【完整源码+数据集+部署教程】 手掌区域姿势图像分割系统源码&数据集分享 [yolov8-seg-C2f-ODConv&yolov8-seg-fasternet等50+全套改进创新点发刊_一键训练教
背景意义
随着计算机视觉技术的迅猛发展,图像分割在各个领域的应用日益广泛,尤其是在手势识别、虚拟现实和人机交互等领域。手掌区域的姿势图像分割作为图像分割中的一个重要分支,具有重要的研究价值和应用前景。手掌的姿势不仅是人类与计算机交互的重要方式,也是表达情感和意图的关键手段。因此,开发高效、准确的手掌区域姿势图像分割系统,对于提升人机交互的自然性和智能化水平具有重要意义。
在众多图像分割算法中,YOLO(You Only Look Once)系列模型因其实时性和高效性而备受关注。YOLOv8作为该系列的最新版本,结合了深度学习的先进技术,能够在保证精度的同时,实现快速的图像处理。然而,传统的YOLOv8模型在处理复杂的手掌姿势时,仍然面临一些挑战,如对手掌区域的细节捕捉不足、对不同姿势的适应性差等。因此,基于改进YOLOv8的手掌区域姿势图像分割系统的研究,旨在通过对模型结构和算法的优化,提高手掌姿势的分割精度和鲁棒性。
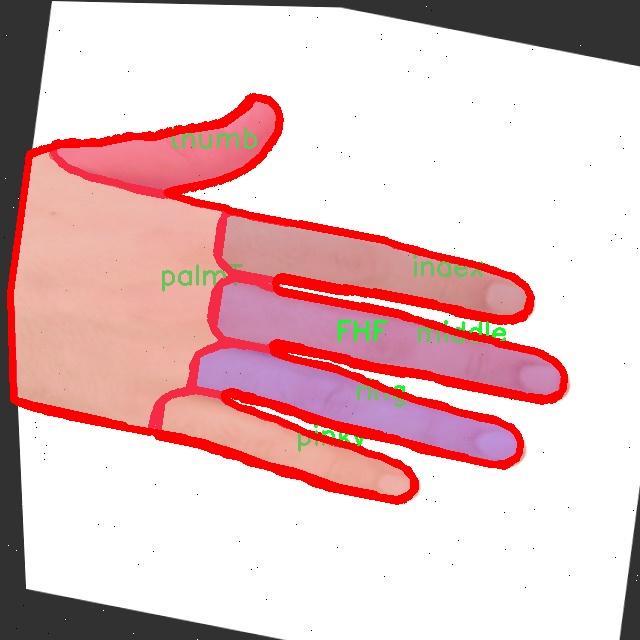
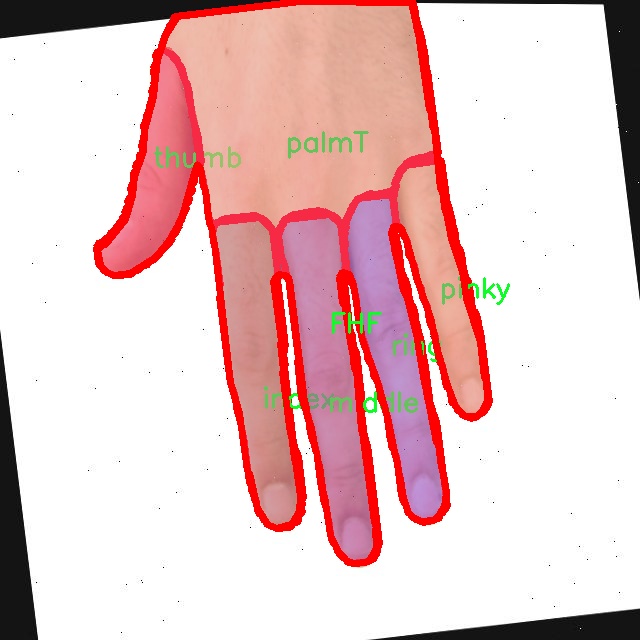
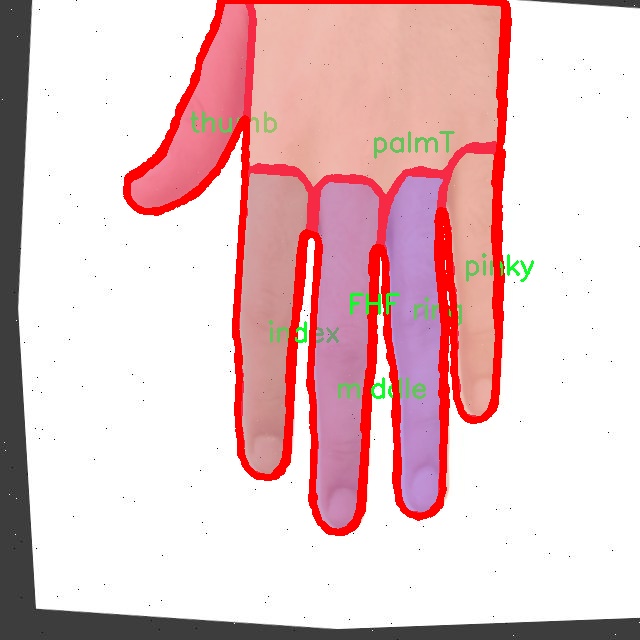
本研究将使用一个包含2000张图像的数据集,涵盖10个不同的手掌姿势类别,包括FHB、FHF、index、jewel、middle、palmB、palmT、pinky、ring和thumb。这些类别的多样性为模型的训练提供了丰富的样本,有助于提升模型对各种手势的识别能力。通过对这些图像进行标注和分析,研究者可以深入理解手掌姿势的特征及其在不同场景下的表现,从而为改进YOLOv8提供数据支持。
此外,手掌区域的姿势图像分割系统不仅在学术研究中具有重要意义,也在实际应用中展现出广泛的前景。例如,在虚拟现实和增强现实中,用户的手势可以直接影响虚拟环境的交互体验;在医疗领域,手势识别技术可以辅助医生进行远程手术;在智能家居中,手势控制能够提升用户的操作便捷性。因此,基于改进YOLOv8的手掌区域姿势图像分割系统的研究,能够推动相关技术的发展,并为各行各业的智能化进程提供有力支持。
综上所述,基于改进YOLOv8的手掌区域姿势图像分割系统的研究,不仅有助于提升图像分割技术的精度和效率,也为手势识别的实际应用提供了新的思路和方法。通过对手掌姿势的深入研究,我们能够更好地理解人机交互的本质,推动智能技术的进一步发展。
图片效果
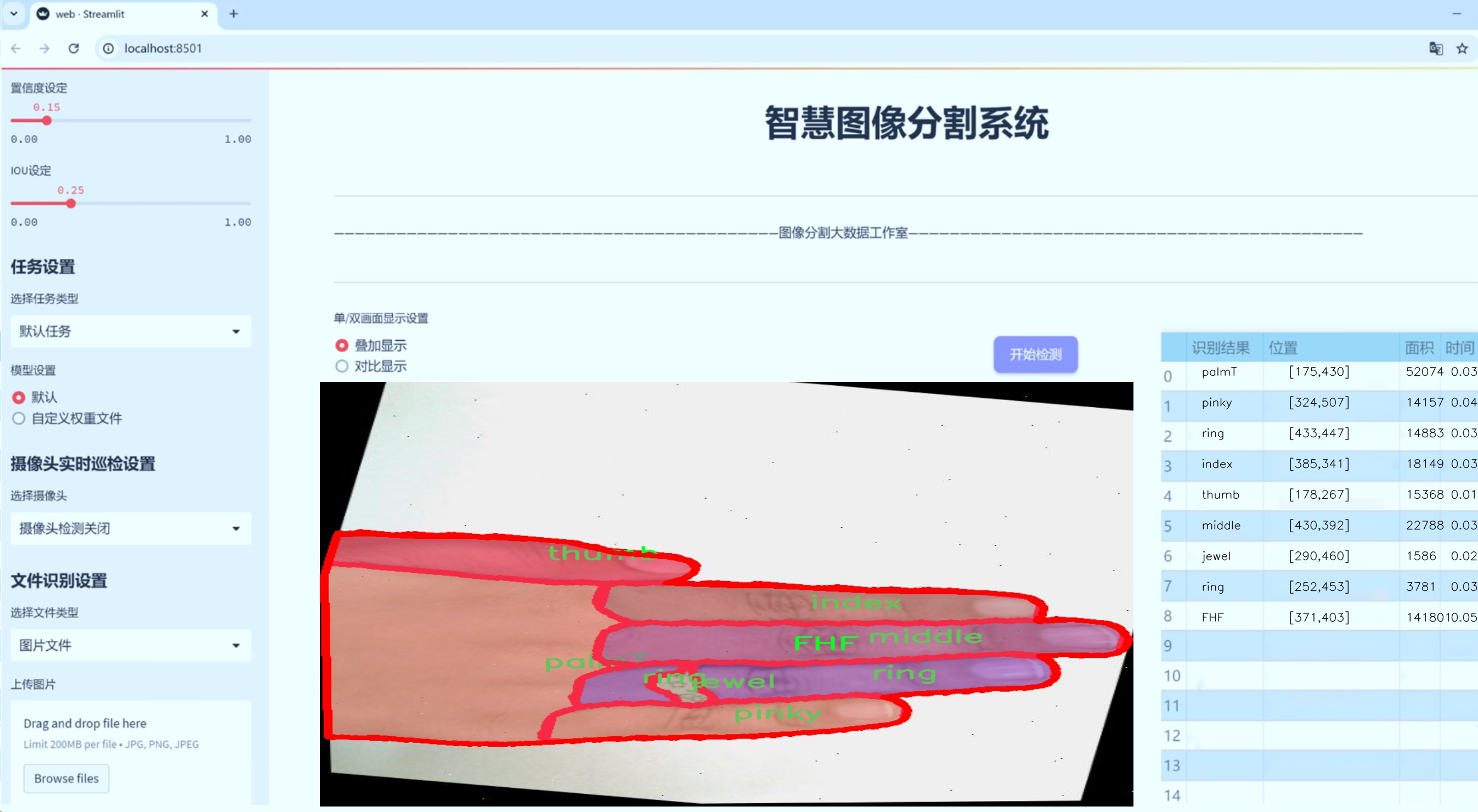
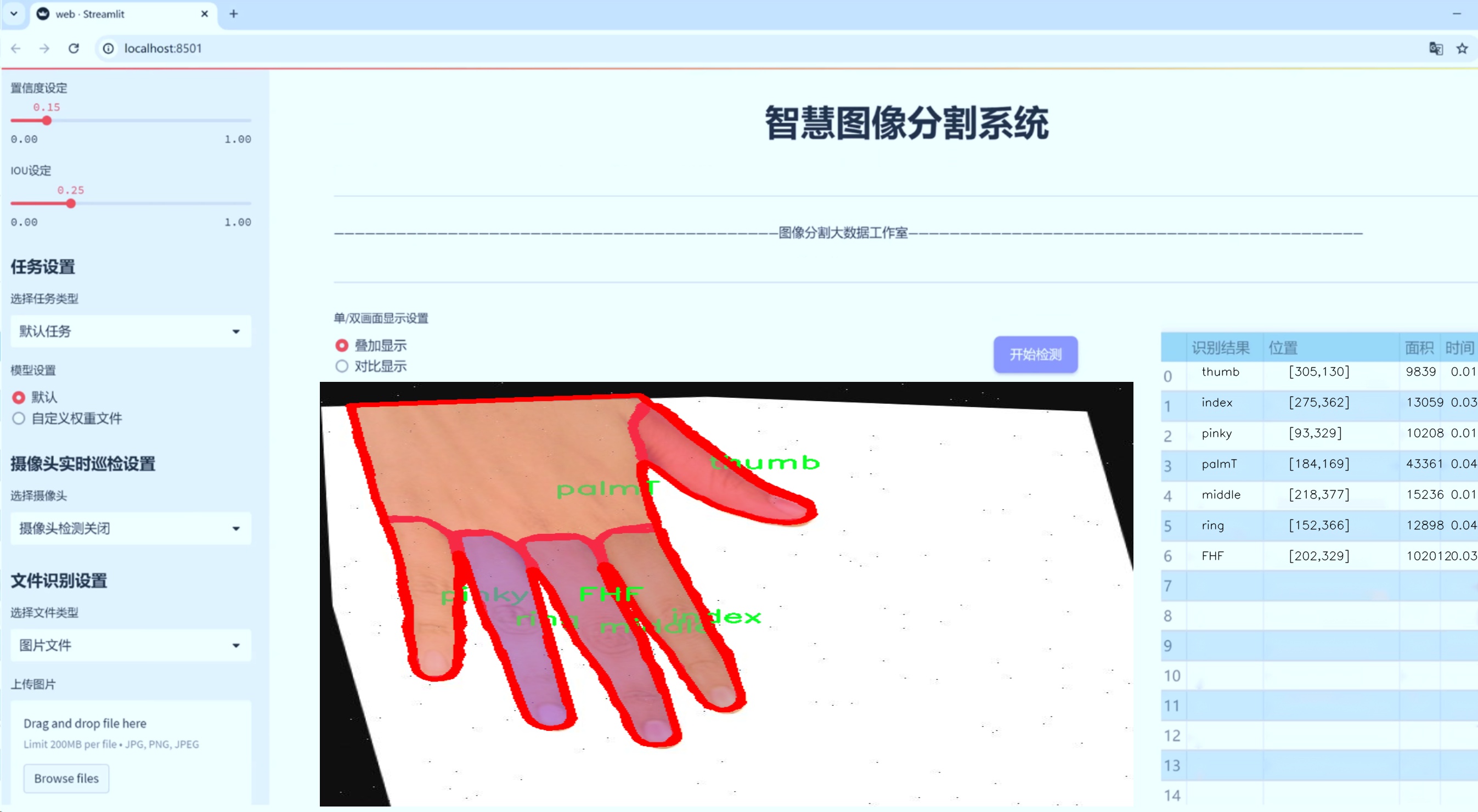
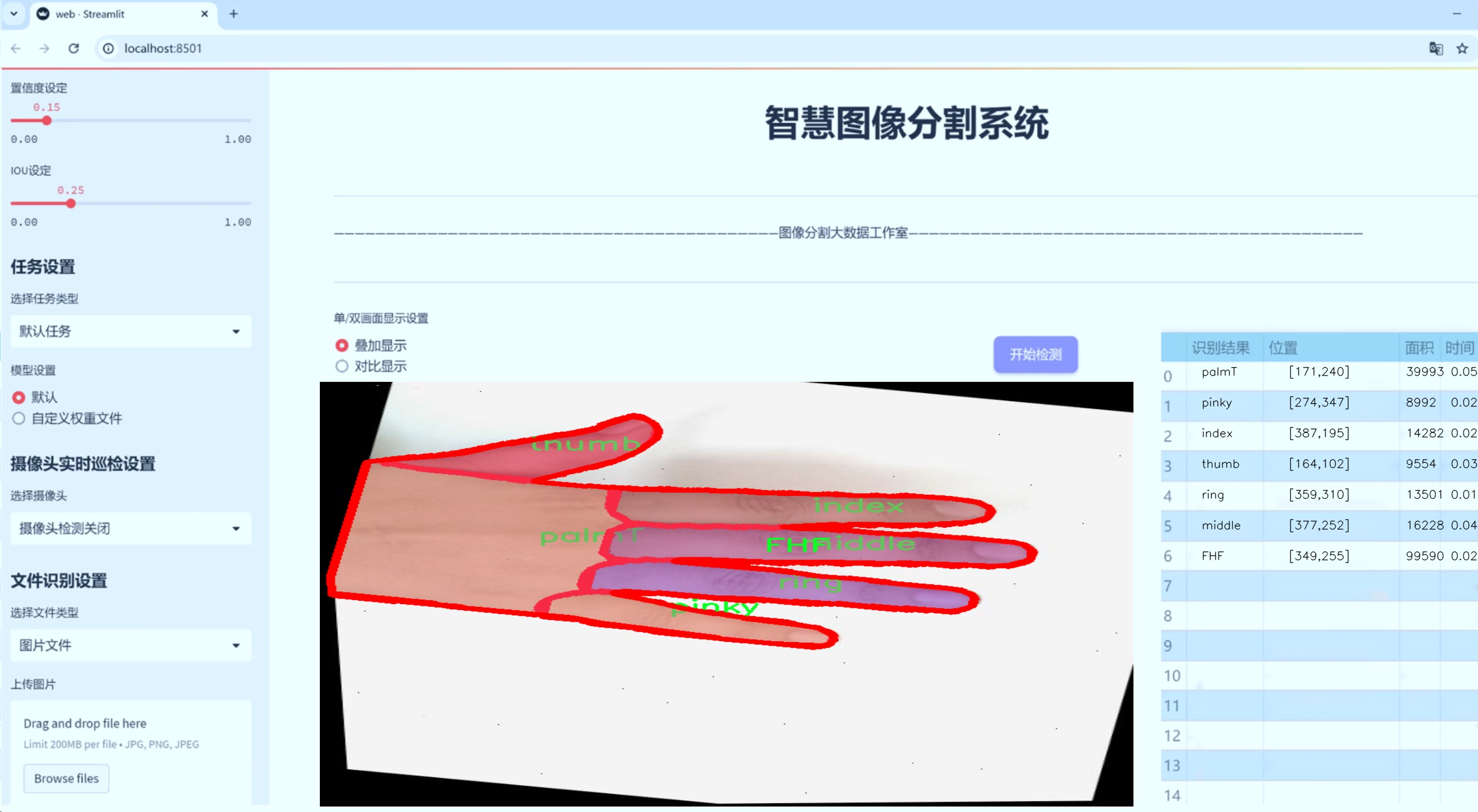
数据集信息
在现代计算机视觉领域,手掌区域姿势识别与图像分割技术的进步为人机交互、虚拟现实以及增强现实等应用提供了强有力的支持。为此,构建一个高质量的训练数据集显得尤为重要。本研究所采用的数据集名为“irt”,专门用于训练和改进YOLOv8-seg模型,以实现对手掌区域的精准图像分割。该数据集的设计旨在涵盖手掌的多种姿势和状态,以便为模型提供丰富的训练样本,从而提升其在实际应用中的表现。
“irt”数据集包含10个类别,具体类别包括:FHB(手掌前部)、FHF(手掌后部)、index(食指)、jewel(中指)、middle(无名指)、palmB(手掌底部)、palmT(手掌顶部)、pinky(小指)、ring(戒指指)、thumb(拇指)。这些类别的设置不仅反映了手掌的解剖结构,还考虑到了不同手势在交互中的重要性。例如,食指和拇指的动作常常用于指向和抓取,而中指和无名指则在手势表达中扮演着重要角色。通过对这些类别的细致划分,数据集能够为模型提供多样化的手势样本,进而提升其在复杂场景下的识别能力。
在数据集的构建过程中,确保每个类别样本的多样性和代表性是至关重要的。为此,数据集中的图像涵盖了不同的光照条件、背景环境以及手掌的各种姿势。这种多样性不仅有助于模型学习到手掌的不同特征,还能增强其对环境变化的适应能力。此外,数据集中的每个图像都经过精确的标注,确保模型在训练过程中能够获得准确的目标信息。这种高质量的标注是实现高效图像分割的基础。
在实际应用中,YOLOv8-seg模型将利用“irt”数据集进行训练,以提高其对手掌区域的分割精度。通过引入深度学习技术,模型能够自动提取手掌的特征,并对不同类别进行有效区分。尤其是在复杂的手势识别任务中,模型的实时性和准确性将直接影响用户体验。因此,数据集的构建不仅是技术实现的基础,更是提升系统性能的关键环节。
综上所述,“irt”数据集为手掌区域姿势图像分割系统的训练提供了坚实的基础。通过对手掌不同部分的细致划分和丰富的样本设计,该数据集能够有效支持YOLOv8-seg模型的训练与优化。未来,随着数据集的不断扩展和优化,预计将进一步推动手掌区域姿势识别技术的发展,为人机交互和智能系统的应用开辟新的可能性。
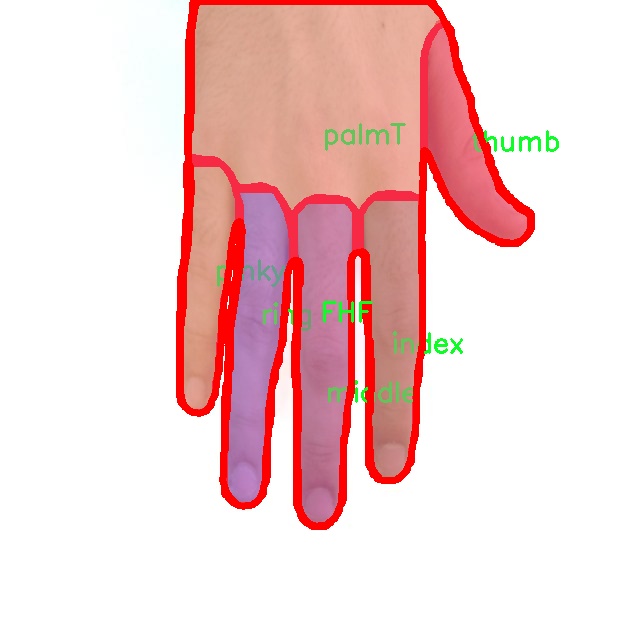
核心代码
```python
# 导入必要的库
import torch
from ultralytics.utils import ops
class NASValidator:
"""
Ultralytics YOLO NAS 验证器,用于目标检测。
该类用于后处理由 YOLO NAS 模型生成的原始预测结果。它执行非最大抑制(NMS),以去除重叠和低置信度的框,
最终生成最终的检测结果。
"""
def __init__(self, args):
"""
初始化 NASValidator。
参数:
args (Namespace): 包含后处理的各种配置,例如置信度和 IoU 阈值。
"""
self.args = args # 存储配置参数
def postprocess(self, preds_in):
"""对预测输出应用非最大抑制(NMS)。"""
# 将预测框从 xyxy 格式转换为 xywh 格式
boxes = ops.xyxy2xywh(preds_in[0][0])
# 将框和置信度合并,并调整维度
preds = torch.cat((boxes, preds_in[0][1]), -1).permute(0, 2, 1)
# 应用非最大抑制,去除重叠的框
return ops.non_max_suppression(
preds,
self.args.conf, # 置信度阈值
self.args.iou, # IoU 阈值
multi_label=False, # 是否使用多标签 NMS
agnostic=self.args.single_cls, # 是否单类 NMS
max_det=self.args.max_det, # 最大检测框数量
max_time_img=0.5 # 每张图像的最大处理时间
)
代码注释说明:
- 导入库:导入了
torch和ultralytics.utils.ops,后者包含了用于处理预测框的操作。 - 类定义:
NASValidator类用于处理 YOLO NAS 模型的预测结果。 - 初始化方法:构造函数接收配置参数
args,用于设置后处理的各种阈值。 - postprocess 方法:
- 框格式转换:将预测框从
(x1, y1, x2, y2)格式转换为(x_center, y_center, width, height)格式。 - 合并框和置信度:将框和对应的置信度合并为一个张量,并调整维度以适应后续处理。
- 非最大抑制:调用
non_max_suppression函数,去除重叠和低置信度的框,返回最终的检测结果。```
这个文件ultralytics\models\nas\val.py是 Ultralytics YOLO(You Only Look Once)模型的一部分,专门用于对象检测的验证过程。它主要定义了一个名为NASValidator的类,该类继承自DetectionValidator,并且专注于处理 YOLO NAS 模型生成的原始预测结果。
- 框格式转换:将预测框从
在这个类中,主要的功能是对检测结果进行后处理,具体来说就是执行非极大值抑制(Non-Maximum Suppression, NMS)。NMS 是一种常用的技术,用于去除重叠的低置信度框,从而最终得到更准确的检测结果。该类包含了一些属性,例如 args,它是一个命名空间,包含了用于后处理的各种配置参数,比如置信度阈值和交并比(IoU)阈值。此外,还有一个可选的张量 lb,用于多标签 NMS。
在使用示例中,首先导入了 NAS 类,然后实例化了一个 YOLO NAS 模型。接着,通过模型的 validator 属性获取到 NASValidator 的实例,并假设已经获得了原始预测结果 raw_preds,调用 postprocess 方法对这些预测结果进行处理,最终得到经过 NMS 处理后的最终预测结果。
该类的 postprocess 方法是其核心功能所在。它接收原始预测结果 preds_in,首先将预测框从 xyxy 格式转换为 xywh 格式,然后将框和对应的置信度合并,并进行维度变换。最后,调用 ops.non_max_suppression 方法,应用 NMS,返回处理后的结果。这个方法的参数包括置信度阈值、IoU 阈值、标签、是否多标签、是否类别无关、最大检测框数量等。
需要注意的是,NASValidator 类通常不会被直接实例化,而是在 NAS 类内部使用。这种设计使得模型的使用更加简洁和高效。整体来看,这个文件的功能是为 YOLO NAS 模型提供一个有效的后处理机制,以提高检测结果的准确性。
```python
import numpy as np
import scipy
from scipy.spatial.distance import cdist
from ultralytics.utils.metrics import bbox_ioa
try:
import lap # 导入线性分配库
assert lap.__version__ # 确保包不是目录
except (ImportError, AssertionError, AttributeError):
from ultralytics.utils.checks import check_requirements
check_requirements('lapx>=0.5.2') # 检查并更新到lap包
import lap
def linear_assignment(cost_matrix, thresh, use_lap=True):
"""
使用线性分配算法进行匹配。
参数:
cost_matrix (np.ndarray): 成本矩阵,包含分配的成本值。
thresh (float): 有效分配的阈值。
use_lap (bool, optional): 是否使用lap.lapjv算法。默认为True。
返回:
(tuple): 包含匹配索引、未匹配的索引(来自'a')和未匹配的索引(来自'b')的元组。
"""
if cost_matrix.size == 0:
# 如果成本矩阵为空,返回空匹配和所有未匹配索引
return np.empty((0, 2), dtype=int), tuple(range(cost_matrix.shape[0])), tuple(range(cost_matrix.shape[1]))
if use_lap:
# 使用lap库进行线性分配
_, x, y = lap.lapjv(cost_matrix, extend_cost=True, cost_limit=thresh)
matches = [[ix, mx] for ix, mx in enumerate(x) if mx >= 0] # 找到匹配对
unmatched_a = np.where(x < 0)[0] # 找到未匹配的'a'索引
unmatched_b = np.where(y < 0)[0] # 找到未匹配的'b'索引
else:
# 使用scipy进行线性分配
x, y = scipy.optimize.linear_sum_assignment(cost_matrix) # 获取匹配的行和列索引
matches = np.asarray([[x[i], y[i]] for i in range(len(x)) if cost_matrix[x[i], y[i]] <= thresh])
if len(matches) == 0:
unmatched_a = list(np.arange(cost_matrix.shape[0]))
unmatched_b = list(np.arange(cost_matrix.shape[1]))
else:
unmatched_a = list(set(np.arange(cost_matrix.shape[0])) - set(matches[:, 0]))
unmatched_b = list(set(np.arange(cost_matrix.shape[1])) - set(matches[:, 1]))
return matches, unmatched_a, unmatched_b # 返回匹配和未匹配的索引
def iou_distance(atracks, btracks):
"""
基于交并比(IoU)计算轨迹之间的成本。
参数:
atracks (list[STrack] | list[np.ndarray]): 轨迹'a'或边界框的列表。
btracks (list[STrack] | list[np.ndarray]): 轨迹'b'或边界框的列表。
返回:
(np.ndarray): 基于IoU计算的成本矩阵。
"""
# 将轨迹转换为边界框格式
atlbrs = [track.tlbr for track in atracks] if not isinstance(atracks[0], np.ndarray) else atracks
btlbrs = [track.tlbr for track in btracks] if not isinstance(btracks[0], np.ndarray) else btracks
ious = np.zeros((len(atlbrs), len(btlbrs)), dtype=np.float32) # 初始化IoU矩阵
if len(atlbrs) and len(btlbrs):
# 计算IoU
ious = bbox_ioa(np.ascontiguousarray(atlbrs, dtype=np.float32),
np.ascontiguousarray(btlbrs, dtype=np.float32),
iou=True)
return 1 - ious # 返回成本矩阵(1 - IoU)
def embedding_distance(tracks, detections, metric='cosine'):
"""
基于嵌入计算轨迹和检测之间的距离。
参数:
tracks (list[STrack]): 轨迹列表。
detections (list[BaseTrack]): 检测列表。
metric (str, optional): 距离计算的度量方式。默认为'cosine'。
返回:
(np.ndarray): 基于嵌入计算的成本矩阵。
"""
cost_matrix = np.zeros((len(tracks), len(detections)), dtype=np.float32) # 初始化成本矩阵
if cost_matrix.size == 0:
return cost_matrix
det_features = np.asarray([track.curr_feat for track in detections], dtype=np.float32) # 获取检测特征
track_features = np.asarray([track.smooth_feat for track in tracks], dtype=np.float32) # 获取轨迹特征
cost_matrix = np.maximum(0.0, cdist(track_features, det_features, metric)) # 计算距离
return cost_matrix # 返回成本矩阵
def fuse_score(cost_matrix, detections):
"""
将成本矩阵与检测分数融合,生成单一相似度矩阵。
参数:
cost_matrix (np.ndarray): 包含分配成本值的矩阵。
detections (list[BaseTrack]): 带有分数的检测列表。
返回:
(np.ndarray): 融合后的相似度矩阵。
"""
if cost_matrix.size == 0:
return cost_matrix
iou_sim = 1 - cost_matrix # 计算IoU相似度
det_scores = np.array([det.score for det in detections]) # 获取检测分数
det_scores = np.expand_dims(det_scores, axis=0).repeat(cost_matrix.shape[0], axis=0) # 扩展分数维度
fuse_sim = iou_sim * det_scores # 融合相似度
return 1 - fuse_sim # 返回融合后的成本矩阵
代码核心部分说明:
- 线性分配:
linear_assignment函数使用成本矩阵和阈值来找到最佳匹配,支持使用lap库或scipy库进行计算。 - IoU距离计算:
iou_distance函数计算两个轨迹集合之间的IoU,返回的成本矩阵是1减去IoU值。 - 嵌入距离计算:
embedding_distance函数基于特征嵌入计算轨迹和检测之间的距离,返回成本矩阵。 - 融合分数:
fuse_score函数将成本矩阵与检测分数结合,生成一个综合的相似度矩阵。```
这个程序文件ultralytics/trackers/utils/matching.py主要用于处理目标跟踪中的匹配问题,涉及到计算成本矩阵和进行线性分配。代码中使用了 NumPy 和 SciPy 库,并且依赖于一个名为lap的库来执行线性分配。
首先,文件导入了必要的库,包括 NumPy 和 SciPy 的空间距离计算模块 cdist,以及一个用于计算边界框交集的函数 bbox_ioa。接着,尝试导入 lap 库,如果导入失败,则通过 check_requirements 函数检查并安装所需的库。
在 linear_assignment 函数中,首先检查成本矩阵是否为空。如果为空,则返回空的匹配结果和未匹配的索引。接着,根据 use_lap 参数的值选择使用 lap 库或 SciPy 的线性分配方法来计算匹配。最终,返回匹配的索引以及未匹配的索引。
iou_distance 函数用于计算基于交并比(IoU)的成本矩阵。它接受两个轨迹列表,首先判断输入是否为 NumPy 数组,如果是,则直接使用;否则,从轨迹对象中提取边界框。然后,计算 IoU 值并返回 1 减去 IoU 的结果作为成本矩阵。
embedding_distance 函数则是计算轨迹与检测之间的距离,基于特征嵌入。它创建一个成本矩阵,计算每个轨迹的平滑特征与检测特征之间的距离,使用的距离度量可以是余弦距离等。
最后,fuse_score 函数将成本矩阵与检测得分融合,生成一个单一的相似度矩阵。它通过计算 IoU 相似度并结合检测得分,返回融合后的成本矩阵。
整体来看,这个文件实现了目标跟踪中常用的匹配算法,提供了多种计算成本的方法,以便在目标跟踪任务中进行有效的匹配。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 19
19 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)