人工智能: 矩阵从数学基础到项目实战!
1. 矩阵
我将从多个方面详细讲解矩阵的概念和应用。
1. 矩阵的基本概念
矩阵是一个按照长方形阵列排列的数或表达式的集合。一个 m×n 的矩阵有 m 行和 n 列,记作:
A=(a11a12⋯a1na21a22⋯a2n⋮⋮⋱⋮am1am2⋯amn)A = \begin{pmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \end{pmatrix}A= a11a21⋮am1a12a22⋮am2⋯⋯⋱⋯a1na2n⋮amn

2. 特殊类型矩阵
- 方阵:行数等于列数的矩阵(n×n)
- 对角矩阵:非对角线元素都为0
- 单位矩阵:主对角线元素为1,其他元素为0
- 上三角矩阵:主对角线以下元素都为0
- 下三角矩阵:主对角线以上元素都为0
- 对称矩阵:转置等于自身(A=ATA = A^TA=AT)
3. 矩阵运算
3.1 矩阵加减法
两个同型矩阵对应元素相加减:
A±B=(a11±b11a12±b12a21±b21a22±b22)A \pm B = \begin{pmatrix} a_{11} \pm b_{11} & a_{12} \pm b_{12} \\ a_{21} \pm b_{21} & a_{22} \pm b_{22} \end{pmatrix}A±B=(a11±b11a21±b21a12±b12a22±b22)
3.2 矩阵乘法
矩阵A(m×n)与B(n×p)相乘得到C(m×p):
(AB)ij=∑k=1naikbkj(AB)_{ij} = \sum_{k=1}^n a_{ik}b_{kj}(AB)ij=k=1∑naikbkj
3.3 矩阵转置
将矩阵的行列互换:
(AT)ij=Aji(A^T)_{ij} = A_{ji}(AT)ij=Aji
4. 矩阵的重要性质
-
行列式:表示方阵的"体积"
det(A)=∣A∣=∣a11a12a21a22∣=a11a22−a12a21\det(A) = |A| = \begin{vmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \end{vmatrix} = a_{11}a_{22} - a_{12}a_{21}det(A)=∣A∣= a11a21a12a22 =a11a22−a12a21 -
矩阵的秩:线性无关的行或列的最大数目
- 满秩:秩等于较小的行数或列数
- 秩的性质:rank(AB)≤min(rank(A),rank(B))rank(AB) \leq \min(rank(A), rank(B))rank(AB)≤min(rank(A),rank(B))
-
逆矩阵:若存在矩阵B使得AB=BA=I,则B为A的逆矩阵
A−1=1det(A)adj(A)A^{-1} = \frac{1}{\det(A)}\text{adj}(A)A−1=det(A)1adj(A)
2. 矩阵习题一
题目背景
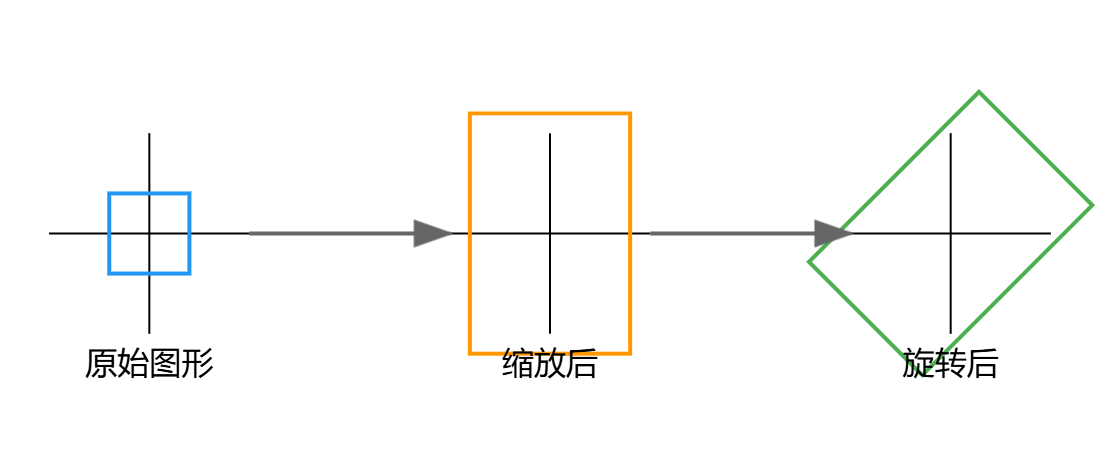
在某图像处理系统中,需要对一张图片进行一系列变换。已知:
- 原始图像经过缩放矩阵 AAA 和旋转矩阵 BBB 变换
- 缩放矩阵 A=(2003)A = \begin{pmatrix} 2 & 0 \\ 0 & 3 \end{pmatrix}A=(2003)
- 旋转矩阵 B=(cos45°−sin45°sin45°cos45°)B = \begin{pmatrix} \cos 45° & -\sin 45° \\ \sin 45° & \cos 45° \end{pmatrix}B=(cos45°sin45°−sin45°cos45°)
求:
- 计算复合变换矩阵 C=BAC = BAC=BA
- 验证矩阵 AAA 是否可逆
- 求矩阵 AAA 的行列式
- 判断矩阵 AAA 和 BBB 是否可交换
相关公式
-
矩阵乘法公式:
(AB)ij=∑k=1naikbkj(AB)_{ij} = \sum_{k=1}^n a_{ik}b_{kj}(AB)ij=k=1∑naikbkj -
行列式公式(2×2矩阵):
det(A)=∣a11a12a21a22∣=a11a22−a12a21\det(A) = \begin{vmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \end{vmatrix} = a_{11}a_{22} - a_{12}a_{21}det(A)= a11a21a12a22 =a11a22−a12a21 -
矩阵可逆的条件:
- 行列式不为零:det(A)≠0\det(A) \neq 0det(A)=0
- 满秩:rank(A)=nrank(A) = nrank(A)=n(方阵)
-
矩阵交换性判定:
AB=BAAB = BAAB=BA
解题步骤
1. 计算复合变换矩阵
首先将旋转矩阵 BBB 具体化(cos45°=sin45°=22\cos 45° = \sin 45° = \frac{\sqrt{2}}{2}cos45°=sin45°=22):
B=(22−222222)B = \begin{pmatrix} \frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \\ \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \end{pmatrix}B=(2222−2222)
计算 C=BAC = BAC=BA:
C=(22−222222)(2003)=(2−3222322)\begin{align*} C &= \begin{pmatrix} \frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \\ \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \end{pmatrix} \begin{pmatrix} 2 & 0 \\ 0 & 3 \end{pmatrix} \\ &= \begin{pmatrix} \sqrt{2} & -\frac{3\sqrt{2}}{2} \\ \sqrt{2} & \frac{3\sqrt{2}}{2} \end{pmatrix} \end{align*}C=(2222−2222)(2003)=(22−232232)
2. 验证矩阵A的可逆性
计算行列式:
det(A)=∣2003∣=2⋅3−0⋅0=6≠0\det(A) = \begin{vmatrix} 2 & 0 \\ 0 & 3 \end{vmatrix} = 2 \cdot 3 - 0 \cdot 0 = 6 \neq 0det(A)=
2003
=2⋅3−0⋅0=6=0
因为行列式不为零,所以矩阵 AAA 可逆。
3. 计算行列式
已在步骤2中完成,det(A)=6\det(A) = 6det(A)=6
4. 判断矩阵交换性
计算 ABABAB:
AB=(2003)(22−222222)=(2−2322322)\begin{align*} AB &= \begin{pmatrix} 2 & 0 \\ 0 & 3 \end{pmatrix} \begin{pmatrix} \frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \\ \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \end{pmatrix} \\ &= \begin{pmatrix} \sqrt{2} & -\sqrt{2} \\ \frac{3\sqrt{2}}{2} & \frac{3\sqrt{2}}{2} \end{pmatrix} \end{align*}AB=(2003)(2222−2222)=(2232−2232)
由于 AB≠BAAB \neq BAAB=BA,所以这两个矩阵不可交换。
总结与分析
-
知识点覆盖:
- 矩阵乘法
- 行列式计算
- 矩阵可逆性
- 矩阵交换性
-
几何意义:
- 缩放变换改变图形的大小
- 旋转变换改变图形的方向
- 复合变换的顺序会影响最终结果
-
计算技巧:
- 先将特殊角的三角函数值具体化
- 矩阵乘法注意顺序
- 利用对角矩阵简化计算
-
应用价值:
- 图像处理
- 计算机图形学
- 几何变换
这个习题展示了矩阵在图形变换中的实际应用,通过具体的计算帮助理解矩阵运算的性质和几何意义。理解这些概念对于图形编程和图像处理至关重要。
3. 矩阵习题
题目背景
在一个振动系统研究中,有一个描述系统状态的矩阵:
A=(4−224)A = \begin{pmatrix} 4 & -2 \\ 2 & 4 \end{pmatrix}A=(42−24)
需要:
- 求矩阵A的特征值和特征向量
- 判断矩阵A是否可对角化
- 写出矩阵A的对角化分解形式
相关公式
-
特征值方程:
det(A−λI)=0\det(A - \lambda I) = 0det(A−λI)=0
其中 λ\lambdaλ 为特征值,III 为单位矩阵 -
特征向量方程:
(A−λI)v⃗=0⃗(A - \lambda I)\vec{v} = \vec{0}(A−λI)v=0
其中 v⃗\vec{v}v 为对应于特征值 λ\lambdaλ 的特征向量 -
对角化分解:
A=PDP−1A = PDP^{-1}A=PDP−1
其中 DDD 是对角矩阵,PPP 是特征向量矩阵
解题步骤
1. 求特征值
计算特征方程:
det(A−λI)=∣4−λ−224−λ∣=0=(4−λ)2−(−2)(2)=0=(4−λ)2−4=0=λ2−8λ+12=0\begin{align*} \det(A - \lambda I) &= \begin{vmatrix} 4-\lambda & -2 \\ 2 & 4-\lambda \end{vmatrix} = 0 \\ &= (4-\lambda)^2 - (-2)(2) = 0 \\ &= (4-\lambda)^2 - 4 = 0 \\ &= \lambda^2 - 8\lambda + 12 = 0 \end{align*}det(A−λI)=
4−λ2−24−λ
=0=(4−λ)2−(−2)(2)=0=(4−λ)2−4=0=λ2−8λ+12=0
解二次方程:
(λ−6)(λ−2)=0(\lambda - 6)(\lambda - 2) = 0(λ−6)(λ−2)=0
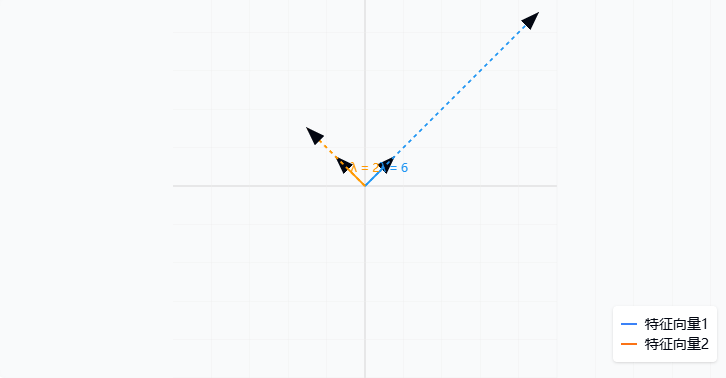
得到特征值:λ1=6\lambda_1 = 6λ1=6,λ2=2\lambda_2 = 2λ2=2
2. 求特征向量
对于 λ1=6\lambda_1 = 6λ1=6:
(A−6I)v1⃗=(−2−22−2)(xy)=(00)(A - 6I)\vec{v_1} = \begin{pmatrix} -2 & -2 \\ 2 & -2 \end{pmatrix}\begin{pmatrix} x \\ y \end{pmatrix} = \begin{pmatrix} 0 \\ 0 \end{pmatrix}(A−6I)v1=(−22−2−2)(xy)=(00)
解得:x=yx = yx=y,可取 v1⃗=(11)\vec{v_1} = \begin{pmatrix} 1 \\ 1 \end{pmatrix}v1=(11)
对于 λ2=2\lambda_2 = 2λ2=2:
(A−2I)v2⃗=(2−222)(xy)=(00)(A - 2I)\vec{v_2} = \begin{pmatrix} 2 & -2 \\ 2 & 2 \end{pmatrix}\begin{pmatrix} x \\ y \end{pmatrix} = \begin{pmatrix} 0 \\ 0 \end{pmatrix}(A−2I)v2=(22−22)(xy)=(00)
解得:x=−yx = -yx=−y,可取 v2⃗=(−11)\vec{v_2} = \begin{pmatrix} -1 \\ 1 \end{pmatrix}v2=(−11)
3. 判断可对角化性
因为:
7. 有两个不同的特征值
8. 对应的特征向量线性无关
所以矩阵A可以对角化。
4. 写出对角化分解
P=(1−111)P = \begin{pmatrix} 1 & -1 \\ 1 & 1 \end{pmatrix}P=(11−11)
D=(6002)D = \begin{pmatrix} 6 & 0 \\ 0 & 2 \end{pmatrix}D=(6002)
A=PDP−1A = PDP^{-1}A=PDP−1
总结与分析
-
知识点覆盖:
- 特征值计算
- 特征向量求解
- 矩阵对角化
- 相似变换
-
几何意义:
- 特征值表示沿特征向量方向的伸缩比例
- 特征向量表示保持方向不变的向量
- 对角化表示找到主轴方向
- 计算技巧:
- 利用特征方程求特征值
- 求解线性方程组得到特征向量
- 检查特征向量的线性无关性
- 应用价值:
- 振动分析
- 主成分分析
- 数据降维
- 动力系统分析
这个习题展示了矩阵特征值和特征向量的重要应用。理解这些概念对于:
- 系统动力学分析
- 数据降维处理
- 振动模式分析
都有重要意义。特别是在工程和数据科学领域,这些工具被广泛应用。
4. 矩阵习题
题目背景
在某工厂的生产规划中:
- 有三种原料 (x1,x2,x3)(x_1, x_2, x_3)(x1,x2,x3)
- 需要生产两种产品
- 原料和产品关系由矩阵方程表示:
Ax⃗=b⃗A\vec{x} = \vec{b}Ax=b
其中:
A=(213426),b⃗=(816)A = \begin{pmatrix} 2 & 1 & 3 \\ 4 & 2 & 6 \end{pmatrix}, \quad \vec{b} = \begin{pmatrix} 8 \\ 16 \end{pmatrix}A=(241236),b=(816)
需要:
- 求矩阵A的秩
- 判断方程组是否有解
- 若有解,求通解
相关公式
-
矩阵的秩:
- 行秩:线性无关的行向量个数
- 列秩:线性无关的列向量个数
- 定理:行秩 = 列秩 = 秩
-
齐次方程组:
Ax⃗=0⃗A\vec{x} = \vec{0}Ax=0
的解构成解空间(零空间) -
增广矩阵:
[A∣b⃗]=(213∣8426∣16)[A|\vec{b}] = \begin{pmatrix} 2 & 1 & 3 & | & 8 \\ 4 & 2 & 6 & | & 16 \end{pmatrix}[A∣b]=(241236∣∣816)
解题步骤
1. 求矩阵A的秩
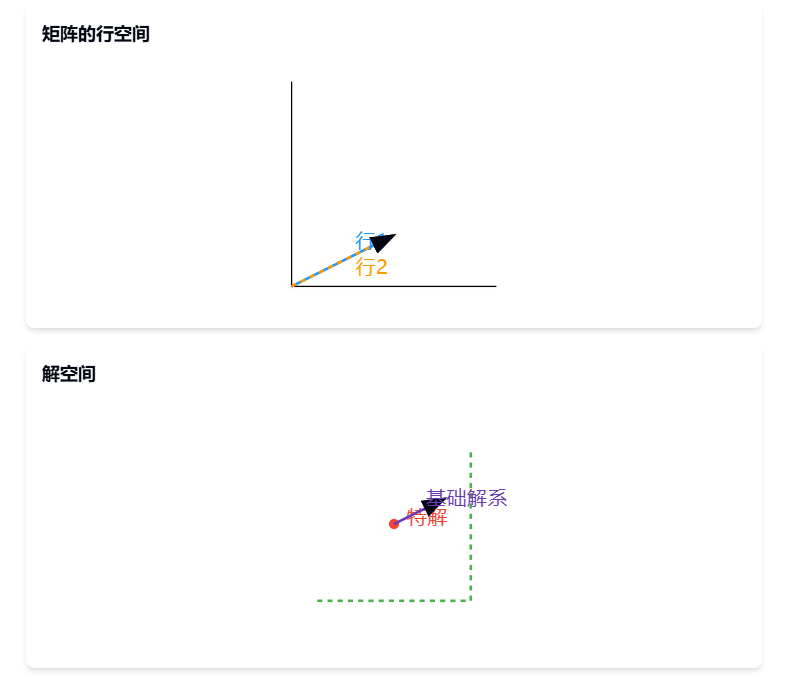
观察A的两行:
(213426)\begin{pmatrix} 2 & 1 & 3 \\ 4 & 2 & 6 \end{pmatrix}(241236)
可以看到第二行是第一行的2倍,因此:
- 两行线性相关
- rank(A)=1rank(A) = 1rank(A)=1
2. 判断方程组是否有解
构造增广矩阵并进行行简化:
(213∣8426∣16)\begin{pmatrix} 2 & 1 & 3 & | & 8 \\ 4 & 2 & 6 & | & 16 \end{pmatrix}(241236∣∣816)
第二行减去第一行的2倍:
(213∣8000∣0)\begin{pmatrix} 2 & 1 & 3 & | & 8 \\ 0 & 0 & 0 & | & 0 \end{pmatrix}(201030∣∣80)
因为:
- rank(A)=rank[A∣b⃗]=1rank(A) = rank[A|\vec{b}] = 1rank(A)=rank[A∣b]=1
- 增广矩阵的秩等于系数矩阵的秩
所以方程组有解。
3. 求通解
方程可简化为:
2x1+x2+3x3=82x_1 + x_2 + 3x_3 = 82x1+x2+3x3=8
令 x2=tx_2 = tx2=t,x3=sx_3 = sx3=s 为自由变量,则:
x1=4−12t−32sx_1 = 4 - \frac{1}{2}t - \frac{3}{2}sx1=4−21t−23s
通解为:
(x1x2x3)=(400)+t(−1210)+s(−3201)\begin{pmatrix} x_1 \\ x_2 \\ x_3 \end{pmatrix} = \begin{pmatrix} 4 \\ 0 \\ 0 \end{pmatrix} + t\begin{pmatrix} -\frac{1}{2} \\ 1 \\ 0 \end{pmatrix} + s\begin{pmatrix} -\frac{3}{2} \\ 0 \\ 1 \end{pmatrix}
x1x2x3
=
400
+t
−2110
+s
−2301
其中 t,st, st,s 为任意实数。
总结与分析
-
知识点覆盖:
- 矩阵的秩
- 线性相关性
- 线性方程组
- 通解结构
-
几何意义:
- 秩表示线性无关的向量个数
- 解空间是一个平面
- 通解包含特解和齐次解
-
计算技巧:
- 观察行向量关系判断秩
- 使用行简化求解
- 选取合适的自由变量
-
应用价值:
- 生产规划
- 资源分配
- 系统优化
- 数据分析
这个习题展示了矩阵在实际生产问题中的应用,特别强调了:
- 线性相关性的判断
- 解的存在性条件
- 解空间的结构
理解这些概念对于处理实际工程问题、优化计算和系统分析都很重要
5. 矩阵习题
题目背景
在某通信系统中,信号传输的状态转换由矩阵描述:
A=(31−1−1111−13)A = \begin{pmatrix} 3 & 1 & -1 \\ -1 & 1 & 1 \\ 1 & -1 & 3 \end{pmatrix}A=
3−1111−1−113
需要:
- 判断A是否为对称矩阵
- 求A的特征值和特征向量
- 判断A是否可对角化,若可以,求对角化矩阵
相关公式
-
对称矩阵判定:
A=ATA = A^TA=AT -
特征值方程:
det(A−λI)=0\det(A - \lambda I) = 0det(A−λI)=0 -
对角化条件:
- 特征值互不相同,或
- n个线性无关的特征向量
-
对角化公式:
A=PDP−1A = PDP^{-1}A=PDP−1
其中D是对角矩阵,P是特征向量矩阵
解题步骤
1. 判断对称性
计算 ATA^TAT:
AT=(3−1111−1−113)A^T = \begin{pmatrix} 3 & -1 & 1 \\ 1 & 1 & -1 \\ -1 & 1 & 3 \end{pmatrix}AT=
31−1−1111−13
由于 A=ATA = A^TA=AT,所以A是对称矩阵。
2. 求特征值
特征方程:
det(A−λI)=∣3−λ1−1−11−λ11−13−λ∣=0\begin{align*} \det(A - \lambda I) &= \begin{vmatrix} 3-\lambda & 1 & -1 \\ -1 & 1-\lambda & 1 \\ 1 & -1 & 3-\lambda \end{vmatrix} = 0 \end{align*}det(A−λI)=
3−λ−1111−λ−1−113−λ
=0
展开得:
−λ3+7λ2−14λ+8=0-\lambda^3 + 7\lambda^2 - 14\lambda + 8 = 0−λ3+7λ2−14λ+8=0
因式分解:
−(λ−4)(λ−2)(λ−1)=0-(\lambda - 4)(\lambda - 2)(\lambda - 1) = 0−(λ−4)(λ−2)(λ−1)=0
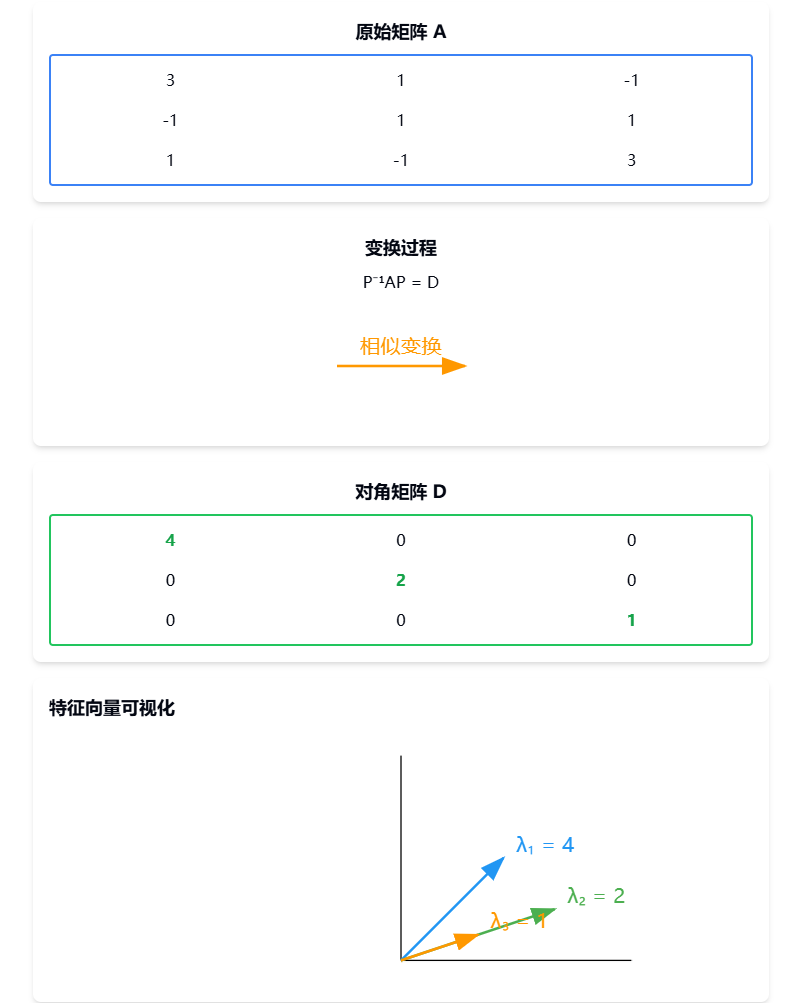
得特征值:λ1=4\lambda_1 = 4λ1=4,λ2=2\lambda_2 = 2λ2=2,λ3=1\lambda_3 = 1λ3=1
3. 求特征向量
对 λ1=4\lambda_1 = 4λ1=4:
(A−4I)v1⃗=0⃗(A - 4I)\vec{v_1} = \vec{0}(A−4I)v1=0
解得:v1⃗=(1,−1,1)T\vec{v_1} = (1, -1, 1)^Tv1=(1,−1,1)T
对 λ2=2\lambda_2 = 2λ2=2:
(A−2I)v2⃗=0⃗(A - 2I)\vec{v_2} = \vec{0}(A−2I)v2=0
解得:v2⃗=(1,0,−1)T\vec{v_2} = (1, 0, -1)^Tv2=(1,0,−1)T
对 λ3=1\lambda_3 = 1λ3=1:
(A−I)v3⃗=0⃗(A - I)\vec{v_3} = \vec{0}(A−I)v3=0
解得:v3⃗=(1,2,1)T\vec{v_3} = (1, 2, 1)^Tv3=(1,2,1)T
4. 对角化
因为有三个不同的特征值,所以A可对角化。
对角化矩阵:
P=(111−1021−11)P = \begin{pmatrix} 1 & 1 & 1 \\ -1 & 0 & 2 \\ 1 & -1 & 1 \end{pmatrix}P=
1−1110−1121
D=(400020001)D = \begin{pmatrix} 4 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 1 \end{pmatrix}D= 400020001
总结与分析
-
知识点覆盖:
- 对称矩阵性质
- 特征值计算
- 特征向量求解
- 矩阵对角化
-
几何意义:
- 对称矩阵的特征向量正交
- 特征值表示变换的缩放
- 对角化表示基变换
-
计算技巧:
- 利用对称性简化计算
- 特征方程的因式分解
- 特征向量的标准化
- 应用价值:
- 信号处理
- 振动分析
- 数据压缩
- 主成分分析
这个习题展示了矩阵对角化的完整过程,特别强调了:
- 对称矩阵的特殊性质
- 特征值和特征向量的计算
- 对角化的几何意义
- 实际应用场景
这些概念在信号处理、数据分析等领域有重要应用。理解对角化不仅有助于简化矩阵计算,也能帮助我们理解系统的本质特性。
6. 矩阵习题
题目背景
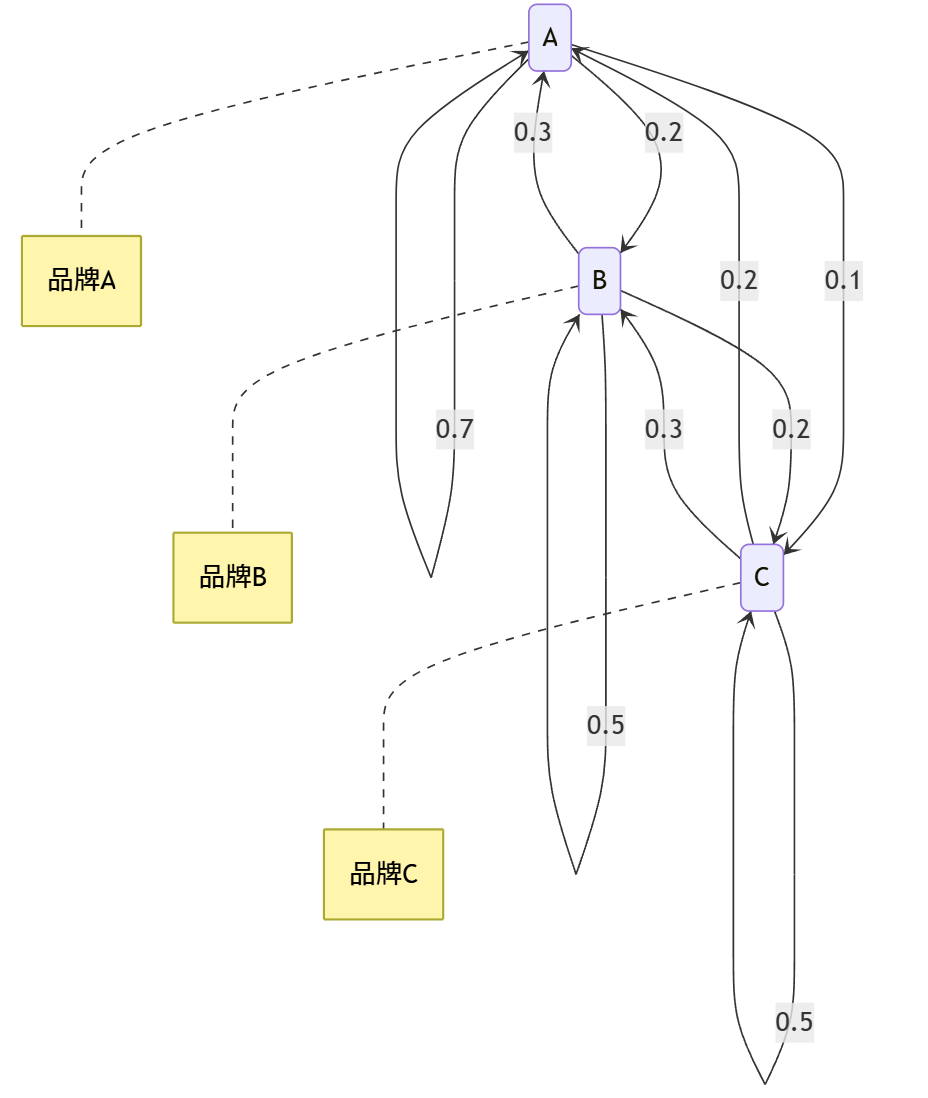
某电商平台研究用户在三个品牌(A、B、C)之间的转化率。每月品牌间的转化概率由转移矩阵P表示:
P=(0.70.20.10.30.50.20.20.30.5)P = \begin{pmatrix} 0.7 & 0.2 & 0.1 \\ 0.3 & 0.5 & 0.2 \\ 0.2 & 0.3 & 0.5 \end{pmatrix}P= 0.70.30.20.20.50.30.10.20.5
需要:
- 验证P是否为随机矩阵(每行和为1)
- 计算两个月后的转化概率矩阵 P2P^2P2
- 预测系统的稳态分布
相关公式
-
随机矩阵的性质:
- 所有元素非负
- 每行元素之和为1
∑j=1npij=1\sum_{j=1}^n p_{ij} = 1j=1∑npij=1
-
矩阵幂运算:
Pn=P⋅Pn−1P^n = P \cdot P^{n-1}Pn=P⋅Pn−1 -
稳态分布方程:
πP=π\pi P = \piπP=π
其中 π\piπ 是稳态分布向量
解题步骤
1. 验证随机矩阵
检查每行之和:
- 第一行:0.7 + 0.2 + 0.1 = 1.0
- 第二行:0.3 + 0.5 + 0.2 = 1.0
- 第三行:0.2 + 0.3 + 0.5 = 1.0
所有元素都非负,且每行和为1,因此P是随机矩阵。
2. 计算两个月后的转化概率
计算 P2=P×PP^2 = P \times PP2=P×P:
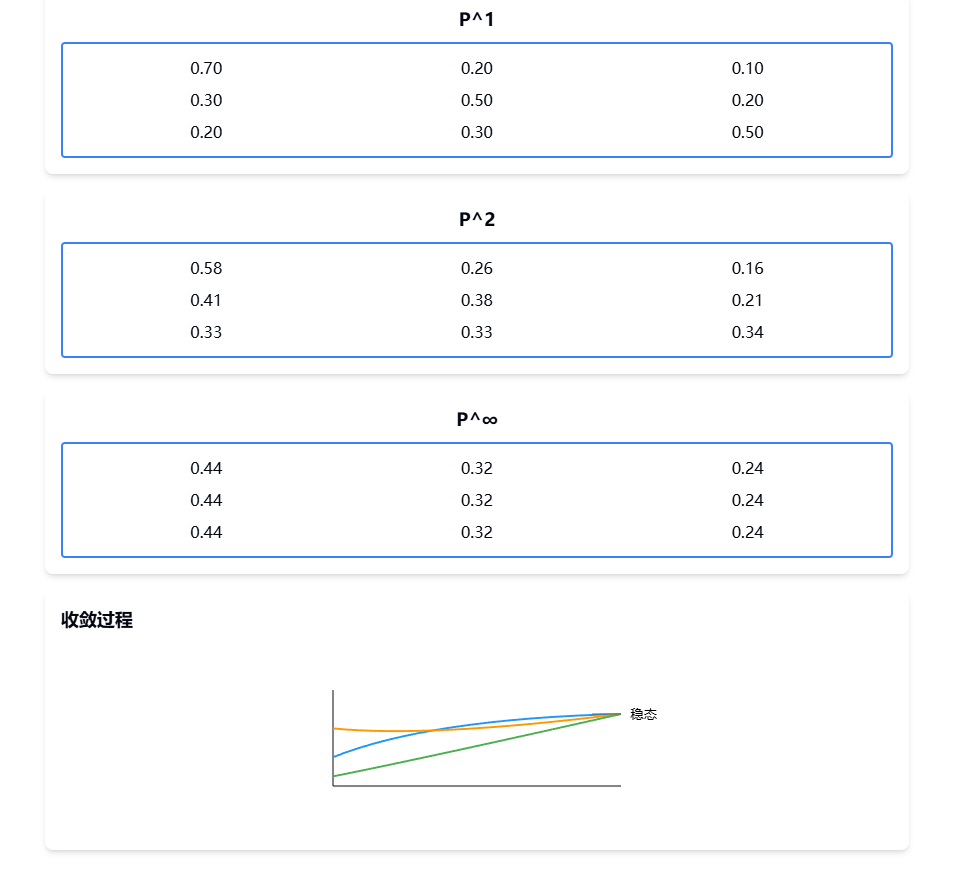
P2=(0.70.20.10.30.50.20.20.30.5)×(0.70.20.10.30.50.20.20.30.5)=(0.580.260.160.410.380.210.330.330.34)\begin{align*} P^2 &= \begin{pmatrix} 0.7 & 0.2 & 0.1 \\ 0.3 & 0.5 & 0.2 \\ 0.2 & 0.3 & 0.5 \end{pmatrix} \times \begin{pmatrix} 0.7 & 0.2 & 0.1 \\ 0.3 & 0.5 & 0.2 \\ 0.2 & 0.3 & 0.5 \end{pmatrix} \\ &= \begin{pmatrix} 0.58 & 0.26 & 0.16 \\ 0.41 & 0.38 & 0.21 \\ 0.33 & 0.33 & 0.34 \end{pmatrix} \end{align*}P2= 0.70.30.20.20.50.30.10.20.5 × 0.70.30.20.20.50.30.10.20.5 = 0.580.410.330.260.380.330.160.210.34
3. 求稳态分布
解方程组:
πP=π\pi P = \piπP=π
{0.7π1+0.3π2+0.2π3=π10.2π1+0.5π2+0.3π3=π20.1π1+0.2π2+0.5π3=π3π1+π2+π3=1\begin{cases} 0.7\pi_1 + 0.3\pi_2 + 0.2\pi_3 = \pi_1 \\ 0.2\pi_1 + 0.5\pi_2 + 0.3\pi_3 = \pi_2 \\ 0.1\pi_1 + 0.2\pi_2 + 0.5\pi_3 = \pi_3 \\ \pi_1 + \pi_2 + \pi_3 = 1 \end{cases}⎩
⎨
⎧0.7π1+0.3π2+0.2π3=π10.2π1+0.5π2+0.3π3=π20.1π1+0.2π2+0.5π3=π3π1+π2+π3=1
解得稳态分布:
π=(0.44,0.32,0.24)\pi = (0.44, 0.32, 0.24)π=(0.44,0.32,0.24)
总结与分析
-
知识点覆盖:
- 随机矩阵
- 矩阵幂运算
- 稳态分布
- 马尔可夫链
-
几何意义:
- 转移概率表示状态间的流动
- 矩阵幂表示多步转移
- 稳态表示长期行为
-
计算技巧:
- 验证随机矩阵的行和
- 利用矩阵乘法计算多步转移
- 求解线性方程组获取稳态
-
应用价值:
- 市场份额预测
- 用户行为分析
- 品牌竞争研究
- 长期趋势预测
这个习题展示了马尔可夫链在市场分析中的应用,特别强调了:
- 转移概率的表示
- 多步转移的计算
- 长期行为的预测
- 稳态的意义
这种分析方法在市场研究、用户行为分析等领域有广泛应用,能够帮助我们理解系统的长期演化趋势。
7. 人工智能中,矩阵 综合实战
1. 案例背景
某图像识别系统需要实现手写数字识别(MNIST数据集),使用简单的神经网络结构:
- 输入层:784个节点(28×28像素)
- 隐藏层:128个节点
- 输出层:10个节点(0-9的数字)

2. 为什么选用矩阵
-
高效的并行计算:
- 矩阵运算可以同时处理大量数据
- 支持GPU加速
- 减少循环操作
-
数据表示优势:
- 自然表示多维特征
- 方便进行批量处理
- 紧凑的数学表达
-
运算便利性:
- 统一的数学运算框架
- 方便求导和反向传播
- 易于实现向量化操作
3. 如何使用矩阵
3.1 数据表示
# 输入图像矩阵化
X = np.array(image).reshape(1, 784) # 1×784
# 权重矩阵
W1 = np.random.randn(784, 128) * 0.01 # 784×128
W2 = np.random.randn(128, 10) * 0.01 # 128×10
# 偏置向量
b1 = np.zeros((1, 128)) # 1×128
b2 = np.zeros((1, 10)) # 1×10
3.2 前向传播
def forward(X, W1, b1, W2, b2):
# 隐藏层
Z1 = np.dot(X, W1) + b1 # (1×784) · (784×128) = (1×128)
A1 = sigmoid(Z1) # (1×128)
# 输出层
Z2 = np.dot(A1, W2) + b2 # (1×128) · (128×10) = (1×10)
A2 = softmax(Z2) # (1×10)
return Z1, A1, Z2, A2
3.3 反向传播
def backward(X, Y, Z1, A1, Z2, A2, W1, W2):
m = X.shape[0]
# 输出层误差
dZ2 = A2 - Y # (1×10)
dW2 = np.dot(A1.T, dZ2) # (128×1) · (1×10) = (128×10)
db2 = np.sum(dZ2, axis=0, keepdims=True)
# 隐藏层误差
dZ1 = np.dot(dZ2, W2.T) * sigmoid_derivative(Z1)
dW1 = np.dot(X.T, dZ1) # (784×1) · (1×128) = (784×128)
db1 = np.sum(dZ1, axis=0, keepdims=True)
return dW1, db1, dW2, db2
4. 整体解决思路
4.1 预处理阶段
- 图像标准化:
def preprocess(image): # 灰度化 gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 归一化 normalized = gray / 255.0 # 展平 flattened = normalized.reshape(1, -1) return flattened
4.2 模型训练
def train(X_train, Y_train, learning_rate=0.01, epochs=100):
m = X_train.shape[0]
W1, b1, W2, b2 = initialize_parameters()
for epoch in range(epochs):
# 前向传播
Z1, A1, Z2, A2 = forward(X_train, W1, b1, W2, b2)
# 计算损失
cost = compute_cost(A2, Y_train)
# 反向传播
dW1, db1, dW2, db2 = backward(X_train, Y_train, Z1, A1, Z2, A2, W1, W2)
# 更新参数
W1 = W1 - learning_rate * dW1
b1 = b1 - learning_rate * db1
W2 = W2 - learning_rate * dW2
b2 = b2 - learning_rate * db2
if epoch % 10 == 0:
print(f"Epoch {epoch}, Cost: {cost}")
return W1, b1, W2, b2
4.3 预测过程
def predict(X, W1, b1, W2, b2):
# 前向传播
_, _, _, A2 = forward(X, W1, b1, W2, b2)
# 获取最大概率的类别
predictions = np.argmax(A2, axis=1)
return predictions
5. 关键矩阵运算的优化
-
批量处理:
# 使用mini-batch而不是单个样本 batch_size = 32 num_batches = len(X_train) // batch_size -
矩阵运算优化:
# 使用矩阵乘法代替循环 Z = np.dot(X, W) # 比for循环快得多 -
内存优化:
# 就地操作避免创建新矩阵 A += b # 比 A = A + b 更高效
6. 总结
矩阵在神经网络中的应用优势:
-
计算效率:
- 批量数据处理
- 并行计算支持
- 优化的数学运算
-
实现简洁:
- 清晰的数学表达
- 统一的运算接口
- 易于维护的代码
-
扩展性好:
- 容易增加层数
- 方便修改网络结构
- 灵活的优化策略
这个案例展示了矩阵在深度学习中的核心作用,通过矩阵运算可以高效实现:
- 数据的批量处理
- 网络的前向传播
- 误差的反向传播
- 参数的优化更新
理解和掌握这些矩阵运算对于深入学习神经网络和实现高效的深度学习模型至关重要。
8. 人工智能中,矩阵 综合实战
1. 案例背景
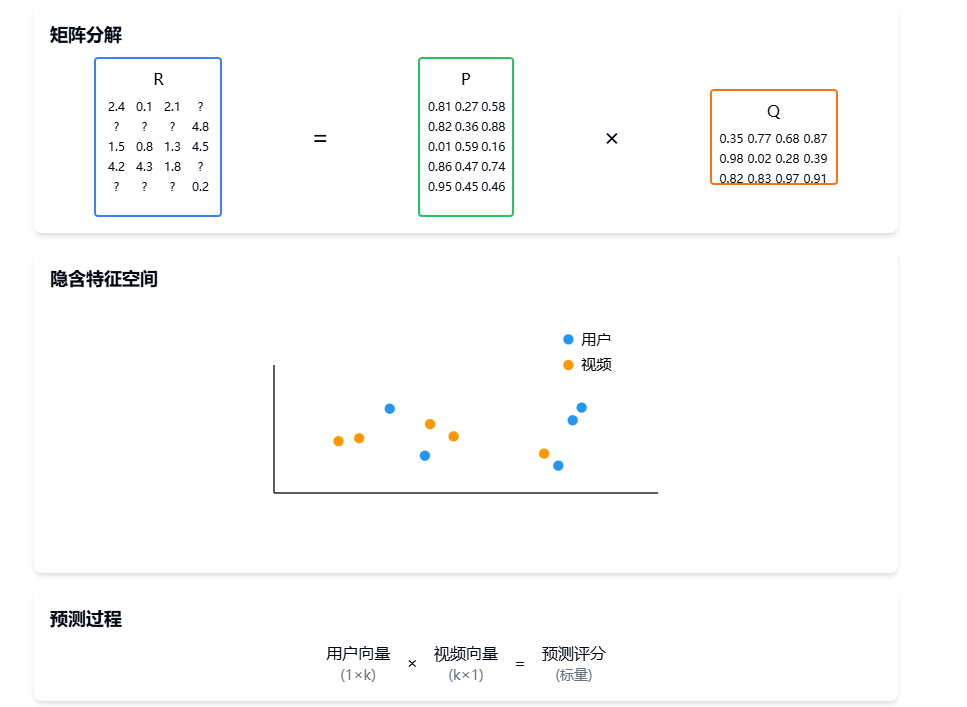
某视频平台需要构建推荐系统,已知:
- 用户-视频评分矩阵 R,大小为 m×n(m个用户,n个视频)
- 许多评分缺失(用户未观看的视频)
- 需要预测用户对未观看视频的可能评分
2. 为什么选用矩阵
-
数据表示优势:
- 自然表示用户-物品交互
- 捕捉潜在特征关系
- 处理高维稀疏数据
-
计算效率:
- 并行化矩阵运算
- 降维处理大规模数据
- 优化的数值计算
-
理论基础:
- SVD(奇异值分解)理论支持
- 低秩矩阵近似
- 潜在语义分析
3. 如何使用矩阵
3.1 矩阵分解模型
将评分矩阵 R 分解为两个低维矩阵的乘积:
# R ≈ P × Q^T
# R: m×n 评分矩阵
# P: m×k 用户特征矩阵
# Q: n×k 视频特征矩阵
# k: 隐含特征维度
def matrix_factorization(R, k, learning_rate=0.01, reg_param=0.02):
m, n = R.shape
P = np.random.normal(0, 0.1, (m, k))
Q = np.random.normal(0, 0.1, (n, k))
# 记录已知评分的位置
known_ratings = ~np.isnan(R)
return P, Q
3.2 模型训练
def train_model(R, P, Q, known_ratings, learning_rate, reg_param, epochs=100):
for epoch in range(epochs):
for i, j in zip(*known_ratings.nonzero()):
# 计算预测误差
prediction = np.dot(P[i], Q[j])
error = R[i, j] - prediction
# 更新参数
temp_p = P[i].copy()
P[i] += learning_rate * (error * Q[j] - reg_param * P[i])
Q[j] += learning_rate * (error * temp_p - reg_param * Q[j])
# 计算损失函数
loss = compute_loss(R, P, Q, known_ratings, reg_param)
if epoch % 10 == 0:
print(f"Epoch {epoch}, Loss: {loss}")
3.3 预测评分
def predict_rating(user_id, item_id, P, Q):
return np.dot(P[user_id], Q[item_id])
def predict_all_ratings(P, Q):
return np.dot(P, Q.T)
4. 整体解决思路
4.1 数据预处理
def preprocess_data(ratings_df):
# 构建用户-物品评分矩阵
user_item_matrix = ratings_df.pivot(
index='user_id',
columns='video_id',
values='rating'
).fillna(np.nan)
# 标准化评分
mean_ratings = user_item_matrix.mean(axis=1)
normalized_matrix = user_item_matrix.sub(mean_ratings, axis=0)
return normalized_matrix, mean_ratings
4.2 实现矩阵分解
class MatrixFactorization:
def __init__(self, n_factors=100, learning_rate=0.01, reg_param=0.02):
self.n_factors = n_factors
self.learning_rate = learning_rate
self.reg_param = reg_param
def fit(self, R, epochs=100):
self.P, self.Q = self._initialize_factors(R.shape)
self._train(R, epochs)
def predict(self, user_id, item_id):
return np.dot(self.P[user_id], self.Q[item_id])
def _initialize_factors(self, shape):
m, n = shape
P = np.random.normal(0, 0.1, (m, self.n_factors))
Q = np.random.normal(0, 0.1, (n, self.n_factors))
return P, Q
4.3 推荐生成
def generate_recommendations(user_id, P, Q, n_recommendations=10):
# 计算用户对所有物品的预测评分
user_predictions = np.dot(P[user_id], Q.T)
# 获取评分最高的N个物品
top_items = np.argsort(user_predictions)[::-1][:n_recommendations]
return [(item_id, user_predictions[item_id])
for item_id in top_items]
4.4 评估系统
def evaluate_recommendations(test_data, P, Q):
predictions = []
actuals = []
for user_id, item_id, rating in test_data:
pred_rating = predict_rating(user_id, item_id, P, Q)
predictions.append(pred_rating)
actuals.append(rating)
rmse = np.sqrt(mean_squared_error(actuals, predictions))
mae = mean_absolute_error(actuals, predictions)
return {'RMSE': rmse, 'MAE': mae}
5. 优化策略
-
参数优化:
# 使用网格搜索找最佳参数 param_grid = { 'n_factors': [50, 100, 150], 'learning_rate': [0.01, 0.001], 'reg_param': [0.02, 0.1] } -
加速训练:
# 使用mini-batch训练 def train_batch(R, P, Q, batch_size=1000): indices = np.random.choice( len(R.nonzero()[0]), batch_size, replace=False ) -
处理冷启动:
# 对新用户使用平均值填充 def handle_cold_start(user_id, item_features): return np.mean(item_features, axis=0)
6. 总结
矩阵分解在推荐系统中的优势:
-
计算效率:
- 降维处理大规模数据
- 并行化计算
- 快速预测
-
特征学习:
- 自动发现潜在特征
- 捕捉用户-物品关系
- 处理稀疏数据
-
可扩展性:
- 易于整合新特征
- 支持增量更新
- 适应不同场景
这个案例展示了矩阵在推荐系统中的应用,通过矩阵分解可以:
- 发现潜在特征
- 预测用户偏好
- 生成个性化推荐
- 处理大规模数据
理解这些概念对于构建高效的推荐系统至关重要。
9. 人工智能中,矩阵 综合实战
我来设计一个关于图像处理中主成分分析(PCA)的综合实战案例。
1. 案例背景
某人脸识别系统需要处理大量人脸图像数据,面临以下挑战:
- 每张图片是64×64像素,展平后为4096维向量
- 数据维度过高,计算开销大
- 存在冗余信息,影响识别效果
- 需要提取主要特征,降低维度

2. 为什么选用矩阵
-
数据表示优势:
- 自然表示图像数据
- 便于处理高维特征
- 支持批量运算
-
特征提取能力:
- 捕捉数据主要方差方向
- 找出数据内在结构
- 去除冗余信息
-
数学基础:
- 协方差矩阵的特征分解
- 正交基变换
- 最小化重构误差
3. 如何使用矩阵
3.1 数据预处理
def preprocess_images(images):
# 图像展平和标准化
m, h, w = images.shape
X = images.reshape(m, h*w)
# 中心化
mean_face = np.mean(X, axis=0)
X_centered = X - mean_face
return X_centered, mean_face
3.2 计算主成分
def compute_pca(X, n_components=50):
# 计算协方差矩阵
m = X.shape[0]
covariance_matrix = (1/m) * (X.T @ X)
# 计算特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eigh(covariance_matrix)
# 选择前k个主成分
idx = np.argsort(eigenvalues)[::-1]
top_eigenvectors = eigenvectors[:, idx[:n_components]]
return top_eigenvectors
3.3 数据投影与重构
def project_and_reconstruct(X, components):
# 投影到低维空间
Z = X @ components
# 重构原始空间
X_reconstructed = Z @ components.T
return Z, X_reconstructed
4. 整体解决思路
4.1 构建PCA类
class FacePCA:
def __init__(self, n_components=50):
self.n_components = n_components
self.mean_face = None
self.components = None
def fit(self, X):
# 中心化
self.mean_face = np.mean(X, axis=0)
X_centered = X - self.mean_face
# 计算主成分
self.components = compute_pca(X_centered, self.n_components)
def transform(self, X):
X_centered = X - self.mean_face
return X_centered @ self.components
def inverse_transform(self, Z):
return Z @ self.components.T + self.mean_face
4.2 实现人脸识别系统
class FaceRecognitionSystem:
def __init__(self, n_components=50):
self.pca = FacePCA(n_components)
self.face_database = None
self.labels = None
def train(self, faces, labels):
# 训练PCA模型
self.pca.fit(faces)
# 转换训练数据
self.face_database = self.pca.transform(faces)
self.labels = labels
def recognize(self, face, threshold=0.8):
# 转换测试脸
face_proj = self.pca.transform(face.reshape(1, -1))
# 计算最近邻
distances = np.linalg.norm(
self.face_database - face_proj,
axis=1
)
min_idx = np.argmin(distances)
if distances[min_idx] < threshold:
return self.labels[min_idx]
return "Unknown"
4.3 评估系统性能
def evaluate_system(system, test_faces, test_labels):
predictions = []
for face in test_faces:
pred = system.recognize(face)
predictions.append(pred)
accuracy = np.mean(np.array(predictions) == test_labels)
return {
'accuracy': accuracy,
'predictions': predictions
}
5. 优化策略
- 增量式PCA:
def incremental_update(self, new_faces):
# 在线更新PCA模型
batch_size = 100
for i in range(0, len(new_faces), batch_size):
batch = new_faces[i:i+batch_size]
self._update_components(batch)
- 并行处理:
from joblib import Parallel, delayed
def parallel_transform(self, X, n_jobs=4):
# 并行处理大批量数据
splits = np.array_split(X, n_jobs)
results = Parallel(n_jobs=n_jobs)(
delayed(self._transform_chunk)(split)
for split in splits
)
return np.vstack(results)
- 内存优化:
def transform_large_dataset(self, X, chunk_size=1000):
# 分块处理大数据集
n_samples = X.shape[0]
transformed = np.zeros((n_samples, self.n_components))
for i in range(0, n_samples, chunk_size):
chunk = X[i:i+chunk_size]
transformed[i:i+chunk_size] = self.transform(chunk)
return transformed
6. 总结
PCA在人脸识别中的优势:
-
维度降低:
- 减少计算复杂度
- 降低存储需求
- 去除噪声信息
-
特征提取:
- 自动学习重要特征
- 保留主要信息
- 增强识别鲁棒性
-
效率提升:
- 加速相似度计算
- 简化模型结构
- 提高系统性能
这个案例展示了矩阵在图像处理和模式识别中的应用,通过PCA可以:
- 有效降低数据维度
- 提取关键特征
- 实现高效识别
- 优化系统性能
理解和掌握这些概念对于构建高效的计算机视觉系统至关重要。
10. 人工智能中,矩阵 综合实战
1. 案例背景
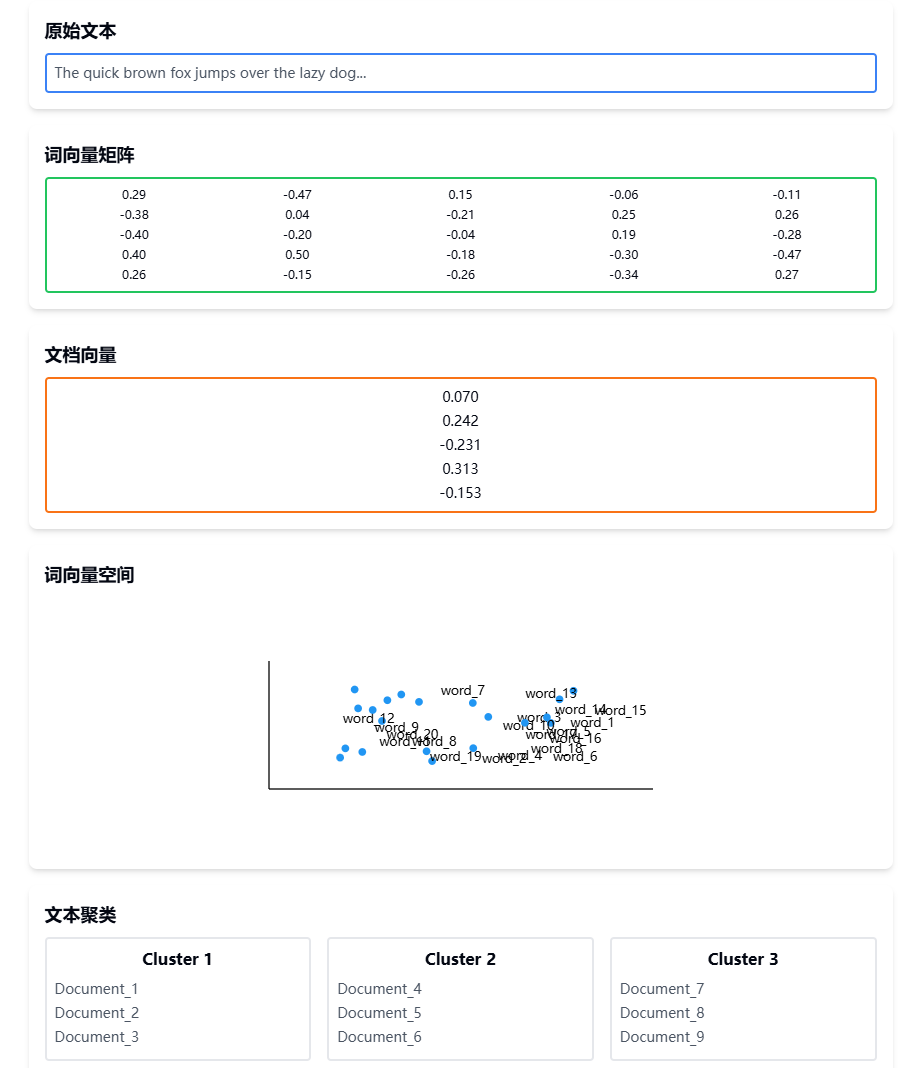
某新闻网站需要构建文本分类系统,要求:
- 处理大量新闻文章进行主题分类
- 分析文章语义相似度
- 实现文章聚类
- 支持关键词提取
关键挑战:
- 文本数据非结构化
- 词汇量大,维度高
- 需要捕捉语义关系
2. 为什么选用矩阵
-
表示优势:
- 自然表示词向量和文档向量
- 捕捉词语间的语义关系
- 支持批量文本处理
-
运算效率:
- 并行化文本处理
- 高效相似度计算
- 快速聚类分析
-
语义分析:
- 词语相似度表示
- 文档主题建模
- 上下文关系捕捉
3. 如何使用矩阵
3.1 构建词向量矩阵
class WordVectorProcessor:
def __init__(self, vector_size=100):
self.vector_size = vector_size
self.word2vec_model = None
self.word_matrix = None
def train_word_vectors(self, documents):
# 训练词向量模型
self.word2vec_model = Word2Vec(
documents,
vector_size=self.vector_size,
window=5,
min_count=5,
workers=4
)
# 构建词向量矩阵
vocabulary = list(self.word2vec_model.wv.key_to_index.keys())
self.word_matrix = np.vstack(
[self.word2vec_model.wv[word] for word in vocabulary]
)
3.2 文档向量生成
def get_document_vector(self, document, method='mean'):
# 分词和预处理
words = self.preprocess_text(document)
# 获取词向量
word_vectors = [
self.word2vec_model.wv[word]
for word in words
if word in self.word2vec_model.wv
]
if not word_vectors:
return np.zeros(self.vector_size)
# 计算文档向量
if method == 'mean':
return np.mean(word_vectors, axis=0)
elif method == 'tfidf':
return self.tfidf_weighted_average(words, word_vectors)
3.3 相似度计算
def compute_similarity_matrix(self, documents):
# 生成文档向量矩阵
doc_vectors = np.vstack([
self.get_document_vector(doc)
for doc in documents
])
# 计算余弦相似度矩阵
similarity_matrix = cosine_similarity(doc_vectors)
return similarity_matrix
4. 整体解决思路
4.1 文本预处理
def preprocess_text(self, text):
# 文本清理
cleaned_text = clean_text(text)
# 分词
tokens = word_tokenize(cleaned_text)
# 去除停用词
stop_words = set(stopwords.words('english'))
tokens = [t for t in tokens if t not in stop_words]
# 词形还原
lemmatizer = WordNetLemmatizer()
tokens = [lemmatizer.lemmatize(t) for t in tokens]
return tokens
4.2 文档分类系统
class DocumentClassifier:
def __init__(self, vector_processor, n_classes=5):
self.vector_processor = vector_processor
self.classifier = LogisticRegression(
multi_class='multinomial'
)
def train(self, documents, labels):
# 生成文档向量
doc_vectors = [
self.vector_processor.get_document_vector(doc)
for doc in documents
]
# 训练分类器
self.classifier.fit(doc_vectors, labels)
def predict(self, document):
# 生成文档向量
doc_vector = self.vector_processor.get_document_vector(
document
)
# 预测类别
return self.classifier.predict([doc_vector])[0]
4.3 文本聚类
def cluster_documents(self, documents, n_clusters=5):
# 生成文档向量矩阵
doc_vectors = np.vstack([
self.get_document_vector(doc)
for doc in documents
])
# K-means聚类
kmeans = KMeans(n_clusters=n_clusters)
clusters = kmeans.fit_predict(doc_vectors)
# 组织聚类结果
clustered_docs = defaultdict(list)
for doc, cluster in zip(documents, clusters):
clustered_docs[cluster].append(doc)
return clustered_docs
4.4 关键词提取
def extract_keywords(self, document, top_k=10):
# 分词和向量化
words = self.preprocess_text(document)
doc_vector = self.get_document_vector(document)
# 计算每个词与文档向量的相似度
word_scores = []
for word in set(words):
if word in self.word2vec_model.wv:
word_vector = self.word2vec_model.wv[word]
similarity = cosine_similarity(
[word_vector],
[doc_vector]
)[0][0]
word_scores.append((word, similarity))
# 返回top-k关键词
return sorted(
word_scores,
key=lambda x: x[1],
reverse=True
)[:top_k]
5. 优化策略
- 向量计算优化:
# 使用批处理加速计算
def batch_process_documents(self, documents, batch_size=32):
vectors = []
for i in range(0, len(documents), batch_size):
batch = documents[i:i+batch_size]
batch_vectors = self._process_batch(batch)
vectors.extend(batch_vectors)
return vectors
- 内存优化:
# 使用增量学习处理大规模数据
def incremental_train(self, document_stream):
for batch in document_stream:
self.word2vec_model.train(
batch,
total_examples=len(batch),
epochs=1
)
- 计算优化:
# 使用近似最近邻搜索
from annoy import AnnoyIndex
def build_search_index(self, vectors, n_trees=10):
dim = vectors.shape[1]
index = AnnoyIndex(dim, 'angular')
for i, v in enumerate(vectors):
index.add_item(i, v)
index.build(n_trees)
return index
6. 总结
矩阵在文本分析中的优势:
-
数据表示:
- 词向量编码
- 文档向量生成
- 语义关系表示
-
计算效率:
- 批量处理
- 并行计算
- 快速检索
-
应用灵活:
- 文本分类
- 文档聚类
- 关键词提取
这个案例展示了矩阵在NLP中的应用,通过矩阵运算可以:
- 有效表示文本语义
- 计算文本相似度
- 实现文本分类聚类
- 提取文本关键信息
理解这些概念对于构建高效的文本处理系统至关重要。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 24
24 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)