机器学习与临床预测模型1临床预测模型建模理论与方法(上)
一、临床预测模型概述
临床预测模型又称临床预测规则,预测模型或者风险评分。利用多因素模型估算当前患有某病的概率或者将来某结局发生的概率。
二、预测模型典型的预测方程

三、诊断模型
定义:用来预测个体患者患有某种疾病的概率。
1)特定群体:表现出某种症状的患者。
2)结局变量:患者当前状态(是否患病)。
诊断模型是诊断试验准确性研究的延伸。
四、预后模型
用来预测个体患者在未来某一时刻发生某件事的概率。
1)患者处于同样起始状态(如确诊为某病)
2)结局变量:患者将来是否发生某一件事(如死亡)
3)基线时间点:有时间维度(1,3,5年生存率)
五、两者区别
结局发生时间点:事前vs事后
研究设计类型:横截面vs队列
统计学方法:Logistic vs更多方法
预测指标:当前 vs 事前
六、预测模型的分类
单个数据集:使用全部数据建模。
1)1a型:数据有限,只有一个数据集可用。基于全部数据建立预测模型,然后使用完全相同的数据直接评估模型的预测能力。由于建模、验证使用统一数据集,通常会高估模型的预测效能。
2)1b型:数据有限,只有一个数据集可用。基于全部数据集建立预测模型,然后使用bootstrap重复抽样技术评估预测模型的效能。重复抽样技术通常被认为是内部验证,是开展预测模型研究的基本条件与方法,在数据有限的情况下较为常用。
单个数据集:使用部分数据建模。
3)2a型:数据相对较多,可被随机分成两组,一组用来建立预测模型,另一组用来评估模型的预测效果。虽然2a型研究被广泛应用,该研究并不优于1b型,因为2a型对样本利用率不高,可能导致建模和验证过程中的功效不足。
4)2b型:数据相对较多,各被随机的分成两组,一组用于建立预测模型,另一组用来评估模型的预测效果,起到外部验证的效果。2b型研究优于2a型,因为它允许两个数据集之间的非随机变化,此时对模型外推能力的验证结果更为稳健。
5)3型:数据较多,有两个以上数集即可用。使用一个数据集建立预测模型,另一个完全不同数据集用于评估模型的预测效果。比如开展前后两个独立的研究,一个用于建模,一个用于验证。
6)4型:仅针对现有(已发表)的数据模型,在独立数据集上评价其预测效果。
七、建模注意要点
训练集加内部验证是基本内容。高分文章结合外部验证。小样本推荐bootstrap法。
强烈不推荐:用复杂、高成本的指标预测低成本、容易评价的金标准。现况调查来构建预后预测模型。结局的结局作为预测因子,构建预后预测模型。
十事件不是严谨的方法,但属于可行的操作。样本量计算的自变量是研究设计时拟参与构建模型的所有候选预测变量。小样本不建议采用简单二分法进行内部验证。
八、临床预测模型研究过程
研究设计→数据收集与整理→统计分析→结果报告
1)研究设计
确立研究问题,确立模型类型,确立研究类型。
1.确立研究问题。2.诊断模型还是预后模型。3.模型开发验证还是皆而有之。4.研究设计类型:横截面,病例对照,队列研究。5.指标的选择,样本量的收集。
临床阶段中可研究的问题:根据疾病的每个阶段,可以挖掘和发现不同的研究问题。
1.预防阶段。2.诊断阶段(构建诊断模型)。3.治疗阶段。4.预后阶段(构建预后模型)。
开发还是验证:开发+验证是基本的;开发+外部验证,大文章、好文章
临床研究设计类型:1)诊断模型:横截面调查。2)预后模型:横截面调查,病例对照研究,队列研究。
2)PECOS准则:研究类型,研究对象/人群,干预性研究还是观察性研究,研究结局
3)诊断模型的研究设计
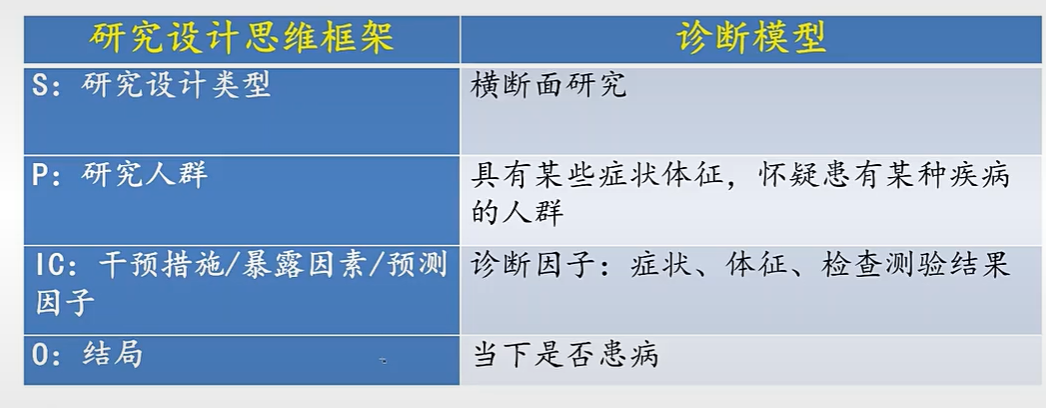
4)预后模型的研究设计
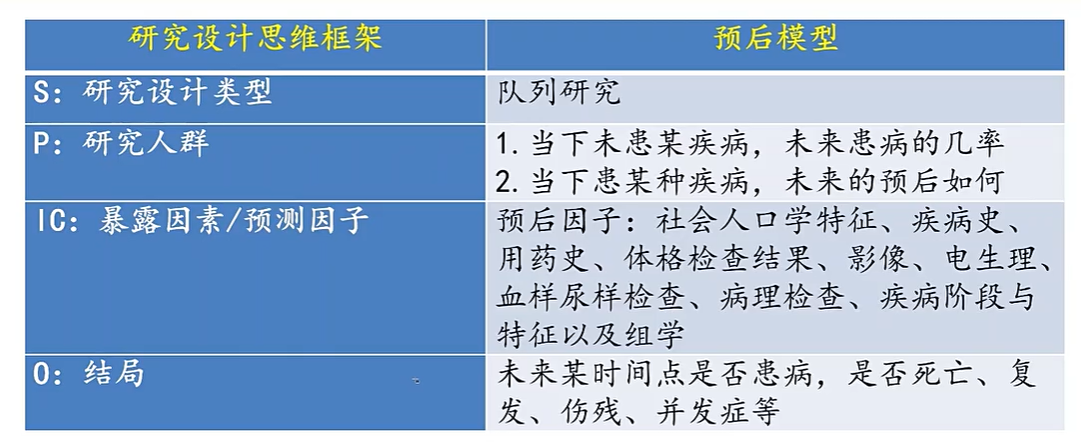
九、预测模型因子的选择
1)医学文献:医学指南最佳、系统综述/综述,预测模型预/测因子。
2)统计方法:单因素、多因素。
3)应用场景:面向大众(推广、简单)。面向医学科研人员、医生(精准)。
十、样本计算量
以二分类结局的研究为例,根据过往经验,通常我们认为每个变量至少需要纳入10个事件,这是已经被广泛接受的默认规则。
但实际上,一些预测分子会产生两个或以上的β项,多个变量间的相互作用也会增加模型参数的数量,所以预测模型其实往往需要更多的参数。
小样本数据的问题
小样本研究缺陷:一、把握度低,容易过拟合,研究的稳定性、可靠性差。二、缺失值对小样本研究的参数估计影响很大。三、通常缺乏有效的验证,尤其是采用拆分数据做验证集。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)