大云海山数据库(He3DB) 内核分析 — Btree索引篇
前言:提到索引大家都不陌生,日常生活中也常用到索引,比如查字典,课本的目录等等,都是利用了索引的思想来快速找到想要的内容,数据库也是一样,引入索引来提升数据库读的性能,但是没有免费的午餐索引的引入在提升读性能的同时会牺牲掉一部分写的性能,且需要占用一定的磁盘存储空间,所以合理的使用索引非常重要。
索引是每个数据库最基本也是常用的功能,最近在学大云海山数据库(He3DB)的过程中,花了点时间研究了一下数据库中索引的实现He3DB 所支持的索引种类有B-Tree索引,hash索引,GiST(Generalized Search Tree)索引,GIN(Generalized Inverted Index)索引,Brin索引,SP-Gist索引。本文并不打算详细的介绍全部种类的索引,会挑一个最常用的B-Tree索引来介绍它的实现套路。
既然叫B-Tree索引自然和B-Tree结构是分不开的,可以联想到磁盘上索引文件的数据组织形式是以B-Tree的结构组织,但实际He3DB实现的工程中是以B-Tree的一种变形结构B+Tree的数据结构来存储数据的。
说索引实现之前先来回顾一下B+Tree的结构特点:
- B+树的所有的键值都在叶子节点,并且键值之间使用双向链表的方式连接
- B+树叶子节点保存了指向实际数据的指针
- 非叶子节点保存了子树节点的最小值指针,并不指向数据实际存储位置
- B+树每次查找过程都会经历从根到叶子节点的路径
基本知识回顾完之后,下面会从B-Tree索引的创建,查找,插入,删除几个部分来揭秘He3DB的B-Tree索引实现,这部分内容会涉及到比较多的代码分析。
Btree索引的创建
先说第一个部分索引的创建,关系型的数据库创建索引的路子都是大同小异He3DB也不例外,先构建索引相关信息,处理元数据,再创建索引文件,最后导数据到索引文件。这部分内容直接看流程图就完事了,一目了然。
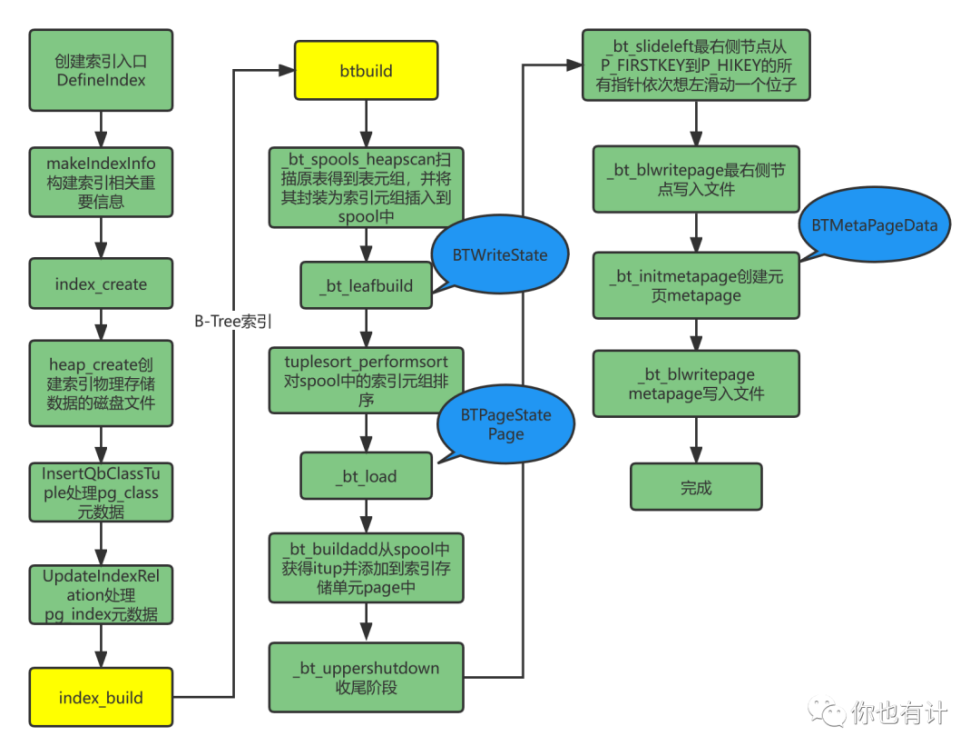
流程图虽直观但展示不出实现的细节,下面分别介绍一下上述流程图中涉及到的几个具体的结构体:
Page:页是在流程图的_bt_load函数中被首次构建,page承担着存储实际索引元组的任务,是索引文件的最小存储单元,也就是说索引文件中实际存储的是一个个的page,B+Tree的每个节点也就是一个page结构,这些page被人为组织成了B+Tree的结构,He3DB默认的每个页大小(pagesize)是8k,每个page中可以存储很多个索引元组(itup),这些itup被逐个顺序的安排在page中,当一个page存满了8k的数据之后会再创建一个新的page,之后所有的itup都往新的page中插入,并将已经插满的page落盘。
看一下He3DB的page结构示意图:
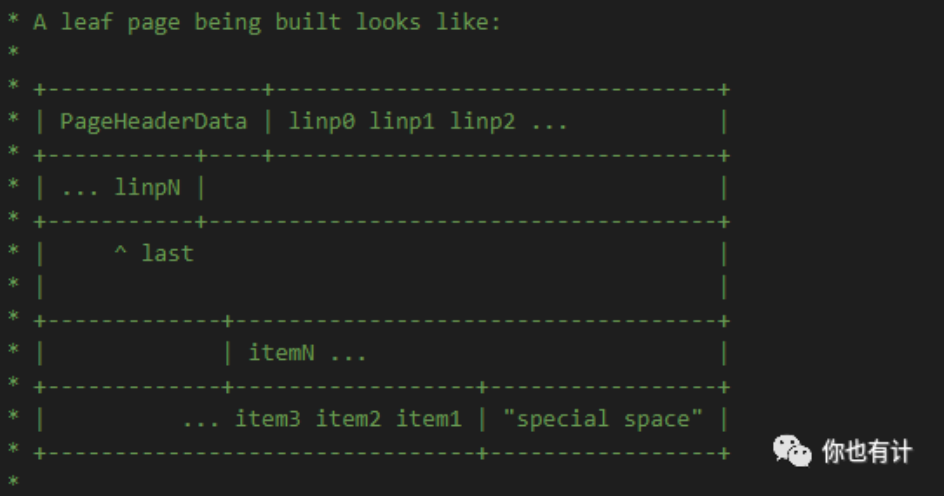
分析一下这张图展示的page结构,这张page结构图包含了PageHeaderData,linpN,itemN,special space 4个部分。
- PageHeaderData里面存储的就是当前page的布局信息,包括上述4个部分的起止位置,page的大小和版本还有标志位信息。
- linpN这部分存储的是索引元组在page内的实际位置的指针,每一个linp指针指向一个对应item位置,linp内存结构对应代码里的ItemId的结构。
- itemN这部分就是实际的索引元组也就是itup,对应代码中的IndexTuple结构。
- SpecialSpace:在每个page的最后位置,这块空间存储了当前page的左右兄弟节点指针,页面类型(叶子,根,元页等),页面在Btree中的层号等。
BTPageState:
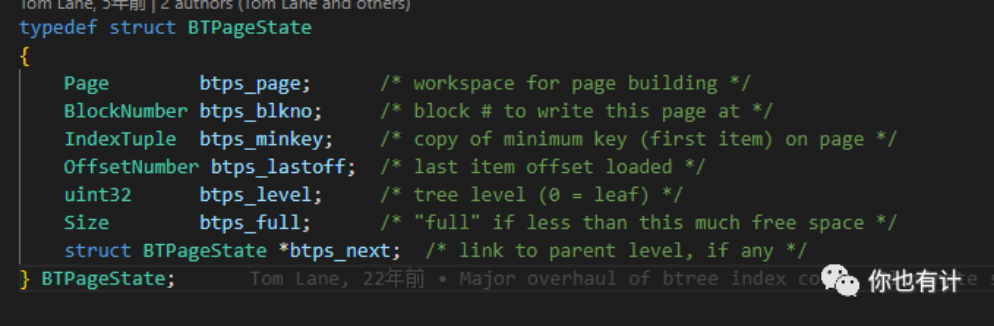
这个结构首次构建也是在_bt_load函数,实际上_bt_load是先构建的BTPageState,后构建的Page,再将BTPageState中的btps_page指向新创建page,其他字段的信息也一并获取,由此可见BTPageState描述的就是当前正在操作的page,至于btps_next指针是用来指向父节点的BTPageState结构,这个指针在所有索引元组插入完成后,调整B+Tree每一层的最右节点时用到,后面再说具体用法。由以上分析可以看出当一个page填满之后只要再创建一个page结构,同时将BTPageState里面原来的page信息更新成为新创建的,就实现兄弟节点复用BTPageState结构,所以B+Tree的每一层只会有一个BTPageState结构。
BTWriteState
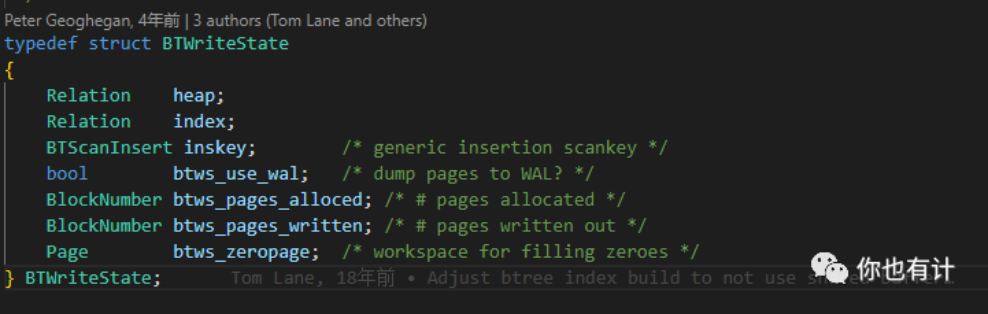
用于记录索引写入过程中的总体状态,整个索引创建的过程只产生一个BTWriteState结构。
BTMetaPageData
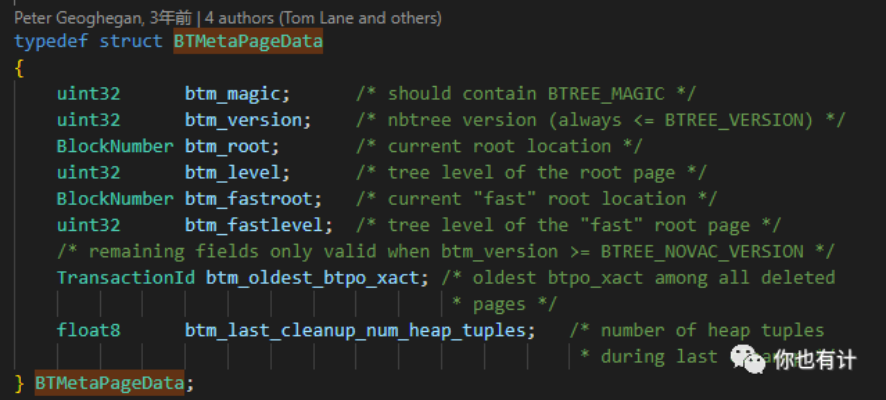
元页,B+Tree树上的第一个节点,但是确是在整个树构建完成后再构建的元页节点,元页中保存了B-Tree的版本,根节点,根节点层号,有效根节点,有效根节点的层号等。
重要结构介绍完了,现在可以用一段文字描述一下整个B-Tree的构建过程了:首先扫描原表将原表元组转为索引元组,并对索引元组进行排序,然后调用_bt_load函数逐个的从spool中获取排好序的索引元组,并将其添加到当前页面,当填满一个页面之后,重新创建一个新的page作为它的右兄弟节点,创建新page后立马做两件事情,第一把填满的page中最后一个元组添加的新page中,作为新page的firstkey,第二把填满的page的linp0指向最后一个元组也就是填满页的highkey,并清除掉原来指向最后一个元组的linpn。在创建右兄弟节点后还会判断是否有父节点,如果没有则一并创建一个父节点和一个描述父节点的结构BTPageState,并和子节点的BTPageState通过btps_next指针相关联,还会将满页的最小元组插入到父节点中,这一步作用就是将父节点和满页相链接,父节点可通过这个最小元组指针找到子节点,再将左右兄弟节点通过SpecialSpace结构中左右指针连接起来,最后再将满页写入索引文件,重复上述过程直到所有的元组全部添加完成,最后调用_bt_uppershutdown函数做收尾工作,该函数是在元组插入过程完成之后调用主要用来连接父节点和最右侧的节点,这个连接过程也是使用BTPageState结构中保存的向上指针btps_next来完成的,完成连接工作之后每个最右侧节点从firstkey到highkey的linp指针依次向左滑动一个元组的位置,最后一个linpn同样不再使用,做完滑动之后再创建一个元页并写入索引文件,到此整个B+Tree索引就构建完成了。
再梳理一下B-Tree构建的过程:先填充page,填满之后创建右兄弟节点和父节点,连接父节点和满页节点,连接左右兄弟节点,满页写入磁盘,填充新page重复上述过程,直到所有元组填充完,再连接每一层最右节点和父节点。
Btree索引的扫描
关于创建索引的过程就说这么多,B-Tree构建详细过程有很多经典的图,大家有兴趣可以网上找找,这里不在多说,下面讨论一下B-Tree索引的查询。 在He3DB中当一条sql语句的查询条件包含索引列,优化器就会将索引的查找考虑在内,一旦优化器最终选择了索引扫就会生成相关的物理算子来执行索引上的扫描过程,比如 Index Scan/BitMap Index Scan等。由前面的索引创建过程可以联想到,如果执行计划走索引扫,那必然牵涉到从索引回原表取其他列数据的过程,也就是说走索引的执行计划执行所需要的总时间是索引扫描的时间加上回表的时间,如果要想这两个过程比直接扫描原表的快一定要有特殊缩短时间的方法才能达到效果,对于B-Tree索引来说,主要用到的是B+Tree的查找特性,一有序,二每次查找都是经历从根节点到叶子结点的过程,利用二分法将查找的时间复杂度控制在logN,这样从索引文件在logN的时间内找到满足条件的索引元组,在用这些索引元组去原表文件取表元组则是有着对应的偏移量可根据偏移量直接拿到表的元组,避免全表扫,这样就可以大幅缩短整个查询的时间。
下面从代码角度剖析一下IndexScan这个算子的执行过程。
根据刚才分析BTree构建过程在插完所有的itup之后最后一步是写入元页,元页中保存了整个树的根节点信息,查找的时候就是从B+树最上层的的元页开始,先从元页中得到根节点(fastroot),在调用_bt_binsrch在根节点上找出满足扫描条件的孩子节点,因为B+Tree会将所有的key值都存在叶子结点,所以这一个过程会一直重复直到找出叶子结点为止,由于每个叶子结点可能会存有很多的索引元组,在找出的叶子结点上需要再次调用_bt_binsrch函数进一步找出满足条件的索引元组的offset,在调用_bt_readpage根据offset在page中找到itup,如此就得到了IndexScan算子回表需要用的tid,下图展示了tid的内存定义结构:
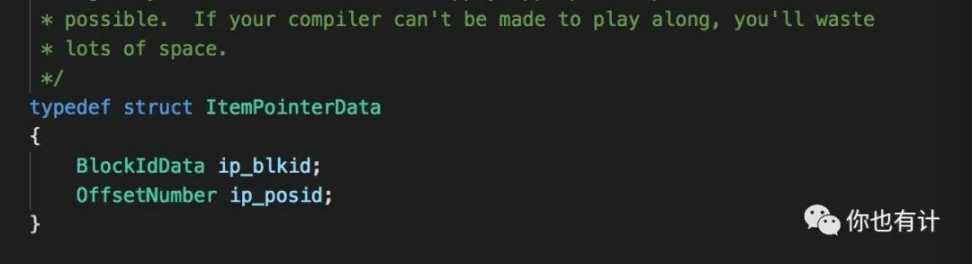
可以看出来tid中详细记载了当前tid所指向的表元组在哪个block以及block内的偏移,所以再打开原表文件的时候可以直接定位到要找的内容到此整个索引查找的过程基本就结束了。
还有一个需要区别一下的就是IndexScan和BitMap Index Scan都是索引扫描算子,他们的区别在于Index Scan一次只返回一个tid,而BitMap Index Scan会将所有满足条件的tid封装成为一个bitmap一次性返回给执行器,执行器再利用bitmap逐条的回表,这个设计可以减少索引底层的函数调用次数提升性能。
Btree索引的插入
下面再说说B-Tree索引的插入:
插入相关的数据结构:
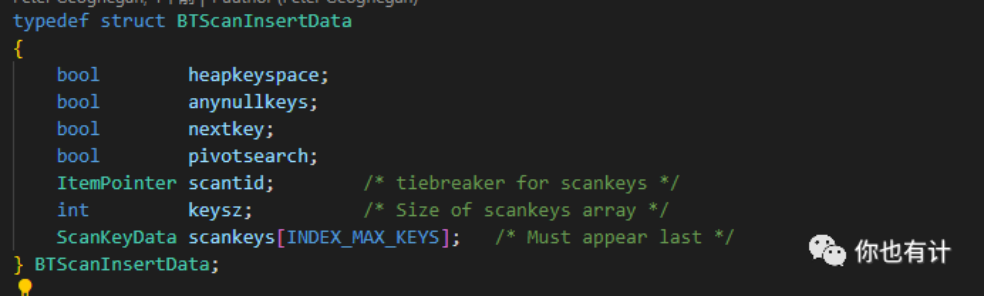
BTScanInsert结构保存了要插入元组对应生成的scankey等信息,B-Tree查询时也用到这个结构。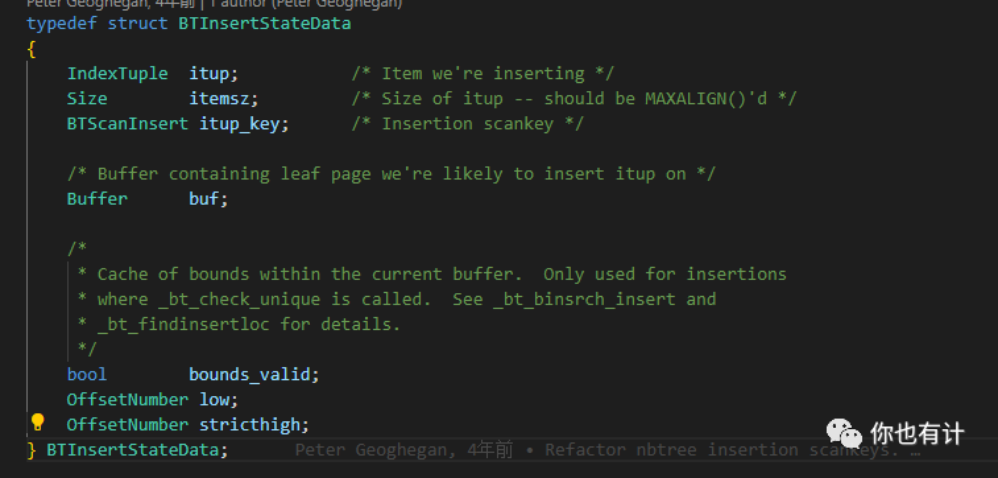
BTInsertStateData结构在整个插入阶段工作,它包含了要插入了itup,itup_key, 插入的buf等信息。
一个有索引的表对其插入数据,生成的执行计划中是会包含索引相关的维护操作,对于B-Tree索引来说btinsert函数就是做插入维护B-Tree索引的,这个函数会先将表元组转换成索引元组,在将索引元组插入B-Tree上的相应位置。
btinsert函数首先将原表元组生成要插入的索引元组itup,再用itup生成BTScanInsert结构,该结构包含了查找插入位置需要用的关键信息scankey,插入过程同样会调用到_bt_search函数来找到itup对应的节点号,然后构建BTInsertStateData结构,后续在页面上找到应该插入的偏移位置,拿到位置之后就可以直接将索引元组插入到对应的偏移位置即可,这里会有两种情况,一种是当前页面剩余的空间充足,可以容纳要插入的itup,直接将元组插进去就完成了索引插入的过程,还一种情况是页面剩余空间不足以容纳itup,此时会发生页面分裂。
_bt_split函数是He3DB处理B-Tree页面分裂的主函数,在索引插入数据的过程中一旦发生页面分裂就会调用到这个函数,它的处理逻辑是:首先计算出一个合适的分裂位置,创建一个新的左节点和一个右节点,从原页的firstkey遍历到highkey,根据分裂的位置将原page中的itup分成两份分别放在左右节点中,这个遍历过程包含了新插入的itup插入对应的节点,再将左page的所有itup拷贝到原page中,释放左page,到此就得到了分裂后的两个节点,
_bt_split处理完成,然后再将原page的highkey(也就是分裂后右节点的firstkey)插入到父节点中将右孩子与父节点相连,并递归的判断是否父节点也要分裂,重复上述过程直到所有分裂出来的右节点都完成和父节点的连接,分裂过程处理就结束了。
Btree索引的删除
最后再来讨论一下B-Tree索引的删除
先看个delete语句的执行计划

上图中的执行计划在删除原表数据前会先扫描表上的索引,得到tid在回原表上删除表元组,实际上删除表元组的操作只是将对应的表元组标记为DEAD状态,并未实际的从磁盘中物理删除,此时在查这条数据时虽然数据还在,但由于表元组已经被标记为DEAD状态,所以对数据库来说这条记录是不可查的。而这条记录只有在最终对表做vacuum操作时才会从BTree对应的page上真正的删除掉。
vacuum删除物理索引元组的过程:在对一张表做vacuum时,如果表上有索引在,那么会对应的去每个索引上删除相应的索引元组,He3DB B-Tree索引提供了一个批量删除的接口btbulkdelete,该函数会遍历除了元页之外的B-Tree所有节点,并找出每个节点内需要delete的itup,调用_bt_delitems_vacuum函数从对应的page中删除所有要删除的itup,完成磁盘空间释放。
到此本文的正文内容就基本结束了,下面做个总结。
1. 基于B+tree实现的索引适用于等值和范围查找,尤其是范围查找由于左右节点可以直接相连使得范围查找不必再回溯到父节点上加快了查找的速度。
2.B+tree内部节点指向下一层节点的位置,叶子节点指向实际存储数据的位置。
3. B+tree索引的并发扫描插入和锁控制相关进阶内容下次再说吧

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 31
31 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)