机器学习创建训练和测试集的方法
·
1.随机抽样方法
手动分离数据集
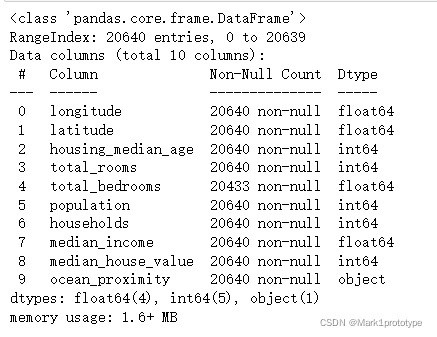
以房价数据集为例 8:2的比例分配训练集和测试集
import numpy as np
def split_train_test(data, test_ratio):
# 数据集shape[0]长度的随机序列
np.random.seed(33) # 确保生成序列一致,保持每次生成数据集一直
indices = np.random.permutation(len(data))
test_size = int(len(data) * test_ratio)
test_indices = indices[:test_size] # 前百分之test_ratio为测试集
train_indices = indices[test_size:]
return data.iloc[train_indices],data.iloc[test_indices]
train_set, test_set = split_train_test(housingdataset, 0.2)
标识符法
每个sample进入测试集之前,使用一个标识符,这样在数据集更新的时候,依然可以保证测试集是一致的; 新的实例放入到新的数据集,而使用过的数据不会再被放入新测试集。
import hashlib
def test_set(identifier, test_ratio, hash):
return hash(np.int64(identifier)).digest()[-1] < 256 * test_ratio #取hash最后一个字节,256字节的百分之test_ratio放入测试集
def split_train_test_id(data, test_ratio, id_column, hash = hashlib.md5):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set(id_, test_ratio,hash))
return data.loc[in_test_set], data.loc[in_test_set]
dataset_with_id = dataset.reset_index() # 利用data的索引行作为ID
train_set, test_set = split_train_test_id(dataset_with_id, 0.2,
"index"
numpy 包 train_test_split
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(dataset, test_size=0.2, random_state=42
2.分层抽样
分层抽样就是按照一定的数据分布规律分离数据集,从而得到符合原数据集分布的测试集和训练集。比随机抽样方法得到测试集和训练集更加不容易出现数据偏移。
假设收入中位数是一个重要的属性。我们根据收入中位数的分布来分离数据集。
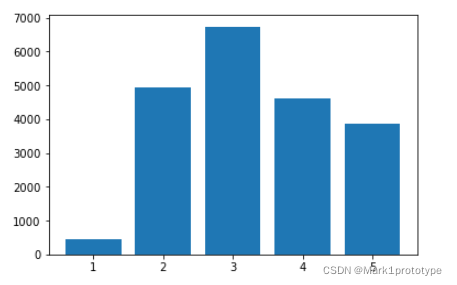
收入种类分布图
from sklearn.model_selection import StratifiedShuffleSplit
data["income_category"] = np.ceil(data["median_income"] / 1.5)
data["income_category"].where(data["income_category"]<5, 5.0, inplace = True)
# 收入中位数除以1.5限制收入类别,再取整得到离散类别,大于5的合并为一类,一共为5类。
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, ra
ndom_state=42)
for train_index, test_index in split.split(data, data["income_category"]):
strat_train_set = data.loc[train_index]
strat_test_set = data.loc[test_index]
data["income_category"].value_counts() / len(data)
与分布一致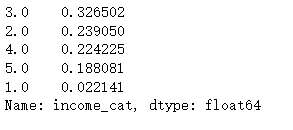
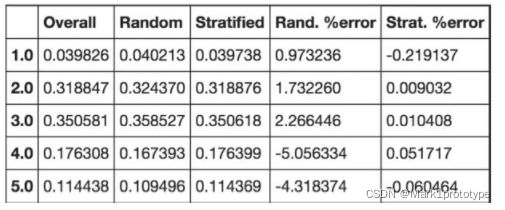
分层抽样的偏差很小与原数据集。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)