Spark淘宝用户数据分析
·
一、项目目标:
将淘宝处理好的淘宝用户数据上传hadoop的hdfs中,在idea中通过maven管理项目,并编写用户数据分析java代码,接着用maven打包代码上传到hdfs集群中运行,接着查看结果
二、项目准备:
- hadoop集群部署,及相关组件Spark等安装
- java的idea软件安装及maven安装
三、需求分析:

四、具体内容:
1.idea中新建一个maven空项目
2.修改pom。xml文件中的内容(若下载慢,受搜索maven改国内源教程进行更改),具体如图:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>UserBehav</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<spark.version>2.0.0</spark.version>
<hadoop.version>2.7.1</hadoop.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<!--打包依赖-->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>3.用户数据分析代码具体详解:(hdfs具体读取文件目录和保存查询文件目录根据自己的更改)
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class TaobaoUserBehaviorFX {
public static void main(String[] args) {
// 创建SparkSession
SparkSession spark = SparkSession.builder()
.appName("TaobaoUserBehaviorFX")
.getOrCreate();
// 读取数据
Dataset<Row> data = spark.read()
.option("header", "true")
.option("inferSchema", "true")
.csv("hdfs:///taobaoData/input/UserBehavior.csv");
// 注册临时视图
data.createOrReplaceTempView("taobao_user_behavior");
// 使用临时视图进行查询,并将结果存储到 HDFS
spark.sql("SELECT type, COUNT(*) AS count FROM taobao_user_behavior GROUP BY type")
.coalesce(1) // 将结果合并到一个文件中
.write()
.option("header", "true")
.csv("hdfs:///taobaoData/output/type_cnt.csv");
spark.sql("SELECT itemid, COUNT(*) AS count FROM taobao_user_behavior WHERE type = 'buy' GROUP BY itemid ORDER BY count DESC LIMIT 10")
.coalesce(1) // 将结果合并到一个文件中
.write()
.option("header", "true")
.csv("hdfs:///taobaoData/output/top10_items.csv");
spark.sql("SELECT userid, COUNT(*) AS count FROM taobao_user_behavior WHERE type = 'buy' GROUP BY userid ORDER BY count DESC LIMIT 10")
.coalesce(1) // 将结果合并到一个文件中
.write()
.option("header", "true")
.csv("hdfs:///taobaoData/output/top10_users.csv");
// 关闭SparkSession
spark.stop();
}
}
4.打jar包上传hadoop集群,记得改上传后改.jar文件的执行权限和拥有者问题
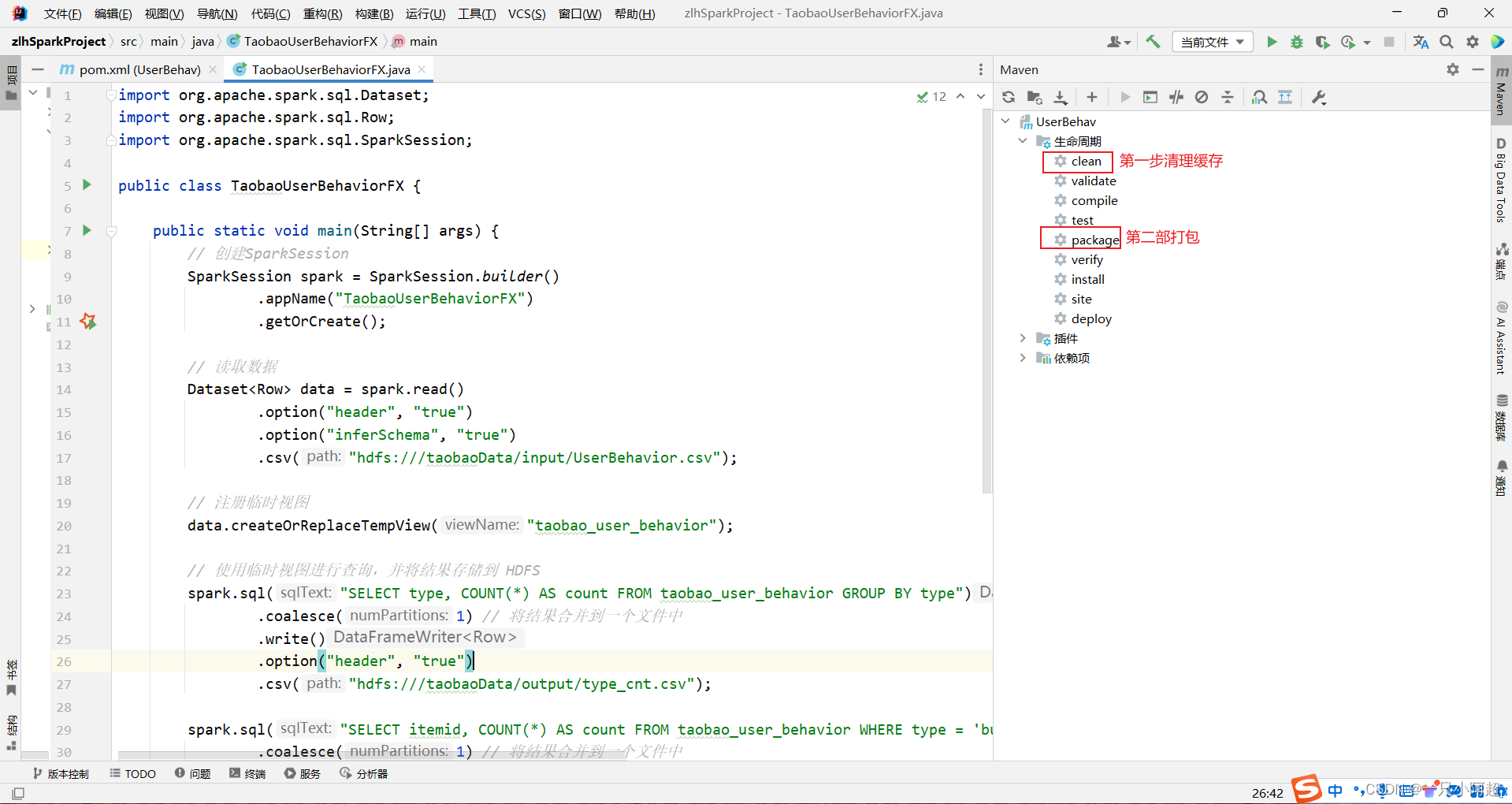
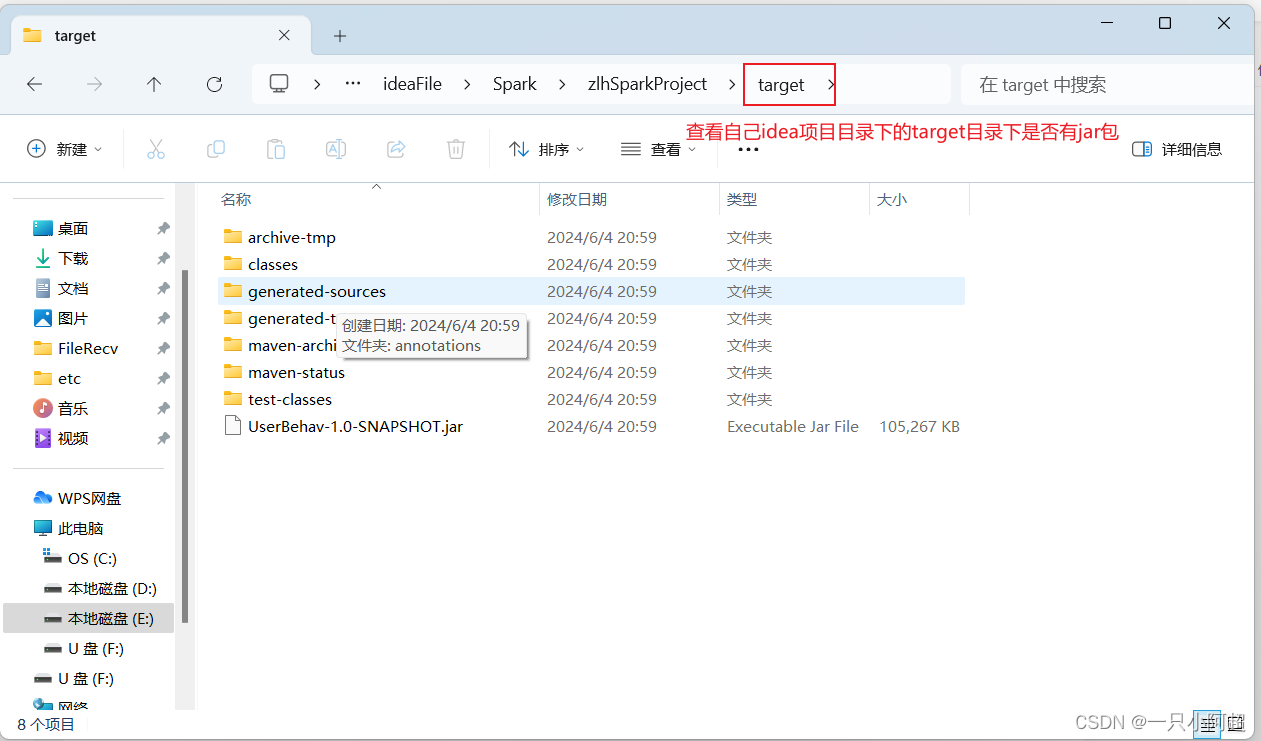
五、运行命令及结果查看
1.运行命令
spark-submit --class 类名 jar包名2.结果查看
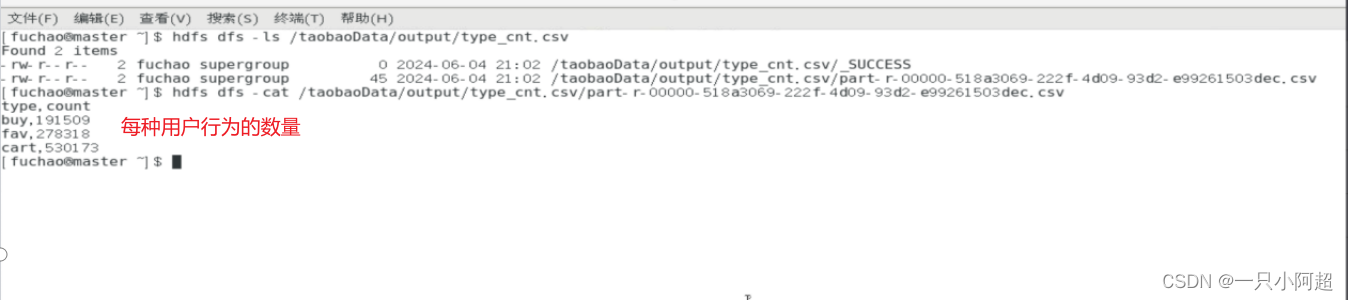
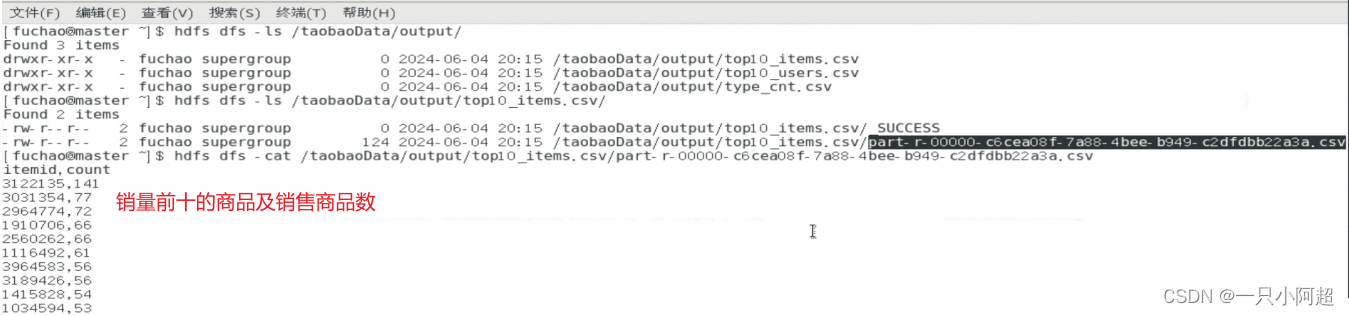
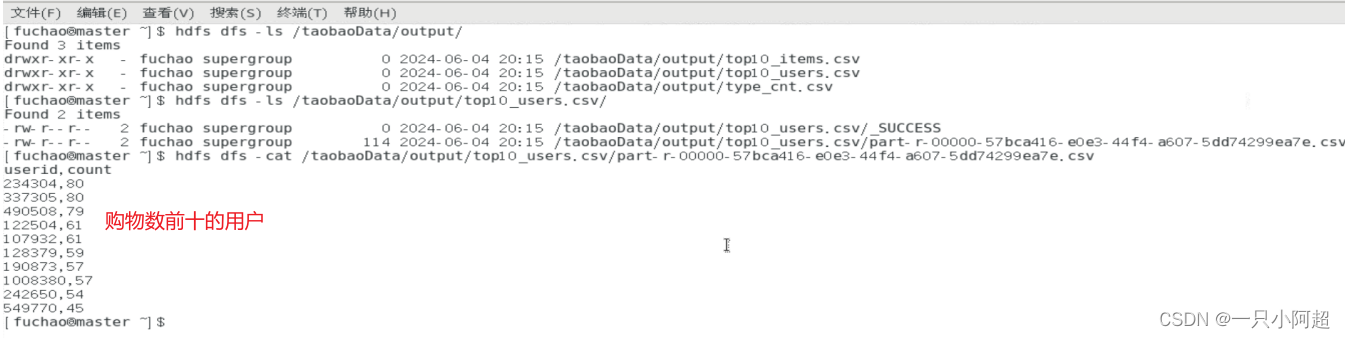
谢谢!!!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)