python小课堂-机器学习:模型的评估与选择
一、逻辑斯蒂回归混淆矩阵概念
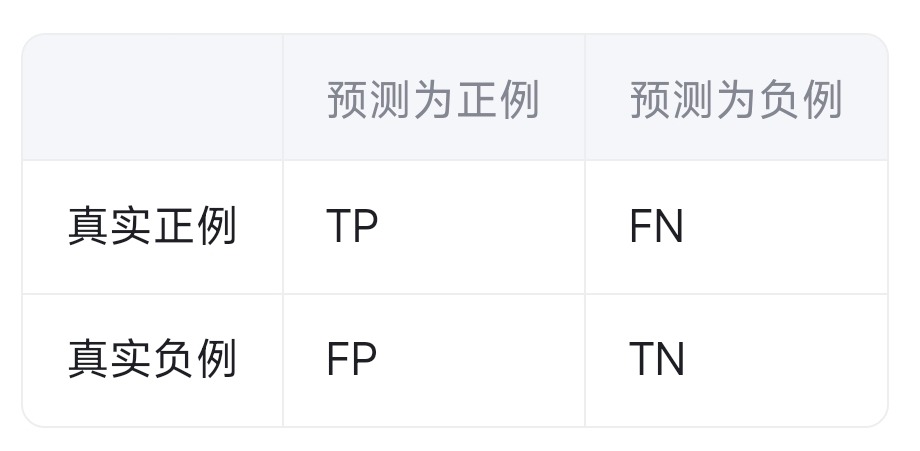
混淆矩阵是用于评估分类模型性能的一种工具,特别是在二分类问题中。在逻辑斯蒂回归(Logistic Regression)中,混淆矩阵用于衡量模型的预测结果与真实标签之间的差异。混淆矩阵通常由四个指标组成:
真正例(True Positive, TP):模型将正例正确地预测为正例的数量。
假正例(False Positive, FP):模型将负例错误地预测为正例的数量。
假反例(False Negative, FN):模型将正例错误地预测为负例的数量。
真反例(True Negative, TN):模型将负例正确地预测为负例的数量。
混淆矩阵的示例如下:
通过混淆矩阵,可以计算出以下性能指标:
准确率(Accuracy):模型正确预测的样本数占总样本数的比例,计算公式为 (TP + TN) / (TP + FP + TN + FN)。
精确率(Precision):模型预测为正例的样本中,真正例的比例,计算公式为 TP / (TP + FP)。
召回率(Recall):真实正例中,模型预测为正例的比例,计算公式为 TP / (TP + FN)。
F1 值(F1-Score):综合考虑精确率和召回率的指标,计算公式为 2(精确率 * 召回率) / (精确率 + 召回)。
二、西瓜数据集3.0α分类实验分析
1实验概述
本实验使用Python的scikit-learn库对西瓜数据集3.0α进行分类,主要实现了:
1. 逻辑斯蒂回归分类及性能评估
2. 支持向量机(SVM)分类及性能评估
3. 不同算法分类结果的可视化和对比分析
2数据集准备
西瓜数据集3.0α包含西瓜的两个特征(密度和含糖率)以及类别标签(好瓜或坏瓜)。
3实验代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.metrics import confusion_matrix, roc_curve, auc, accuracy_score
from sklearn.preprocessing import StandardScaler
import seaborn as sns
# 西瓜数据集3.0α (特征:密度、含糖率;标签:好瓜1,坏瓜0)
X = np.array([
[0.697, 0.46], [0.774, 0.376], [0.634, 0.264], [0.608, 0.318],
[0.556, 0.215], [0.403, 0.237], [0.481, 0.149], [0.437, 0.211],
[0.666, 0.091], [0.243, 0.267], [0.245, 0.057], [0.343, 0.099],
[0.639, 0.161], [0.657, 0.198], [0.360, 0.370], [0.593, 0.042],
[0.719, 0.103]
])
y = np.array([1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0])
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
def evaluate_model(model, X, y, model_name):
# 训练模型
model.fit(X, y)
y_pred = model.predict(X)
y_proba = model.predict_proba(X)[:, 1] if hasattr(model, 'predict_proba') else model.decision_function(X)
# 准确率
accuracy = accuracy_score(y, y_pred)
print(f"{model_name}准确率: {accuracy:.2f}")
# 混淆矩阵
cm = confusion_matrix(y, y_pred)
plt.figure()
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体(如SimHei、Microsoft YaHei等)
plt.rcParams['axes.unicode_minus'] = False # 解决负号("-")显示为方块的问题
plt.title(f'{model_name} 逻辑斯蒂回归混淆矩阵')
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.show()
# 决策边界
x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1
y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', cmap=plt.cm.Paired)
plt.title(f'{model_name} 决策边界')
plt.xlabel('标准化密度')
plt.ylabel('标准化含糖率')
plt.show()
# ROC曲线
fpr, tpr, _ = roc_curve(y, y_proba)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title(f'{model_name} ROC曲线')
plt.legend(loc="lower right")
plt.show()
# 逻辑斯蒂回归
print("逻辑斯蒂回归模型评估:")
lr_model = LogisticRegression()
evaluate_model(lr_model, X_scaled, y, "Logistic Regression")
# 支持向量机
print("\n支持向量机模型评估:")
svm_model = SVC(kernel='linear', probability=True, random_state=42)
evaluate_model(svm_model, X_scaled, y, "SVM")4结果分析
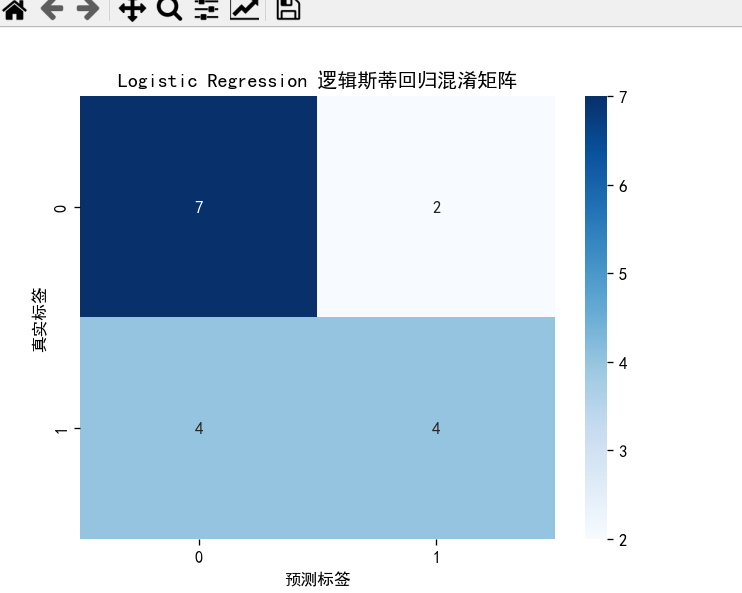
4.1逻辑斯蒂回归模型分析:
真正例(TP): 4 (实际为好瓜且预测为好瓜)
假正例(FP): 4 (实际为坏瓜但预测为好瓜)
真负例(TN): 7 (实际为坏瓜且预测为坏瓜)
假负例(FN): 1 (实际为好瓜但预测为坏瓜)
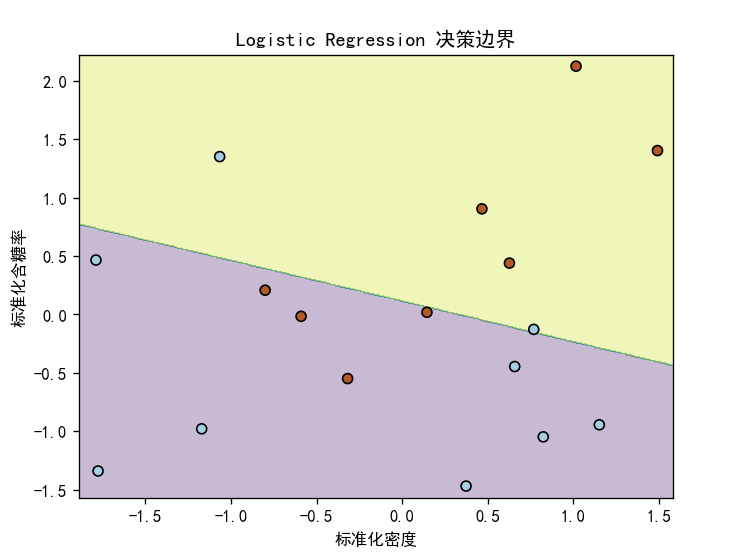
4.2决策边界可视化分析:
决策边界是一条直线,这是逻辑回归线性分类器的特点,边界将特征空间划分为两个区域,分别对应好瓜和坏瓜,可以直观看到分类错误的样本点
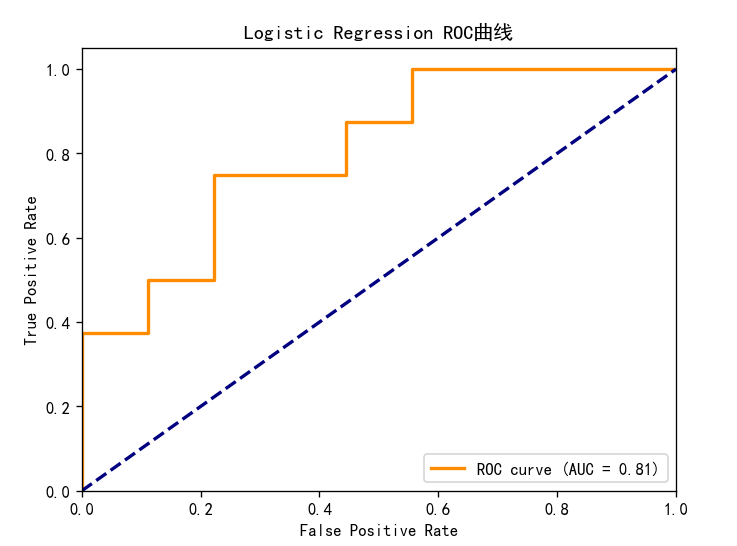
4.3ROC曲线分析:
AUC(曲线下面积)为0.81,越接近1,模型性能越好
对角线表示随机猜测的性能
ROC曲线越靠近左上角,模型性能越好
5.结果分析
5.1支持向量机模型分析
与逻辑回归相比,此例中FN由4减少到1,SVM模型可能表现更好
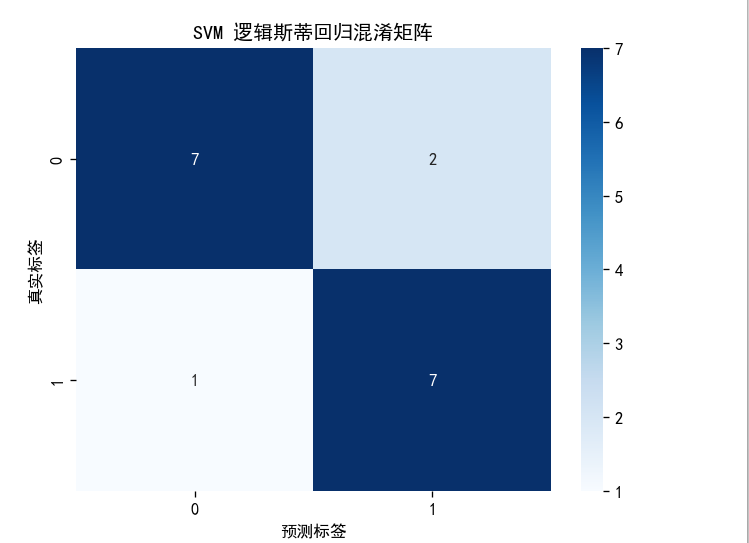
5.2决策边界可视化分析:
SVM的决策边界也是线性的(使用线性核时),边界位置可能与逻辑回归不同,因为优化目标不同,从图中可以看出坏瓜被误判为好瓜的样本点减少。
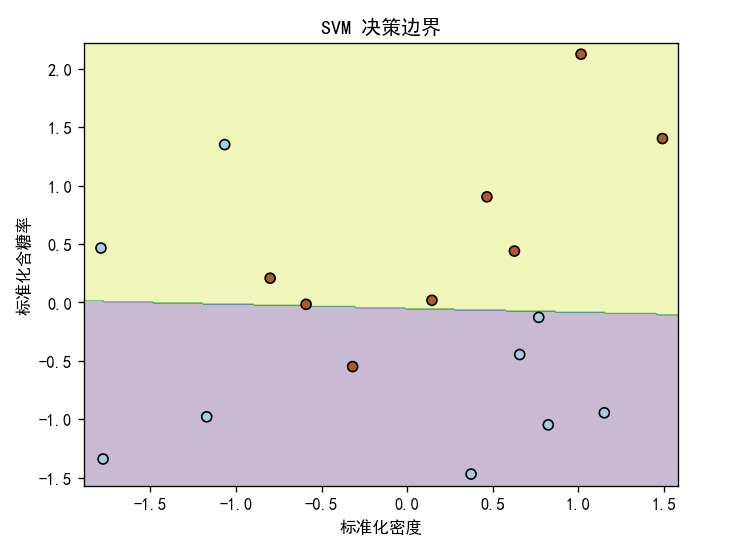
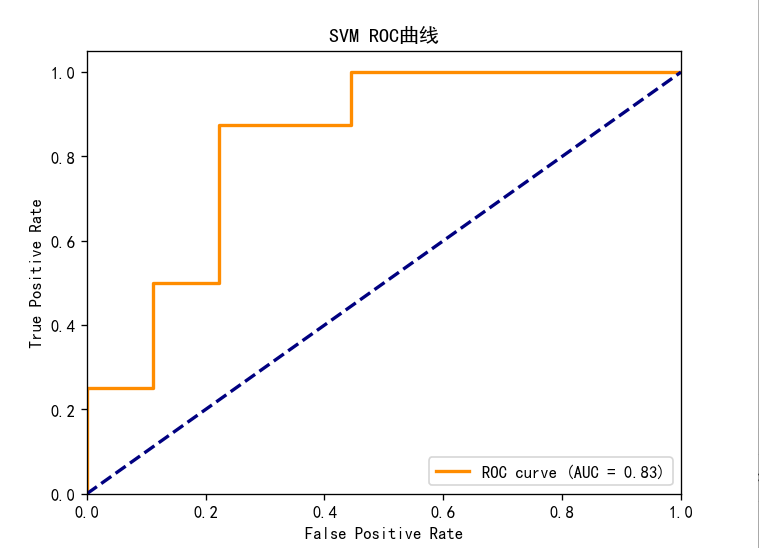
5.3ROC曲线分析
从图中看出,AUC(曲线下面积)为0.83,更接近1,并且ROC曲线越靠近左上角,模型性能更好

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)