机器学习算法——线性回归(超级详细总结)
·
1.线性回归模型
1.1公式

y^ 是预测值
n 是特征数量
xi 是第i个特征
θi 是每个特征的模型参数
1.2向量化公式

θ.T是θ的转置向量。
θ.T · x 是θ.T和x的点乘
hθ(X) 是θ的假设函数
1.3 MSE损失函数

线性回归的损失函数通常使用MSE(均方误差), 其原理对于欧几里得距离,当数据含有异常值的的时候,可以使用MAE(均值误差),对应曼哈顿距离,由于采用绝对值得形式,减少了异常值对数据的影响。
2.优化算法
2.1 标准方程

可以利用标准方程求出 θ^的优化最小值,是模型求解最优参数的一种形式。
手写实现
import numpy as np
X = np.random.rand(100,1) # 随机生成
y = 1+2*X + np.random.randn(100,1) # 目标函数
X_b = np.c_[np.ones((100,1)),X] # 加入噪音 b
theta = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y) # 标准方程
Sklearn
from sklearn.linear_model import LinearRegression
X = np.random.rand(100,1)
y = 1+2*X + np.random.randn(100,1)
linReg = LinearRegression()
linReg.fit(X, y)
linReg.intercept_, linReg.coef_ # 得到参数与标准方程一致
标准方程求逆矩阵的复杂度为O(n ^ 2.4) 到 O(n ^ 3) 之间, 所以特征数量较大时,标准方程计算会很慢。对于实例数量来说,方程是线性的,只要内存足够还是可以计算的。当计算量无限大的时候,梯度下降就成了一种更好的选择。
2.2 批量梯度下降梯度下降
梯度下降的是通用的优化算法,其目的是通过迭代找到使损失函数最小的参数。
求偏导部分:
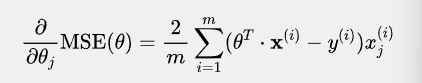
线性模型的MSE损失函数恰好是个凸函数,这意味全局只有一个最小值。它同时也是一个连续函数,所以斜率不会产生陡峭的变化。
eta = 0.1 # 学习率
iteras = 1000 # 迭代周期
m = 100 #实例数量(数据的行数)
X = np.random.rand(100,1) # 随机生成
y = 1+2*X + np.random.randn(100,1) # 目标函数
X_b = np.c_[np.ones((100,1)),X] # 加入噪音 b
np.random.seed(42)
theta = np.random.randn(2,1)
for itera in range(iteras):
gradients = 2/m * X_b.T @ (X_b @ theta - y) # @ 是点乘的另外一种形式
theta = theta - eta * gradients
只要时间允许,批量梯度下降可以帮助线性模型找到全局最小值,批量梯度下降的缺点是每次迭代过程都采用了所有的训练样本,训练开销相对于其他类型梯度下降算法慢。
应用梯度下降时,需要保证所有特征值的大小比例都差不多(比如使用Scikit-Learn的StandardScaler类),否则收敛的时间会长很多。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)