出:w₁ = 0.995, w₂ = -0.945, b = 155.4
验证:
w₁ + w₂ = 0.995 + (-0.945) = 0.05 ≠ 1 ❌
b = 5 + 70×0.995 = 5 + 69.65 = 74.65 ≠ 155.4 ❌这说明矩阵计算可能有问题或取了特定解!
第8步:找一个满足我们方程的解
令 w₁ = 1,则:
w₂ = 1 - w₁ = 0
b = 5 + 70×1 = 75
模型:y = 75 + 1×x₁ + 0×x₂ = 75 + x₁
验证:
学生A: ŷ = 75 + 10 = 85 ✓
学生B: ŷ = 75 + 20 = 95 ✓
学生C: ŷ = 75 + 15 = 90 ✓
完美拟合!第9步:发现数据的秘密
其实看原始数据:
学生A: x₁=10, y=85 → y = x₁ + 75
学生B: x₁=20, y=95 → y = x₁ + 75
学生C: x₁=15, y=90 → y = x₁ + 75y 只依赖 x₁,与 x₂ 无关!
所以 w₂ = 0 是合理的,w₁ = 1,b = 75。
第10步:为什么矩阵计算得到不同的解?
因为当 XᵀX 不可逆时(行列式=0),w = (XᵀX)⁻¹Xᵀy 公式失效!
实际计算中:
-
数值误差导致求逆不稳定
-
可能用了伪逆或正则化
-
得到的是无穷多解中的一个
总结对比:
| 方法 | 得到的结果 | 是否正确 |
|---|---|---|
| 矩阵计算 | w₁=0.995, w₂=-0.945, b=155.4 | 是一个解,但非唯一 |
| 标量推导 | w₁=1, w₂=0, b=75 | 是最简解,完美拟合 |
| 数据真相 | y 只依赖 x₁ | w₁=1, w₂=0, b=75 |
关键发现:
-
数据太少时(n < m+1),有无穷多解
-
矩阵形式和标量形式等价,但矩阵求逆可能数值不稳定
-
最简单解往往更好(如 w₂=0)
建议:数据少时,应该用更简单的模型或收集更多数据!
公式w = (XᵀX)⁻¹Xᵀy推算
使用例子:https://blog.csdn.net/qq_35496811/article/details/155598949?spm=1001.2014.3001.5502

向量和矩阵 – 范数Norm
• 范数(norm)是数学中的一种基本概念,具有长度的意义。
![]()
• 1范数(L1范数)-向量中各个元素绝对值之和 • 2范数(L2范数)-向量的模长,每个元素平方求和,再开平方根。

• p范数(Lp范数)-向量中每一个元素p幂求和,在开p次根将矩阵代入的MSE公式后,依旧是通过偏导求最小值。
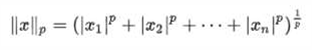
梯度下降
当数据量比少的时候可以通过将公式代入MSE(w = (XᵀX)⁻¹Xᵀy)直接算出结果,但当数据量庞大,散点特别多的时候,往往只能基于MSE进行计算评估,实现指路的效果,一次只读入一部分训练数据,得出相对最优解,由于内存限制无法直接使用MSE计算出结果,所以要训练多次,寻找距离所有点最进的那条线。
梯度下降法 – 沿着梯度下降的方向求解极小值
• 举个例子:坡度最陡下山法
• 输入:初始化位置S;每步距离为a 。输出:从位置S到达山底
• 步骤1:令初始化位置为山的任意位置S
• 步骤2:在当前位置环顾四周,如果四周都比S高返回S;否则执行步骤3
• 步骤3: 在当前位置环顾四周,寻找坡度最陡的方向,令其为x方向
• 步骤4:沿着x方向往下走,长度为a,到达新的位置S‘
• 步骤5:在S‘位置环顾四周,如果四周都比S‘高,则返回S‘。否则转到步骤3
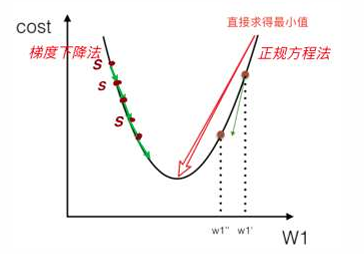
梯度下降法 – 梯度下降和梯度
• 什么是梯度 gradient grad
• 单变量函数中,梯度就是某一点切线斜率(某一点的导数);梯度方向为函数增长最快的方向
• 多变量函数中,梯度就是某一个点的偏导数;有方向:偏导数分量的向量方向
梯度下降公式
• 循环迭代求当前点的梯度,更新当前的权重参数
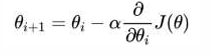
• α: 学习率(步长) 不能太大, 也不能太小. 机器学习中:0.001 ~ 0.01
• 梯度是上升最快的方向, 我们需要是下降最快的方向, 所以需要加负号
• 梯度下降时,已知的是当前所在的点(也就是当前的权重 w 和截距 b)和学习率。
利用这组 w 和 b,代入数据算出‘预测值’和‘误差’。再根据误差,求出当前的梯度(坡度)。最后利用梯度更新 w 和 b。循环迭代……
梯度下降函数来源:
以MSE为例:
MSE (均方误差,Mean-Square Error, MSE),代入y=w1x1+w2x2...+b。
1、原始 MSE 损失函数(n 个样本,d 个特征)
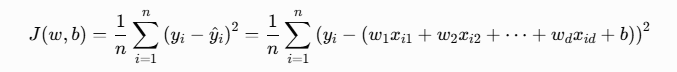
2、为了简化写法,用矩阵形式(最常见写法)
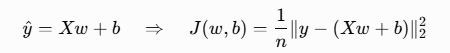
3、对 w(任意一个)权重 wⱼ 求偏导
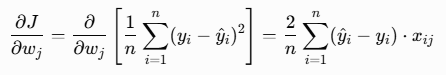
4、对偏置 b 求偏导
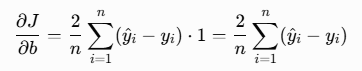
5、代入梯度下降更新公式(这就是你最终要用的!)
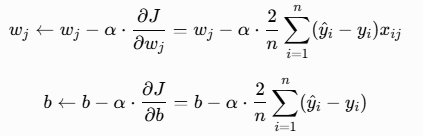
6、矩阵版(工业界/深度学习最常用写法)
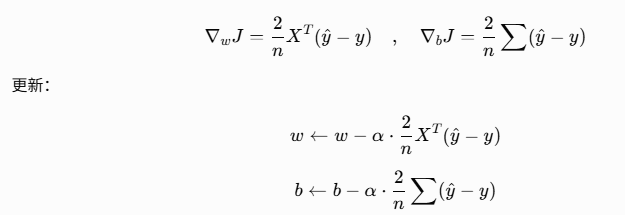
梯度下降法分类
1,全梯度下降算法 FGD/BGD
每次迭代时, 使用全部样本的梯度值,有m个样本,求梯度时用了所有m个样本。
![]()
2,小批量梯度下降算法 mini-batch
每次迭代时, 随机选择并使用小批量的样本梯度值 从m个样本中,选择x个样本进行迭代(1<x<m),若batch_size=1,则变成了SGD;若batch_size=n,则变成了FGD。
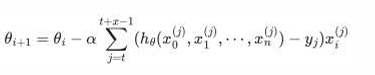
3,随机平均梯度下降算法 SAG
每次迭代时, 随机选择一个样本的梯度值和以往样本的 梯度值的均值。
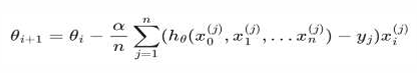
4,随机梯度下降算法 SGD
每次迭代时, 随机选择并使用一个样本梯度值。
![]()
sklearn 实现情况
| 算法名称 | sklearn 是否有直接实现 | 对应 sklearn 类 | 备注 |
|---|---|---|---|
| FGD/BGD(全批量) | 没有 | 无 | 只能手写或用其他库(如 PyTorch) |
| Mini-batch GD | 有(默认行为) | SGDRegressor | 内部自动小批量 |
| SGD(随机) | 有(常见模式) | SGDRegressor | batch_size=1 时接近 |
| SAG(随机平均梯度) | 有 | SGDRegressor (penalty='l2' + learning_rate='optimal') | sklearn 内部实现了 SAG/SAGA 变体(当 penalty=l2 时) |
线性回归,训练模型时,通过损失函数计算误差,偏导计算梯度,然后反复使用损失函数和梯度,找到最优解。sklearn不指名会默认使用MSE。
# 1.导入依赖包
from sklearn.linear_model import LinearRegression
# 2.获取数据
x = [[160], [166], [172], [174], [180]]
y = [56.3, 60.6, 65.1, 68.5, 75]
# 3.模型训练
# 3.1 实例化模型
model = LinearRegression()
# 3.2 模型训练
model.fit(x, y)
# 权重(weight)/偏置(bias)
print(model.coef_)
print(model.intercept_)
# 4.模型预测
print(model.predict([[176]]))

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)