【day12】从零开始学数学建模-国赛2023C题228-问题二+问题三-LSTM模型向后预测
前言
国赛2023C题问题二
要求:考虑商超以品类为单位做补货计划,请分析各蔬菜品类的销售总量与成本加成定价的关系,并给出各蔬菜品类未来一周(2023年7月1-7日)的日补货总量和定价策略, 使得商超收益最大。
思路:首先利用双对数需求模型探究销售总量与成本加成定价的关系,然后通过LSTM模型对未来7天各品类的成本与销量进行预测,再设定价格弹性修正函数融入定价的影响,最后使用Gbest-PSO算法求解连续优化模型。
学习目标
LSTM原理及应用
LSTM模型
LSTM原理
基本原理建议听这个
其他的还有,超全面讲透一个算法模型,LSTM !! - 知乎 (zhihu.com)
长短时记忆网络(LSTM)(超详细 |附训练代码)_lstm代码-CSDN博客
LSTM从入门到精通(形象的图解,详细的代码和注释,完美的数学推导过程)_lstm模型-CSDN博客
简要的说,LSTM(长短期记忆网络)核心解决传统 RNN 在处理长序列时的 “梯度消失 / 爆炸” 问题, 通过 “门控 + 细胞状态” 的设计,让网络具备 “选择性记忆” 能力,适合处理长时序、有依赖关系的数据(如时间序列预测、自然语言处理等)。
代码
本博客代码主要参考论文附件以及利用LSTM进行时序预测(一个让你少走弯路的视频)_哔哩哔哩_bilibili
注这次LSTM主要利用Python实现,如需使用Matlab,请参考下文,基于MATLAB的LSTM神经网络时序预测_matlab lstm-CSDN博客
Step 1:导入数据库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import LSTM, Dense, Activation
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from math import sqrtStep 2:导入数据
data = pd.read_csv('result_price.csv')
#print(data.head())
data.drop(columns=data.columns[0], inplace=True)
df=np.array(data)
#print(df)Step 3:数据归一化
scaler = MinMaxScaler(feature_range = (0,1))
scaler_data = scaler.fit_transform(df)
#print(scaler_data)Step 4:转换数据格式
def create_dataset(dataset, look_back=1, look_forward=7):
dataX, dataY = [], []
for i in range(len(dataset) - look_back- look_forward):
dataX.append(dataset[i: (i + look_back), :])
dataY.append(dataset[(i + look_back):(i + look_back + look_forward), :])
return np.array(dataX), np.array(dataY)
look_back = 30
look_forward = 7
trainX, trainY = create_dataset(train, look_back, look_forward)
trainY_input = trainY.reshape(trainY.shape[0], -1)Step 5:构建LSTM模型
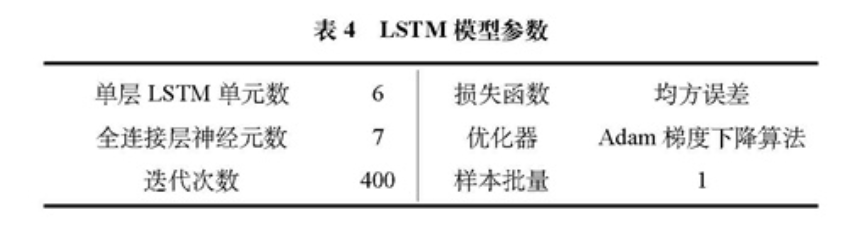
论文使用的LSTM模型参数
model = Sequential()
model.add(LSTM(6, input_shape=[look_back, 6]))
model.add(Activation('relu'))
model.add(Dense(6*7))
model.compile(loss='mse', optimizer = 'adam')
h = model.fit(trainX, trainY_input, epochs = 50, batch_size = 1, verbose=2)Step 6:预测
prediction_train = model.predict(trainX)
prediction_inverse = scaler.inverse_transform(prediction_train.reshape(-1, 6))
trainY_inverse = scaler.inverse_transform(trainY_input.reshape(-1, 6))
pre_X = train[-look_back:, :].reshape(1, look_back, 6)
per_Y = model.predict(pre_X)
per_Y_reshaped = per_Y.reshape(look_forward, 6)
per_Y_inverse = scaler.inverse_transform(per_Y_reshaped)Step 7:验证结果
i = 5
list_test = ['花叶类', '花菜类', '水生根茎类', '茄类', '辣椒类', '食用菌']
mse = mean_squared_error(trainY_inverse[:, i], prediction_inverse[:, i])
rmse = sqrt(mse)
mae = mean_absolute_error(trainY_inverse[:, i], prediction_inverse[:, i])
r2 = r2_score(trainY_inverse[:, i], prediction_inverse[:, i])
print(f'R2:{r2}, MSE:{mse}, RMSE:{rmse}, MAE:{mae}')
print(f'预测未来一天的销量:{per_Y_inverse }')
Step 8:作图
fig, ax = plt.subplots(figsize=(12, 6))
ax.plot(trainY_inverse[:, 0], label=f'True')
ax.plot(prediction_inverse[:, 0], label=f'Prediction')
ax.set_xlabel('Time')
ax.set_ylabel('Value')
ax.legend()
ax.grid()
fig.show()
fig, ax = plt.subplots(figsize=(12, 6))
loss_history = h.history['loss']
ax.plot(loss_history, label='Loss')
ax.set_xlabel('Epoch')
ax.set_ylabel('Loss')
ax.legend()
ax.set_title('Loss Over Training Epochs')
ax.grid()
fig.show()结果
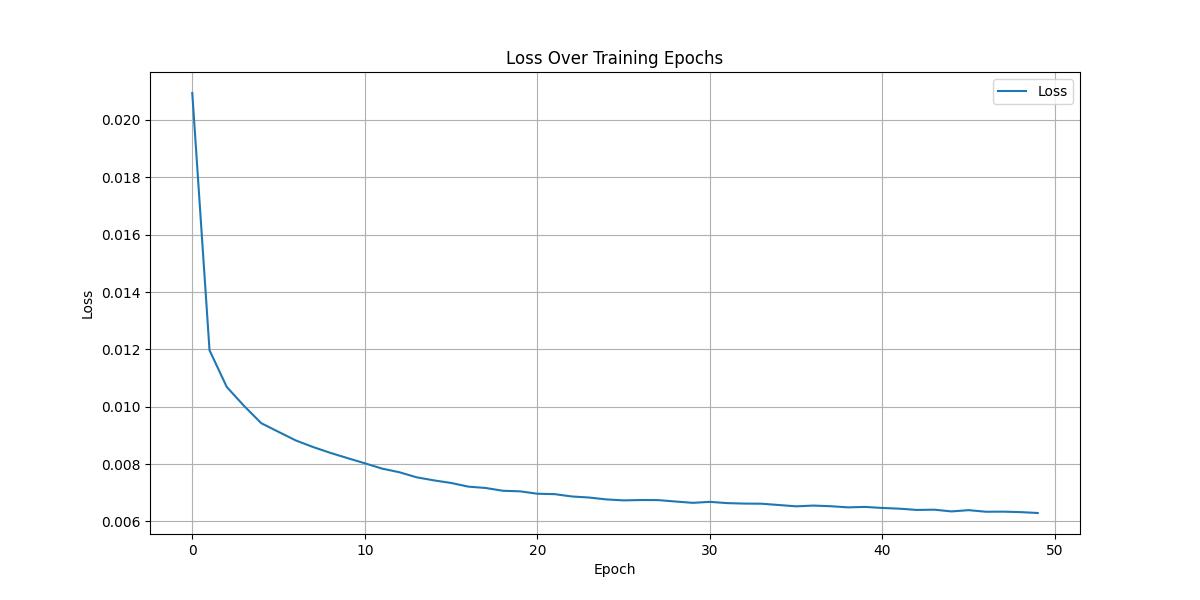 图1 训练结果
图1 训练结果
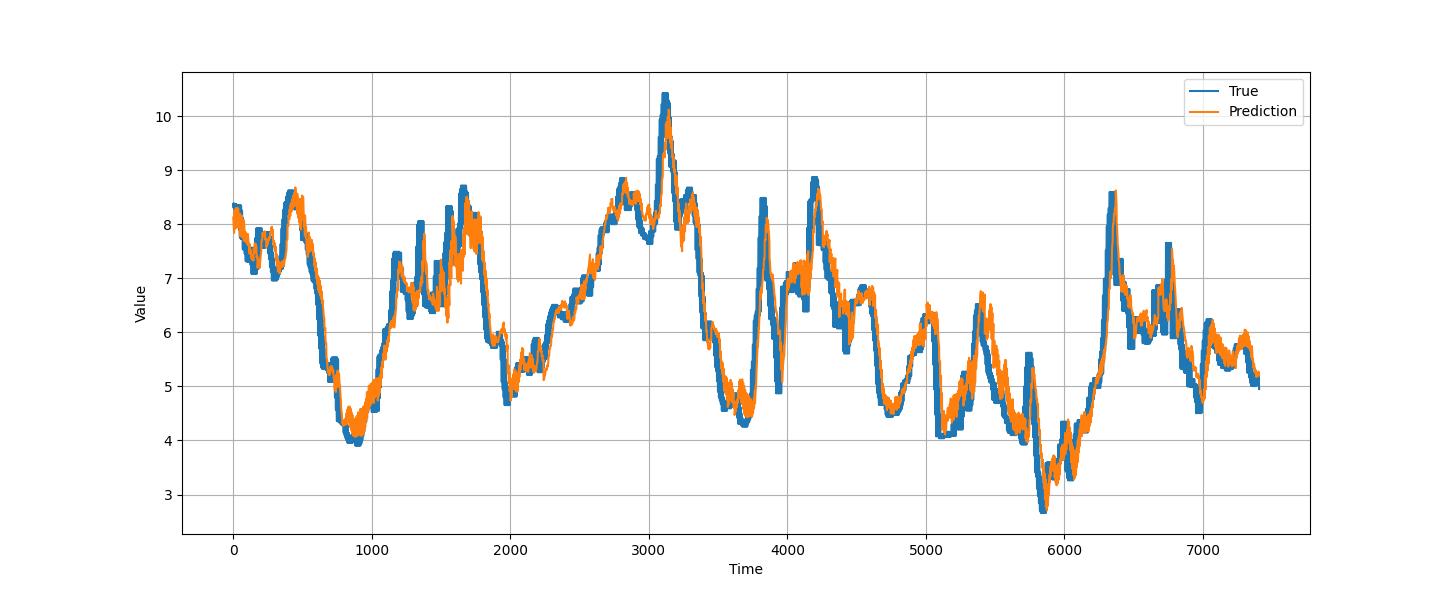
图2 进价食用菌类的真实值与预测值
表1 LSTM对进价的预测效果
| 花叶类 | 花菜类 | 水生根茎类 | 茄类 | 辣椒类 | 食用菌类 | |
| r2 | 0.8887 | 0.8447 | 0.8904 | 0.9004 | 0.9182 | 0.8393 |
| MSE | 0.2310 | 0.8996 | 1.3090 | 0.6012 | 1.6404 | 0.9212 |
| RMSE | 0.4806 | 0.9485 | 1.1441 | 0.7753 | 1.2808 | 0.9598 |
| MEA | 0.3529 | 0.6617 | 0.7392 | 0.5546 | 0.8440 | 0.7077 |
表2 LSTM对进价的预测结果
| 花叶类 | 花菜类 | 水生根茎类 | 茄类 | 辣椒类 | 食用菌类 | |
| 未来第1天 | 5.1522 | 12.0895 | 15.0872 | 8.1175 | 7.0757 | 11.0338 |
| 未来第2天 | 5.1813 | 12.0403 | 15.1549 | 8.0895 | 7.1648 | 11.0316 |
| 未来第3天 | 5.2021 | 11.9350 | 15.1859 | 8.0743 | 7.3360 | 10.9508 |
| 未来第4天 | 5.2117 | 11.8279 | 15.0287 | 8.0546 | 7.4959 | 10.9826 |
| 未来第5天 | 5.2067 | 11.6939 | 14.9942 | 8.0450 | 7.4909 | 11.0108 |
| 未来第6天 | 5.2161 | 11.5709 | 15.0057 | 8.0208 | 7.4321 | 11.0074 |
| 未来第7天 | 5.2170 | 11.4646 | 14.9785 | 8.0448 | 7.4476 | 11.0232 |
未来一周(2023年7月1-7日)的日补货总量和定价策略
C228这篇论文提到引入先验知识改进GBest-PSO算法,求解连续性优化问题。
但不得不承认,我不擅长优化算法,迄今为止仍是不能独立编写代码,由于我的代码基本参考该论文附录,烦请各位移步至论文p63-67学习。
现在附上相关的学习资料:
粒子群算法(Particle Swarm Optimization)超详细解析+入门代码实例讲解-CSDN博客
数学建模智能优化算法之粒子群算法(PSO)案例附Matlab代码_计算智能粒子群算法论文实例-CSDN博客
问题三
因蔬菜类商品的销售空间有限,商超希望进一步制定单品的补货计划,要求可 售单品总数控制在27-33 个,且各单品订购量满足最小陈列量2.5 千克的要求。根据2023 年6月24-30日的可售品种,给出7月1日的单品补货量和定价策略,在尽量满足市场对各 品类蔬菜商品需求的前提下,使得商超收益最大。
问题三同样是一个优化问题,解题思路:
采用VIKOR评价确定需求量→建立混合多目标非线性规划模型→引入先验知识改进NSGA-Ⅱ非支配排序遗传算法→引入BG-RI混合编码,建立多重CV约束→确认双优化目标→确认最优解
决策方案:附录D
代码:p63-67
相关参考资料:
【多目标优化】2. 非支配排序遗传算法 —(NSGA、NSGA-II)-CSDN博客
系列教程
国赛2023C题228论文系列教程
【day7】从零开始学数学建模-国赛2023C题228-思路-CSDN博客
【day8】从零开始学数学建模-国赛2023C题228-问题一-数据整合_2023数学建模大赛c题题目-CSDN博客
【day9】从零开始学数学建模-国赛2023C题228-问题一- 时间分布规律-CSDN博客
【day10】从零开始学数学建模-国赛2023C题228-问题二- 时间序列预测模型-ARIMA-CSDN博客

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 30
30 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)