【深度学习|学习笔记】循环神经网络(Recurrent Neural Network, RNN)详解,附代码。
·
【深度学习|学习笔记】循环神经网络(Recurrent Neural Network, RNN)详解,附代码。
【深度学习|学习笔记】循环神经网络(Recurrent Neural Network, RNN)详解,附代码。
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/147776348
前言
- 在机器学习持续演进与深度模型不断革新的背景下,循环神经网络(Recurrent Neural Network, RNN)凭借其“序列记忆”机制,从1980年代便开始崭露头角,并通过长短期记忆网络(LSTM)与门控循环单元(GRU)等关键改进,成为处理时序数据与自然语言处理等领域的基石。
本文首先回顾RNN的起源与基本原理,随后梳理其发展脉络,接着探讨典型应用与优缺点,最后给出Python实现示例,帮助读者系统掌握这一经典模型。
起源
- RNN的思想可追溯至1982年John Hopfield提出的Hopfield网络,该结构引入了神经元间的循环连接,为记忆存储与能量最小化奠定了基础。
- 1986年,David Rumelhart等人在误差反向传播研究中首次引入带有循环连接的神经网络概念,开启了RNN的正式探索。
- 随后,Jordan网络(1986)与Elman网络(1990)等早期模型将RNN用于认知心理学实验,验证了“隐状态”对序列信息的捕捉能力。
原理
- RNN的核心在于隐状态(hidden state)的递归更新。对于时刻 t t t 的输入向量 x t \mathbf{x}_t xt,网络维护一个状态向量 h t \mathbf{h}_t ht,其更新公式为:
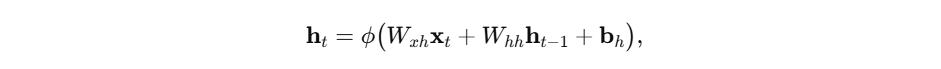
- 其中 ϕ \phi ϕ 为激活函数,如 tanh \tanh tanh 或 ReLU,参数矩阵 W x h , W h h W_{xh},W_{hh} Wxh,Whh 负责输入与隐状态的线性变换, b h \mathbf{b}_h bh 为偏置项。网络输出则可通过
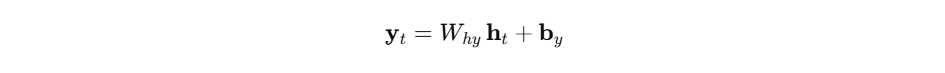
- 映射到目标空间。由于参数在时间步间共享,RNN对任意长度序列具有天然适应性,但同时也导致梯度消失与爆炸问题,影响长期依赖的学习。
发展
长短期记忆网络(LSTM)
- 为缓解基础RNN的梯度问题,Hochreiter & Schmidhuber于1997年提出了LSTM,通过引入输入门、遗忘门和输出门,实现对信息的选择性记忆与遗忘,有效捕捉长程依赖。
门控循环单元(GRU)
- 2014年,Cho et al.提出GRU,将LSTM的三个门简化为“更新门”和“重置门”,在保留时序记忆能力的同时,减少了模型参数与计算开销。
其他变体
- 门控反馈RNN(GF-RNN):2015年,Chung et al.提出通过层间门控反馈信号,实现多层RNN间的自适应时序互联,进一步提升深度堆叠效果。
- 双向RNN(Bidirectional RNN)与注意力机制的结合,也在机器翻译与语音识别中大放异彩。
应用
- 自然语言处理(NLP):RNN及其变体在语言模型、机器翻译与文本生成中处于核心地位,如使用LSTM进行序列到序列(seq2seq)学习。
- 时序预测:在金融市场预测、气象预报等领域,RNN可基于历史数据捕捉隐含时序模式,提供短期与中期预测。
- 语音与音频处理:RNN善于处理音频信号的连续性,被广泛用于语音识别、声纹鉴别与音乐生成等任务。
- 控制与机器人:借助在线学习与时序建模能力,RNN在轨迹跟踪与强化学习控制策略中实现了有效应用。
优缺点
优点
- 参数共享:时间维度参数复用,减少模型规模,增强对变长序列的适应性。
- 序列建模能力:天然捕捉前后文依赖,适合文本、语音与时序数据。
- 多样化变体:LSTM、GRU等多种结构可针对不同任务与资源约束灵活选用。
缺点
- 梯度消失/爆炸:基础RNN在长序列上难以保持稳定训练,需要门控或正则化改进。
- 计算效率低:序列计算不可并行化,训练与推理速度相对CNN等结构较慢。
- 长期依赖限制:即便使用LSTM/GRU,也存在跨越极长距离信息衰减问题,需要结合注意力或记忆网络进一步增强。
Python 实现示例(基于 PyTorch)
import torch
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# x: [batch, seq_len, input_size]
out, hn = self.rnn(x) # out: [batch, seq_len, hidden_size]
# 只取最后时刻的输出
return self.fc(out[:, -1, :]) # [batch, output_size]
# 示例用法
if __name__ == "__main__":
batch, seq_len, input_size = 32, 10, 8
hidden_size, output_size = 16, 4
model = SimpleRNN(input_size, hidden_size, output_size)
dummy_input = torch.randn(batch, seq_len, input_size)
output = model(dummy_input)
print("Output shape:", output.shape) # 应为 [32, 4]
- 该示例中,
nn.RNN搭建最基础的循环层,batch_first=True方便以[batch, seq, feature]格式输入;最后通过全连接层映射为目标维度。您可将nn.RNN替换为nn.LSTM或nn.GRU,并根据任务需添加多层网络、dropout与正则化,以获得更强大的建模能力。
通过上述回顾,您可以全面了解RNN的历史渊源、核心机制、关键演进、典型应用与优劣所在,并能够在Python中快速上手实现,为处理各类时序与序列数据提供可靠工具。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 26
26 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)