VLA-Adapter论文解读(三):Bridge Attention的机制与原理解析
论文链接:https://arxiv.org/abs/2509.09372
项目主页:VLA-Adapter
桥接注意力机制(Bridge Attention)作为VLA-Adapter的核心贡献,也是理解“为什么0.5B参数模型能够跑出SOTA级别性能”的关键原因。本文将从设计动机、内部结构、数学原理以及关键设计决策四个层面完成拆解。
一、设计动机
1.1 现有桥接方式
在VLA-Adapter模型之前主流的VL→A的桥接方式可以归纳为以下三类:
- Raw特征直传:直接提取VLM的最后一层特征,凭借或交叉注意力传入Policy;
- 离散Token化:将动作离散化为token,与文本公用词表;
- 额外的Query接口:插入可学习token作为VLM输入。
这三种方式的弊端在于,Raw特征直传因为只用了VLM最后一层,所以丢失了中间层的丰富细节;离散Token化容易导致量化误差;Query以mask形式输入,冻结骨干时无法训练。
1.2 三大发现对桥接设计的要求
基于上一节中的三大关键发现,Bridge Attention需要满足以下设计目标:
- 访问Raw特征的中间层
- AQ深层最优,需要足够的Transformer层;
- 全层最优,策略网络的每一层都需要访问VLM对应层的特征。
因此Bridge Attention需要同时接收Raw和AQ两类特征,并且进行差异化处理。策略的每一层都需要接收VLM的每一层特征,并让动作主动查询。
二、内部结构
论文设计了一种基于L1的策略网络。在时间t步,策略网络的输入包括:。其中
是策略网络的层,具有
。
是H步的初始动作(全零),通过层归一化(LN)和多层感知机(MLP)处理得到
。
为本体感知状态,通过两层MLP映射得到本体嵌入
。输出为
步的动作块
。每一层由桥接注意力模块和前馈网络(FFN)组成。桥接注意力架构如图所示。
Bridge Attention位于Policy的每一层当中,输入的是动作隐变量,输出的是融合后的动作表征,并且是由三路并行注意力组成:
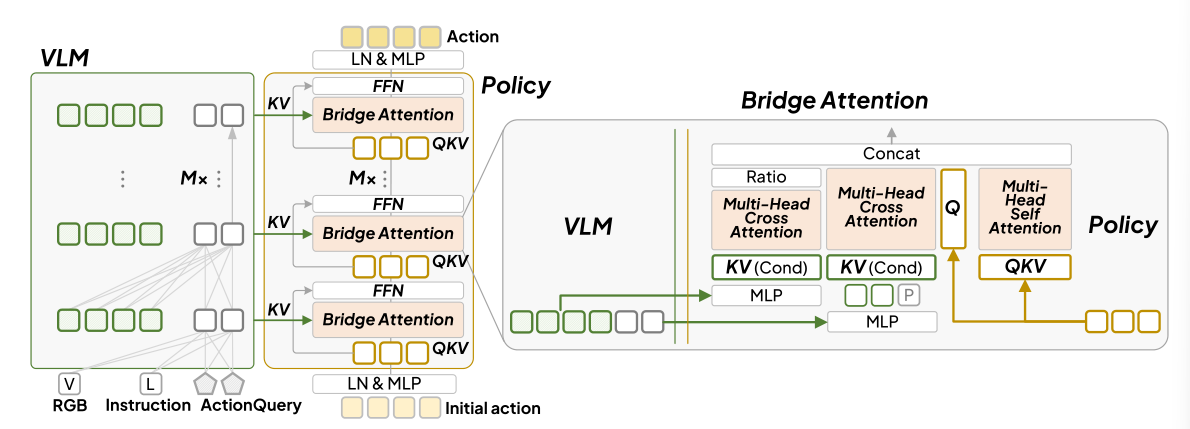
论文所提出的Bridge Attention旨在通过条件和
最大程度地引导动作生成。每个桥接注意力都是由两个交叉注意力和一个自注意力组成。第一个交叉注意力中,
通过MLP
处理得到
。动作潜在变量
用作
,并且执行注意力操作得到
。在第二个交叉注意力中,
需要与
拼接,并通过MLP
得到
。
用作
,得到
。自注意力中,
作为
,并有
。
| 注意力 | 全称 | Q | K/V | 作用 | 门控 |
| 交叉注意力1 | 动作隐变量 | Raw特征 | 根据VLM中间层提取视觉-语言细节 | ||
| 交叉注意力2 | 动作隐变量 | AQ特征+本体感受 | 提取任务导向的深层语义 | 无 | |
| 自注意力 | 动作隐变量 | 动作隐变量自身 | 建模动作块内的时间连贯性 | 无 |
三路并行注意力的主要作用在于:如果只用则缺乏语义,难以理解复杂指令,如果只用
则缺乏视觉细节,难以精准定位;如果没有
那么动作块内时间步之间缺乏连贯性,动作可能不连续。对应了动作生成的三个必要条件:看得准(Raw)+ 懂意图(AQ)+ 动得顺(SA)。
三、数学原理
为了将特定的选择性地注入到策略的动作空间中,本文引入了一个学习参数比率g来调节
的影响。g初始化为0值,并采用tanh激活函数
,以防止极端值破坏分布的稳定性。核心公式如下:
拼接后的维度会变为原来的3倍,再通过FFN投影回原始维度,相当于让网络学习一个自适应的融合权重矩阵。
四、三个关键设计决策
- 决策1:为什么Raw带门控,AQ不带?
| 特征类型 | 门控策略 | 原因 | 训练动态 |
| Raw | 来自预训练VLM,分布与动作空间差异大 | 初期≈0,训练中g逐渐增大 | |
| AQ | 1 | 从零训练,完全为动作生成优化 | 全称无条件信任 |
如果Raw无门控,而AQ有门控,则初期训练会崩溃——因为Raw的分布与动作输出完全不对齐。
- 决策2:为什么用tanh而非sigmoid?
| 激活函数 | 范围 | 效果 | 适用性 |
| sigmoid | [0,1] | 只能正注入,无法抑制有害特征 | 适合二值开关 |
| tanh | [-1,1] | 允许负注入,主动抑制某些层的有害Raw特征 | 适合连续调节 |
尽管训练后g通常收敛到正值,但是负值的能力提供了更大的优化空间,让模型在训练早起有机会关掉或者反转某些层带来的干扰。
- 决策3:为什么用交叉注意力而非简单拼接或者MLP?
| 融合方式 | 计算复杂度 | 信息检索能力 | 可解释性 |
| 简单拼接+MLP | 低 | 弱 | 差 |
| 交叉注意力 | 中 | 强 | 好 |
交叉注意力的核心优势是让动作主动查询——动作隐变量作为Q,可以学习到应该关注Raw/AQ中的哪些部分。这种查询-检索模式天然适合条件生成任务。
总结
Bridge Attention本质上是让动作生成从“被动接收最后一层特征”升级为“主动查询全层条件特征”。动作同时查询Raw特征(获取视觉细节)、AQ特征(获取任务语义)、和自身历史(获取时间连贯性);Raw带可学习的门控单元tanh(g),AQ完全注入(完全可信);策略的每一层都需要主动访问VLM对应层的特征,而非被动接收最后一层的“压缩摘要”。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)