Python数据分析入门:从零开始玩转数据
大家好,我是Silas,在数据深耕多年。今天咱们来聊聊Python数据分析——这个听起来有点高大上,但实际上特别接地气的技能。 你有没有过这样的经历:老板扔给你一堆Excel表格,让你“分析分析”;或者自己想做个小项目,却不知道从哪下手处理数据?别担心,Python数据分析就是你的瑞士军刀,简单、强大,而且特别好玩。
01
为什么是Python?

在开始之前,我们先聊聊为什么选择Python。想象一下,数据分析就像做菜:
-
Excel像是微波炉——简单快捷,热个剩饭还行,但想做满汉全席就力不从心了
-
R语言像是专业烤箱——统计功能强大,但学起来门槛不低
-
Python呢?它就是个现代化厨房,什么工具都有,而且特别容易上手
Python在数据分析领域的三大优势:
-
简单易学:语法接近英语,读起来像在读伪代码
-
生态丰富:有NumPy、Pandas、Matplotlib等神器加持
-
一专多能:数据分析、网站开发、人工智能,一个Python全搞定
02
数据分析的“三驾马车”

正式开始前,咱们得认识三个最重要的工具包。我把它们叫做“数据分析的三驾马车”:
1. NumPy:数据的“集装箱”
NumPy是数值计算的基础,它提供了多维数组对象。想象一下,Excel表格是个二维的,NumPy可以创建三维、四维甚至更高维度的“数据集装箱”。
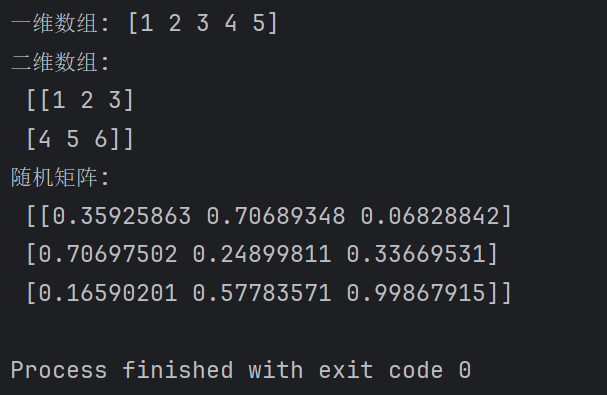
import numpy as np
arr1 = np.array([1, 2, 3, 4, 5])
print("一维数组:", arr1)
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print("二维数组:\n", arr2)
zeros_arr = np.zeros((3, 3)) # 3x3的全0矩阵
ones_arr = np.ones((2, 4)) # 2x4的全1矩阵
random_arr = np.random.rand(3, 3) # 3x3的随机数矩阵
print("随机矩阵:\n", random_arr)返回如下:

2. Pandas:数据的“瑞士军刀”
如果说NumPy是集装箱,那Pandas就是集装箱码头上的龙门吊——专门用来搬运、整理、分析数据。
Pandas有两个核心数据结构:
-
Series:一维带标签的数组,像Excel中的一列数据
-
DataFrame:二维表格,这才是我们最常用的
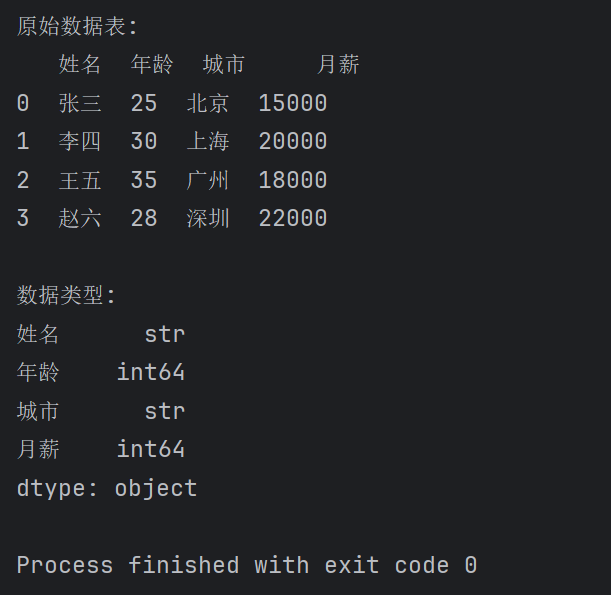
import pandas as pd
data = {
'姓名': ['张三', '李四', '王五', '赵六'],
'年龄': [25, 30, 35, 28],
'城市': ['北京', '上海', '广州', '深圳'],
'月薪': [15000, 20000, 18000, 22000]
}
df = pd.DataFrame(data)
print("原始数据表:")
print(df)
print("\n数据类型:")
print(df.dtypes)返回如下:
3. Matplotlib:数据的“化妆师”
数据再好看,不会展示也是白搭。Matplotlib就是让数据“颜值飙升”的工具。
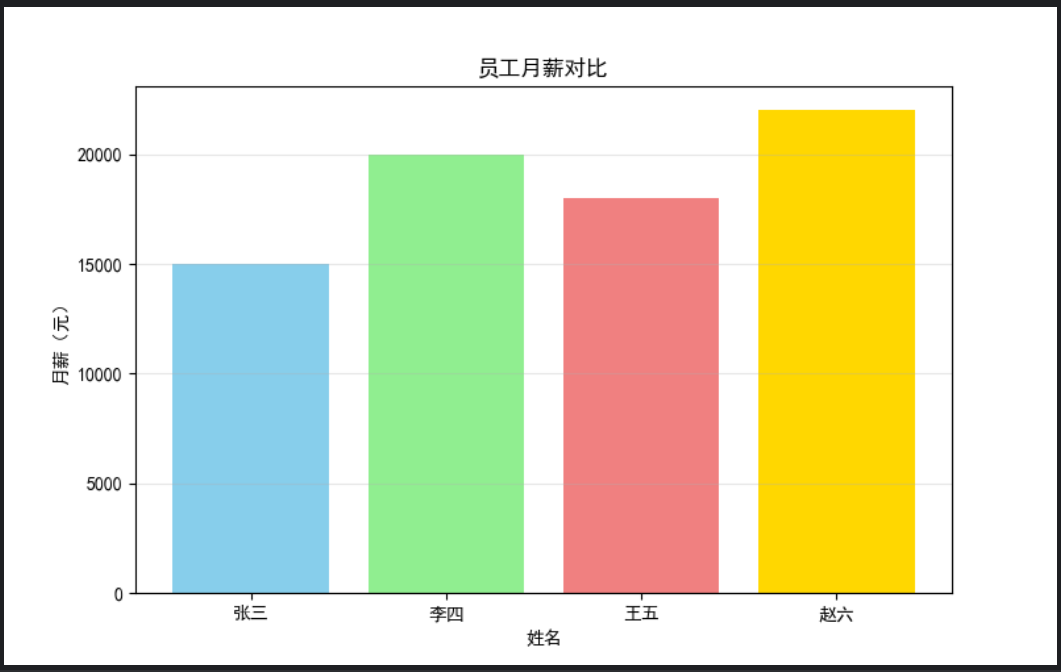
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(8, 5))
plt.bar(df['姓名'], df['月薪'], color=['skyblue', 'lightgreen', 'lightcoral', 'gold'])
plt.title('员工月薪对比')
plt.xlabel('姓名')
plt.ylabel('月薪(元)')
plt.grid(axis='y', alpha=0.3)
plt.show()返回如下:
当然,上述这些代码之间是存在耦合的,建议使用jupyter notebook来学习,或者交互式命令行执行,像pycharm这类集成开发平台的话需要将前置代码一并执行。
03
实战演练:分析电商销售数据

光说不练假把式,咱们来一个完整的实战案例。假设你是一家电商公司的数据分析师,老板给了你一份销售数据,让你分析分析。
第一步:加载数据
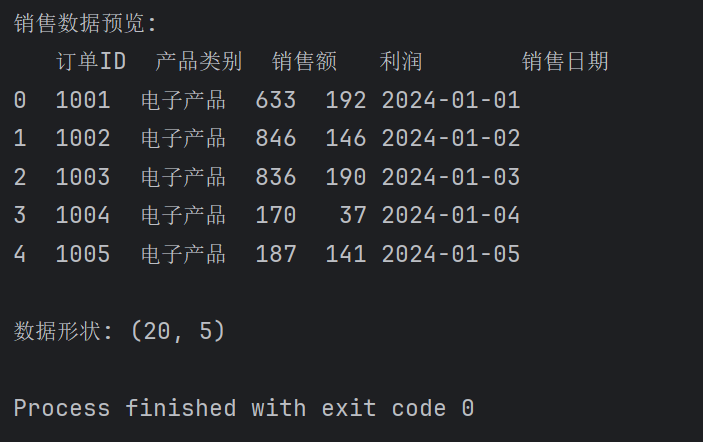
import numpy as np
import pandas as pd
sales_data = {'订单ID': range(1001, 1021), # 生成1001-1020共20个订单ID
'产品类别': ['电子产品']*5 + ['服装']*5 + ['图书']*5 + ['食品']*5, # 每种类别各5个,总计20个
'销售额': np.random.randint(100, 1000, 20), # 20个100-999的随机销售额
'利润': np.random.randint(20, 200, 20), # 20个20-199的随机利润
'销售日期': pd.date_range('2024-01-01', periods=20, freq='D') # 2024-01-01开始的20天日期
}
sales_df = pd.DataFrame(sales_data)
print("销售数据预览:")
print(sales_df.head()) # 只看前5行
print(f"\n数据形状: {sales_df.shape}") # 查看数据维度(应该输出(20,5))返回如下:
第二步:数据清洗与探索
数据往往不是完美的,我们需要先“打扫卫生”:
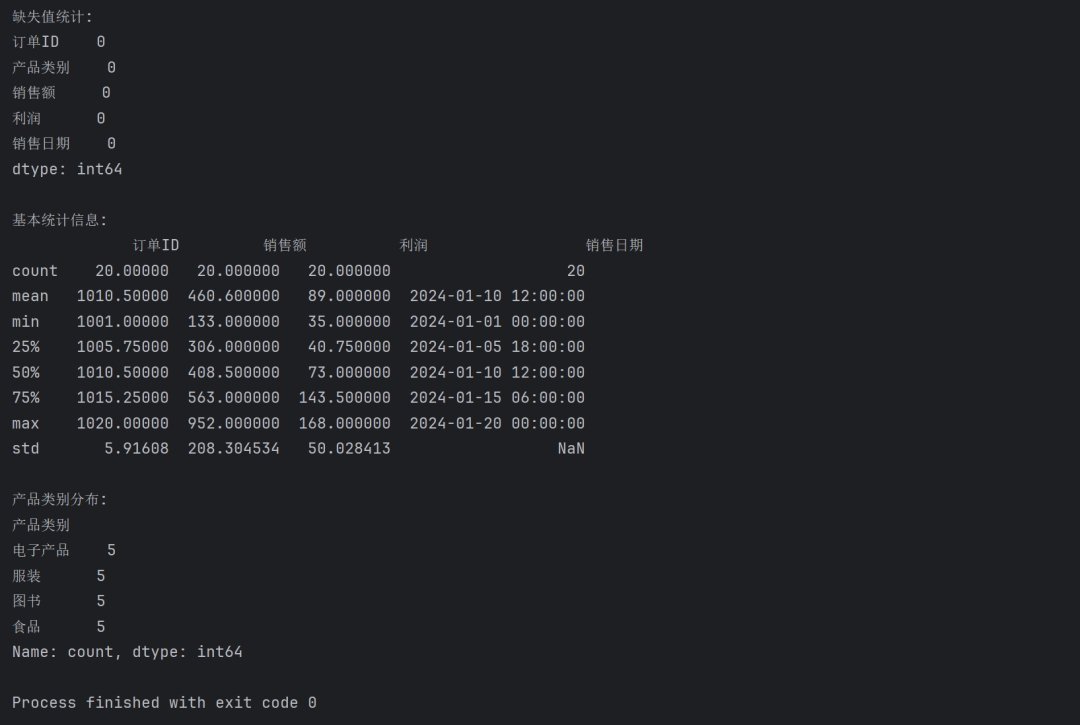
print("缺失值统计:")
print(sales_df.isnull().sum())
print("\n基本统计信息:")
print(sales_df.describe())
print("\n产品类别分布:")
print(sales_df['产品类别'].value_counts())返回如下:
第三步:数据分析
现在是重头戏——真正开始分析了:
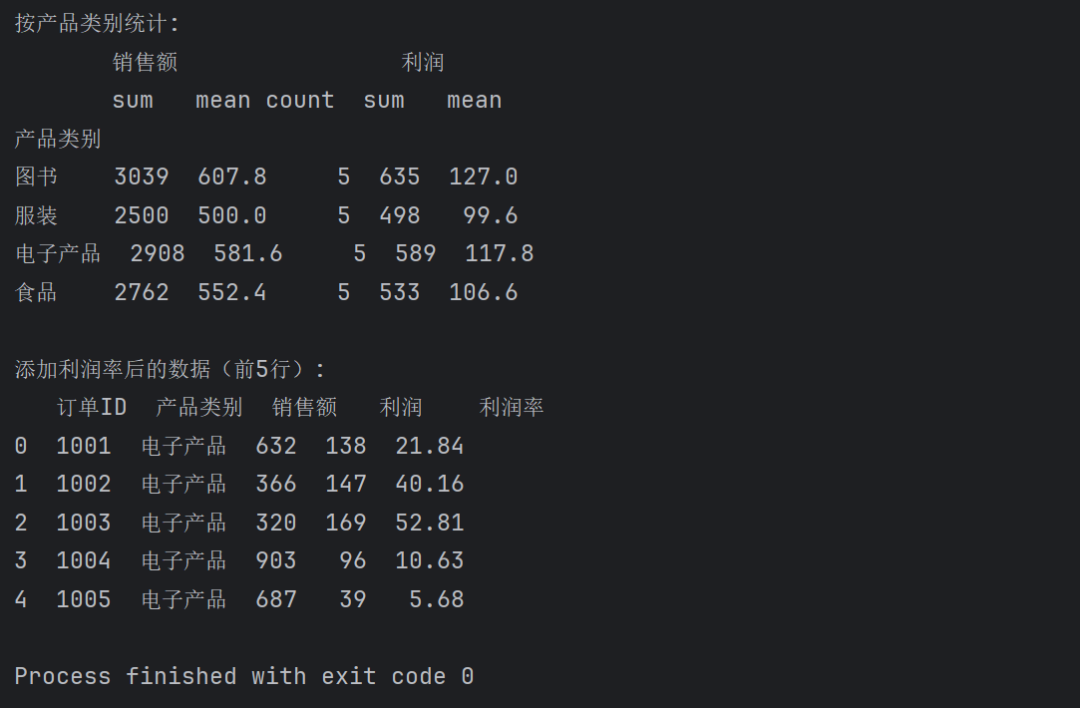
# 按产品类别聚合统计
category_stats = sales_df.groupby('产品类别').agg({
'销售额': ['sum', 'mean', 'count'], # 销售额总和、均值、订单数
'利润': ['sum', 'mean'] # 利润总和、均值
}).round(2) # 保留2位小数
print("按产品类别统计:")
print(category_stats)
# 计算利润率并添加到原数据框
sales_df['利润率'] = (sales_df['利润'] / sales_df['销售额'] * 100).round(2)
print("\n添加利润率后的数据(前5行):")
print(sales_df[['订单ID', '产品类别', '销售额', '利润', '利润率']].head())返回如下:
第四步:数据可视化
一图胜千言,咱们用图表说话:
import matplotlib.pyplot as plt
# 设置matplotlib中文显示(避免乱码,核心配置)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体显示中文
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# 创建2x2子图布局,修正所有变量名空格问题
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
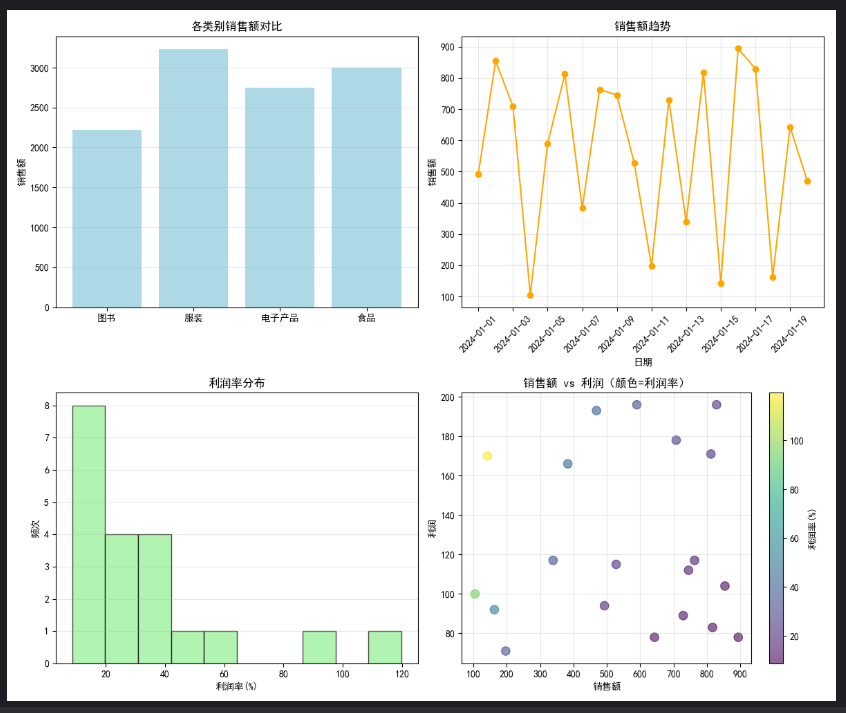
# 子图1:各类别销售额对比(柱状图)
category_sales = sales_df.groupby('产品类别')['销售额'].sum() # 修正变量名空格
axes[0, 0].bar(category_sales.index, category_sales.values, color='lightblue')
axes[0, 0].set_title('各类别销售额对比', fontsize=12)
axes[0, 0].set_ylabel('销售额', fontsize=10)
axes[0, 0].grid(axis='y', alpha=0.3) # 添加网格,更易读
# 子图2:销售额趋势(折线图)
axes[0, 1].plot(sales_df['销售日期'], sales_df['销售额'], marker='o', linestyle='-', color='orange') # 修正变量名空格
axes[0, 1].set_title('销售额趋势', fontsize=12)
axes[0, 1].set_xlabel('日期', fontsize=10)
axes[0, 1].set_ylabel('销售额', fontsize=10)
axes[0, 1].tick_params(axis='x', rotation=45)
axes[0, 1].grid(alpha=0.3) # 添加网格
# 子图3:利润率分布(直方图)
axes[1, 0].hist(sales_df['利润率'], bins=10, edgecolor='black', alpha=0.7, color='lightgreen')
axes[1, 0].set_title('利润率分布', fontsize=12)
axes[1, 0].set_xlabel('利润率(%)', fontsize=10)
axes[1, 0].set_ylabel('频次', fontsize=10)
axes[1, 0].grid(axis='y', alpha=0.3)
# 子图4:销售额 vs 利润(散点图,按利润率着色)
scatter = axes[1, 1].scatter(
sales_df['销售额'], sales_df['利润'], # 修正变量名空格
c=sales_df['利润率'], cmap='viridis', alpha=0.6, s=80# 增大点的尺寸,更清晰
)
axes[1, 1].set_title('销售额 vs 利润(颜色=利润率)', fontsize=12)
axes[1, 1].set_xlabel('销售额', fontsize=10)
axes[1, 1].set_ylabel('利润', fontsize=10)
axes[1, 1].grid(alpha=0.3)
plt.colorbar(scatter, ax=axes[1, 1], label='利润率(%)') # 颜色条标签
# 调整子图间距,避免重叠
plt.tight_layout()
# 显示图表
plt.show()返回如下:
第五步:深入分析
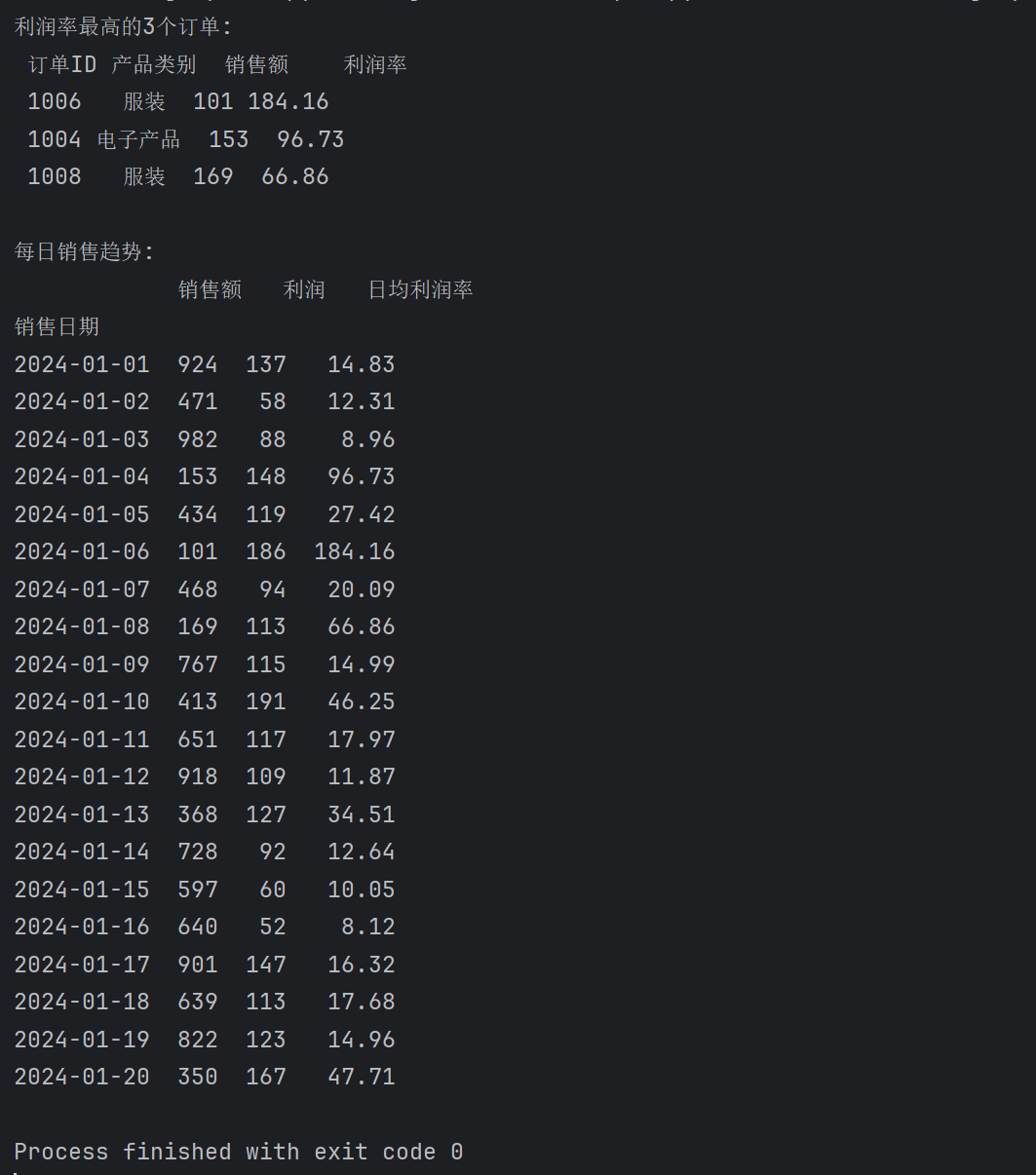
# 筛选利润率最高的3个订单
high_profit = sales_df.nlargest(3, '利润率')[['订单ID', '产品类别', '销售额', '利润率']]
print("利润率最高的3个订单:")
# 强制对齐输出(无行索引,更整洁)
print(high_profit.to_string(index=False))
# 按日期聚合销售额/利润,计算日均利润率
daily_sales = sales_df.groupby('销售日期').agg({'销售额': 'sum', '利润': 'sum'})
daily_sales['日均利润率'] = (daily_sales['利润'] / daily_sales['销售额'] * 100).round(2)
print("\n每日销售趋势:")
# 对齐输出每日数据
print(daily_sales.round(2).to_string())返回如下:
04
实际应用场景

数据分析不是纸上谈兵,它在实际工作中大有用处:
场景一:用户行为分析
假设你运营一个App,可以用数据分析:
-
用户最喜欢在什么时间使用App
-
哪些功能最受欢迎
-
用户流失的原因是什么
场景二:销售预测
基于历史销售数据,可以:
-
预测下个月的销售额
-
找出销售旺季和淡季
-
优化库存管理
场景三:市场调研
通过爬虫获取竞品数据后:
-
分析竞品定价策略
-
了解市场趋势
-
发现新的市场机会
05
学习路线建议

如果你觉得这篇文章有意思,想深入学习,我建议的路线是:
1、基础阶段(1-2周)
-
Python基础语法
-
NumPy数组操作
-
Pandas数据处理
2、进阶阶段(2-3周)
-
数据可视化(Matplotlib/Seaborn)
-
数据清洗技巧
-
基础统计分析
3、实战阶段(持续进行)
-
找真实数据集练习(Kaggle、天池等平台)
-
参与数据分析比赛
-
解决工作中的实际问题
06
总结

数据分析就像侦探破案——数据是线索,分析工具是放大镜,而你就是那个找出真相的侦探。Python提供了全套的“侦探工具包”,让你能够:
-
快速上手:语法简单,学习曲线平缓
-
高效处理:Pandas能轻松处理百万级数据
-
直观展示:Matplotlib让数据“会说话”
-
无限扩展:从数据分析到机器学习,一路畅通
记住,数据分析的核心不是工具,而是思维。工具只是帮你实现想法的帮手。最好的学习方式就是:找一个你感兴趣的数据集,马上开始动手分析!
最后送给大家一句话:数据不会说谎,但需要有人听懂它的语言。Python就是你和数据对话的最佳翻译官。
小练习:找一份你感兴趣的数据(可以是你的月度开支、运动记录、或者公开的天气数据),用今天学的方法试着分析一下。遇到问题?欢迎在评论区交流!
往期推荐

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)