Bright Data Web Scraping 实战指南:如何用 Web Scraper API 采集 Instagram、TikTok 社媒数据(2026)
前言:
国内工具做国内很强,但出海品牌找海外 KOL 就抓瞎。飞瓜、卡思、新榜覆盖的是抖音快手生态,一旦需要 Instagram、TikTok 海外版、YouTube 的博主数据,这些工具要么没有,要么字段少得可怜。而 HypeAuditor 虽然覆盖海外,但每月订阅费用高、数据更新慢、细分条件有限——你想找"粉丝在东南亚、互动率>5%、近30天发过美妆内容"这样的组合条件,海外社媒数据分散在多个平台,传统营销工具通常难以满足跨平台、实时和自定义筛选需求。
| 工具 | 月费 | 覆盖平台 | 数据时效 | 核心局限 |
|---|---|---|---|---|
| 飞瓜数据 | ¥999–¥3,999/月 | 抖音/快手/B站/小红书 | 较新 | 不覆盖 Instagram/TikTok 海外平台;出海用不了 |
| 新榜 | ¥1,500–¥5,000/月 | 微信/微博/抖音 | 较新 | 主要服务国内投放,海外博主数据几乎没有 |
| 卡思数据 | ¥2,000+/月 | 抖音/快手/B站 | 较新 | 仅限国内平台 |
| 蝉妈妈 | ¥299–¥1,999/月 | 抖音/TikTok 部分 | 较新 | TikTok 海外数据覆盖不全,字段有限 |
| HypeAuditor | $99–$399/月 | Instagram/TikTok/YouTube | 月度更新 | 价格高,细分筛选能力弱,无中文支持 |
| 自建(Bright Data) | 按用量付费 | 海外社媒全平台,可自定义 | 实时 | 需要初始配置时间 |
本文教你用 Bright Data 的 Web Scraper API,从零搭建一套 KOL 数据采集 + 评分 Pipeline。
Bright Data 是全球 Web 数据平台,提供:
- Web Scraper API — 提供 100+ 网站的数据采集方案,输出结构化数据,覆盖社交媒体、电商和企业数据等场景
- Residential Proxies — 提供 4 亿+ residential IPs,支持全球定位、IP rotation 和高级 anti-bot 场景
- 按量付费 — 支持按使用量计费,适合从 Demo 验证到生产级数据采集 Pipeline 的不同阶段
从 KOL 发现、竞品分析,到 AI 数据采集和市场研究,稳定的 Web 数据来源是自动化系统的基础。
Bright Data 提供 Web Scraper API、Residential Proxies 和数据产品,帮助团队更高效地完成大规模 Web 数据采集。
👉 探索 Bright Dat 数据采集解决方案
一、注册并获取 API Token
1.1 注册 Bright Data
注册账号。新用户获得免费额度,足够跑通本文全部示例。
1.2 创建 API Token
登录后在控制台:Account → API Tokens → Create Token,记下生成的 Token,后续所有 API 调用都需要。
# .env
BRIGHTDATA_API_TOKEN=你的_API_Token_放这里
1.3 创建 Instagram 和 TikTok 数据采集器(Zone)
在 Bright Data 控制台进入 Data Collector → Scrapers → Scrapers Library:
- 搜索 “Instagram” → 选择 Instagram Profile Scraper → 点击 Create Zone,命名为
instagram_profiles - 搜索 “TikTok” → 选择 TikTok Profile Scraper → 点击 Create Zone,命名为
tiktok_profiles
每个 Zone 都有一个 Zone Name,后续调用 API 时指定这个名称即可触发采集。
二、Bright Data API 的调用方式
Bright Data Web Scraper API 是一个用于自动化采集结构化 Web 数据的 API。它允许开发者提交 URL、运行预构建 Scraper,并获取 JSON 格式结果。开发者只需要通过 API 提交采集任务,再根据返回的 snapshot_id 查询任务状态并下载结果数据。
2.1 API 端点
Bright Data Web Scraper API 的核心端点是 Data Collector API (DCA):
POST https://api.brightdata.com/dca/trigger
注意:API Endpoint 可能随 Bright Data 产品版本更新,请以官方 API 文档为准。
2.2 认证方式
所有请求在 Header 中携带 Bearer Token:
Authorization: Bearer <你的_API_Token>
Content-Type: application/json
2.3 工作流程
Bright Data 的 Scraper API 是异步模式:
1. POST /dca/trigger ← 提交采集任务
↓
2. 轮询 GET /dca/snapshot/{id} ← 查询任务状态(每 10 秒一次)
↓
3. 任务完成后下载数据 ← 结构化 JSON
每次调用返回一个 snapshot_id,用它持续查询任务状态(phase 字段),直到 phase = "done"。
2.4 触发采集的请求体
{
"zone": "instagram_profiles",
"input": [
{"url": "https://www.instagram.com/beauty_by_emma/"},
{"url": "https://www.instagram.com/techwithjason/"}
]
}
zone:你在控制台创建的 Zone 名称input:要采集的目标 URL 列表
三、采集 Instagram 博主数据
# instagram_scraper.py
import os
import json
import time
import requests
from dotenv import load_dotenv
load_dotenv()
API_TOKEN = os.getenv("BRIGHTDATA_API_TOKEN")
ZONE = "instagram_profiles" # 你在控制台创建的 Zone 名称
API_BASE = "https://api.brightdata.com/dca"
HEADERS = {
"Authorization": f"Bearer {API_TOKEN}",
"Content-Type": "application/json",
}
def trigger_collection(usernames: list[str]) -> str:
"""提交采集任务,返回 snapshot_id"""
inputs = [{"url": f"https://www.instagram.com/{u}/"} for u in usernames]
resp = requests.post(
f"{API_BASE}/trigger",
headers=HEADERS,
json={"zone": ZONE, "input": inputs},
timeout=30,
)
resp.raise_for_status()
snapshot_id = resp.json()["snapshot_id"]
print(f"✓ 任务已提交,snapshot_id = {snapshot_id}")
return snapshot_id
def poll_until_done(snapshot_id: str, interval: int = 10, max_attempts: int = 60):
"""轮询任务状态,直到完成"""
for i in range(max_attempts):
time.sleep(interval)
resp = requests.get(
f"{API_BASE}/snapshot/{snapshot_id}",
headers=HEADERS,
timeout=30,
)
resp.raise_for_status()
snap = resp.json()
phase = snap.get("phase")
print(f" 轮询 {i+1}/{max_attempts} — phase={phase}")
if phase == "done":
return snap
if phase == "failed":
raise RuntimeError(f"任务失败: {snap}")
raise TimeoutError("采集超时")
def download_records(snapshot: dict) -> list[dict]:
"""从完成的 snapshot 中提取数据"""
records = snapshot.get("records", [])
if records:
return records
snapshot_id = snapshot["snapshot_id"]
resp = requests.get(
f"{API_BASE}/snapshot/{snapshot_id}/download",
headers=HEADERS,
timeout=60,
)
resp.raise_for_status()
return resp.json() if resp.headers.get("Content-Type", "").startswith("application/json") else []
# ── 主流程 ──
if __name__ == "__main__":
targets = ["beauty_by_emma", "techwithjason", "fitness_with_luna"]
sid = trigger_collection(targets)
result = poll_until_done(sid)
data = download_records(result)
print(f"\n✓ 采集完成,共 {len(data)} 条博主数据")
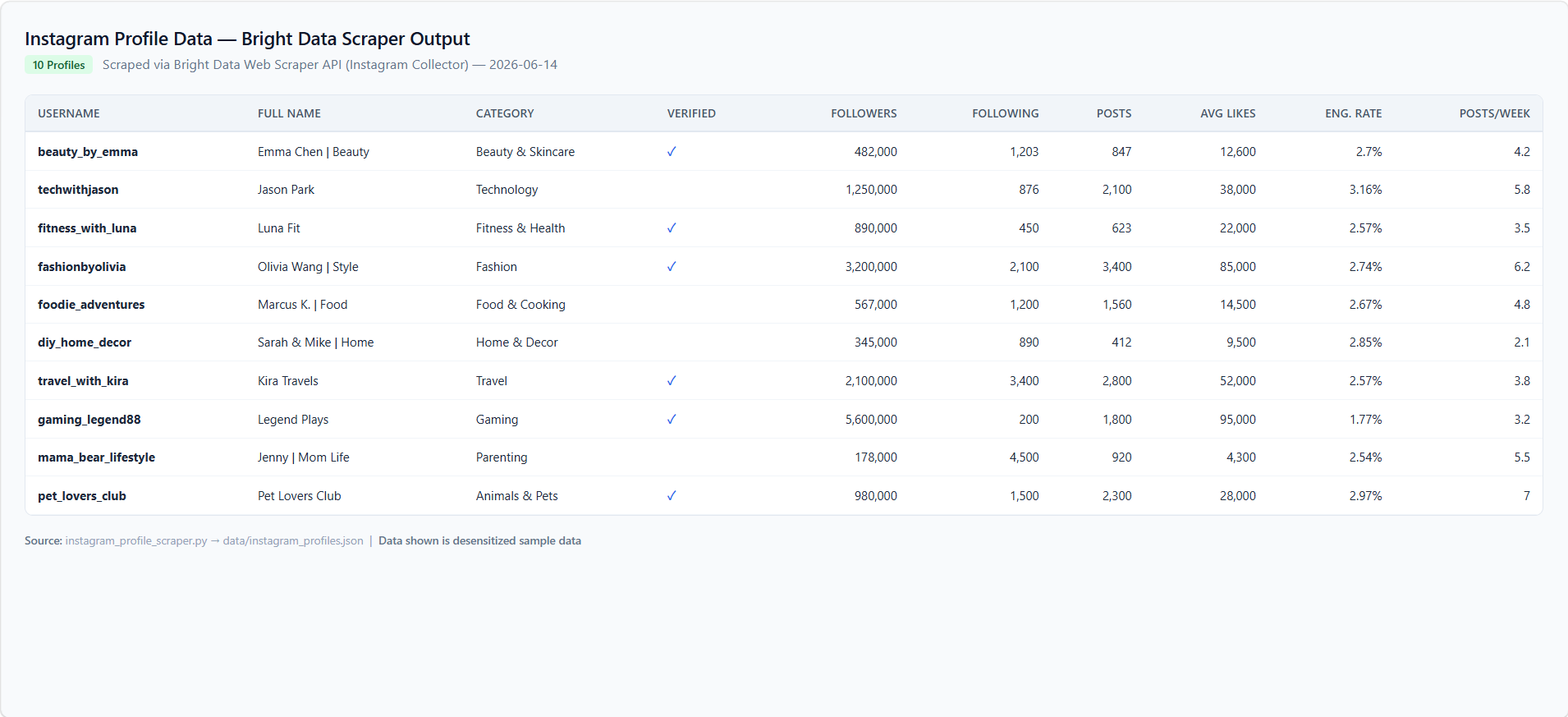
# Bright Data 返回的典型字段包括:
# username, full_name, biography, followers_count, following_count,
# posts_count, is_verified, is_business_account, category,
# recent_posts (含 likes, comments, timestamp, caption)
with open("instagram_data.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print("✓ 已保存到 instagram_data.json")
关键点:
zone必须与你在控制台创建的 Zone Name 完全一致- 输入是 Instagram 的公开 profile URL,不需要登录
- 返回数据是结构化 JSON,包含粉丝数、互动数据、近期帖文等
- 轮询间隔建议 10 秒,多数采集任务在 30-60 秒内完成
四、采集 TikTok 创作者数据
TikTok 的调用逻辑与 Instagram 完全一致,只是 Zone 名称和目标 URL 不同。
# tiktok_scraper.py
import os
import json
import time
import requests
from dotenv import load_dotenv
load_dotenv()
API_TOKEN = os.getenv("BRIGHTDATA_API_TOKEN")
ZONE = "tiktok_profiles" # 你在控制台创建的 TikTok Zone
API_BASE = "https://api.brightdata.com/dca"
HEADERS = {
"Authorization": f"Bearer {API_TOKEN}",
"Content-Type": "application/json",
}
def trigger_tiktok_collection(usernames: list[str]) -> str:
"""提交 TikTok 采集任务"""
inputs = [{"url": f"https://www.tiktok.com/@{u}"} for u in usernames]
resp = requests.post(
f"{API_BASE}/trigger",
headers=HEADERS,
json={"zone": ZONE, "input": inputs},
timeout=30,
)
resp.raise_for_status()
return resp.json()["snapshot_id"]
def poll_tiktok(snapshot_id: str, interval: int = 10, max_attempts: int = 60):
"""轮询直到完成"""
for i in range(max_attempts):
time.sleep(interval)
resp = requests.get(
f"{API_BASE}/snapshot/{snapshot_id}",
headers=HEADERS,
timeout=30,
)
snap = resp.json()
if snap.get("phase") == "done":
return snap
if snap.get("phase") == "failed":
raise RuntimeError(f"任务失败: {snap}")
print(f" 轮询 {i+1}/{max_attempts} — phase={snap.get('phase')}")
raise TimeoutError("采集超时")
def download_tiktok(snapshot: dict) -> list[dict]:
"""下载数据"""
records = snapshot.get("records", [])
if records:
return records
sid = snapshot["snapshot_id"]
resp = requests.get(
f"{API_BASE}/snapshot/{sid}/download",
headers=HEADERS,
timeout=60,
)
return resp.json() if isinstance(resp.json(), list) else []
if __name__ == "__main__":
targets = ["beauty_by_emma", "techwithjason", "fitness_with_luna"]
sid = trigger_tiktok_collection(targets)
result = poll_tiktok(sid)
data = download_tiktok(result)
print(f"\n✓ 采集完成,共 {len(data)} 条创作者数据")
# TikTok 返回字段示例:
# username, nickname, follower_count, heart_count, video_count,
# avg_views, avg_likes, avg_shares, follower_growth_estimate
with open("tiktok_data.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print("✓ 已保存到 tiktok_data.json")
TikTok 特殊说明:
- 除了按 username 采集,Bright Data 还支持按 hashtag 发现创作者
- 在
input中传入{"url": "https://www.tiktok.com/tag/beauty"}即可触发标签搜索模式 - TikTok JSON 返回通常嵌套在
userInfo.stats下,解析时注意字段路径
从 Demo 到生产环境
本文示例展示了如何调用 API 获取 Instagram 和 TikTok 数据。
在真实项目中,你还可以进一步扩展:
- 自动化每日数据更新
- 多平台 KOL 数据合并
- AI 驱动的内容分析
- 企业级 Web 数据 Pipeline
👉 开始使用 Bright Data 构建你的数据基础设施
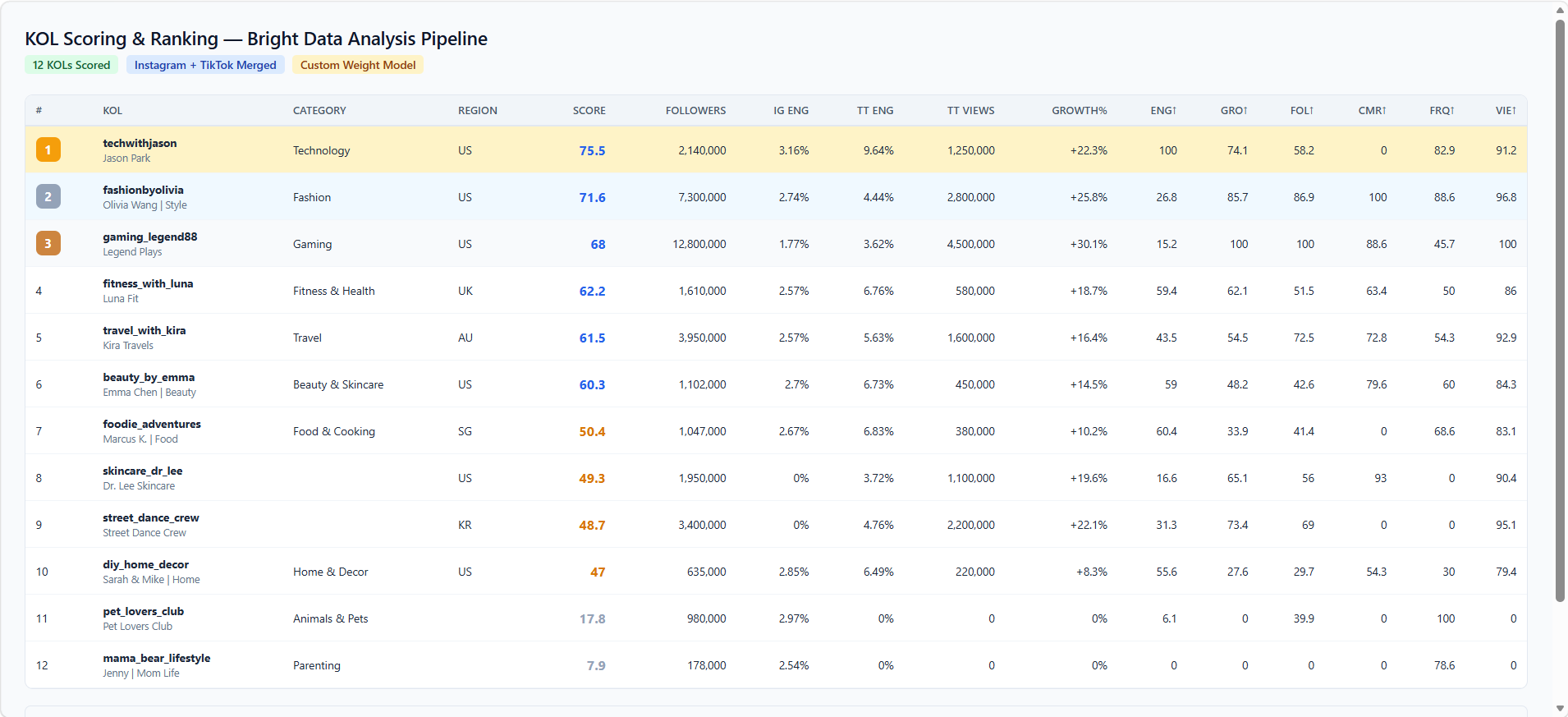
五、构建 KOL 评分与筛选模型
拿到 Instagram 和 TikTok 的原始数据后,我们需要:
- 合并 — 同一个 KOL 可能在 IG 和 TT 都有账号,按 username 合并
- 标准化 — 不同维度的指标量纲不同(粉丝数 vs 互动率),需要归一化到 0-100
- 加权打分 — 根据你的 campaign 优先级设置各维度权重
- 排名 — 按综合得分降序排列
5.1评分维度与默认权重
| 维度 | 权重 | 指标来源 | 归一化方式 |
|---|---|---|---|
| 互动率 | 30% | Instagram / TikTok engagement rate | Min-Max → 0–100 |
| 涨粉速度 | 20% | TikTok 近期视频播放量趋势 | Min-Max → 0–100 |
| 粉丝规模 | 15% | Instagram + TikTok 总粉丝数 | 对数归一化 |
| 带货潜力 | 10% | 是否有 TikTok Shop + 商品数 | Min-Max → 0–100 |
| 更新频率 | 10% | Instagram 每周发帖数 | Min-Max → 0–100 |
| 平均播放 | 15% | TikTok 视频平均播放量 | 对数归一化 |
权重可在 **.env** 中自定义:
KOL_WEIGHT_ENGAGEMENT_RATE=0.30
KOL_WEIGHT_FOLLOWER_GROWTH=0.20
KOL_WEIGHT_FOLLOWERS=0.15
KOL_WEIGHT_COMMERCE_POTENTIAL=0.10
KOL_WEIGHT_CONTENT_FREQUENCY=0.10
KOL_WEIGHT_AVG_VIEWS=0.15
5.2核心评分代码
# kol_scoring.py — 核心逻辑
import numpy as np
import pandas as pd
def minmax_norm(values: np.ndarray) -> np.ndarray:
"""Min-Max 归一化到 0–100"""
lo, hi = values.min(), values.max()
if hi - lo < 1e-9:
return np.full_like(values, 50.0)
return (values - lo) / (hi - lo) * 100
def log_norm(values: np.ndarray) -> np.ndarray:
"""对数归一化(适合粉丝数这类长尾指标)"""
logged = np.log1p(np.maximum(values, 1))
lo, hi = logged.min(), logged.max()
if hi - lo < 1e-9:
return np.full_like(values, 50.0)
return (logged - lo) / (hi - lo) * 100
def score_kols(df: pd.DataFrame, weights: dict) -> pd.DataFrame:
df["_engagement"] = np.maximum(
df["ig_engagement_rate"].fillna(0),
df["tt_engagement_rate"].fillna(0),
)
df["score_engagement"] = minmax_norm(df["_engagement"].values)
df["score_growth"] = minmax_norm(df["tt_follower_growth"].fillna(0).values)
df["score_followers"] = log_norm(df["total_followers"].fillna(0).values)
df["score_commerce"] = minmax_norm(df["tt_products_count"].fillna(0).values)
df["score_content_freq"] = minmax_norm(df["ig_posts_per_week"].fillna(0).values)
df["score_views"] = log_norm(df["tt_avg_views"].fillna(0).values)
df["kol_score"] = (
df["score_engagement"] * weights["engagement_rate"]
+ df["score_growth"] * weights["follower_growth"]
+ df["score_followers"] * weights["followers"]
+ df["score_commerce"] * weights["commerce"]
+ df["score_content_freq"]* weights["content_frequency"]
+ df["score_views"] * weights["avg_views"]
)
df.sort_values("kol_score", ascending=False, inplace=True)
df["rank"] = range(1, len(df) + 1)
return df
总结及代码仓库
你可以在GitHub中获取完整代码(将 <API_TOKEN> 替换为你的真实 Token):
https://github.com/xyp0213/brightdata–
brightdata--/
├── scripts/
│ ├── instagram_scraper.py ← Instagram 采集器
│ ├── tiktok_scraper.py ← TikTok 采集器
│ ├── kol_scoring.py ← KOL 评分引擎
│ └── export_report.py ← 导出 Excel/Google Sheets
├── .env.example ← 环境变量模板
├── requirements.txt
└── README.md
本文给出了一个自建 KOL 数据 Pipeline 的完整方案,Bright Data Web Scraper API 可以降低海外平台数据采集的工程复杂度,减少代理管理和反爬基础设施维护成本,同时避免从零编写 XPath/CSS selector。
对于需要跨平台、自定义字段和自动化更新的出海团队来说,自建 Web 数据采集 Pipeline 能提供更高的灵活性。通过 Bright Data Web Scraper API,你可以按业务需求采集 Instagram、TikTok 等平台的数据,并将结果接入后续的 KOL 评分、内容分析和市场研究流程。
下一步:把社媒数据转化为业务洞察
找到合适的 KOL 只是第一步。
通过自动化 Web 数据采集,你可以持续追踪:
- 创作者增长趋势
- 内容表现变化
- 市场热点
- 竞品营销动作
立即开始使用 Bright Data,搭建你的海外社媒数据分析系统。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 4
4 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)