Python爬虫实战:爬取携程酒店评论并存入MySQL数据库
1. 前言
大家好!今天带来一篇适合新手的Python爬虫实战教程,我们将从零开始,爬取携程网的酒店评论数据,并将结果存入MySQL数据库。通过这个项目,你可以掌握:
- 如何分析网页接口并构造请求
- 如何使用
requests库发送POST请求 - 如何处理JSON数据
- 如何将数据保存到MySQL数据库
- 简单的反爬措施(随机延时、异常处理)
注意:本教程仅用于学习和研究,请勿对目标网站进行大规模请求,尊重网站版权和用户隐私。爬取前建议查看网站的robots.txt文件。
2. 环境准备
2.1 安装Python
确保你已经安装了Python 3.6+版本,如果没有安装,可以去官网下载安装。
2.2 安装第三方库
我们需要用到以下几个库:
pymysql:操作MySQL数据库requests:发送HTTP请求json:处理JSON数据(Python自带)time、random:用于延时和随机数
打开命令行(终端),执行以下命令安装:
pip install pymysql requests
2.3 安装MySQL数据库
你需要安装MySQL数据库,并创建一个用户(例如root)并记住密码。本教程使用本地数据库,你也可以使用云数据库。
3. 爬虫分析
在写代码之前,我们先来分析携程酒店评论的接口。
打开浏览器,访问携程酒店详情页(例如:https://hotels.ctrip.com/hotel/xxx),按F12打开开发者工具,切换到Network(网络)标签,刷新页面,找到评论相关的请求。通常会有一个getHotelCommentList的POST请求。
我们通过抓包发现,评论接口地址是:
https://m.ctrip.com/restapi/soa2/33278/getHotelCommentList

请求方式为POST,请求头(headers)中包含很多参数,如cookie、user-agent等,请求体中是一个JSON对象,包含hotelId、pageIndex等参数。
4. 代码实现
我们按照面向对象的方式编写爬虫,将所有功能封装在Spider类中。
4.1 导入所需模块
import pymysql
import requests
import time
import random
import json
from requests.exceptions import RequestException
4.2 定义Spider类及初始化
class Spider:
def __init__(self):
# 接口地址
self.url = 'https://m.ctrip.com/restapi/soa2/33278/getHotelCommentList'
# 伪装头
self.headers = {
'accept': 'application/json',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'no-cache',
'content-type': 'application/json',
# 替换成自己的cookie
'cookie': '',
'origin': 'https://hotels.ctrip.com',
'pragma': 'no-cache',
'priority': 'u=1, i',
'referer': 'https://hotels.ctrip.com/',
'sec-ch-ua': '"Not(A:Brand";v="8", "Chromium";v="144", "Microsoft Edge";v="144"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/144.0.0.0 Safari/537.36 Edg/144.0.0.0',
'x-ctx-country': 'CN',
'x-ctx-currency': 'CNY',
'x-ctx-locale': 'zh-CN',
'x-ctx-ubt-pageid': '10650171194',
'x-ctx-ubt-pvid': '5',
'x-ctx-ubt-sid': '15',
'x-ctx-ubt-vid': '1766813870908.08e9zbNAFVFP',
'x-ctx-wclient-req': 'da863c9181a16db6375013e79f3520dc'
}
# 参数(URL中的查询参数)
self.params = {
'_fxpcqlniredt': '09031109216141753464',
'x-traceID': '09031109216141753464-1768914287515-4391436'
}
# 临时存储所有页的评论响应
self.commentList = []
# 初始化数据库连接(先连接到MySQL服务器,不指定数据库)
self.connect = pymysql.connect(
host='localhost',
user='root',
password='your_password', # 修改为你的密码
charset='utf8mb4' # 使用utf8mb4支持表情
)
self.cursor = self.connect.cursor()
# 数据库名称
self.db_name = 'hotel'
# 表名称
self.table_name = 'hotel_comments'
关键点说明:
self.headers中的cookie需要从浏览器中复制,因为携程需要登录状态或某些认证信息。你可以登录携程后,在开发者工具中找到任意请求的cookie,复制粘贴到这里。self.params是URL后面的查询参数,可能包含追踪ID,一般可以保留原样。- 数据库连接时,先不指定数据库名,因为后面需要创建数据库。
4.3 获取酒店评论(多页)
def getHotelCommentFile(self, Id):
"""
获取酒店评论文件
:param Id: 酒店的id
:return: 酒店评论列表(每页响应数据)
"""
for i in range(1, 101): # 假设最多100页,可自行调整
data_dict = {
"hotelId": Id,
"pageIndex": i,
"pageSize": 10,
"repeatComment": 1,
"needStaticInfo": False,
"functionOptions": ["integratedTopComment", "ctripIntegratedExpediaTaList"],
"head": {
"cid": "1766813870908.08e9zbNAFVFP",
"ctok": "",
"cver": "0",
"lang": "01",
"sid": "",
"syscode": "09",
"auth": "",
"xsid": "",
"extension": [],
"platform": "PC",
"bu": "HBU",
"group": "ctrip",
"aid": "",
"ouid": "",
"locale": "zh-CN",
"timezone": "8",
"currency": "CNY",
"pageId": "102003",
"vid": "1766813870908.08e9zbNAFVFP",
"guid": "",
"isSSR": False
}
}
# 将字典转为JSON字符串
data = json.dumps(data_dict, ensure_ascii=False)
try:
# 随机延时,避免请求过快被反爬
time.sleep(random.uniform(2, 3))
# 发送POST请求
response = requests.post(self.url, headers=self.headers, params=self.params, data=data)
if response.status_code == 200:
self.commentList.append(response.json())
print(f'第{i}页的评论数据获取完毕!!!')
else:
print(f'状态码为: {response.status_code}')
print(f'网页内容为: {response.text}')
except RequestException as request_error:
print(f'网络异常: {request_error}')
time.sleep(random.uniform(2.5, 3.5))
except Exception as e:
print(f'其他异常: {e}')
time.sleep(random.uniform(3, 4))
return self.commentList
注意:
- 我们假设评论最多100页,实际可根据返回的总页数动态控制,这里为了简化直接循环。
data_dict是请求体,模仿了浏览器发送的数据结构。time.sleep(random.uniform(2, 3))用于模拟人类访问,降低被封IP的风险。
4.4 解析评论内容
def parseComment(self, Comments):
"""
解析内容 - 获取评论内容
:param Comments: 评论列表(每页响应数据)
:return: 评论内容列表
"""
commentContents = []
for Comment in Comments:
# 获取当前页的评论列表(注意:Comment['data']里可能包含commentList字段)
commentList = Comment['data']['commentList']
for comment in commentList:
# 提取评论内容
commentContents.append(comment['content'])
return commentContents
响应数据结构大致如下(简化):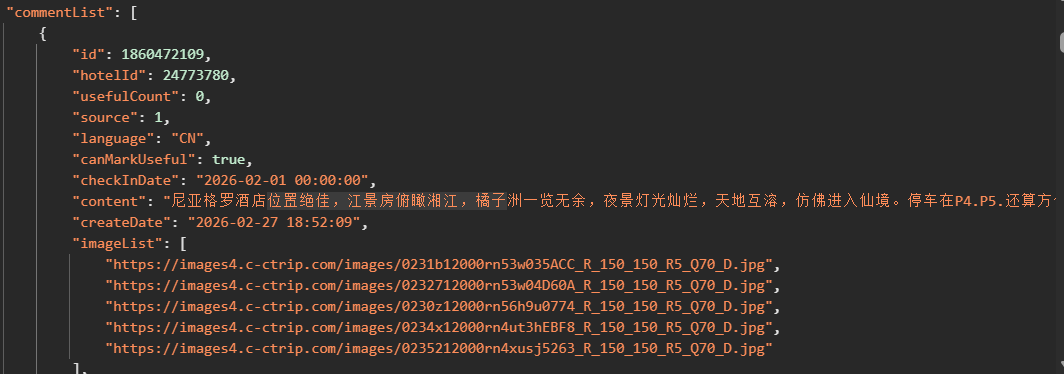
我们只需提取content字段。
4.5 创建数据库和表
def createMysqlDbTable(self):
"""
创建数据库和数据表
"""
# 1. 创建数据库(如果不存在)
create_db_sql = f"CREATE DATABASE IF NOT EXISTS {self.db_name} CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;"
try:
self.cursor.execute(create_db_sql)
print(f"数据库 {self.db_name} 已存在或创建成功。")
except Exception as e:
print(f"创建数据库失败: {e}")
raise
# 2. 切换到目标数据库
self.cursor.execute(f"USE {self.db_name}")
# 3. 创建数据表(如果不存在)
create_table_sql = f"""
CREATE TABLE IF NOT EXISTS {self.table_name} (
id INT AUTO_INCREMENT PRIMARY KEY,
hotel_id INT NOT NULL,
comment TEXT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
"""
try:
self.cursor.execute(create_table_sql)
print(f"数据表 {self.table_name} 已存在或创建成功。")
except Exception as e:
print(f"创建数据表失败: {e}")
raise
表字段说明:
id:自增主键hotel_id:酒店ID(整数)comment:评论内容(TEXT类型,支持长文本)created_at:插入时间戳,自动生成
使用utf8mb4字符集是为了支持emoji表情等特殊字符。
4.6 保存评论到MySQL
def saveToMysql(self, hotel_id, contents):
"""
将评论保存到数据库中
:param hotel_id: 酒店ID
:param contents: 评论内容列表
"""
insert_sql = f"INSERT INTO {self.table_name} (hotel_id, comment) VALUES (%s, %s);"
try:
# 准备批量插入的数据(元组列表)
data_to_insert = [(hotel_id, content) for content in contents]
# 批量插入
self.cursor.executemany(insert_sql, data_to_insert)
self.connect.commit()
print(f"成功插入 {len(contents)} 条记录到数据库。")
except Exception as e:
self.connect.rollback()
print(f"批量插入失败: {e}")
使用executemany可以一次性插入多条记录,提高效率。
4.7 主流程方法
def start(self, hotel_id):
"""
主程序 - 集合所有功能模块的函数
:param hotel_id: 酒店的id
"""
# 1. 创建数据库和表
self.createMysqlDbTable()
# 2. 获取评论数据(返回的是完整的响应列表,包含分页)
comment_responses = self.getHotelCommentFile(hotel_id)
if comment_responses:
# 3. 解析出评论内容
comment_contents = self.parseComment(comment_responses)
# 4. 存入数据库
self.saveToMysql(hotel_id, comment_contents)
4.8 关闭数据库连接
def close(self):
"""关闭数据库连接"""
self.cursor.close()
self.connect.close()
4.9 程序入口
if __name__ == '__main__':
hotelId = int(input('请输入酒店id: '))
hotelComment = Spider()
try:
hotelComment.start(hotelId)
except Exception as e:
print(f"程序运行出错: {e}")
finally:
hotelComment.close()
print('所有评论信息已经插入到数据表中!!!')
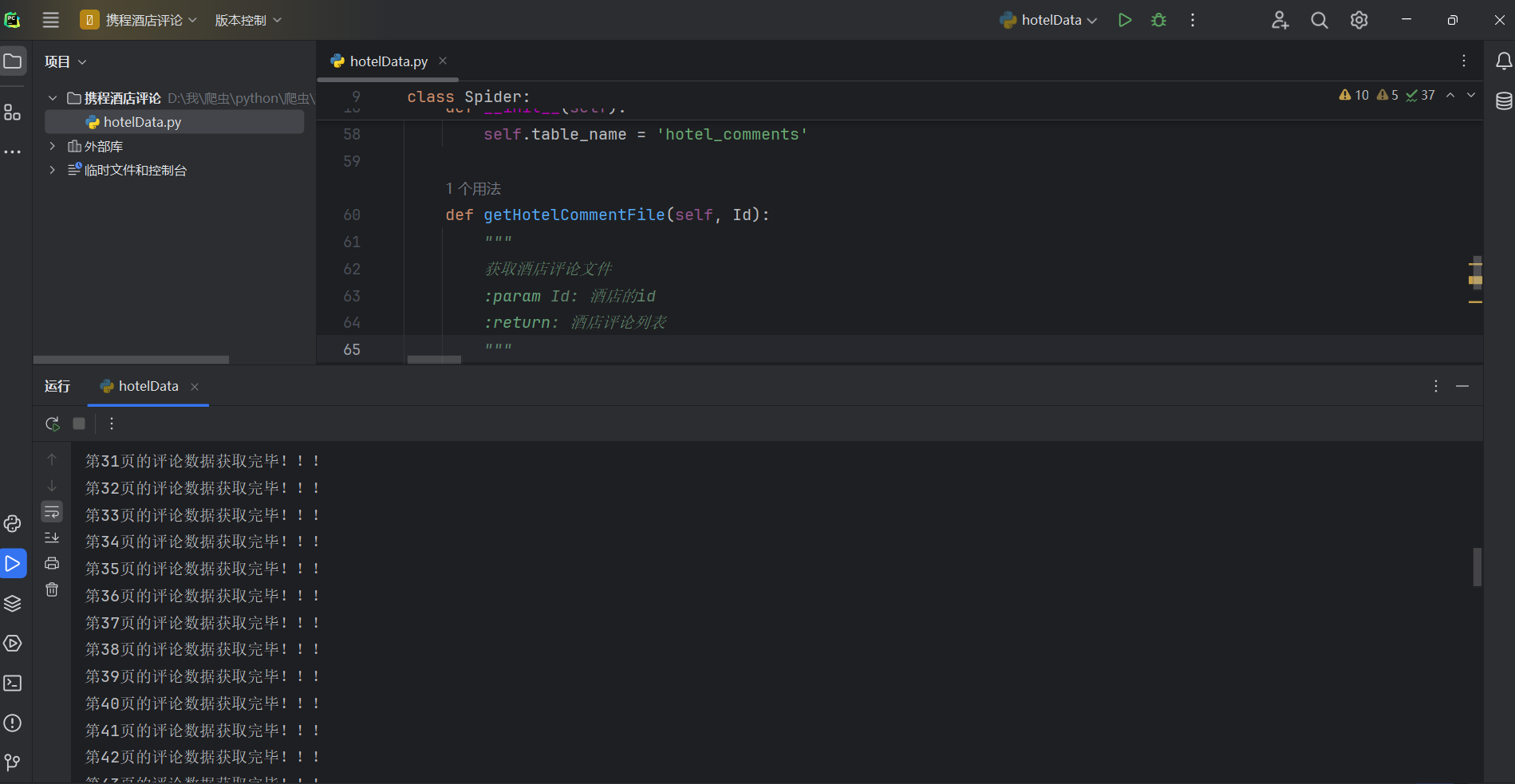
5. 运行效果
运行程序后,输入酒店ID(例如从携程酒店详情页URL中获取的数字),程序开始爬取评论并存入数据库。控制台会输出每页的获取情况以及插入成功的记录数。
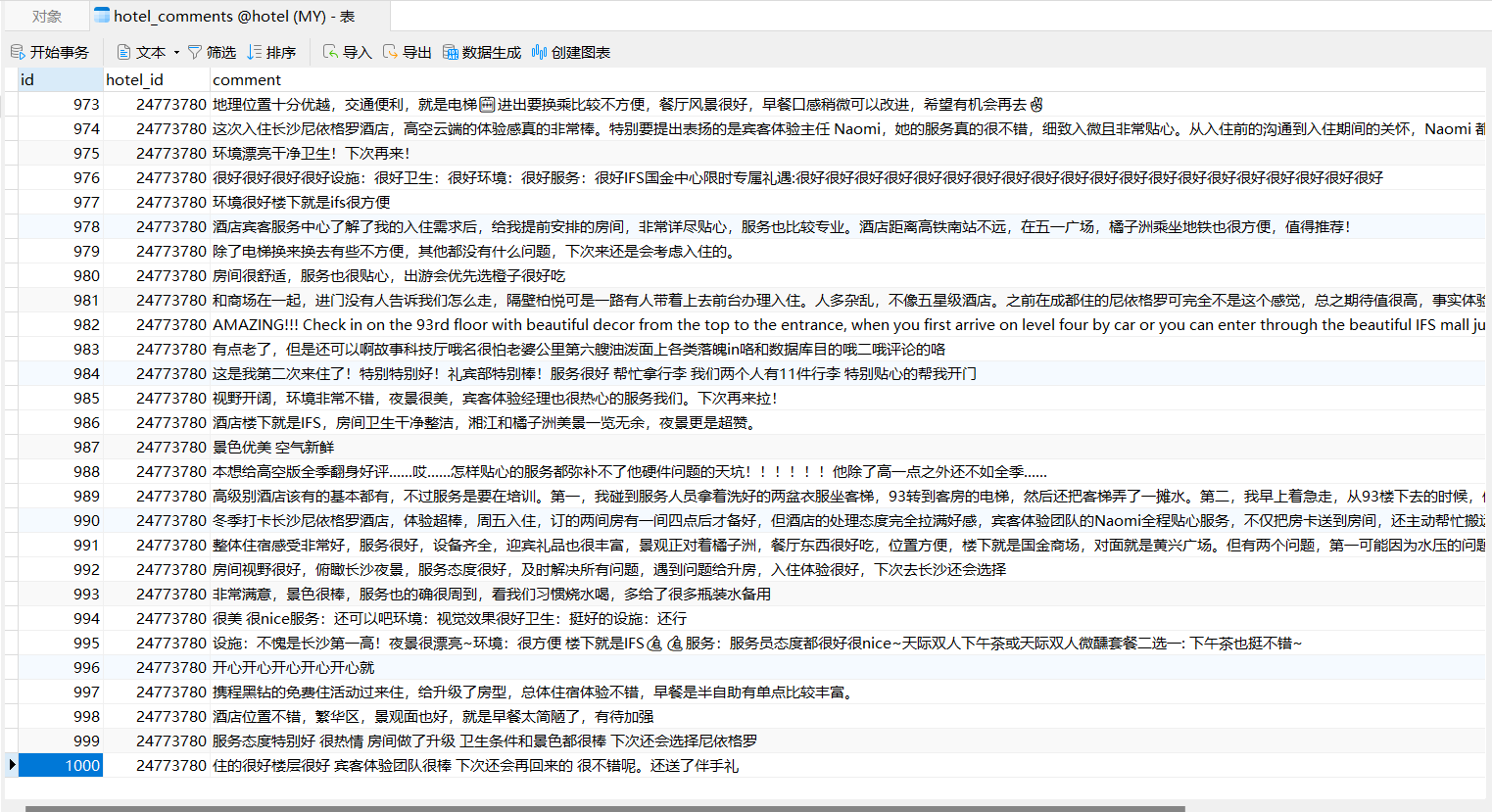
使用MySQL客户端或工具查看数据:
USE hotel;
SELECT * FROM hotel_comments;
可以看到评论内容已被保存。
6. 注意事项与常见问题
6.1 Cookie失效
携程的Cookie有时效性,如果遇到401或403错误,请重新登录携程,在开发者工具中复制新的cookie替换代码中的self.headers。
6.2 请求频率过高
代码中已经加入了随机延时,但如果还是被封IP,可以增加延时时间,或者使用代理IP。
6.3 数据库连接错误
- 确保MySQL服务已启动。
- 检查用户名、密码、主机是否正确。
- 如果MySQL安装在非默认端口,需要在
pymysql.connect中添加port参数。
6.4 编码问题
使用utf8mb4字符集可以避免某些特殊字符导致的插入错误。
7. 完整代码整合
为了方便大家复制,以下是整合后的完整代码(注意替换cookie和数据库密码):
import pymysql
import requests
import time
import random
import json
from requests.exceptions import RequestException
class Spider:
def __init__(self):
self.url = 'https://m.ctrip.com/restapi/soa2/33278/getHotelCommentList'
self.headers = {
'accept': 'application/json',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'no-cache',
'content-type': 'application/json',
# 替换成自己的cookie
'cookie': '',
'origin': 'https://hotels.ctrip.com',
'pragma': 'no-cache',
'priority': 'u=1, i',
'referer': 'https://hotels.ctrip.com/',
'sec-ch-ua': '"Not(A:Brand";v="8", "Chromium";v="144", "Microsoft Edge";v="144"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/144.0.0.0 Safari/537.36 Edg/144.0.0.0',
'x-ctx-country': 'CN',
'x-ctx-currency': 'CNY',
'x-ctx-locale': 'zh-CN',
'x-ctx-ubt-pageid': '10650171194',
'x-ctx-ubt-pvid': '5',
'x-ctx-ubt-sid': '15',
'x-ctx-ubt-vid': '1766813870908.08e9zbNAFVFP',
'x-ctx-wclient-req': 'da863c9181a16db6375013e79f3520dc'
}
self.params = {
'_fxpcqlniredt': '09031109216141753464',
'x-traceID': '09031109216141753464-1768914287515-4391436'
}
self.commentList = []
self.connect = pymysql.connect(
host='localhost',
user='root',
password='your_password', # 修改为你的数据库密码
charset='utf8mb4'
)
self.cursor = self.connect.cursor()
self.db_name = 'hotel'
self.table_name = 'hotel_comments'
def getHotelCommentFile(self, Id):
for i in range(1, 101):
data_dict = {
"hotelId": Id,
"pageIndex": i,
"pageSize": 10,
"repeatComment": 1,
"needStaticInfo": False,
"functionOptions": ["integratedTopComment", "ctripIntegratedExpediaTaList"],
"head": {
"cid": "1766813870908.08e9zbNAFVFP",
"ctok": "",
"cver": "0",
"lang": "01",
"sid": "",
"syscode": "09",
"auth": "",
"xsid": "",
"extension": [],
"platform": "PC",
"bu": "HBU",
"group": "ctrip",
"aid": "",
"ouid": "",
"locale": "zh-CN",
"timezone": "8",
"currency": "CNY",
"pageId": "102003",
"vid": "1766813870908.08e9zbNAFVFP",
"guid": "",
"isSSR": False
}
}
data = json.dumps(data_dict, ensure_ascii=False)
try:
time.sleep(random.uniform(2, 3))
response = requests.post(self.url, headers=self.headers, params=self.params, data=data)
if response.status_code == 200:
self.commentList.append(response.json())
print(f'第{i}页的评论数据获取完毕!!!')
else:
print(f'状态码为: {response.status_code}')
print(f'网页内容为: {response.text}')
except RequestException as request_error:
print(f'网络异常: {request_error}')
time.sleep(random.uniform(2.5, 3.5))
except Exception as e:
print(f'其他异常: {e}')
time.sleep(random.uniform(3, 4))
return self.commentList
def parseComment(self, Comments):
commentContents = []
for Comment in Comments:
commentList = Comment['data']['commentList']
for comment in commentList:
commentContents.append(comment['content'])
return commentContents
def createMysqlDbTable(self):
create_db_sql = f"CREATE DATABASE IF NOT EXISTS {self.db_name} CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;"
try:
self.cursor.execute(create_db_sql)
print(f"数据库 {self.db_name} 已存在或创建成功。")
except Exception as e:
print(f"创建数据库失败: {e}")
raise
self.cursor.execute(f"USE {self.db_name}")
create_table_sql = f"""
CREATE TABLE IF NOT EXISTS {self.table_name} (
id INT AUTO_INCREMENT PRIMARY KEY,
hotel_id INT NOT NULL,
comment TEXT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
"""
try:
self.cursor.execute(create_table_sql)
print(f"数据表 {self.table_name} 已存在或创建成功。")
except Exception as e:
print(f"创建数据表失败: {e}")
raise
def saveToMysql(self, hotel_id, contents):
insert_sql = f"INSERT INTO {self.table_name} (hotel_id, comment) VALUES (%s, %s);"
try:
data_to_insert = [(hotel_id, content) for content in contents]
self.cursor.executemany(insert_sql, data_to_insert)
self.connect.commit()
print(f"成功插入 {len(contents)} 条记录到数据库。")
except Exception as e:
self.connect.rollback()
print(f"批量插入失败: {e}")
def start(self, hotel_id):
self.createMysqlDbTable()
comment_responses = self.getHotelCommentFile(hotel_id)
if comment_responses:
comment_contents = self.parseComment(comment_responses)
self.saveToMysql(hotel_id, comment_contents)
def close(self):
self.cursor.close()
self.connect.close()
if __name__ == '__main__':
hotelId = int(input('请输入酒店id: '))
hotelComment = Spider()
try:
hotelComment.start(hotelId)
except Exception as e:
print(f"程序运行出错: {e}")
finally:
hotelComment.close()
print('所有评论信息已经插入到数据表中!!!')
8. 总结
通过这个项目,我们完整地实现了一个爬虫程序,从分析接口、构造请求、处理响应,到最终将数据持久化到数据库。希望这个教程能帮助你理解爬虫的基本流程和数据库操作。
如果在运行过程中遇到任何问题,欢迎在评论区留言交流!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)