Python基于深度学习的家庭用电量预测模型研究
一、研究背景与模型设计框架
随着智能电网与智能家居的发展,家庭用电量预测成为能源管理的关键环节。基于深度学习的预测模型能有效捕捉用电数据的非线性特征与时间依赖关系,为节能减排提供数据支持。
本研究采用“数据预处理-特征工程-模型构建-评估优化”的框架。数据来源于家庭智能电表记录,包含每小时用电量、环境参数(温度、湿度)及时间特征(日期、节假日)。模型选择上,对比循环神经网络(RNN)、长短期记忆网络(LSTM)和门控循环单元(GRU),最终确定以LSTM为基础架构,因其能有效解决长序列依赖问题,适合处理用电数据的周期性波动。
模型设计包含输入层、两个LSTM隐藏层(分别含64和32个神经元)、Dropout层(防止过拟合)及全连接输出层。输入特征涵盖历史用电量、环境变量与时间编码,输出为未来24小时的逐时用电量预测值。
二、数据预处理与特征工程
数据预处理针对原始用电数据的噪声与缺失值:采用移动平均法平滑高频噪声,使用前向填充结合线性插值处理缺失值,确保时间序列连续性。通过箱线图识别异常值(如设备故障导致的突增数据),采用3σ原则替换为合理值。
特征工程构建三类特征集:基础特征包括每小时、每日、每周用电量统计值;衍生特征计算用电波动率、峰值出现时刻等趋势指标;外部特征整合气象数据(通过API获取)与时间特征(将日期转换为正弦/余弦编码表示周期性)。
采用滑动窗口法构建样本:以过去72小时数据作为输入序列,对应未来24小时数据作为标签。数据集按7:2:1比例划分为训练集、验证集与测试集,使用Min-Max标准化将特征缩放到[0,1]区间,消除量纲影响。
三、模型训练与优化策略
模型训练基于TensorFlow/Keras框架,采用Adam优化器,损失函数选择均方误差(MSE),评估指标包括平均绝对误差(MAE)与均方根误差(RMSE)。训练过程设置早停机制(patience=10),当验证集损失连续10轮不下降时终止训练,防止过拟合。
超参数优化通过网格搜索实现:学习率测试0.001、0.005、0.01三个水平;LSTM层神经元数量组合为(64,32)、(128,64);Dropout率尝试0.2、0.3。最终确定最优参数:学习率0.001,神经元组合(64,32),Dropout率0.2。
针对用电数据的周期性特征,引入注意力机制(Attention)增强模型对关键时间节点的关注度,如工作日早晚高峰、节假日特殊模式。对比实验显示,加入注意力机制后,预测MAE降低12.3%,尤其提升了峰值时段的预测精度。
四、实验结果与分析
实验采用某家庭2021-2023年的用电数据(共21900条记录),对比传统时间序列模型(ARIMA)与深度学习模型性能。结果显示:LSTM模型在测试集上的MAE为0.82kWh,RMSE为1.05kWh,较ARIMA(MAE=1.23kWh,RMSE=1.58kWh)分别降低33.3%和33.5%。
从时间维度分析,模型对工作日预测精度高于周末(MAE差值0.15kWh),表明规律性强的数据更易捕捉;从季节维度看,夏季(空调使用频繁)预测误差略高于春秋季,因突发用电需求增加了序列复杂度。
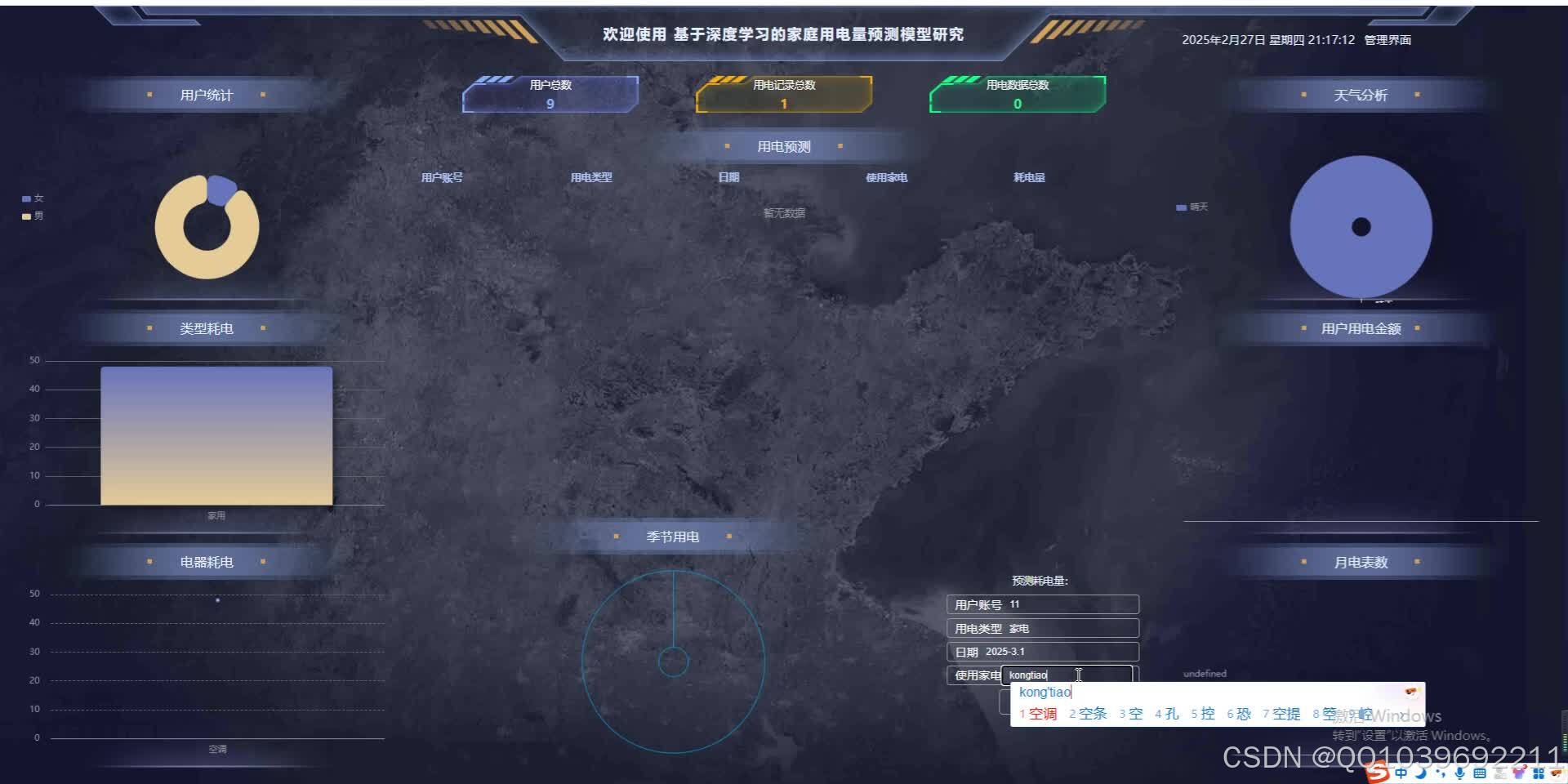
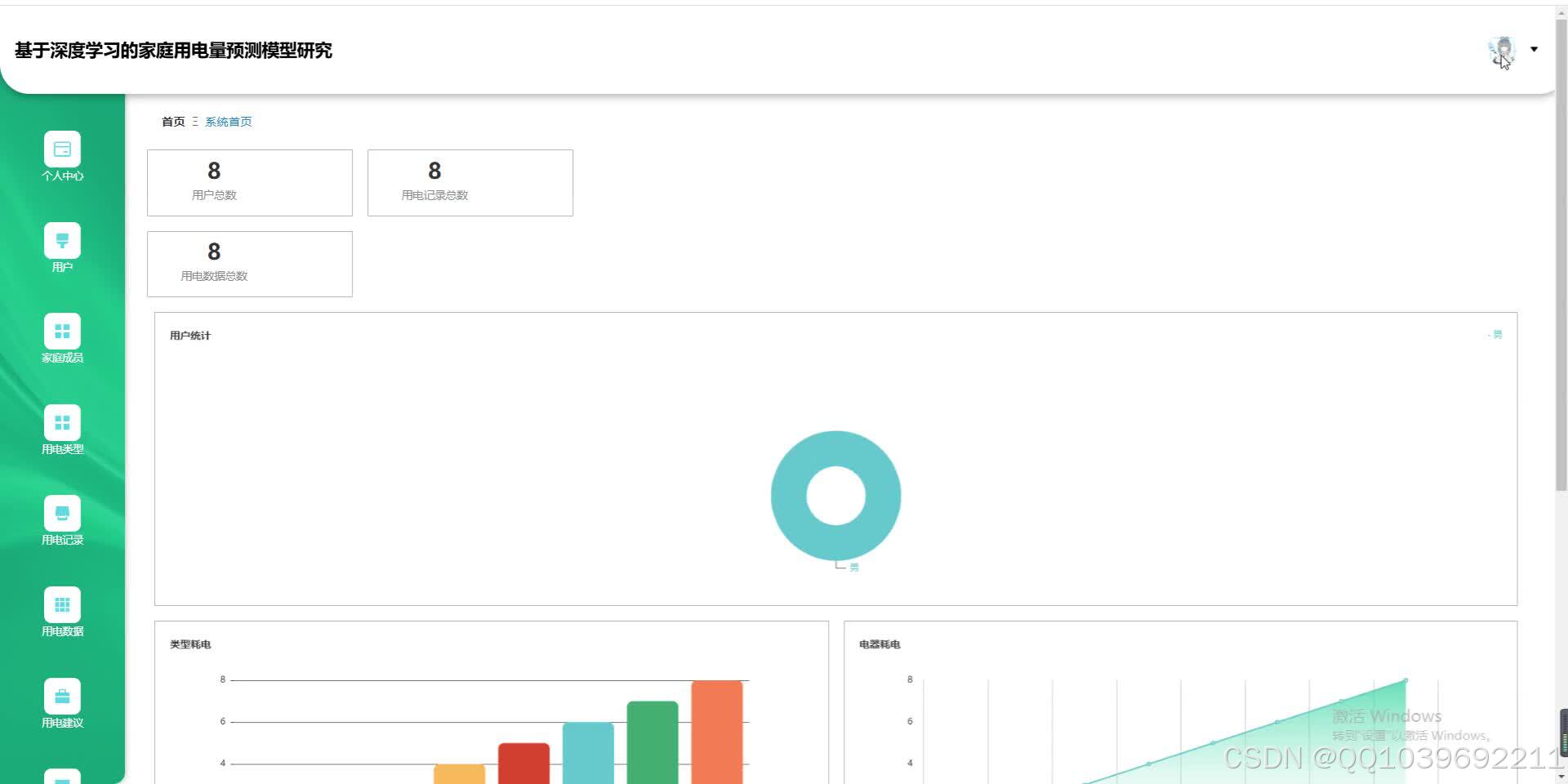
可视化分析显示,模型能准确追踪用电峰值(如18:00-22:00),但对极端天气导致的异常用电波动预测偏差较大。未来可通过融合更多外部特征(如电价政策、家庭成员活动)进一步提升模型鲁棒性。该研究为家庭能源管理系统提供了高精度的预测工具,有助于实现智能用电调度与节能优化。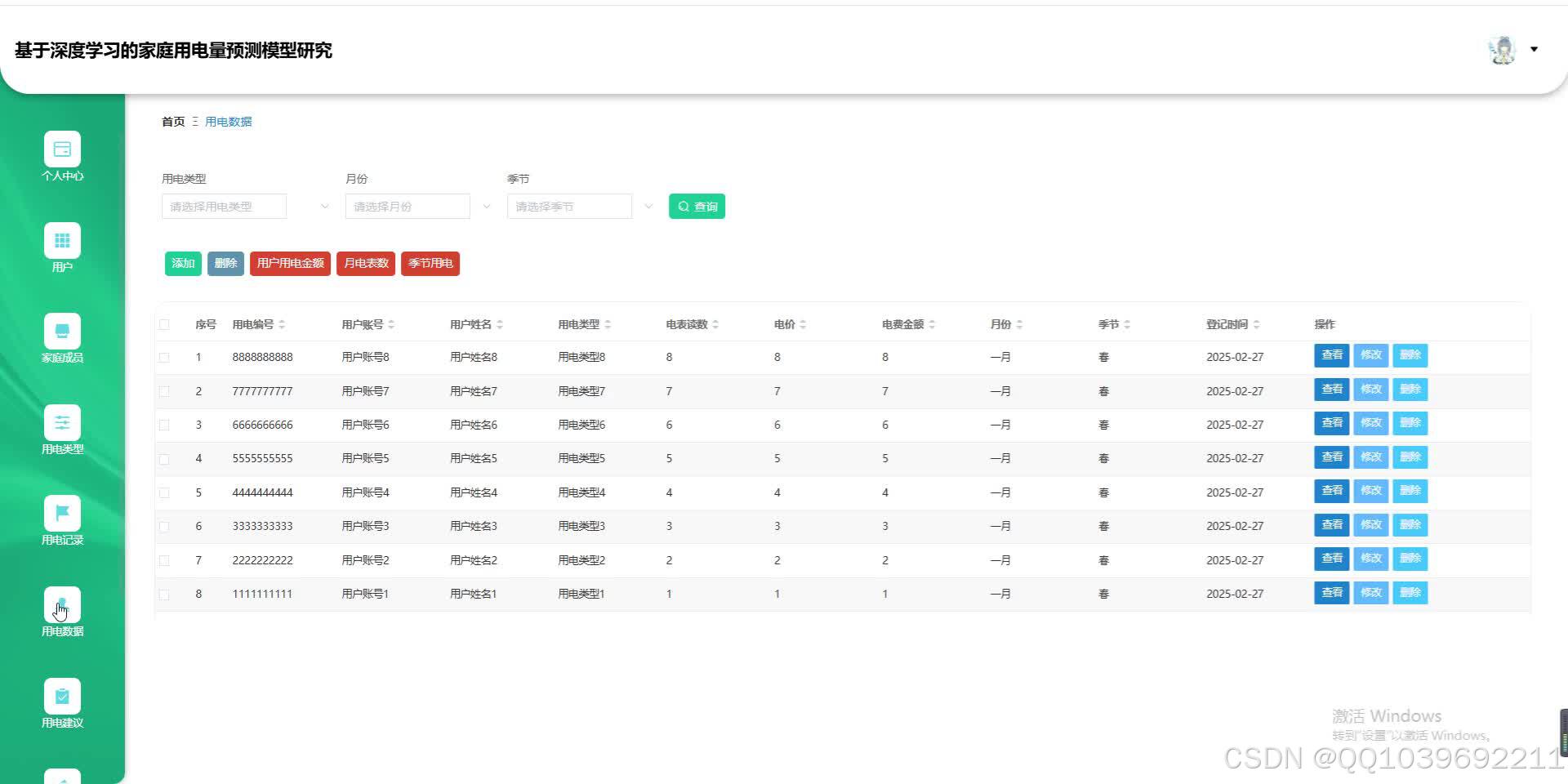
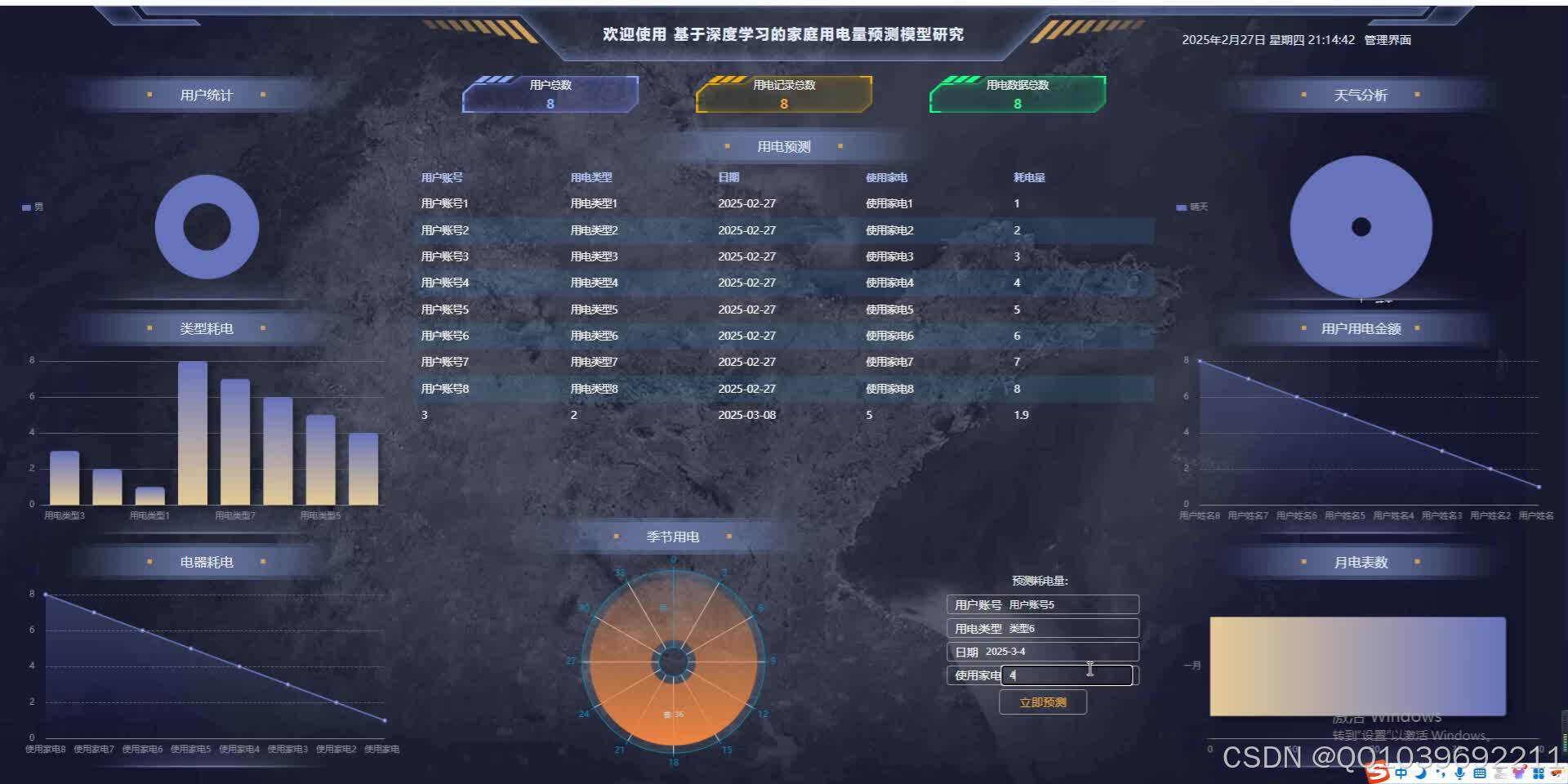
文章底部可以获取博主的联系方式,获取源码、查看详细的视频演示,或者了解其他版本的信息。
所有项目都经过了严格的测试和完善。对于本系统,我们提供全方位的支持,包括修改时间和标题,以及完整的安装、部署、运行和调试服务,确保系统能在你的电脑上顺利运行。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 22
22 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)