[Python嗯~机器学习]---简述支持向量机(SVM)和核函数
简述支持向量机
这一个博客我们还是讨论监督学习和分类问题-----支持向量机 / SVM
还是用问题引出我们的内容。
我们在逻辑回归中通过对概率值的惩罚来判断决策边界,那么我我们在SVM中怎么分类?在线性不可分的高维度情况
下,我们对样本进行分类?
这样就引出了我们支持向量机中的最重要的两个内容
1、顾名思义的支持向量(离决策边界最近的点)~~~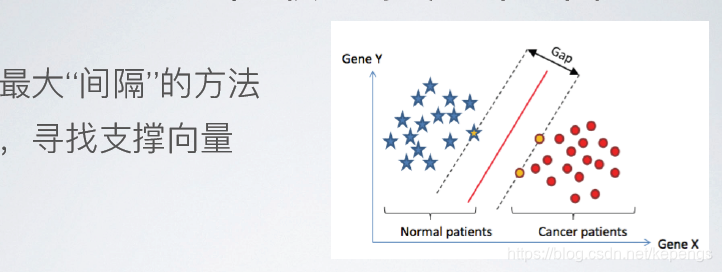
2、引入核函数,使线性不可分的内容线性可分~~~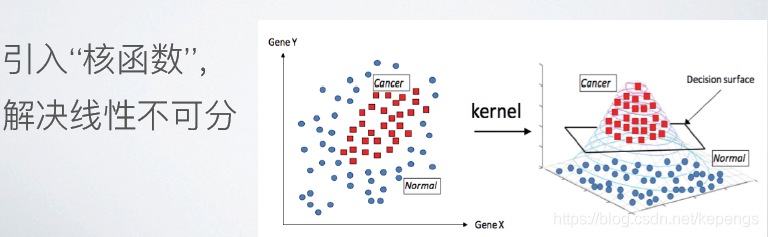
-------------------------------------------------------------------分隔线-------------------------------------------------------------------------------
开始我们今天的讨论~~~
我们首先看看支持向量机的优化目标。为了描述支持向量机,我们将从逻辑回归开始,然后对它进行小小的修改,
便可以得到支持向量机。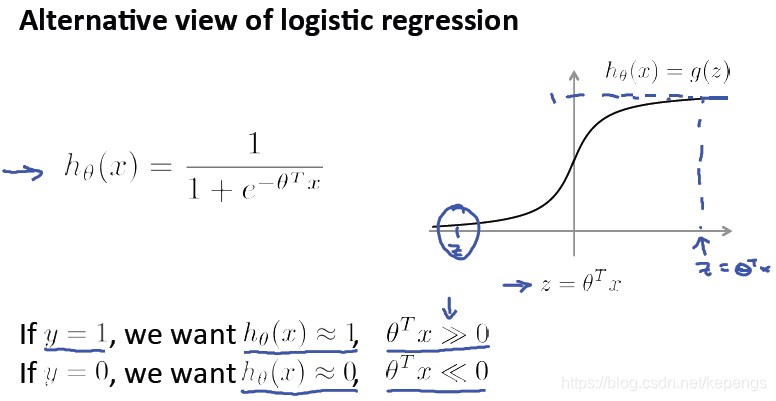
在逻辑回归中,假设函数如上图,将样本分成两类。
正确的分类如 y=1为正类,那么我们就希望 h(x)≈1,越接近于1,表示分类越准确 。负类同理。
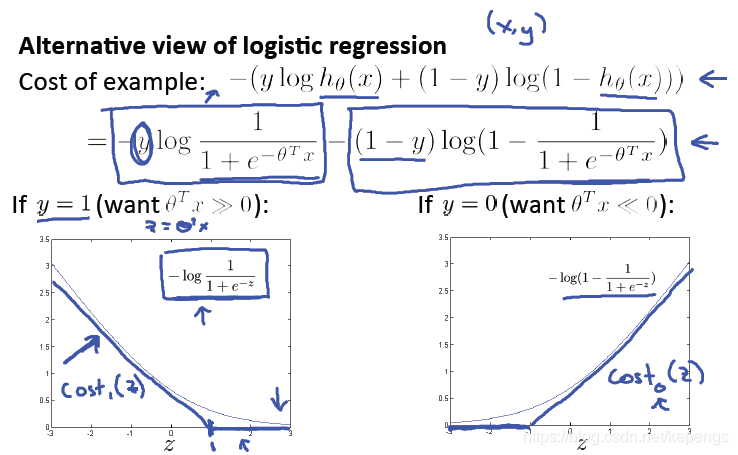
使用z作为自变量,绘制损失函数图。在这里,当 z 增大时,也就是θ转置乘以x增大时,那么它对应的代价就会很小,
就意味着离着决策边界越远,代价就越小,说明 θ 转置乘以 x 和到决策边界的距离成正比,跟代价成反比。
构建支持向量机
在sigmoid函数中,当 x 大于某一个值开始,逼近 1 或 0 的速度就会明显减慢,如上图中的 +1 和 -1 。例如,我们选择
z = +1 的点,在这个点右边,我们的损失将认为是 0。然后我们对于该点左侧,我们定义它的损失是一接近逻辑回归的
损失的直线。这样损失函数就是一个两段的直线组合,暂时不考虑斜率。这样会极容易计算。y=0 的情况如上图右。
代价函数我们暂时就叫做cost 1(z) 和 cost 0(z),具体表达式先不关心。
参考我们的logistic函数的代价函数: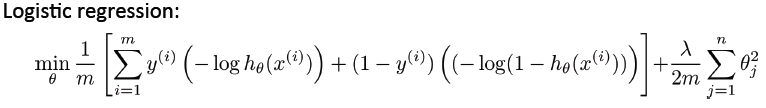
我们可以把SVM的代价函数表示成: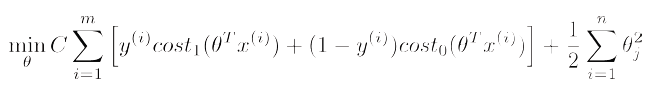
对于支持向量机,不同的只是 cost1(z) 和把正则化项的 λ 替换成现在的 C,目的是一样的不影响。
逻辑回归输出的是一个概率值,而支持向量机做的只是进行预测。
目标函数: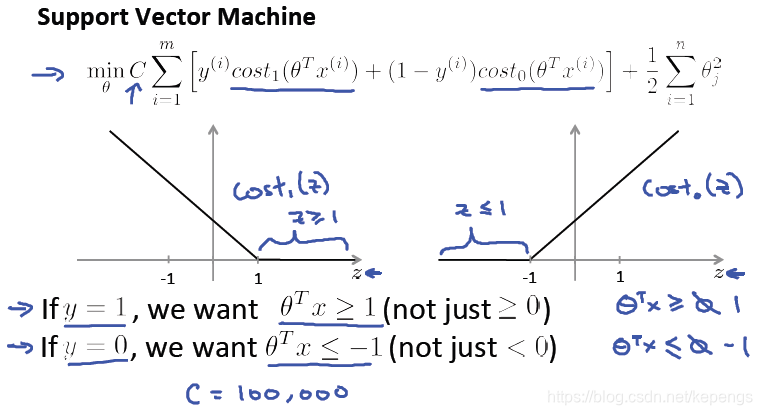
还是我们的 cost() 代价函数,阈值还是 +1 和 -1 。
当样本标签 y=1 的时候,如果θT*x大于等于1,就是说样本点离决策边界很远。我们就认为此时的分类是完全准确的,
没有任何损失。但是,当θT*x虽然大于0,但如果它的值小于1,就说明这个样本点离目前由 θ 定义的决策边界的距离
并不远,虽然仍然能够正确分类,但会认为仍然有一点损失,就是分类不确定。
所以,在支持向量机中对分类有较高的要求,我们不仅仅需要能正确地分类出样本,更希望分类的时候置信度要尽量的
高。就是说,在把一个样本分类成 y=1的时候,我们希望不要仅仅是 θT*x>=0,我们希望的是θT*x>=1,也就是说在决
策边界上最好不要有样本点,最好所有的样本都能够离决策边界较远,保证我们分类的把握更大。
讨论下常数 C:
可以用正则化项 1 / λ 来理解。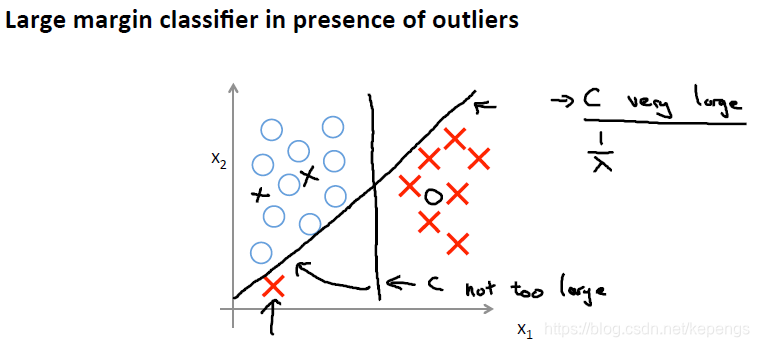
例如,C 很大的时候,比如100,000。那么对应这个数据集,也许决策边界就会是黑色斜线。
因为C很大,就意味着我们更加关心模型对数据的拟合程度,而不太关心模型本身的复杂度。
数学相关知识
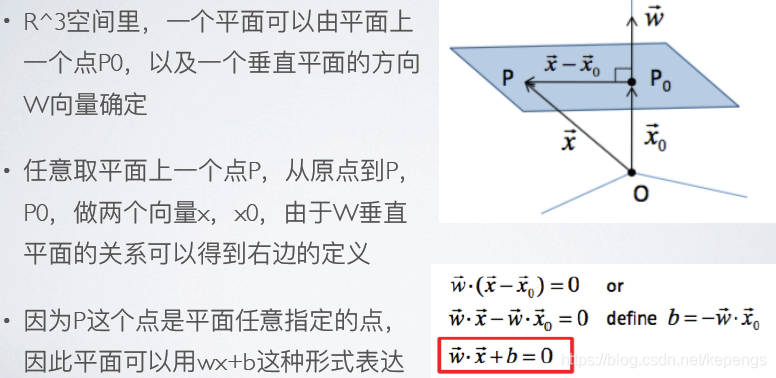
一个方向向量 w 和一个点 P0 能定义一个平面。
两个平行平面之间的距离也能用 w 和 b 表示出来。
上面分析代价函数的时候,我们定义的样本类别为 +1 和 -1 时才确保分类,那么这时候在 +1 和 -1 确定的直线上的
点就叫做支持向量。
计算间隔:
定义分隔直线为![]() ,任意点
,任意点  到该直线的距离为
到该直线的距离为![]() 。对于N个训练点的信息记为
。对于N个训练点的信息记为 :
:![\arg\max_{w,b}\left\{ \frac{1}{||w||}\min_{n}\left[ y_i(w^Tx_i+b) \right] \right\}](https://i-blog.csdnimg.cn/blog_migrate/efa035868fb80f486bb84562d2732339.png) ,也就是
,也就是

subject to 
分类 Yi = +1 或 Yi = -1 。
最大间隔: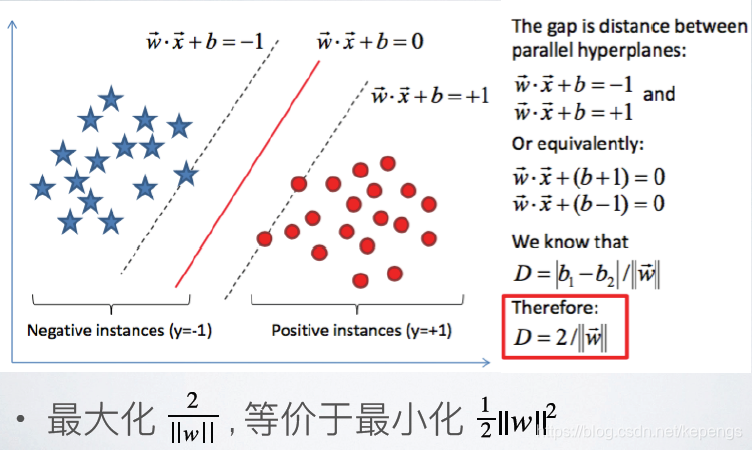
那么,这又是一个有约束条件的极值问题,我们首先想到的是拉格朗日对偶函数。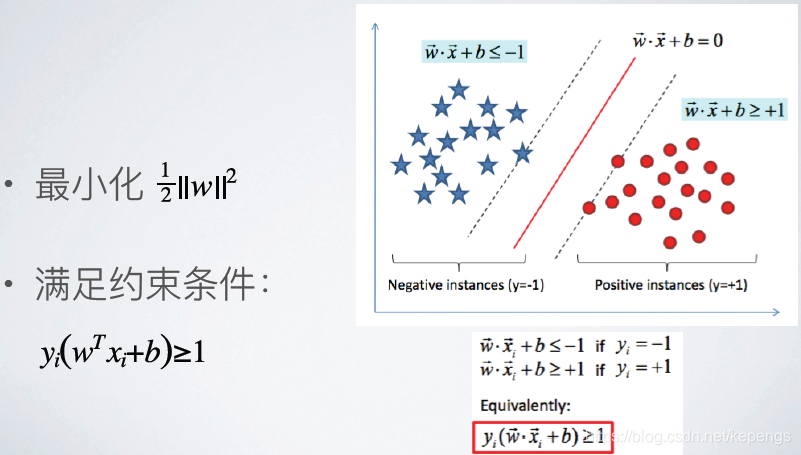
构造拉格朗日对偶函数:
可以这样想:
(1) 我们的两个任务:①对参数最小化L(解SVM要求)。②对乘子又要最大化(拉格朗日乘子法要求)。
(2) 如果上面的约束条件成立,整个求和都是非负的,L是可以求最小值的。
(3) 约束条件不成立,又要对乘子最大化,非负的L直接原地爆炸。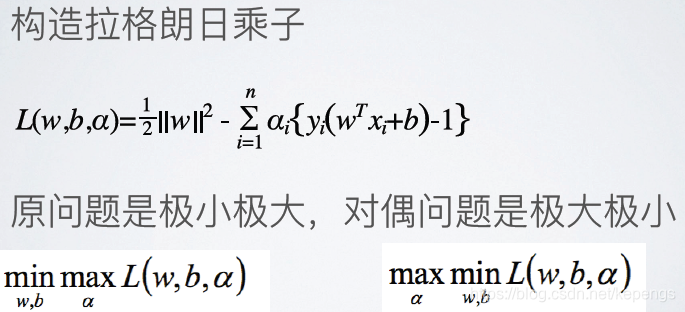

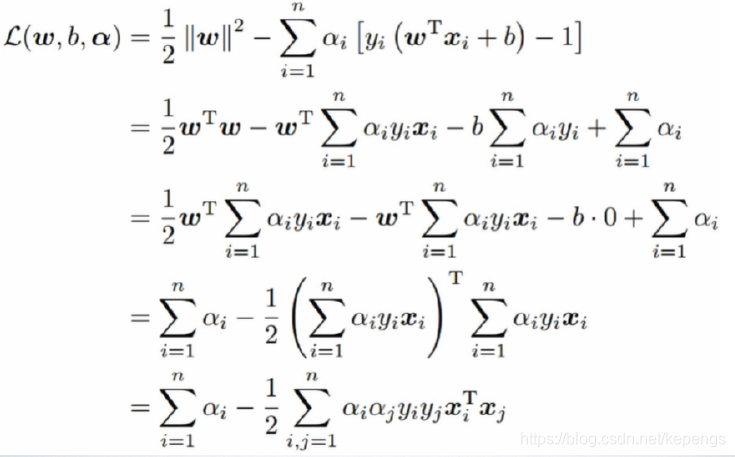
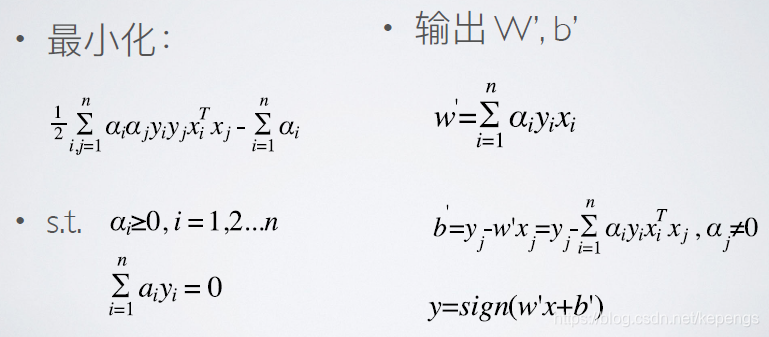
这时候,w 已经被表达出来了也就是说这个直线现在变成了: 一个关于 α 的函数。
一个关于 α 的函数。
核函数
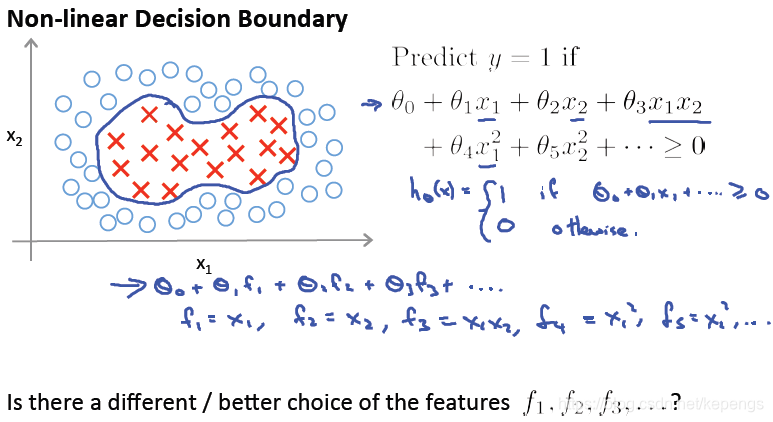
LIBSVM中提供的核函数
线性核函数
多项式核函数
RBF核函数(高斯核函数)
sigmoid核函数
SVM关键是选取核函数的类型,主要有线性内核,多项式内核,径向基内核(RBF),sigmoid核。
这些函数中应用最广的应该就是RBF核了,无论是小样本还是大样本,高维还是低维等情况,RBF核函数均适用,它相比
其他的函数有一下优点:
1)RBF核函数可以将一个样本映射到一个更高维的空间,而且线性核函数是RBF的一个特例,也就是说如果考虑使用RBF,
那么就没有必要考虑线性核函数了。
2)与多项式核函数相比,RBF需要确定的参数要少,核函数参数的多少直接影响函数的复杂程度。另外,当多项式的阶数
比较高时,核矩阵的元素值将趋于无穷大或无穷小,而RBF则在上,会减少数值的计算困难。
3)对于某些参数,RBF和sigmoid具有相似的性能。
非线性分类器
我们还是从一个问题来引出来,如果我们有很多个特征,是不是会构建很多高阶项的特征,如果特征太多那么我们的
计算量是不是太大了?这时候有没有更好的高级特征来代替这些高阶多项式吗?
这时候我们就需要”核函数”(Kernels)。

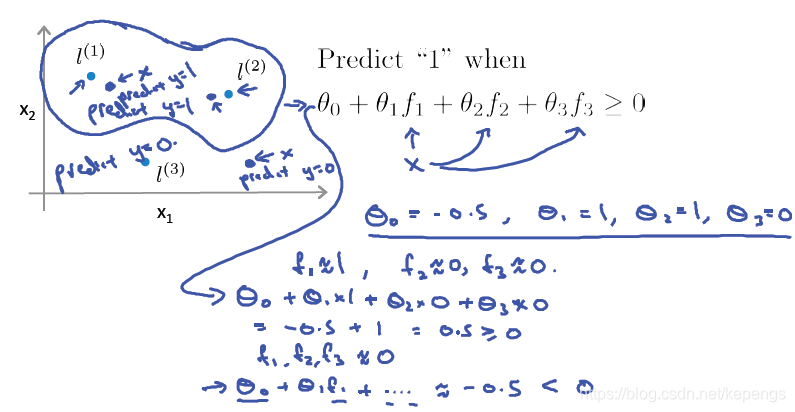
现在,我们有一个关于构造新特征f1, f2,f3的想法。我们暂时只定义三个新特征,真实问题有很多特征。
所以,我们将要做的就是,对于这里的原始特征x1, x2,我们将人工选择一些点 l1, l2, l3,并将它们称作”地标”(landmark)。
构建新特征:
给定一个样本 x,将第一个新特征 f1 定义为和 l1 的一种相似程度,用相似度函数,如上图构建新特征。
这些相似函数,similarity函数,实际上就是所谓的核函数。上图中,叫做高斯核函数。
那么我们就来看看这些核函数到底在干些什么,为什么这些相似函数,或者说这里的高斯核函数是行得通的。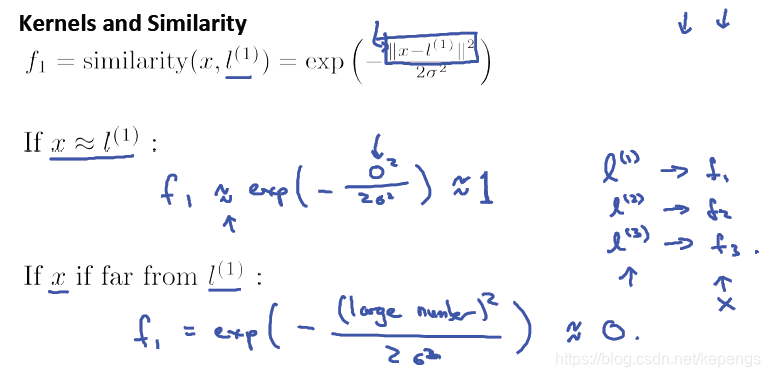
我们先来看看第一个地标(landmark), l1,它是我们前面选择的三个地标之一。因为 x 和 l1 是同一个点。所以
相似度就是 1 。反之相似度接近 0。
所以,f1表示样本和第一个地标点 l1 之间的相似度,它定义了一个新的特征。特征数就等于地标点数。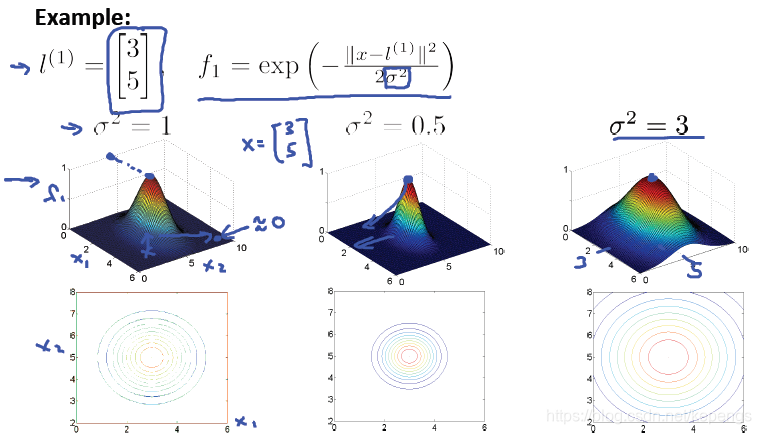
我们使用图形来看看这个高斯核的具体是什么样的。
在高斯核种有一个σ参数,,σ^2实际上是控制着我们对相似度的衡量的松紧。σ越大,相似度的衡量越宽松,即
使离得远也有一些相似度,而σ越小,相似度的衡量越紧张,稍微离得远一点,相似度就会非常小。
假设函数
核函数的基本概念,以及我们在支持向量机中大概如何使SVM。也就是,我们通过计算样本跟地标点之间的相似度
来定义新的特征,从而训练复杂的非线性决策边界。
接下来,我们就来继续讨论下这些问题,然后再把所有的东西组合在一起,看看支持向量机如何通过核函数的定义
来有效的学习非常复杂的非线性函数。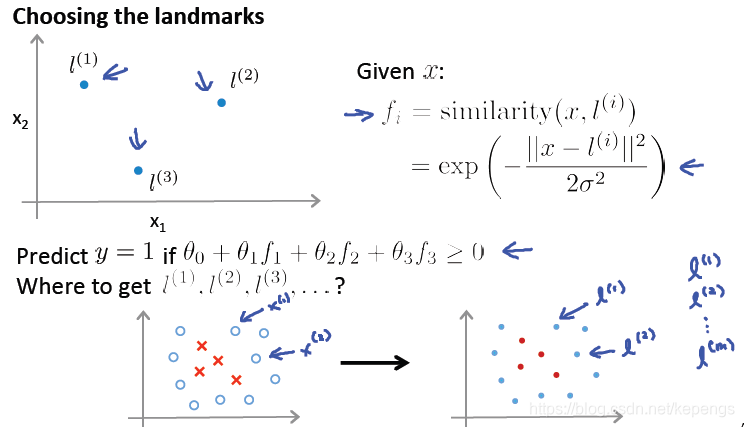
在实际中,我们是这样选择地标点的:给定一个样本集,有正样本,也有负样本,那么我们的想法是,我们将所有训
练样本都作为地标点[x(1)->l(1)]。在右图中,我们使用红点和蓝点来表示不同类型样本点对应的地标点。那么我们可
以得到m个地标点,[右侧l(1)~l(m)]
我们的每一个地标点实际上都对应着一个真实的训练样本。所以,这样我们的特征将会描述样本之间的远近距离关系。
所以,给定这些核函数或者相似度函数以后,我们就可以重新构建我们的样本点特征。
所以,对于使用核函数的支持向量机而言,当给定一个样本x,我们需要计算它通过核函数计算得到的特征向量f,它
是一个m+1的向量,这是因为我们有m个样本,对应着就有m个地标点,那么相应的,就会对应着m个特征,而f0则是
偏置。
那么,如果θ转置乘以f>=0,我们就会预测它是一个正类,也就是y=1。所以,这就是做预测时的流程,如果我们已经
得到了一组学习好了的参数θ,我们就可以按照这个步骤来对新的样本做分类预测。
不过,现在的问题就在于,我们怎么得到这些模型参数θ呢?其实,我们求解支持向量机的过程,本质上就是最小化这个
代价函数。那么求解完这个最小化代价函数以后,我们就可以得到相应的模型参数θ。
使用支持向量机

关注下各个参数就行,很简单的。
不过如果我们决定要选择高斯核的话,或者其他核,我们一定要注意的一点是,一定要在应用核函数之前就进行特
征放缩。

多分类的支持向量机
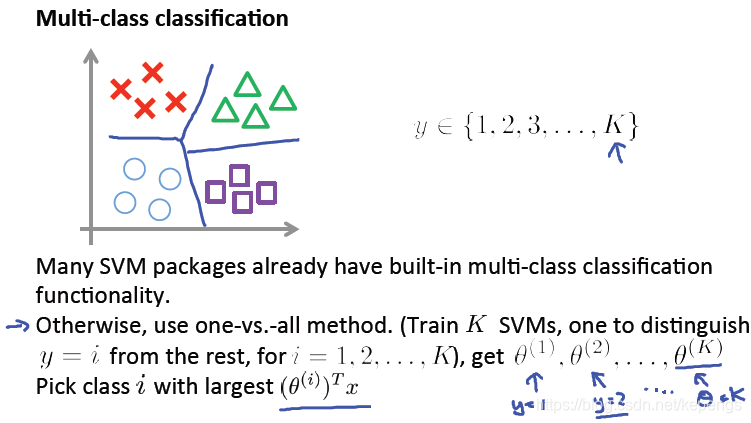
很多支持向量机的软件包都内建了多分类功能,我们只需要直接调用对应的方法或者函数就可以了。
否则的话,我们可以类似在逻辑回归中讲的一样,可以训练k个支持向量机,采用一对多的办法,每个支持向量机都用
于判断样本是否属于该分类器对应的类。
最后,我们要要说一下,在需要使用分类器的时候,我们如何选择逻辑回归和支持向量机。
[线性核或逻辑回归,因为特征多,样本少,线性避免过拟合,而且也因为没有足够的数据来拟合复杂的分类决策边界;
样本太多,高斯核支持向量机会很慢。
其实,这里我想大家可能注意到了,逻辑回归和线性核的支持向量机其实几乎差不多,二者做的事情都很相似,而且得
到的结果也差不多,但是根据实际的情况,其中一个可能会比另一个更加有效,但一般而言,二者差别不会很大。
那么最后,我们说我们面对的是一个分类问题,那么我们什么时候使用神经网络呢?实际上,对于几乎所有的问题,一
个设计得当的神经网络也很有可能会非常有效,不过它的一个劣势是它可能训练起来会比较慢。
好了,以上就是所有关于支持向量机的理论内容了。
-----------------------------------------------------------------分隔线----------------------------------------------------------------------------------
支持向量机(SVM)是什么意思? - 靠靠靠谱的回答 - 知乎 https://www.zhihu.com/question/21094489/answer/117246987

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 4
4 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)