机器学习——聚类评价指标SSE、SC、CH演示案例
·
一.评价指标简介
SSE考虑了簇内因素

SSE越越小越好
SSE+肘部法常用来确定聚类的最佳K值
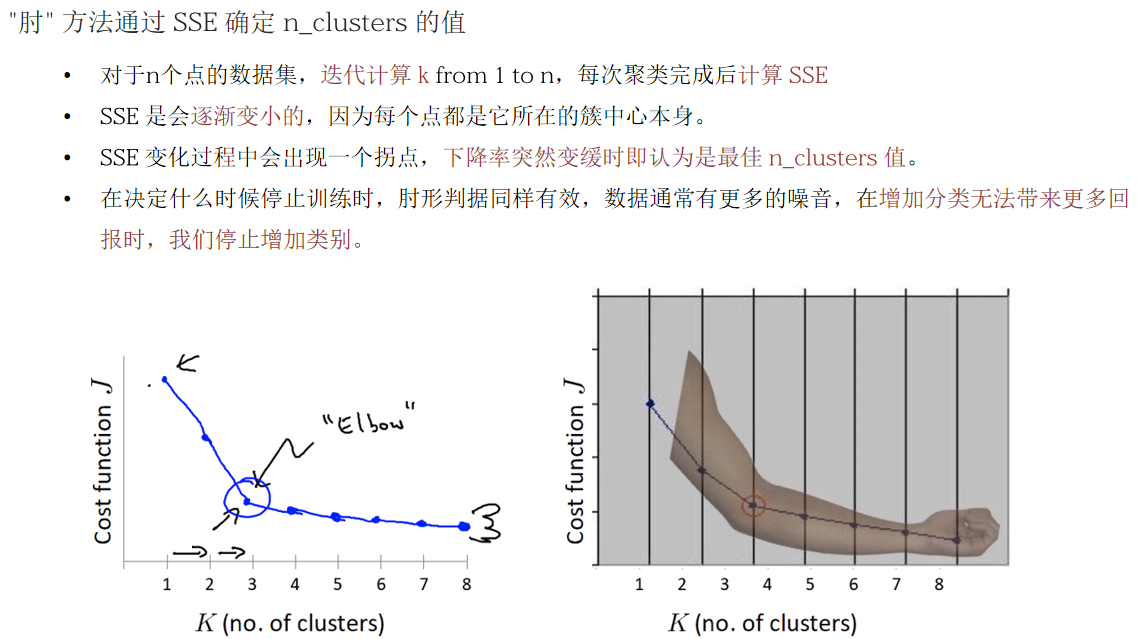
SC轮廓系数法考虑了簇内和簇间因素,数值越大越好

CH考虑簇内,簇间以及K值因素,数值越大越好

二.代码部分详解
1.SSE+肘部法
#1.演示SSE+肘部法
def dm01_SSE():
#1.定义sse列表,记录每个k值的SSE值
sse_list = []
#生成数据 参1:样本数量 参2:特征数 参3:4个簇 参4:标准差 参5:随机种子
x, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=23)
#3.for循环遍历,获取到每个K值,计算对应的sse值,并添加到sse_list 列表中
for k in range(1,100):
#3.1 创建k-means对象,指定K值,迭代次数,随机种子
estimator = KMeans(n_clusters=k, max_iter=100, random_state=23)
#3.2训练模型
estimator.fit(x)
#3.3模型预测
#3.4获取到每个簇的sse值
sse_value = estimator.inertia_
#3.5将每个K值对应的sse,添加到sse_list中
sse_list.append(sse_value)
#绘制SSE曲线-》数据的可视化
#4.1创建画布,指定尺寸
plt.figure(figsize=(20, 10))
#4.2设计标题
plt.title('SSE')
#4.3设置x的 刻度
plt.xticks(range(0, 100, 3) )
#4.4添加x轴, y轴的标签
plt.xlabel('K')
plt.ylabel('SSE')
#4.5绘制网格
plt.grid()
#4.6绘制折线图
#参1:K值 参2:K对应的sse值
plt.plot(range(1, 100), sse_list)
plt.show()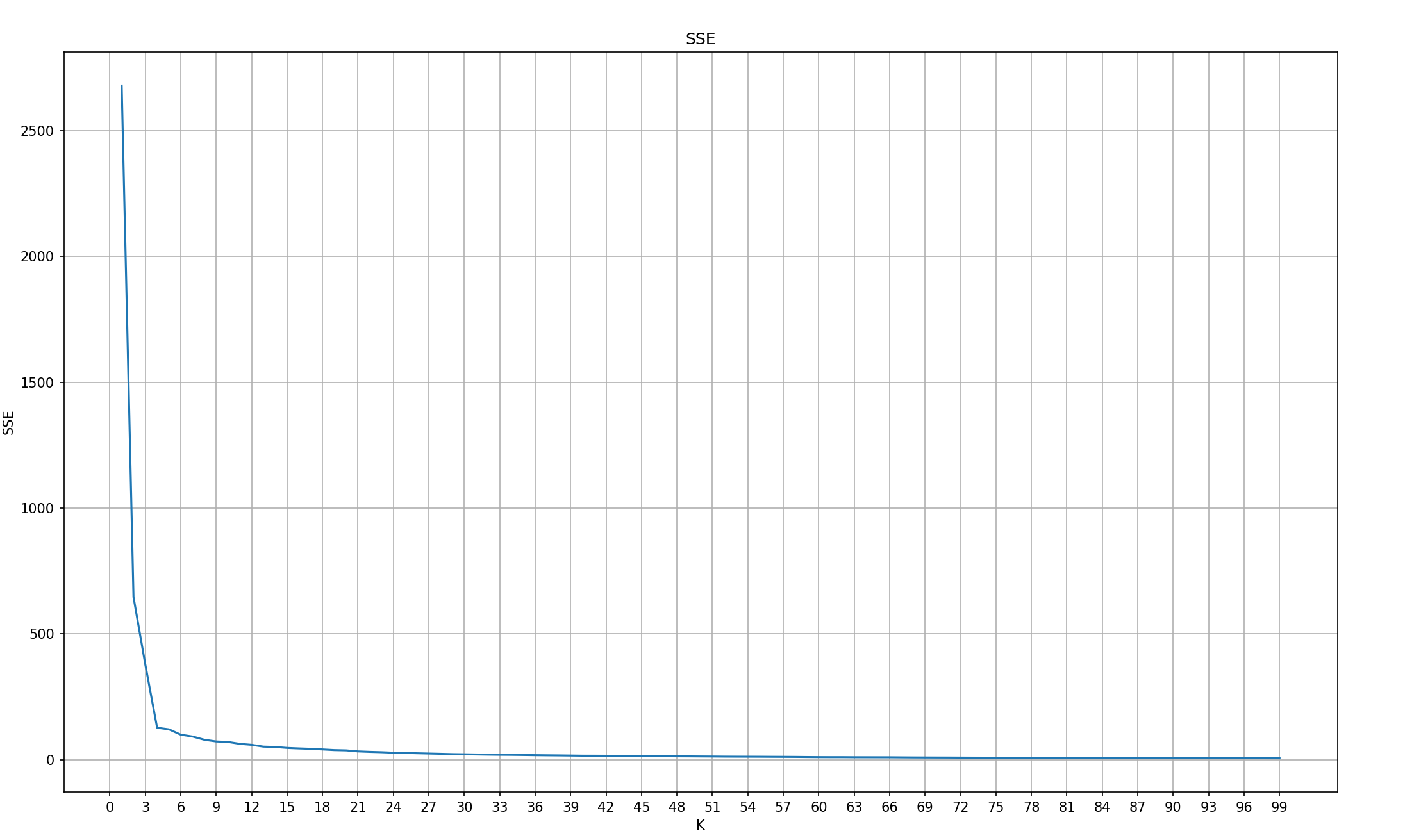
2.SC
#2.演示SC轮廓系数法
def dm02_SC():
#1.定义sc列表,记录每个k值的sc值
sc_list = []
#生成数据 参1:样本数量 参2:特征数 参3:4个簇 参4:标准差 参5:随机种子
x, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=23)
#3.for循环遍历,获取到每个K值,计算对应的sc值,并添加到sc_list 列表中
for k in range(2, 100): #考虑簇外,至少两个簇
#3.1 创建k-means对象,指定K值,迭代次数,随机种子
estimator = KMeans(n_clusters=k, max_iter=100, random_state=23)
#3.2训练模型
estimator.fit(x)
#3.3模型预测
y_pred = estimator.predict(x)
#3.4获取到每个簇的sc值
sc_value = silhouette_score(x, y_pred)
#3.5将每个K值对应的sc,添加到sc_list中
sc_list.append(sc_value)
#绘制sc曲线-》数据的可视化
#4.1创建画布,指定尺寸
plt.figure(figsize=(20, 10))
#4.2设计标题
plt.title('sc')
#4.3设置x的 刻度
plt.xticks(range(0, 100, 3) )
#4.4添加x轴, y轴的标签
plt.xlabel('K')
plt.ylabel('sc')
#4.5绘制网格
plt.grid()
#4.6绘制折线图
#参1:K值 参2:K对应的sc值
plt.plot(range(2, 100), sc_list)
plt.show()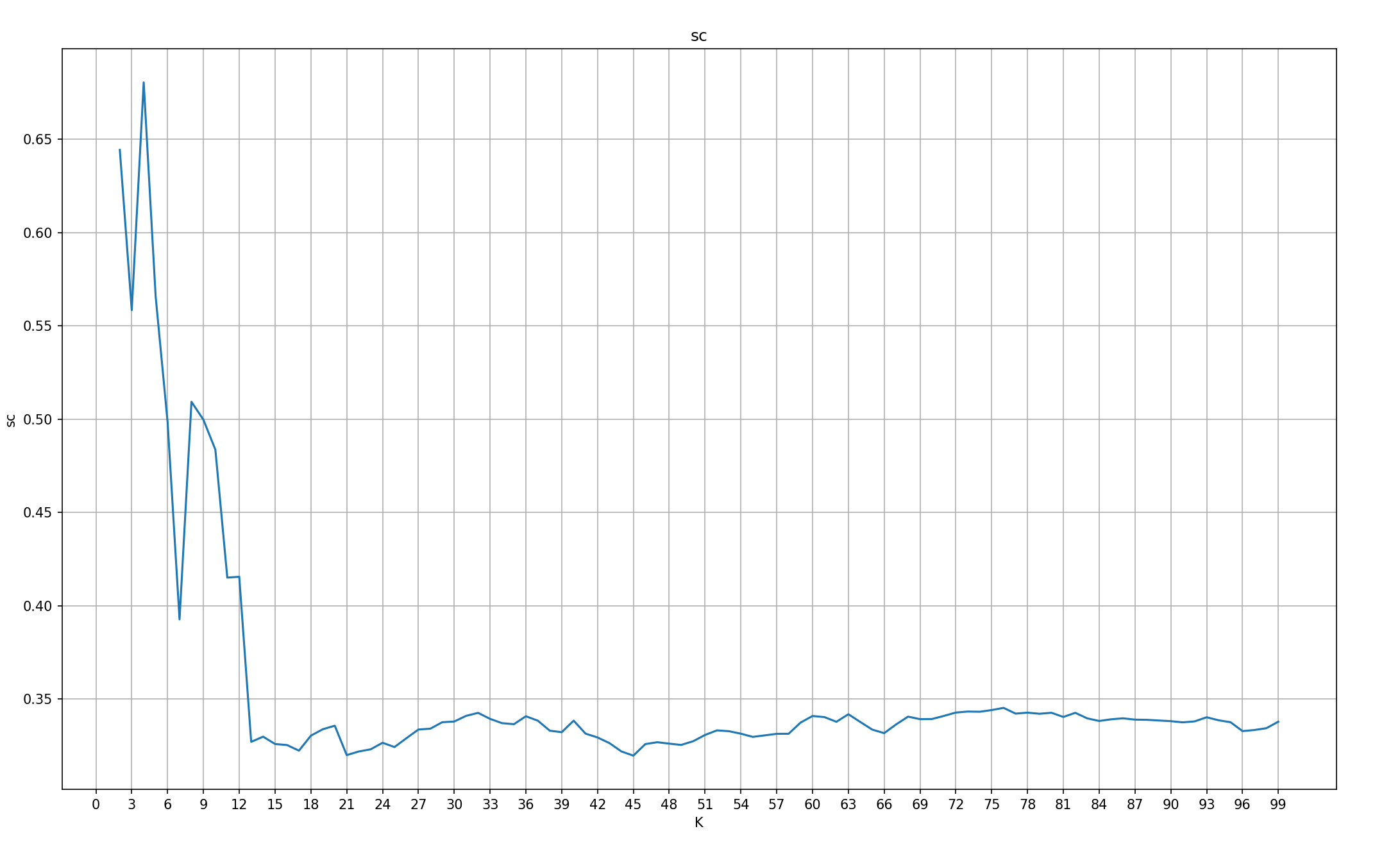
3.CH
#3.演示CH轮廓系数法
def dm03_ch():
#1.定义ch列表,记录每个k值的ch值
ch_list = []
#生成数据 参1:样本数量 参2:特征数 参3:4个簇 参4:标准差 参5:随机种子
x, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=23)
#3.for循环遍历,获取到每个K值,计算对应的ch值,并添加到ch_list 列表中
for k in range(2, 100): #考虑簇外,至少两个簇
#3.1 创建k-means对象,指定K值,迭代次数,随机种子
estimator = KMeans(n_clusters=k, max_iter=100, random_state=23)
#3.2训练模型
estimator.fit(x)
#3.3模型预测
y_pred = estimator.predict(x)
#3.4获取到每个簇的ch值
ch_value = calinski_harabasz_score(x, y_pred)
#3.5将每个K值对应的ch,添加到ch_list中
ch_list.append(ch_value)
#绘制ch曲线-》数据的可视化
#4.1创建画布,指定尺寸
plt.figure(figsize=(20, 10))
#4.2设计标题
plt.title('ch')
#4.3设置x的 刻度
plt.xticks(range(0, 100, 3) )
#4.4添加x轴, y轴的标签
plt.xlabel('K')
plt.ylabel('ch')
#4.5绘制网格
plt.grid()
#4.6绘制折线图
#参1:K值 参2:K对应的ch值
plt.plot(range(2, 100), ch_list)
plt.show()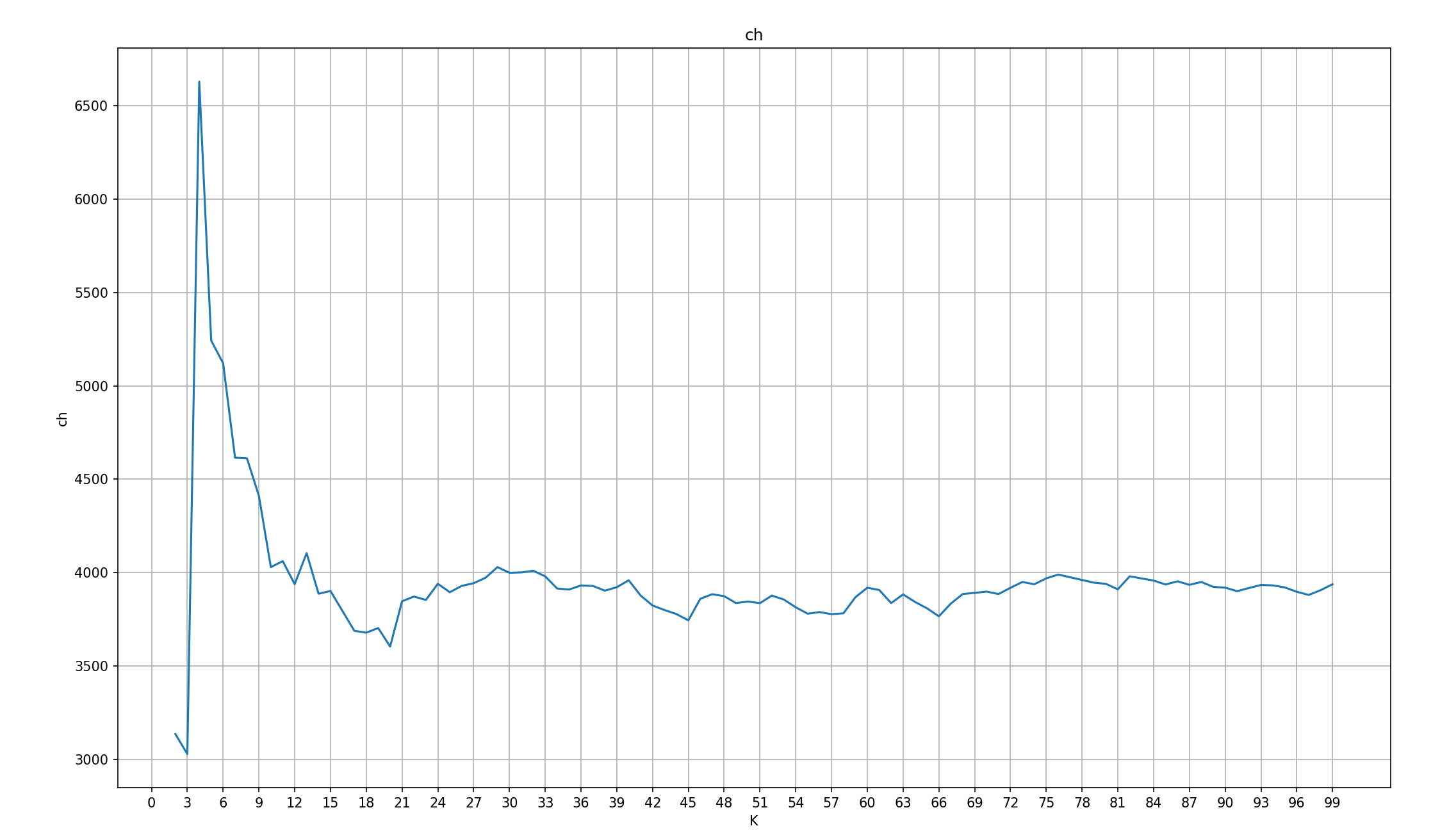
4.完整代码
"""
SSE:只考虑簇内部 值越小越好
SC:考虑了簇内和簇间 值越大越好
CH:考虑了簇内 簇间 以及K值 值越大越好
"""
#导包
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.metrics import calinski_harabasz_score, silhouette_score
import matplotlib
matplotlib.use('TkAgg') # 解决后端错误
#1.演示SSE+肘部法
def dm01_SSE():
#1.定义sse列表,记录每个k值的SSE值
sse_list = []
#生成数据 参1:样本数量 参2:特征数 参3:4个簇 参4:标准差 参5:随机种子
x, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=23)
#3.for循环遍历,获取到每个K值,计算对应的sse值,并添加到sse_list 列表中
for k in range(1,100):
#3.1 创建k-means对象,指定K值,迭代次数,随机种子
estimator = KMeans(n_clusters=k, max_iter=100, random_state=23)
#3.2训练模型
estimator.fit(x)
#3.3模型预测
#3.4获取到每个簇的sse值
sse_value = estimator.inertia_
#3.5将每个K值对应的sse,添加到sse_list中
sse_list.append(sse_value)
#绘制SSE曲线-》数据的可视化
#4.1创建画布,指定尺寸
plt.figure(figsize=(20, 10))
#4.2设计标题
plt.title('SSE')
#4.3设置x的 刻度
plt.xticks(range(0, 100, 3) )
#4.4添加x轴, y轴的标签
plt.xlabel('K')
plt.ylabel('SSE')
#4.5绘制网格
plt.grid()
#4.6绘制折线图
#参1:K值 参2:K对应的sse值
plt.plot(range(1, 100), sse_list)
plt.show()
#2.演示SC轮廓系数法
def dm02_SC():
#1.定义sc列表,记录每个k值的sc值
sc_list = []
#生成数据 参1:样本数量 参2:特征数 参3:4个簇 参4:标准差 参5:随机种子
x, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=23)
#3.for循环遍历,获取到每个K值,计算对应的sc值,并添加到sc_list 列表中
for k in range(2, 100): #考虑簇外,至少两个簇
#3.1 创建k-means对象,指定K值,迭代次数,随机种子
estimator = KMeans(n_clusters=k, max_iter=100, random_state=23)
#3.2训练模型
estimator.fit(x)
#3.3模型预测
y_pred = estimator.predict(x)
#3.4获取到每个簇的sc值
sc_value = silhouette_score(x, y_pred)
#3.5将每个K值对应的sc,添加到sc_list中
sc_list.append(sc_value)
#绘制sc曲线-》数据的可视化
#4.1创建画布,指定尺寸
plt.figure(figsize=(20, 10))
#4.2设计标题
plt.title('sc')
#4.3设置x的 刻度
plt.xticks(range(0, 100, 3) )
#4.4添加x轴, y轴的标签
plt.xlabel('K')
plt.ylabel('sc')
#4.5绘制网格
plt.grid()
#4.6绘制折线图
#参1:K值 参2:K对应的sc值
plt.plot(range(2, 100), sc_list)
plt.show()
#3.演示CH轮廓系数法
def dm03_ch():
#1.定义ch列表,记录每个k值的ch值
ch_list = []
#生成数据 参1:样本数量 参2:特征数 参3:4个簇 参4:标准差 参5:随机种子
x, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=23)
#3.for循环遍历,获取到每个K值,计算对应的ch值,并添加到ch_list 列表中
for k in range(2, 100): #考虑簇外,至少两个簇
#3.1 创建k-means对象,指定K值,迭代次数,随机种子
estimator = KMeans(n_clusters=k, max_iter=100, random_state=23)
#3.2训练模型
estimator.fit(x)
#3.3模型预测
y_pred = estimator.predict(x)
#3.4获取到每个簇的ch值
ch_value = calinski_harabasz_score(x, y_pred)
#3.5将每个K值对应的ch,添加到ch_list中
ch_list.append(ch_value)
#绘制ch曲线-》数据的可视化
#4.1创建画布,指定尺寸
plt.figure(figsize=(20, 10))
#4.2设计标题
plt.title('ch')
#4.3设置x的 刻度
plt.xticks(range(0, 100, 3) )
#4.4添加x轴, y轴的标签
plt.xlabel('K')
plt.ylabel('ch')
#4.5绘制网格
plt.grid()
#4.6绘制折线图
#参1:K值 参2:K对应的ch值
plt.plot(range(2, 100), ch_list)
plt.show()
#4.测试
if __name__ =='__main__':
#dm01_SSE()
#dm02_SC()
dm03_ch()三.总结
加强了对于对于聚类算法评价指标的练习。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)