随机森林分析在生物信息学中的应用
随机森林(Random Forest)是一种基于集成学习(Ensemble Learning)的机器学习算法,它通过构建多个决策树(Decision Trees)并结合它们的预测结果来提高模型的准确性和鲁棒性。其核心思想是“集体决策”,通过投票(分类任务)或平均(回归任务)来减少过拟合风险。
在生物信息学中的应用
1. 疾病分类与生物标志物发现:通过分析高通量基因表达数据(如 RNA-seq、微阵列),区分癌症亚型或预测疾病状态,筛选关键基因作为诊断标志物;
2. 非同义突变致病性预测:如工具 MutPred 结合随机森林评估突变对蛋白质功能的影响;从全基因组关联研究中识别与疾病相关的单核苷酸多态性(SNP);
3. 蛋白质-蛋白质相互作用预测:利用序列或结构特征预测互作关系,预测蛋白质的亚细胞定位或酶功能分类(如工具 ProtForest);
4. 微生物群落分析:从宏基因组数据中分类微生物物种或预测功能(如肠道菌群与疾病的关联);
5. 药物反应预测:基于患者基因组或转录组数据预测药物敏感性(如癌症药物筛选);
6. 细胞类型注释:通过 scRNA-seq 数据自动聚类和标记细胞类型(如工具 SCINA)。
这里给大家推荐一个在线分析平台【掌上生信绘图平台(https://handybioplot.cn)】,无需编写代码,只需要上传文件即可一键分析并自动绘制相关图片,为您节约宝贵的时间成本。
使用说明
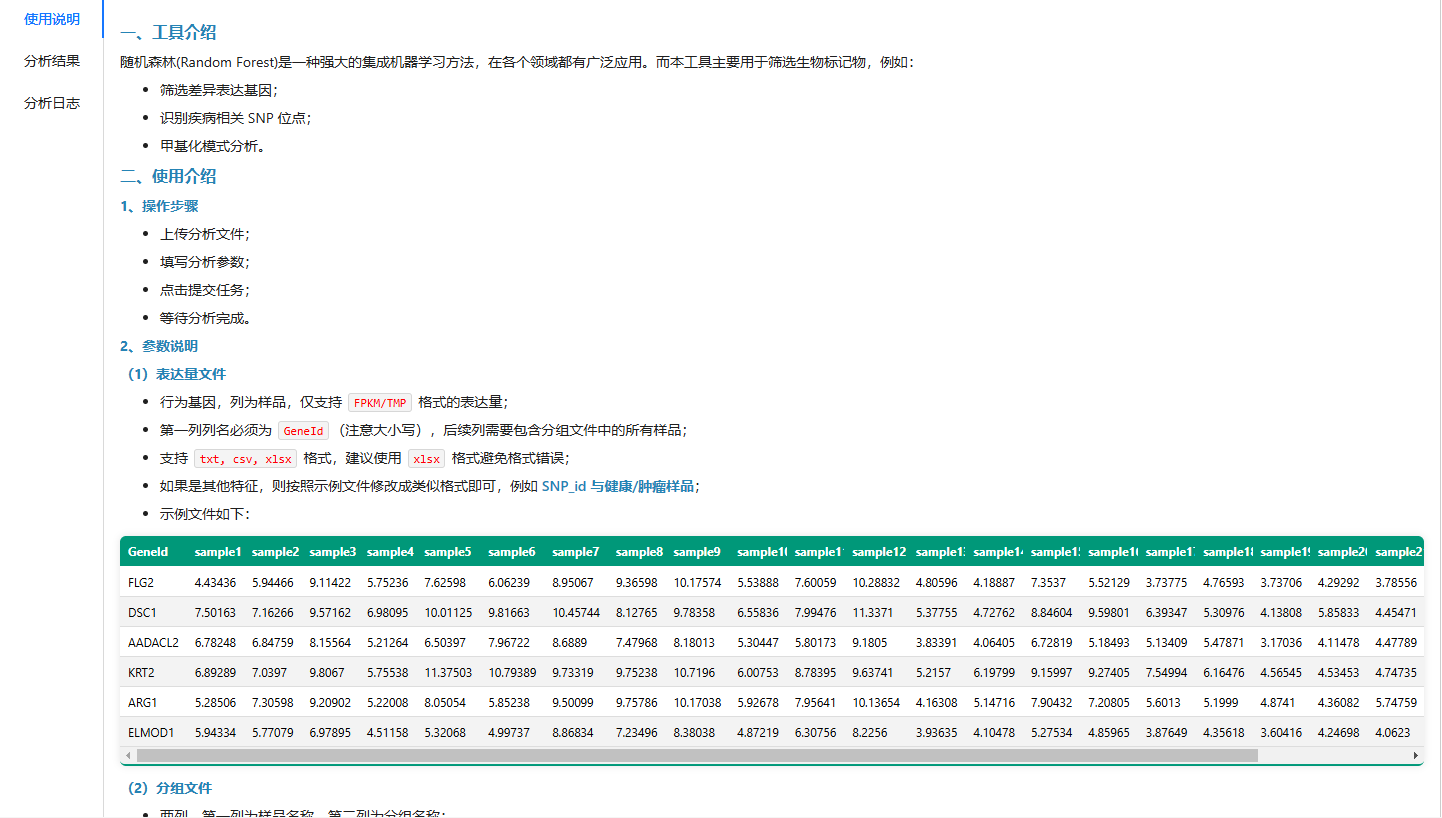
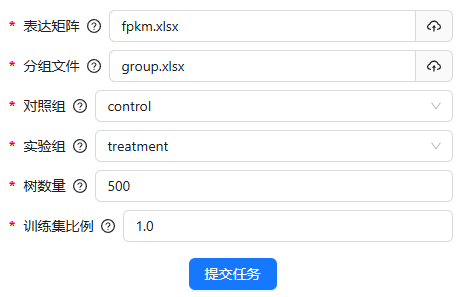
分析参数
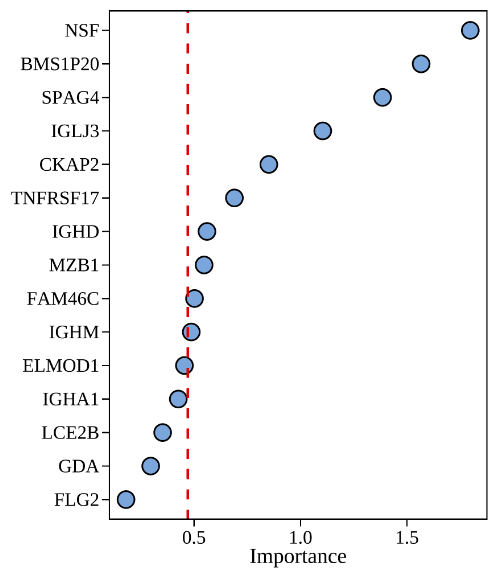
特征重要性排序图
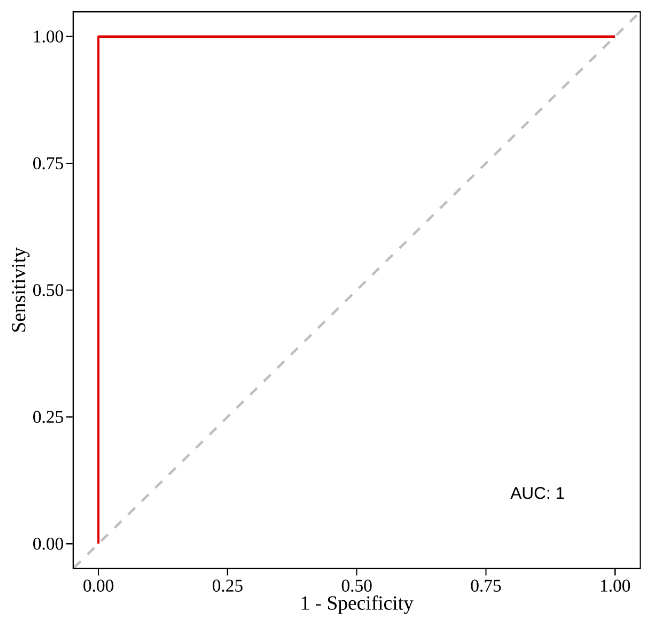
roc图
绘图参数
结果图片还可以使用绘图参数自由修改
任务列表
如果分析结果不满意,可以修改参数重新提交分析,所有任务独立记录,可自由切换查看结果

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)