【Edu】机器学习——逻辑回归
目录
第1关:逻辑回归核心——sigmoid函数
任务描述
本关任务:根据本节课所学知识完成本关所设置的编程题。
相关知识
为了完成本关任务,你需要掌握:
-
什么是逻辑回归;
-
sigmoid函数。
什么是逻辑回归
当一看到“回归”这两个字,可能会认为逻辑回归是一种解决回归问题的算法,然而逻辑回归是通过回归的思想来解决二分类问题的算法。
那么问题来了,回归的算法怎样解决分类问题呢?其实很简单,逻辑回归是将样本特征和样本所属类别的概率联系在一起,假设现在已经训练好了一个逻辑回归的模型为 f(x) ,模型的输出是样本 x 的标签是 1 的概率,则该模型可以表示, z=f(x) 。若得到了样本 x 属于标签 1 的概率后,很自然的就能想到当 z>0.5 时 x 属于标签 1 ,否则属于标签 0 。所以就有
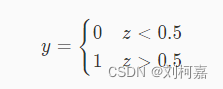
(其中 y 为样本 x 根据模型预测出的标签结果,标签 0 和标签 1 所代表的含义是根据业务决定的,比如在癌细胞识别中可以使 0 代表良性肿瘤, 1 代表恶性肿瘤)。
由于概率是 0 到 1 的实数,所以逻辑回归若只需要计算出样本所属标签的概率就是一种回归算法,若需要计算出样本所属标签,则就是一种二分类算法。
那么逻辑回归中样本所属标签的概率怎样计算呢?其实和线性回归有关系,学习了线性回归的同学肯定知道线性回归无非就是训练出一组参数 w 和 b 来拟合样本数据,线性回归的输出为 z=xTw+b 。不过 z 的值域是 (−∞,+∞) ,如果能够将值域为 (−∞,+∞) 的实数转换成 (0,1) 的概率值的话问题就解决了。要解决这个问题很自然地就能想到将线性回归的输出作为输入,输入到另一个函数中,这个函数能够进行转换工作,假设函数为 σ ,转换后的概率为 y ,则逻辑回归在预测时可以看成y=σ(xTw+b) 。 σ 其实就是接下来要介绍的sigmoid函数。
sigmoid 函数
sigmoid函数的公式为:
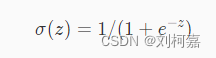
函数图像如下图所示:
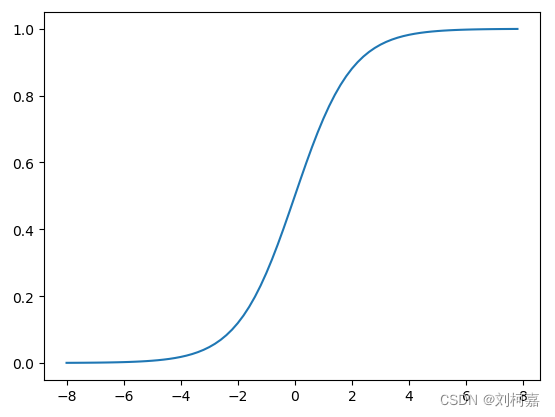
从sigmoid函数的图像可以看出当 z 趋近于 −∞ 时函数值趋近于 0 ,当 z 趋近于 +∞ 时函数值趋近于 1 。可见sigmoid函数的值域是 (0,1) ,满足我们要将 (−∞,+∞) 的实数转换成 (0,1) 的概率值的需求。因此逻辑回归在预测时可以看成
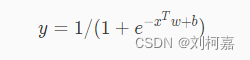
编程要求
根据提示,在右侧编辑器补充 Python 代码,实现sigmoid函数。底层代码会调用您实现的sigmoid函数来进行测试。(提示: numpy.exp()函数可以实现 e 的幂运算)
测试说明
测试用例:
输入:1
预期输出:0.731059
输入:-2
预期输出:0.119203
我的代码
#encoding=utf8
import numpy as np
def sigmoid(z):
'''
完成sigmoid函数计算
:param z: 负无穷到正无穷的实数
:return: 转换后的概率值
:可以考虑使用np.exp()函数
'''
#********** Begin **********#
return 1/(1+np.exp(-z))
#********** End **********#第2关:梯度下降
本关任务:用 Python 构建梯度下降算法,并求取目标函数最小值。
相关知识
为了完成本关任务,你需要掌握:梯度下降算法。
什么是梯度
梯度:梯度的本意是一个向量,由函数对每个参数的偏导组成,表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向变化最快,变化率最大。
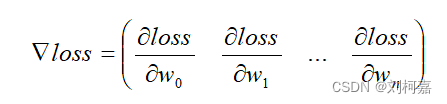
梯度下降算法原理
算法思想:梯度下降是一种非常通用的优化算法,能够为大范围的问题找到最优解。梯度下降的中心思想就是迭代地调整参数从而使损失函数最小化。假设你迷失在山上的迷雾中,你能感觉到的只有你脚下路面的坡度。快速到达山脚的一个策略就是沿着最陡的方向下坡。这就是梯度下降的做法:通过测量参数向量 θ 相关的损失函数的局部梯度,并不断沿着降低梯度的方向调整,直到梯度降为 0 ,达到最小值。
梯度下降公式如下:
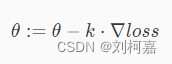
对应到每个权重公式为:
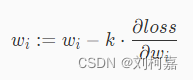
其中 k 为学习率,是 0 到 1 之间的值,是个超参数,需要我们自己来确定大小。
有时候,∇loss可以由与θ相关的函数计算出来,因此也可以将∇loss表示成∇(θ)
算法原理: 在传统机器学习中,损失函数通常为凸函数,假设此时只有一个参数,则损失函数对参数的梯度即损失函数对参数的导数。如果刚开始参数初始在最优解的左边
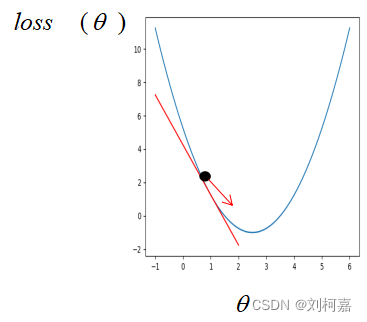
很明显,这个时候损失函数对参数的导数是小于 0 的,而学习率是一个 0 到 1 之间的数,此时按照公式更新参数,初始的参数减去一个小于 0 的数是变大,也就是在坐标轴上往右走,即朝着最优解的方向走。同样的,如果参数初始在最优解的右边,
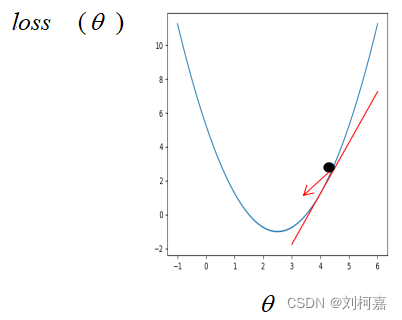
此时按照公式更新,参数将会朝左走,即最优解的方向。所以,不管刚开始参数初始在何位置,按着梯度下降公式不断更新,参数都会朝着最优解的方向走。
梯度下降算法流程
- 随机初始参数 θ;
- 确定学习率 k;
- 由∇(θ)计算出损失函数对参数梯度;
- 按照公式更新参数;
- 重复 3 、 4 直到满足终止条件(如:损失函数或参数更新变化值小于10−8,或者训练次数达到1000次)。
编程要求
根据提示,使用 Python 实现梯度下降算法,计算迭代1000次后对应的参数theta,并返回theta。外部代码会判断theta是否正确。
其中,初始θ、学习率k、∇(θ)函数,都已经通过参数结出,参数名分别为initial_theta、k、nabla_function。
提示:参数nabla_function指向了一个函数,使用nabla_function(theta)即可调用这个函数并将参数theta传递过去,并返回结果∇loss。
测试样例
当initial_theta = 10、k = 0.1、∇(θ)=2∗(θ−3)时,迭代结果为theta = 3
我的代码
# -*- coding: utf-8 -*-
import numpy as np
import warnings
warnings.filterwarnings("ignore")
def gradient_descent(initial_theta, k, nabla_function):
'''
梯度下降
:param initial_theta: 参数初始值,类型为numpy数组
:param k: 学习率,类型为float
:param nabla_function: 损失函数对参数的梯度函数
:return: 训练后得到的theta
'''
#********** Begin *********#
theta = initial_theta
for i in range(1001):#迭代1000次
grad = nabla_function(theta)
if(abs(grad).any()<1e-8):#损失函数或参数更新变化值小于10^−8
break
theta = theta - k*grad
return theta
#********** End **********#
第3关:动手实现逻辑回归 - 癌细胞精准识别
任务描述
本关任务:使用逻辑回归算法建立一个模型,并通过梯度下降算法进行训练,得到一个能够准确对癌细胞进行识别的模型。
相关知识
为了完成本关任务,你需要掌握:
- 逻辑回归算法流程;
- 逻辑回归中的梯度下降。
数据集介绍
乳腺癌数据集,其实例数量是 569 ,实例中包括诊断类和属性,帮助预测的属性一共 30 个,各属性包括为 radius 半径(从中心到边缘上点的距离的平均值), texture 纹理(灰度值的标准偏差)等等,类包括: WDBC-Malignant 恶性和 WDBC-Benign 良性。用数据集的 80% 作为训练集,数据集的 20% 作为测试集,训练集和测试集中都包括特征和类别。其中特征和类别均为数值类型,类别中 0 代表良性, 1 代表恶性。
构建逻辑回归模型
由数据集可以知道,每一个样本有 30 个特征和 1 个标签,而我们要做的事就是通过这 30 个特征来分析细胞是良性还是恶性(其中标签 y=0 表示是良性, y=1 表示是恶性)。逻辑回归算法正好是一个二分类模型,我们可以构建一个逻辑回归模型,来对癌细胞进行识别。模型如下:
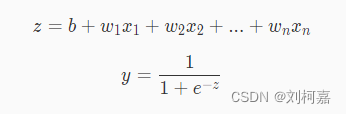
其中 xi表示第 i 个特征,wi表示第 i 个特征对应的权重,b表示偏置。 为了方便,我们稍微将模型进行变换:
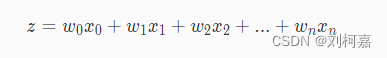
其中等于 1 。
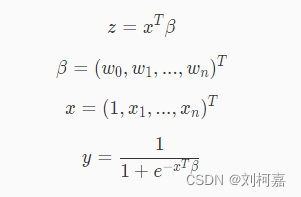
我们将一个样本输入模型,如果预测值大于等于 0.5 则判定为 1 类别,如果小于 0.5 则判定为 0 类别。
训练逻辑回归模型
我们已经知道如何构建一个逻辑回归模型,但是如何得到一个能正确对癌细胞进行识别的模型呢?通常,我们先将数据输入到模型,从而得到一个预测值,再将预测值与真实值结合,得到一个损失函数,最后用梯度下降的方法来优化损失函数,从而不断的更新模型的参数 β ,最后得到一个能够正确对良性细胞和癌细胞进行分类的模型。
在上一节中,我们知道要使用梯度下降算法首先要知道损失函数对参数的梯度,即损失函数对每个参数的偏导。 此处我们略过推导过程,直接给出在逻辑回归中的梯度下降公式如下:

训练流程:
同梯度下降算法流程:请参见上一关卡。
编程要求
根据提示,在右侧编辑器fit函数的Begin-End处补充 Python 代码,构建一个逻辑回归模型,并对其进行训练,最后将得到的逻辑回归模型对癌细胞进行识别。
其中,参数X指向了用于训练的特征数据,它由多条记录组成,而且每条记录前面已经补充了x0项,也就是1;参数Y指向了标签数据,它的数量与X的行数一致。
请自行选择β的初始值和学习率k,自行决定循环次数和/或训练停止条件。
提示:想知道β有多少个数据,看X有多少列就知道了。
.
测试说明
只需返回预测结果即可,程序内部会检测您的代码,预测正确率高于 95% 视为过关。
我的代码
# -*- coding: utf-8 -*-
import numpy as np
import warnings
warnings.filterwarnings("ignore")
def fit(X, Y):
'''
训练逻辑回归模型
:param X: 训练集特征数据,类型为ndarray
:param Y: 训练集标签,类型为ndarray
:return: 模型参数,类型为ndarray
'''
# 请在此添加实现代码 #
#********** Begin *********#
beta = np.ones(X.shape[1]) # 初始beta
k = 0.1
for i in range(1001):
y_hat = 1 / (1 + np.exp(- X.dot(beta)))
d = X.T.dot(y_hat - Y)
beta = beta - k*d
return beta
#********** End **********#
第4关:手写数字识别
任务描述
本关任务:使用sklearn中的LogisticRegression类完成手写数字识别任务。
相关知识
为了完成本关任务,你需要掌握如何使用sklearn提供的LogisticRegression类。
数据简介
本关使用的是手写数字数据集,该数据集有 1797 个样本,每个样本包括 8*8 像素(实际上是一条样本有 64 个特征,每个像素看成是一个特征,每个特征都是float类型的数值)的图像和一个 [0, 9] 整数的标签。比如下图的标签是 0 :
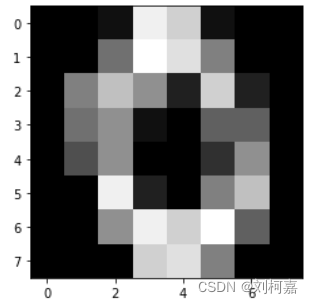
sklearn为该数据集提供了接口,若想使用该数据集,代码如下:
from sklearn import datasets
import matplotlib.pyplot as plt
#加载数据集
digits = datasets.load_digits()
#X表示图像数据,y表示标签
X = digits.data
y = digits.target
#将第49张手写数字可视化
plt.imshow(digits.images[49], cmap='gray')LogisticRegression
这个问题是个多分类问题,幸好sklearn中提供的LogisticRegression可以实现多分类。LogisticRegression的构造函数中有三个常用的参数可以设置:
-
solver:{'newton-cg' , 'lbfgs', 'liblinear', 'sag', 'saga'}, 分别为几种优化算法。默认为liblinear; -
C:正则化系数的倒数,默认为 1.0 ,越小代表正则化越强; -
max_iter:最大训练轮数,默认为 100 。
和sklearn中其他分类器一样,LogisticRegression类中的fit函数用于训练模型,fit函数有两个向量输入:
-
X:大小为 [样本数量,特征数量] 的ndarray,存放训练样本; -
Y:值为整型,大小为 [样本数量] 的ndarray,存放训练样本的分类标签。
LogisticRegression类中的predict函数用于预测,返回预测标签,predict函数有一个向量输入:
X:大小为[样本数量,特征数量]的ndarray,存放预测样本。
LogisticRegression的使用代码如下:
model = LogisticRegression(solver='lbfgs', max_iter=10, C=10)
model.fit(X_train, Y_train)
result = model.predict(X_test)编程要求
填写digit_predict(train_image, train_label, test_image)函数完成手写数字识别任务,其中:
-
train_image:训练集图像,相当于X_train,类型为ndarray,shape=[-1, 8, 8]; -
train_label:训练集标签,相当于Y_train,类型为ndarray; -
test_image:测试集图像,相当于X_test,类型为ndarray。
测试说明
只需返回预测结果即可,程序内部会检测您的代码,预测正确率高于 0.97 视为过关。
我的代码
版权声明:本文为CSDN博主「小段学长」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_45962068/article/details/117964907from sklearn.linear_model import LogisticRegression def digit_predict(train_image, train_label, test_image): ''' 实现功能:训练模型并输出预测结果 :param train_sample: 包含多条训练样本的样本集,类型为ndarray,shape为[-1, 8, 8] :param train_label: 包含多条训练样本标签的标签集,类型为ndarray :param test_sample: 包含多条测试样本的测试集,类型为ndarry :return: test_sample对应的预测标签 ''' #************* Begin ************# # 训练集变形 flat_train_image = train_image.reshape((-1, 64)) # 训练集标准化 train_min = flat_train_image.min() train_max = flat_train_image.max() flat_train_image = (flat_train_image-train_min)/(train_max-train_min) # 测试集变形 flat_test_image = test_image.reshape((-1, 64)) # 测试集标准化 test_min = flat_test_image.min() test_max = flat_test_image.max() flat_test_image = (flat_test_image - test_min) / (test_max - test_min) # 训练--预测 rf = LogisticRegression(C=4.0) rf.fit(flat_train_image, train_label) return rf.predict(flat_test_image) #************* End **************#

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)