机器学习实战:特征工程之 TF-IDF公式原理解析
·
TF-IDF可用于评估词语在文档中的重要程度,是一种统计方法。
学习 TF-IDF 就像是给特征提取器装上了“智能滤镜”。
TF-IDF 的全称是 Term Frequency-Inverse Document Frequency(词频-逆文档频率)。它的核心思想是:如果一个词在某篇文章中出现次数很多,但在其他文章
中很少出现,那么这个词就非常具有代表性。
1. 拆解两个核心指标
TF-IDF 是由两个部分相乘得来的:
TF (Term Frequency) —— 词频
- 含义:一个词在当前文章中出现的频率。
- 逻辑:一个词在文章里出现的次数越多,它可能越重要。
- 公式:

IDF (Inverse Document Frequency) —— 逆文档频率
- 含义:衡量一个词的“稀有程度”。
- 逻辑:如果一个词在所有文章里都出现(比如“的”、“是”、“我们”),那它就不具备区分度。IDF 会给这种大众词打低分,给“稀有词”打高分。
- 公式:

- (加 1 是为了防止分母为 0)
- 偶尔也会在分子上+1,会在常数项上+1

个人对该公式的数学注解,示例:
如果每个文章都有 词汇“的”,那么log(0.99999)≈ log 1= 0
即便他的TF(term frequency术语频率)=有限大的数N
然而实际 TF-IDF=0
2. 最终计算公式
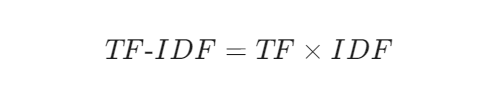
3. 为什么它比 CountVectorizer (词汇统计/词汇矢量器)更好?
举个例子,假设你在分析一批关于“人工智能”的新闻:
- “的”:在每篇文章都出现。虽然它的 TF 很高,但 IDF 极低(接近 0),所以最终 TF-IDF 很低。
- “神经网络”:可能只在其中两篇技术文章中反复出现。它的 TF 高,IDF 也高,最终 TF-IDF 很高。
结论:TF-IDF 能够自动帮你过滤停用词(Stop Words)并提取关键词。
4. 在 sklearn 中如何实现?
只需要把之前的 CountVectorizer 换成 TfidfVectorizer。
5. 必须掌握的细节
- 结果是浮点数:与 CountVectorizer 输出整数次数不同,TF-IDF 输出的是 0 到 1 之间的浮点数,代表了重要性权重。
- 数值归一化:sklearn 的 TfidfVectorizer 默认会进行 L2 归一化,这意味着每行向量的平方和为 1。这对于后续使用余弦相似度计算文档距离非常方便。
- 中文处理:依然需要先用 jieba 分词,否则 sklearn 无法正确识别词语。
掌握了 TF-IDF 后,就可以开始做简单的“文本分类”或“关键词提取”了。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)