【完整源码+数据集+部署教程】轮胎表面缺陷检测图像分割系统源码和数据集:改进yolo11-DynamicConv
背景意义
研究背景与意义
随着汽车工业的快速发展,轮胎作为车辆安全和性能的重要组成部分,其质量直接影响到行车安全和驾驶体验。因此,轮胎表面缺陷的检测变得尤为重要。传统的人工检测方法不仅耗时耗力,而且容易受到人为因素的影响,导致漏检或误检的情况。为了提高检测的准确性和效率,基于计算机视觉的自动化检测技术逐渐成为研究的热点。
近年来,深度学习技术的快速发展为图像处理和物体检测提供了新的解决方案。YOLO(You Only Look Once)系列模型因其高效的实时检测能力和较高的准确率,广泛应用于各类物体检测任务。YOLOv11作为该系列的最新版本,结合了更为先进的网络结构和优化算法,能够在复杂环境中实现更为精确的目标检测。然而,针对轮胎表面缺陷的特定需求,现有的YOLOv11模型仍需进行改进,以适应轮胎表面缺陷检测的特点。
本研究基于改进的YOLOv11模型,构建一个针对轮胎表面缺陷的图像分割系统。数据集包含880张经过标注的轮胎缺陷图像,涵盖了四类缺陷:CBU(表面气泡)、bead_damage(胎圈损伤)、cut(切割)和tr(裂纹)。这些缺陷的准确识别与分割不仅有助于提高轮胎生产过程中的质量控制,还能为后续的维修和更换提供科学依据。通过对YOLOv11模型的改进与优化,本研究旨在提升轮胎表面缺陷检测的精度和效率,为智能制造和自动化检测技术的发展贡献力量。
图片效果
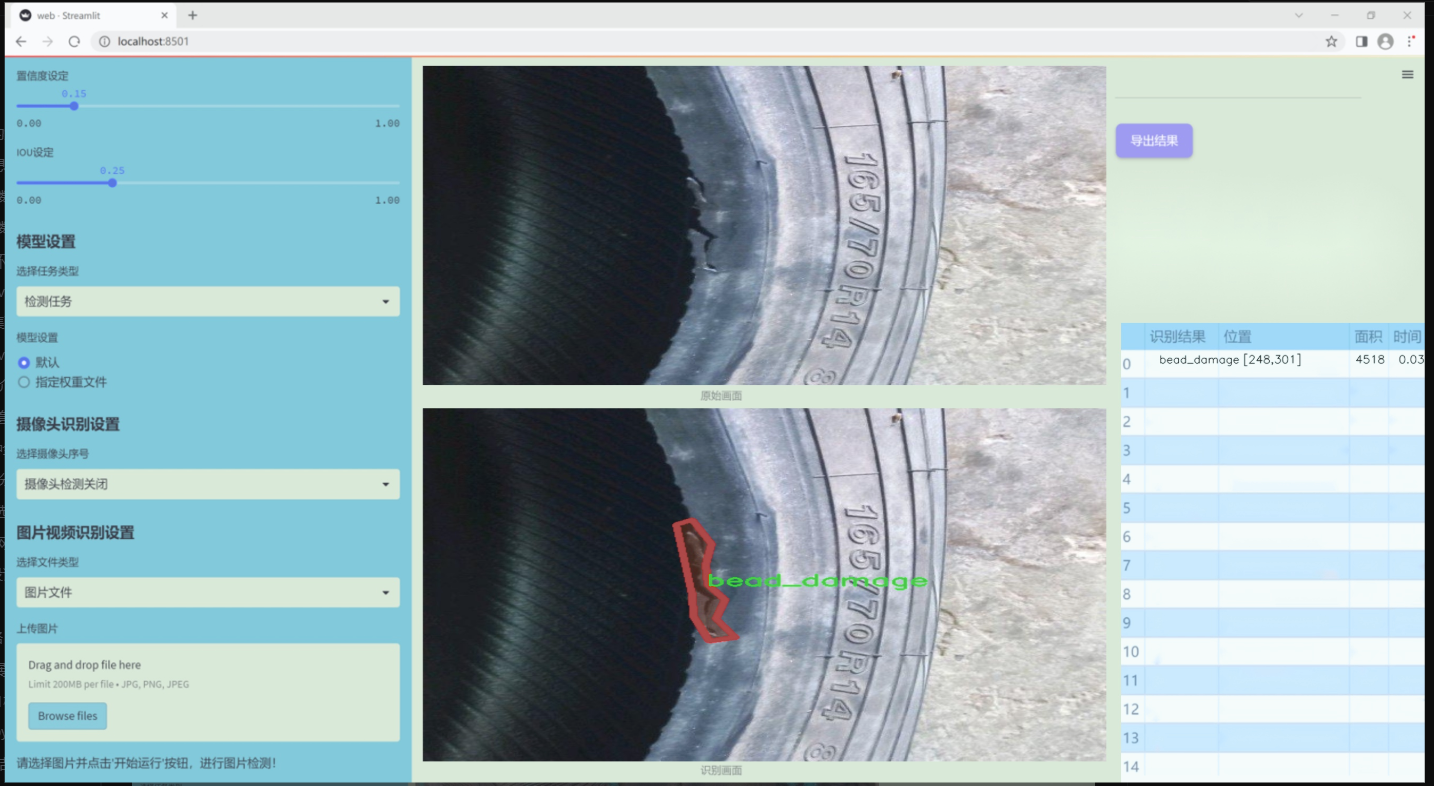
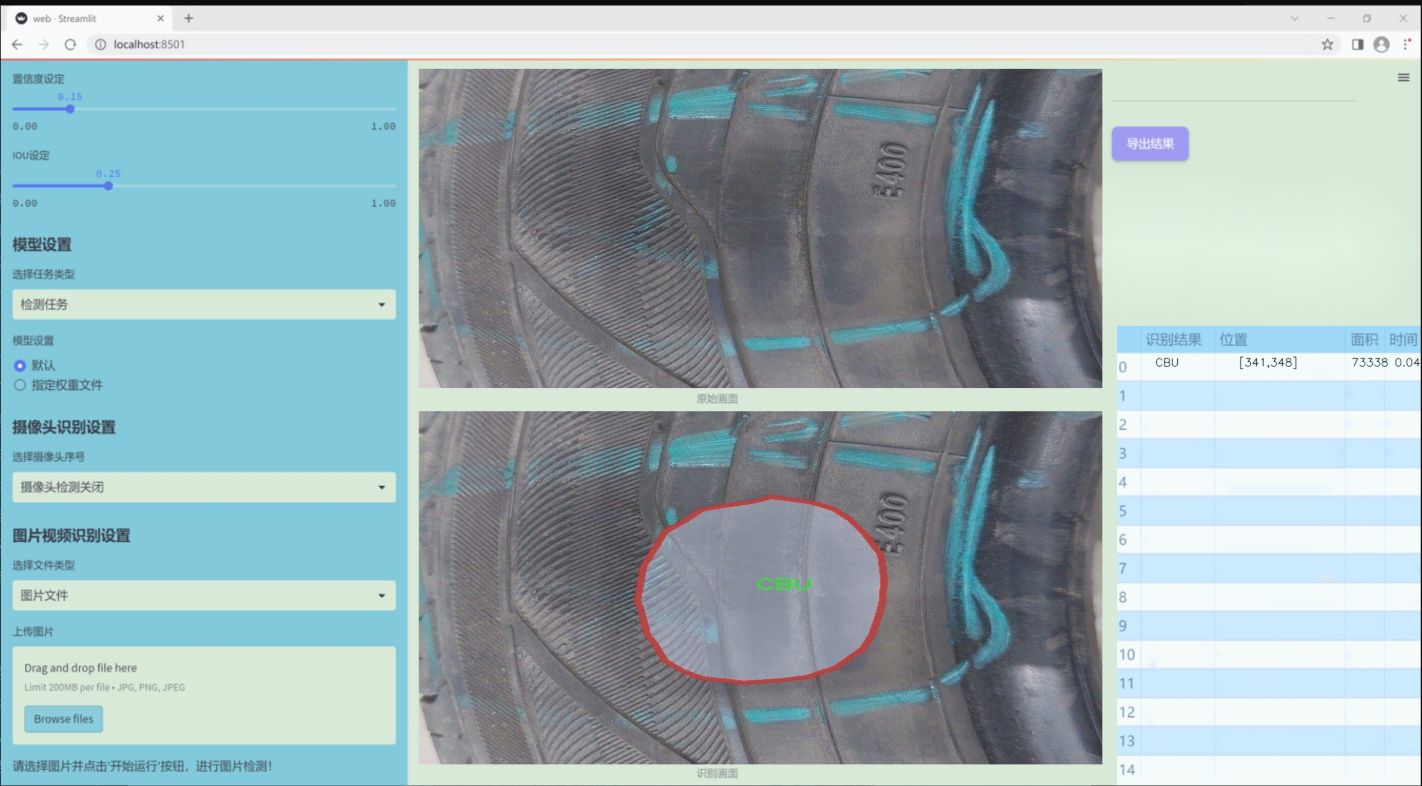
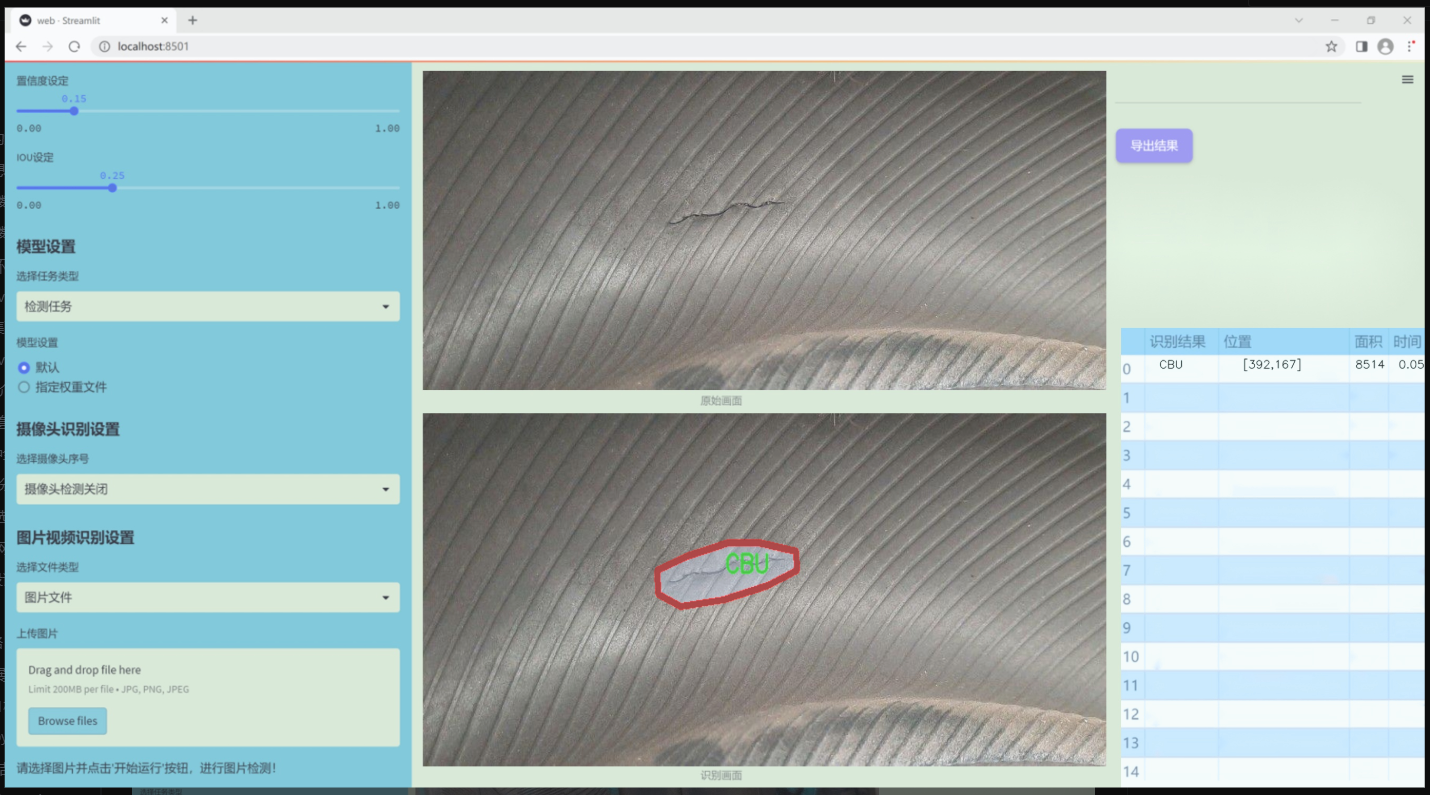
数据集信息
本项目数据集信息介绍
本项目旨在改进YOLOv11的轮胎表面缺陷检测图像分割系统,因此我们构建了一个专门针对轮胎缺陷的图像数据集。该数据集的主题围绕“缺陷”(defect),涵盖了轮胎表面可能出现的多种问题,以提高模型在实际应用中的准确性和鲁棒性。数据集中包含四个主要类别,分别为“CBU”(侧壁裂纹)、“bead_damage”(胎圈损伤)、“cut”(切割缺陷)和“tr”(胎面磨损)。这些类别的选择基于轮胎在使用过程中常见的缺陷类型,旨在帮助模型更好地识别和分割不同的缺陷区域。
数据集的构建过程包括收集大量高质量的轮胎图像,这些图像涵盖了不同的拍摄角度、光照条件和轮胎类型,以确保模型能够在多样化的环境中进行有效的学习。每个图像都经过精确标注,确保缺陷区域的边界清晰可见,从而为图像分割任务提供了可靠的训练数据。此外,为了增强模型的泛化能力,数据集中还包含了一些经过数据增强处理的图像,如旋转、缩放和颜色调整等。这些处理不仅丰富了数据集的多样性,还提高了模型在面对未知数据时的表现。
通过使用这一数据集,我们期望能够显著提升YOLOv11在轮胎表面缺陷检测中的性能,使其能够快速、准确地识别出各种缺陷类型,从而为轮胎质量监控和安全检测提供强有力的技术支持。整体而言,本项目的数据集为改进现有的缺陷检测系统奠定了坚实的基础,助力于实现更高效的轮胎安全管理。




核心代码
以下是经过简化和注释的核心代码部分,主要集中在 FreqFusion 类及其关键方法上。
import torch
import torch.nn as nn
import torch.nn.functional as F
class FreqFusion(nn.Module):
def init(self, channels, scale_factor=1, lowpass_kernel=5, highpass_kernel=3, **kwargs):
super().init()
hr_channels, lr_channels = channels
self.scale_factor = scale_factor
self.lowpass_kernel = lowpass_kernel
self.highpass_kernel = highpass_kernel
# 压缩高分辨率和低分辨率特征通道
self.compressed_channels = (hr_channels + lr_channels) // 8
self.hr_channel_compressor = nn.Conv2d(hr_channels, self.compressed_channels, 1)
self.lr_channel_compressor = nn.Conv2d(lr_channels, self.compressed_channels, 1)
# 低通和高通滤波器的卷积层
self.content_encoder = nn.Conv2d(
self.compressed_channels,
lowpass_kernel ** 2 * self.scale_factor * self.scale_factor,
kernel_size=3,
padding=1
)
self.content_encoder2 = nn.Conv2d(
self.compressed_channels,
highpass_kernel ** 2 * self.scale_factor * self.scale_factor,
kernel_size=3,
padding=1
)
def kernel_normalizer(self, mask, kernel):
"""
对卷积核进行归一化处理。
参数:
- mask: 输入的mask
- kernel: 卷积核大小
返回:
- 归一化后的mask
"""
n, mask_c, h, w = mask.size()
mask_channel = int(mask_c / float(kernel**2))
mask = mask.view(n, mask_channel, -1, h, w)
mask = F.softmax(mask, dim=2) # 对mask进行softmax归一化
mask = mask.view(n, mask_channel, kernel, kernel, h, w)
mask = mask.permute(0, 1, 4, 5, 2, 3).view(n, -1, kernel, kernel)
mask /= mask.sum(dim=(-1, -2), keepdims=True) # 确保mask的和为1
return mask
def forward(self, x):
"""
前向传播函数,处理输入特征。
参数:
- x: 输入特征,包含高分辨率和低分辨率特征
返回:
- 融合后的高分辨率特征
"""
hr_feat, lr_feat = x
compressed_hr_feat = self.hr_channel_compressor(hr_feat) # 压缩高分辨率特征
compressed_lr_feat = self.lr_channel_compressor(lr_feat) # 压缩低分辨率特征
# 计算低通和高通滤波器的mask
mask_lr = self.content_encoder(compressed_hr_feat) + self.content_encoder(compressed_lr_feat)
mask_hr = self.content_encoder2(compressed_hr_feat) + self.content_encoder2(compressed_lr_feat)
# 归一化mask
mask_lr = self.kernel_normalizer(mask_lr, self.lowpass_kernel)
mask_hr = self.kernel_normalizer(mask_hr, self.highpass_kernel)
# 使用mask进行特征融合
lr_feat = F.interpolate(lr_feat, size=hr_feat.shape[2:], mode='nearest')
hr_feat = hr_feat + lr_feat # 融合特征
return hr_feat
示例使用
channels = (高分辨率通道数, 低分辨率通道数)
model = FreqFusion(channels=(64, 32))
output = model((高分辨率特征, 低分辨率特征))
代码注释说明:
类的初始化:init 方法中定义了高分辨率和低分辨率特征的通道压缩,以及低通和高通滤波器的卷积层。
kernel_normalizer 方法:用于对卷积核进行归一化处理,确保输出的mask在空间上具有相同的权重。
forward 方法:实现了前向传播,输入高分辨率和低分辨率特征,经过压缩和滤波后进行特征融合,输出融合后的高分辨率特征。
该代码实现了频率感知特征融合的基本框架,适用于图像预测任务。
这个程序文件 FreqFusion.py 实现了一种频率感知特征融合的方法,主要用于密集图像预测任务。程序中使用了 PyTorch 框架,定义了多个类和函数,以便于在图像处理过程中进行特征的压缩、融合和上采样。
首先,文件导入了必要的库,包括 PyTorch 的核心模块和一些用于图像处理的函数。接着,定义了一些初始化函数,如 normal_init 和 constant_init,用于初始化神经网络层的权重和偏置。这些初始化方法确保网络在训练开始时有一个合理的起点。
resize 函数用于调整输入张量的大小,支持多种插值模式,并且在某些情况下会发出警告,以帮助用户避免潜在的对齐问题。hamming2D 函数则生成一个二维的 Hamming 窗,通常用于信号处理中的窗口函数。
接下来,定义了 FreqFusion 类,这是该文件的核心部分。这个类继承自 nn.Module,其构造函数接受多个参数,包括通道数、缩放因子、低通和高通卷积核的大小等。类中定义了多个卷积层,用于特征的压缩和编码。具体来说,hr_channel_compressor 和 lr_channel_compressor 分别用于高分辨率和低分辨率特征的压缩,content_encoder 则用于生成低通和高通特征。
在 FreqFusion 类中,init_weights 方法用于初始化网络中的卷积层,确保它们的权重符合一定的分布。kernel_normalizer 方法则用于对生成的掩码进行归一化处理,以确保其和为1。
forward 方法是模型的前向传播函数,它接受高分辨率和低分辨率的特征输入,进行特征融合。根据不同的配置,可能会使用高通和低通卷积生成的掩码来对特征进行处理。融合的结果是高分辨率特征和低分辨率特征的加和,最终输出融合后的特征图。
此外,文件中还定义了 LocalSimGuidedSampler 类,这是一个用于生成偏移量的模块,主要用于特征的重采样。它通过计算输入特征的相似度来指导重采样过程,从而增强特征的空间一致性。
最后,compute_similarity 函数用于计算输入张量中每个点与其周围点的余弦相似度,以便在特征重采样时使用。
整体来看,这个程序实现了一个复杂的图像特征融合框架,结合了多种卷积操作和特征处理技术,旨在提高图像预测的精度和效果。
10.4 EfficientFormerV2.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import math
import itertools
class Attention4D(nn.Module):
def init(self, dim=384, key_dim=32, num_heads=8, attn_ratio=4, resolution=7, act_layer=nn.ReLU, stride=None):
super().init()
self.num_heads = num_heads # 注意力头的数量
self.scale = key_dim ** -0.5 # 缩放因子
self.key_dim = key_dim # 键的维度
self.nh_kd = key_dim * num_heads # 每个头的键的总维度
# 如果有步幅,则调整分辨率和定义卷积层
if stride is not None:
self.resolution = math.ceil(resolution / stride) # 计算新的分辨率
self.stride_conv = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=3, stride=stride, padding=1, groups=dim),
nn.BatchNorm2d(dim),
)
self.upsample = nn.Upsample(scale_factor=stride, mode='bilinear') # 上采样
else:
self.resolution = resolution
self.stride_conv = None
self.upsample = None
self.N = self.resolution ** 2 # 分辨率的平方
self.d = int(attn_ratio * key_dim) # 输出的维度
self.dh = self.d * num_heads # 所有头的输出维度
self.attn_ratio = attn_ratio # 注意力比率
# 定义查询、键、值的卷积层
self.q = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1), nn.BatchNorm2d(self.num_heads * self.key_dim))
self.k = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1), nn.BatchNorm2d(self.num_heads * self.key_dim))
self.v = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.d, 1), nn.BatchNorm2d(self.num_heads * self.d))
# 局部值的卷积层
self.v_local = nn.Sequential(
nn.Conv2d(self.num_heads * self.d, self.num_heads * self.d, kernel_size=3, stride=1, padding=1, groups=self.num_heads * self.d),
nn.BatchNorm2d(self.num_heads * self.d),
)
# 定义投影层
self.proj = nn.Sequential(act_layer(), nn.Conv2d(self.dh, dim, 1), nn.BatchNorm2d(dim))
# 计算注意力偏置
points = list(itertools.product(range(self.resolution), range(self.resolution)))
attention_offsets = {}
idxs = []
for p1 in points:
for p2 in points:
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = nn.Parameter(torch.zeros(num_heads, len(attention_offsets))) # 注意力偏置参数
self.register_buffer('attention_bias_idxs', torch.LongTensor(idxs).view(self.N, self.N)) # 注册偏置索引
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and hasattr(self, 'ab'):
del self.ab # 删除训练模式下的偏置
else:
self.ab = self.attention_biases[:, self.attention_bias_idxs] # 获取偏置
def forward(self, x): # 前向传播
B, C, H, W = x.shape # 获取输入的形状
if self.stride_conv is not None:
x = self.stride_conv(x) # 应用步幅卷积
# 计算查询、键、值
q = self.q(x).flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 3, 2)
k = self.k(x).flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 2, 3)
v = self.v(x)
v_local = self.v_local(v)
v = v.flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 3, 2)
# 计算注意力权重
attn = (q @ k) * self.scale + (self.attention_biases[:, self.attention_bias_idxs] if self.training else self.ab)
attn = attn.softmax(dim=-1) # 归一化
x = (attn @ v) # 计算输出
out = x.transpose(2, 3).reshape(B, self.dh, self.resolution, self.resolution) + v_local # 结合局部值
if self.upsample is not None:
out = self.upsample(out) # 上采样
out = self.proj(out) # 投影
return out
EfficientFormerV2类的定义
class EfficientFormerV2(nn.Module):
def init(self, layers, embed_dims=None, mlp_ratios=4, downsamples=None, num_classes=1000, drop_rate=0., drop_path_rate=0.):
super().init()
self.patch_embed = stem(3, embed_dims[0]) # 定义初始的嵌入层
network = []
for i in range(len(layers)):
stage = eformer_block(embed_dims[i], i, layers, mlp_ratio=mlp_ratios) # 构建每一层
network.append(stage)
if downsamples[i] or embed_dims[i] != embed_dims[i + 1]:
network.append(Embedding(in_chans=embed_dims[i], embed_dim=embed_dims[i + 1])) # 添加嵌入层
self.network = nn.ModuleList(network) # 将网络层放入ModuleList中
def forward(self, x):
x = self.patch_embed(x) # 嵌入输入
for block in self.network:
x = block(x) # 逐层前向传播
return x
实例化模型
def efficientformerv2_s0(weights=‘’, **kwargs):
model = EfficientFormerV2(
layers=[2, 2, 6, 4], # 每层的深度
embed_dims=[32, 48, 96, 176], # 嵌入维度
downsamples=[True, True, True, True], # 是否下采样
**kwargs)
if weights:
pretrained_weight = torch.load(weights)[‘model’]
model.load_state_dict(pretrained_weight) # 加载预训练权重
return model
主程序入口
if name == ‘main’:
inputs = torch.randn((1, 3, 640, 640)) # 随机输入
model = efficientformerv2_s0() # 实例化模型
res = model(inputs) # 前向传播
print(res.size()) # 输出结果的尺寸
代码核心部分说明:
Attention4D类:实现了一个四维注意力机制,包含查询、键、值的计算以及注意力权重的计算。
EfficientFormerV2类:构建了整个网络结构,包括嵌入层和多个块的组合。
efficientformerv2_s0函数:用于实例化一个特定配置的EfficientFormerV2模型,并可加载预训练权重。
主程序:用于测试模型的前向传播,输出结果的尺寸。
这些部分构成了EfficientFormer模型的核心功能,其他辅助函数和类则用于模型的构建和训练。
这个程序文件实现了一个名为EfficientFormerV2的深度学习模型,主要用于图像处理任务,如图像分类。该模型的设计灵感来源于Transformer架构,并进行了优化以提高效率和性能。
首先,文件中定义了一些模型的超参数,包括不同版本的模型宽度和深度(如S0、S1、S2和L),这些参数决定了模型的复杂度和计算量。接着,文件中定义了多个类,分别实现了模型的不同组件。
Attention4D类实现了一个四维注意力机制,能够处理输入的图像特征。该类通过计算查询(Q)、键(K)和值(V)来生成注意力权重,并应用于输入特征。它还支持不同的步幅和上采样操作,以适应不同的输入分辨率。
接下来,LGQuery类和Attention4DDownsample类分别实现了局部查询和下采样的注意力机制,前者用于生成局部特征,后者则在下采样过程中应用注意力机制,以保持特征的有效性。
Embedding类负责将输入图像转换为嵌入特征,支持不同的卷积操作和归一化层,以适应不同的输入通道和嵌入维度。Mlp类实现了多层感知机,使用1x1卷积进行特征变换,并支持激活函数和丢弃层。
AttnFFN和FFN类则实现了结合注意力机制和前馈网络的模块。它们通过堆叠多个这样的模块来构建模型的核心部分。eformer_block函数用于构建每个阶段的网络块,根据输入的层数和参数生成相应的模块。
EfficientFormerV2类是模型的主类,负责构建整个网络结构。它通过调用前面定义的各个模块,逐层堆叠形成完整的模型。该类还实现了前向传播方法,能够处理输入数据并输出特征。
最后,文件中定义了一些辅助函数,如update_weight用于更新模型权重,以及不同版本的模型构建函数(efficientformerv2_s0、efficientformerv2_s1、efficientformerv2_s2和efficientformerv2_l),这些函数根据预定义的超参数创建不同规模的EfficientFormerV2模型,并加载预训练权重。
在文件的最后部分,包含了一个测试代码块,创建了不同版本的模型并对随机生成的输入数据进行前向传播,输出每个模型的特征图尺寸。这为模型的验证和调试提供了基础。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 33
33 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)