机器学习实践——基于线性回归的波士顿房价预测
·
一.案例简介
通过sklearn中的波士顿房价数据,实现对于数据读取、数据处理、模型训练,从而加强对于线性回归的认识。
二.代码详解
1.导包
# from sklearn.datasets import load_boston # 数据 目前这个数据已经不可使用,更换方式已经给出
from sklearn.preprocessing import StandardScaler # 特征处理
from sklearn.model_selection import train_test_split # 数据集划分
from sklearn.linear_model import LinearRegression # 正规方程的回归模型
from sklearn.linear_model import SGDRegressor # 梯度下降的回归模型
from sklearn.metrics import mean_squared_error, root_mean_squared_error, mean_absolute_error # 均方误差评估
from sklearn.linear_model import Ridge, RidgeCV
import pandas as pd
import numpy as np
2.数据读取
#1.加载波士顿房价数据集
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]]) #hstack()函数的作用:水平拼接数组
target = raw_df.values[1::2, 2]
print(f'特征:{data.shape}')
print(f'标签:{target.shape}')
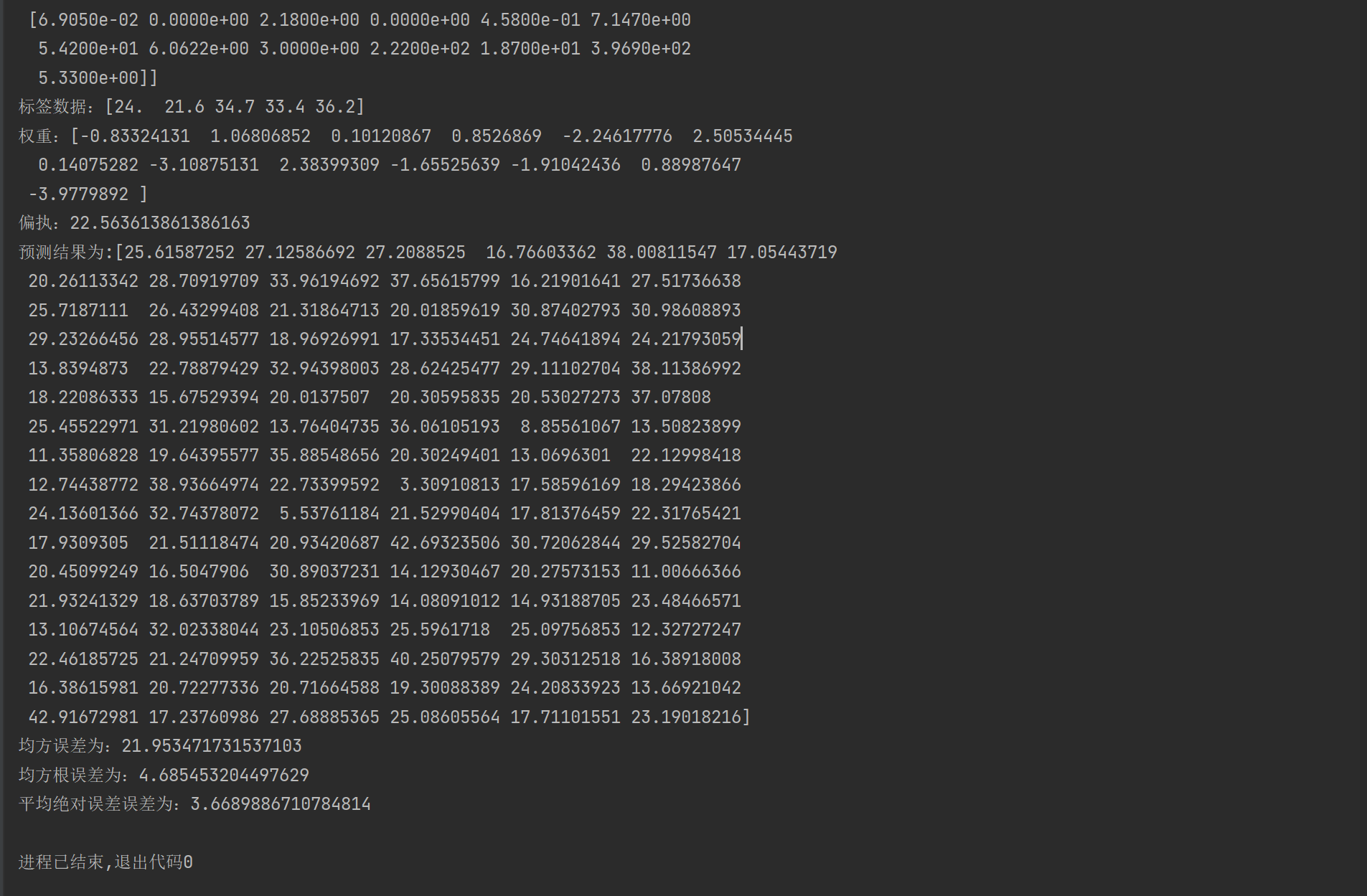
print(f'特征数据:{data[:5]}')
print(f'标签数据:{target[:5]}')
注意:由于一些原因,原sklearn中的数据不可直接使用,但是根据报错提示其他方式获取数据
3.数据预处理
#2.数据的预处理。切分训练集和测试集
#参1:特征数据 参2:标签 参3:测试集和训练集的比例 参4:随机种子
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=23)
#3特征工程
#3.1创建标准化对象
transfer = StandardScaler()
#3.2对数据进行标准化
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)4.模型训练
#4. 模型训练
#4.1创建 线性回归 正规方程 模型对象
estimator = LinearRegression(fit_intercept=True) #fit_intercept:是否需要截距(偏执)默认时True
#4.2 模型选练
estimator.fit(x_train,y_train)
#4.3 打印模型计算出的w 和 b
print(f'权重:{estimator.coef_}')
print(f'偏执:{estimator.intercept_}')
5.模型预测以及评估
#5.模型预测
y_pre = estimator.predict(x_test)
print(f'预测结果为:{y_pre}')
#6.模型评估
#参1:测试集的标签数据 参2:预测结果
print(f'均方误差为:{mean_squared_error(y_test, y_pre)}') #MSE: 均方误差
print(f'均方根误差为:{root_mean_squared_error(y_test, y_pre)}') #RMES
print(f'平均绝对误差误差为:{mean_absolute_error(y_test, y_pre)}') #MAE
6.完整代码
# from sklearn.datasets import load_boston # 数据 目前这个数据已经不可使用,更换方式已经给出
from sklearn.preprocessing import StandardScaler # 特征处理
from sklearn.model_selection import train_test_split # 数据集划分
from sklearn.linear_model import LinearRegression # 正规方程的回归模型
from sklearn.linear_model import SGDRegressor # 梯度下降的回归模型
from sklearn.metrics import mean_squared_error, root_mean_squared_error, mean_absolute_error # 均方误差评估
from sklearn.linear_model import Ridge, RidgeCV
import pandas as pd
import numpy as np
#1.加载波士顿房价数据集
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]]) #hstack()函数的作用:水平拼接数组
target = raw_df.values[1::2, 2]
print(f'特征:{data.shape}')
print(f'标签:{target.shape}')
print(f'特征数据:{data[:5]}')
print(f'标签数据:{target[:5]}')
#2.数据的预处理。切分训练集和测试集
#参1:特征数据 参2:标签 参3:测试集和训练集的比例 参4:随机种子
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=23)
#3特征工程
#3.1创建标准化对象
transfer = StandardScaler()
#3.2对数据进行标准化
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
#4. 模型训练
#4.1创建 线性回归 正规方程 模型对象
estimator = LinearRegression(fit_intercept=True) #fit_intercept:是否需要截距(偏执)默认时True
#4.2 模型选练
estimator.fit(x_train,y_train)
#4.3 打印模型计算出的w 和 b
print(f'权重:{estimator.coef_}')
print(f'偏执:{estimator.intercept_}')
#5.模型预测
y_pre = estimator.predict(x_test)
print(f'预测结果为:{y_pre}')
#6.模型评估
#参1:测试集的标签数据 参2:预测结果
print(f'均方误差为:{mean_squared_error(y_test, y_pre)}') #MSE: 均方误差
print(f'均方根误差为:{root_mean_squared_error(y_test, y_pre)}') #RMES
print(f'平均绝对误差误差为:{mean_absolute_error(y_test, y_pre)}') #MAE
最终效果展示
三.总结
通过波士顿房价预测案例,学习了线性回归相关API的调用,加强了对于线性回归的认识

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)