YOLOv8目标检测(二)_准备数据集
YOLOv8目标检测(一)_检测流程梳理:YOLOv8目标检测(一)_检测流程梳理_yolo检测流程-CSDN博客
YOLOv8目标检测(二)_准备数据集:YOLOv8目标检测(二)_准备数据集_yolov8 数据集准备-CSDN博客
YOLOv8目标检测(三)_训练模型:YOLOv8目标检测(三)_训练模型_yolo data.yaml-CSDN博客
YOLOv8目标检测(三*)_最佳超参数训练:YOLOv8目标检测(三*)_最佳超参数训练_yolo 为什么要选择yolov8m.pt进行训练-CSDN博客
YOLOv8目标检测(四)_图片推理:YOLOv8目标检测(四)_图片推理-CSDN博客
YOLOv8目标检测(五)_结果文件(run/detrct/train)详解:YOLOv8目标检测(五)_结果文件(run/detrct/train)详解_yolov8 yolov8m.pt可以训练什么-CSDN博客
YOLOv8目标检测(六)_封装API接口:YOLOv8目标检测(六)_封装API接口-CSDN博客
YOLOv8目标检测(七)_AB压力测试:YOLOv8目标检测(七)_AB压力测试-CSDN博客
对整个YOLO目标检测流程有一个大体思路之后,从零开始整理自己需要的数据集
先回顾下YOLOv8训练集文件层级
dataset/
├── train/
│ ├── images/
│ └── labels/
└── val/
├── images/
└── labels/
1.收集视频数据
对于笔者而言,收集视频数据,更容易获得高质量的图片。当然各位读者也可以选择直接用图片。
mixkit官网:Mixkit - Awesome free assets for your next video project
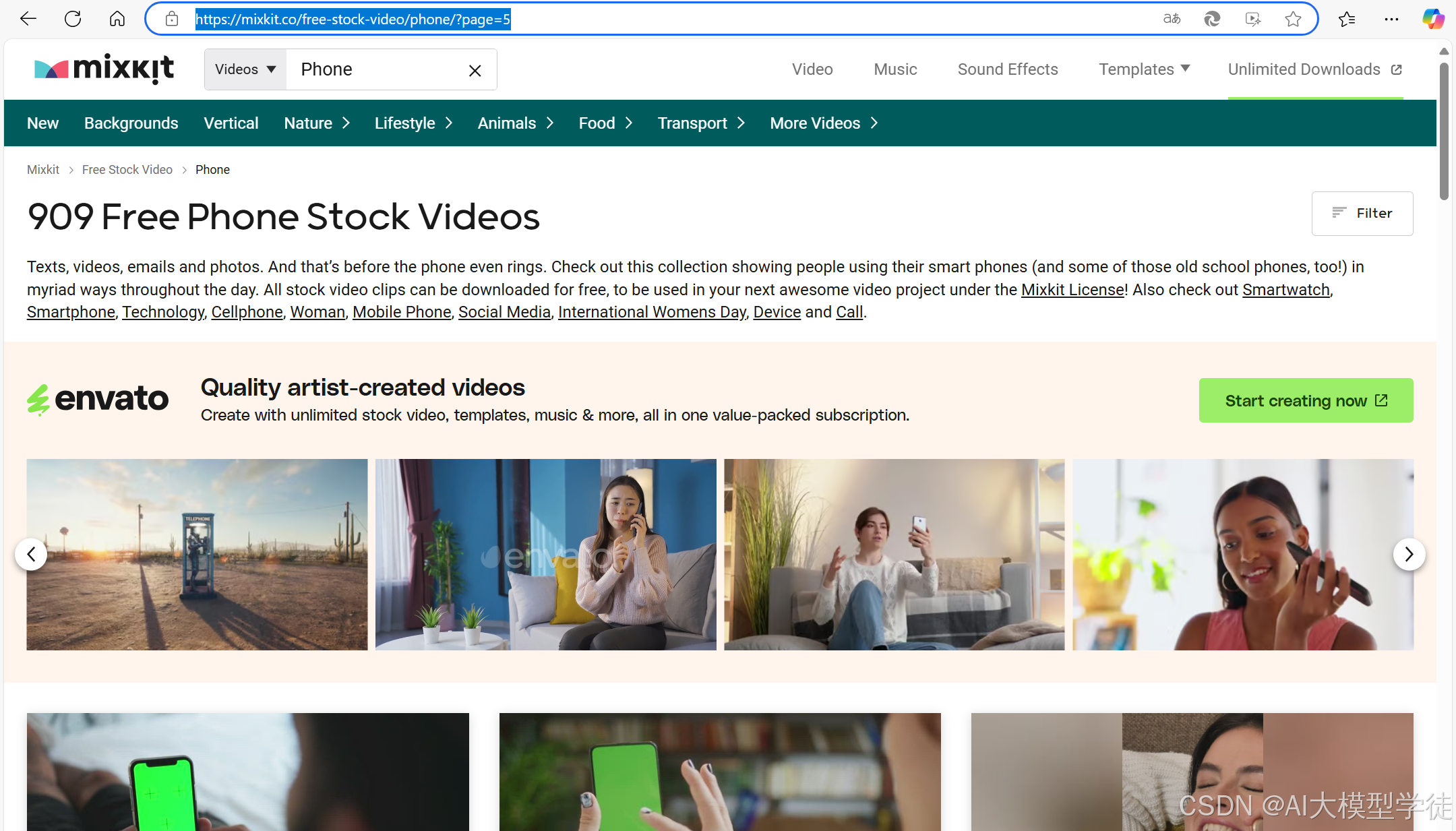
选择自己需要的视频,下载
2.视频抽帧
(1)准备原始视频文件夹
- 注:最好全英文命名
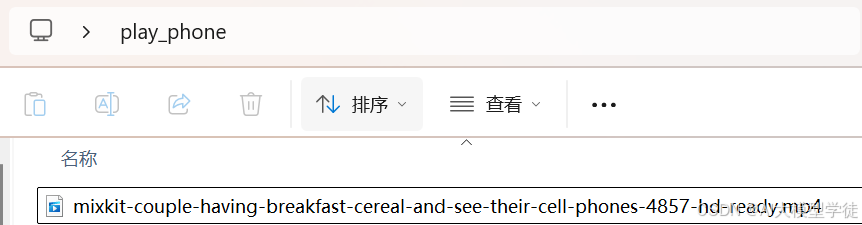
(2)视频重命名
收集的视频名字千奇百怪,不利于我们检查数据及后期的调优,建议大家规范名字。
(3)运行抽帧脚本
将下载好的视频抽帧成图片,下面是笔者常用的视频抽帧脚本
- 注:要修改原始视频文件夹路径
# -----------------------------------------------------------
# 说明:对文件夹中视频进行抽帧,显示当前处理进度.
# -----------------------------------------------------------
import cv2
import os
from concurrent.futures import ThreadPoolExecutor
from tqdm import tqdm
video_folder = r"D:\\Desktop\\play_phone" # 视频文件夹路径
output_folder = r"D:\\Desktop\\play_phone_images" # 保存帧的文件夹路径
save_step = 10 # 间隔帧
# 如果输出文件夹不存在,则创建
if not os.path.exists(output_folder):
os.makedirs(output_folder)
def process_video(video_path):
video = cv2.VideoCapture(video_path)
video_name = os.path.splitext(os.path.basename(video_path))[0] # 提取视频文件名(不包含扩展名)
num = 0 # 计数器
total_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT)) # 获取视频总帧数
with tqdm(total=total_frames // save_step, desc=f"Processing {video_name}") as pbar:
while True:
ret, frame = video.read()
if not ret:
break
num += 1
if num % save_step == 0:
output_path = os.path.join(output_folder, f"{video_name}_{num}.jpg")
cv2.imwrite(output_path, frame)
pbar.update(1) # 更新进度条
video.release() # 释放视频捕获对象
# 遍历文件夹中的所有视频文件
video_files = [os.path.join(video_folder, filename) for filename in os.listdir(video_folder) if filename.endswith(".mp4")]
# 使用多线程处理视频文件
with ThreadPoolExecutor(max_workers=4) as executor: # 根据 CPU 核心数调整 max_workers
executor.map(process_video, video_files)
cv2.destroyAllWindows() # 关闭所有 OpenCV 窗口

运行后文件内容
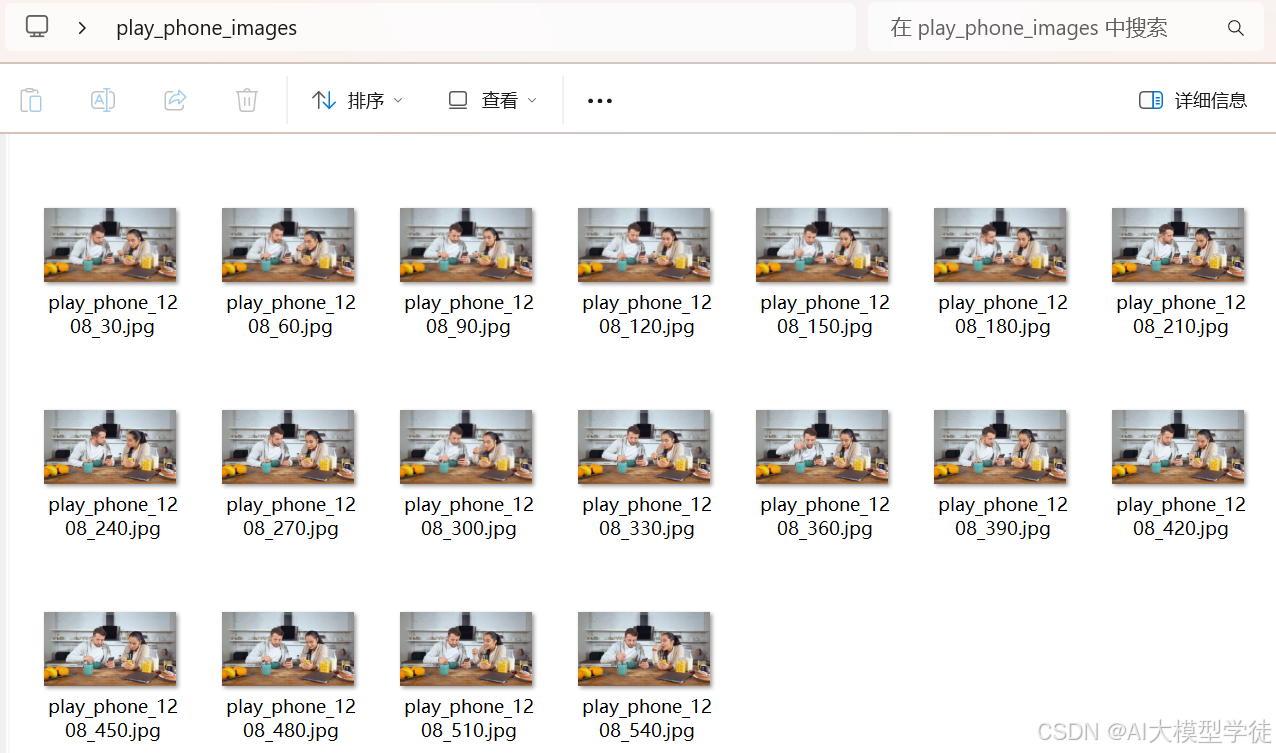
3.图片梳理
剔除低质量的图片,即模糊、部分无目标、混乱的图片。
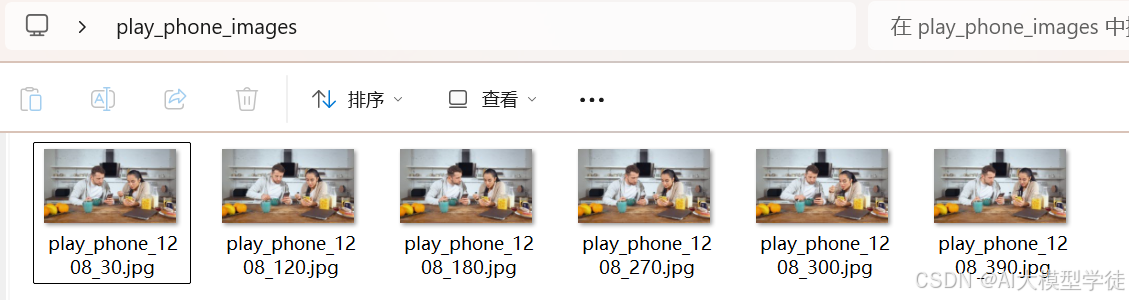
- 注:本次选择的视频只是举例,一个视频是远远不够的,场景、动作、角度都太少。
4.图片标注
YOLOv8训练的标签格式为txt格式,如果标注类别较少建议选择YOLO格式即txt格式,如果PascalVOC格式即xml格式。
本次选择PascalVOC格式,为了给各位读者演示更详细数据处理的流程。
(1)安装labelimg
推荐读者先创建个虚拟环境再安装labelimg
1)创建环境
#创建环境labelimg,前提安装了anaconda,没有需安装
conda create -n labelimg python=3.8 -y
2)激活环境
#激活labelimg环境
conda activate labelimg
3)安装
pip install labelimg
4)命令行打开
labelimg
(2)打开labelimg
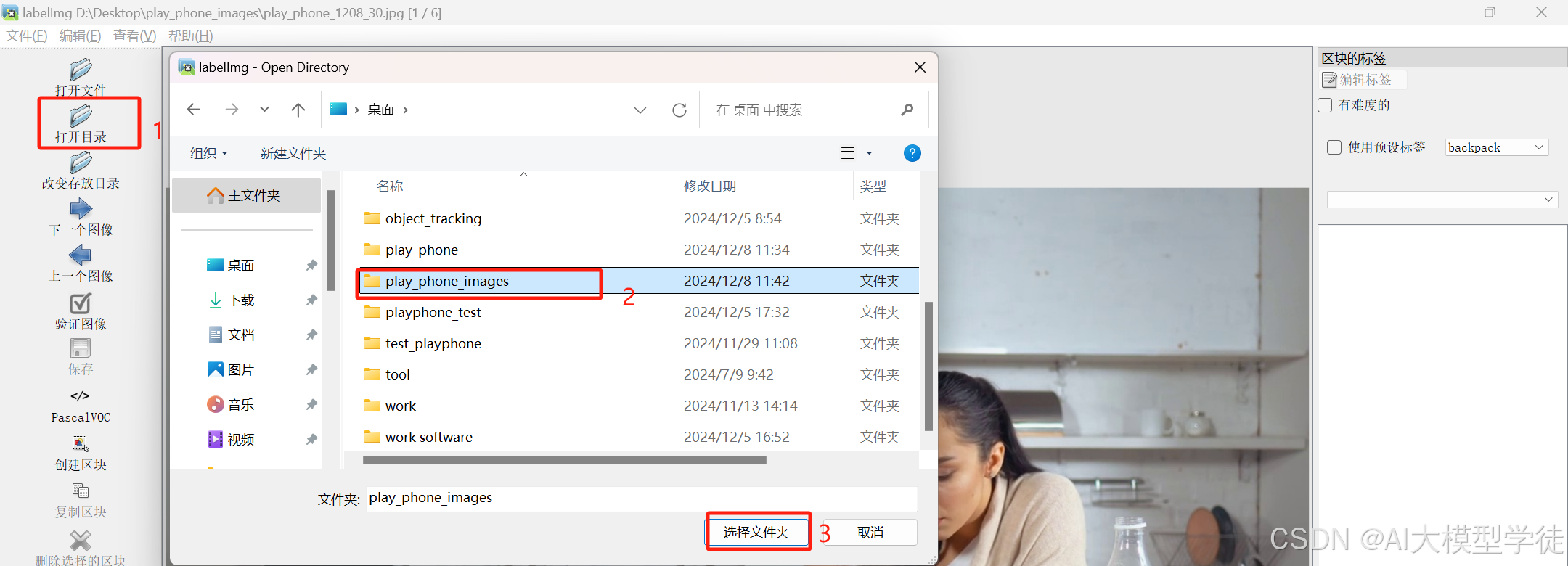
(3)打开目录
打开准备好的图片
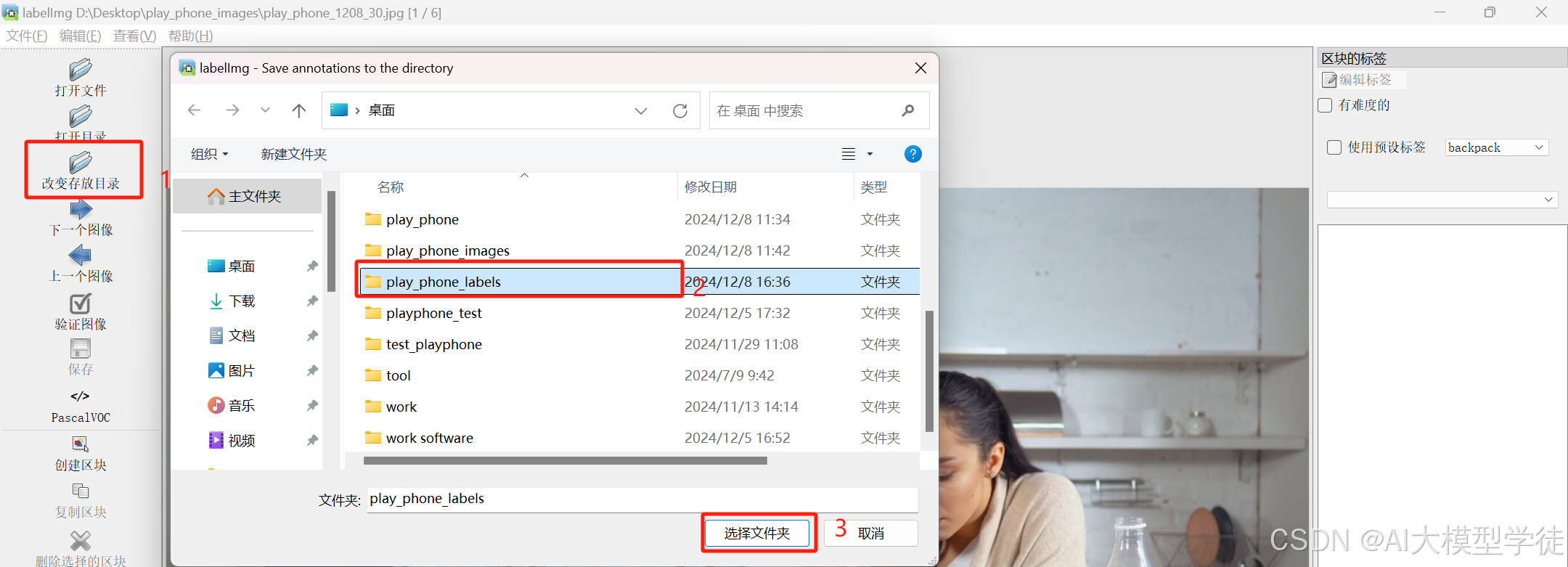
(4)改变存放目录
选择你保存标签的位置
(5)确认格式和自动保存
确认PascalVOC格式,并勾选自动保存

(6)开始标注
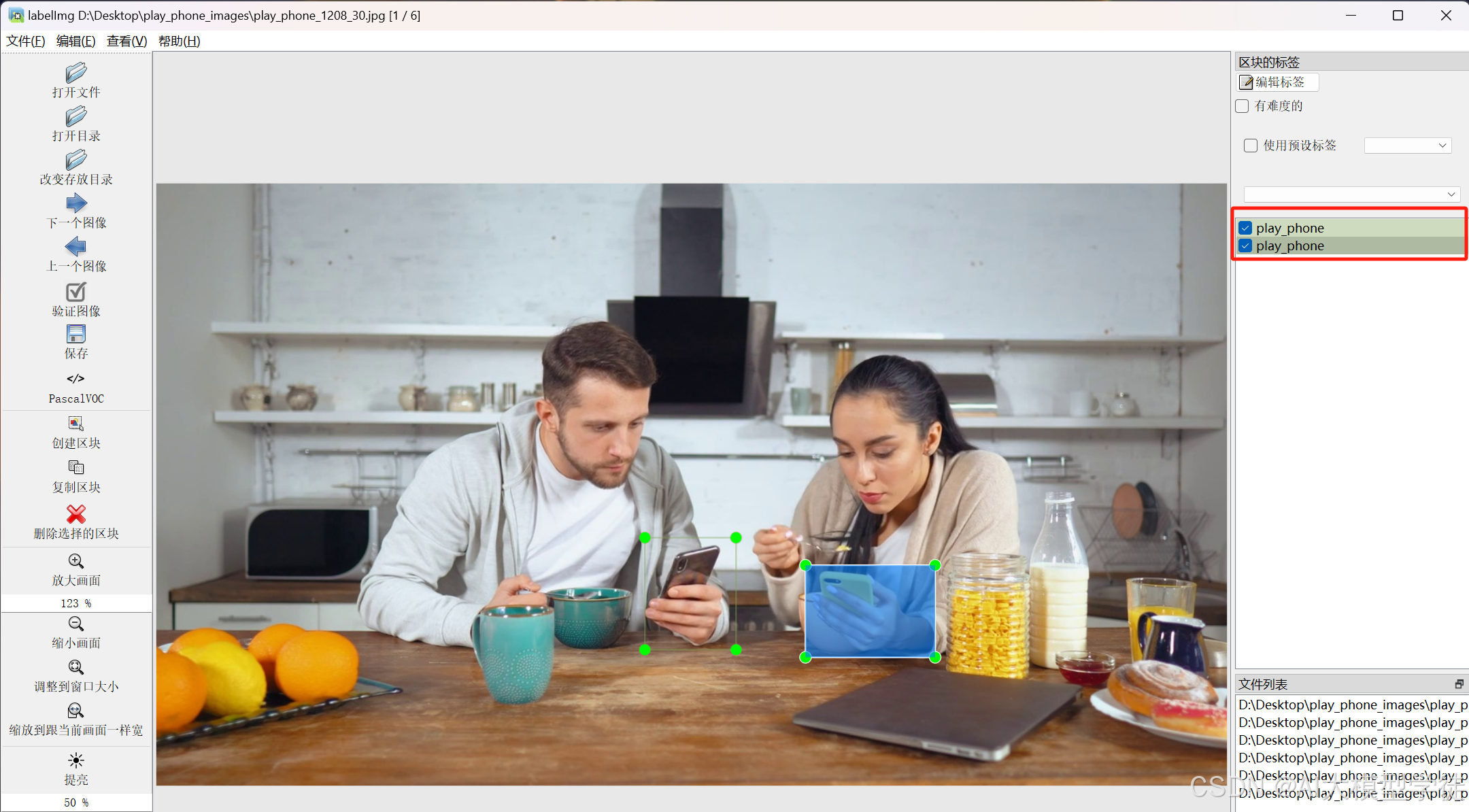
(7)检查标签
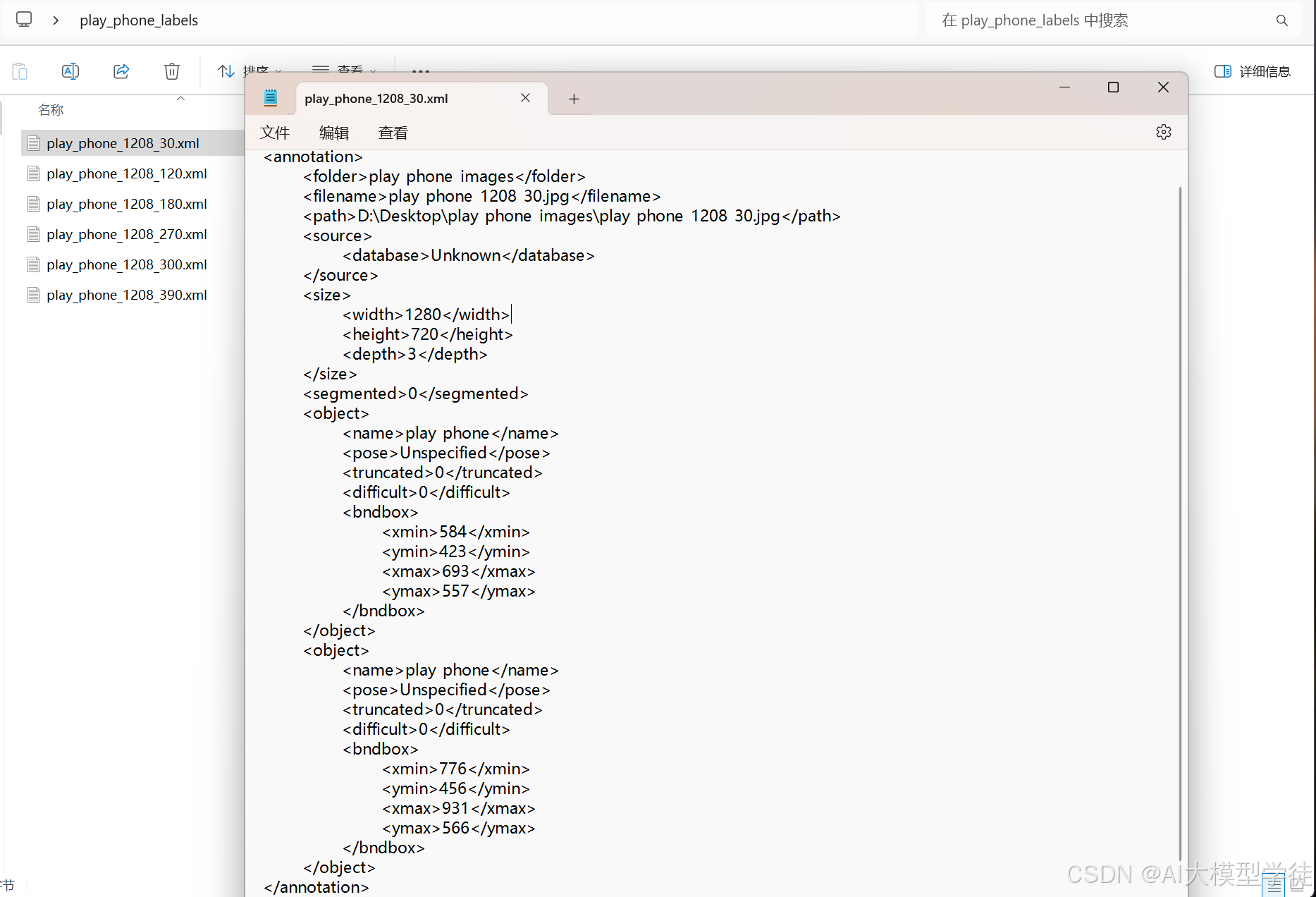
5.标签格式转化
将xml格式标签转为txt格式
为什么要一开始选择xml格式而不是txt格式呢?
对于笔者而言,xml格式标签兼容性和通用性好能被许多标注工具支持、能存储更详细的信息、便于后期格式转换。如果类别单一直接选txt也可以。
# ------------------------------------------------------------------------------------
# 说明:标签将xml转为yolo格式,并将坐标解析失败和不在namelist中的名字放到新的文件夹中
# ------------------------------------------------------------------------------------
import xml.etree.ElementTree as ET
import os
import shutil
from tqdm import tqdm
import sys
class XmlParse:
def __init__(self, file_path):
self.tree = None
self.root = None
self.xml_file_path = file_path
def ReadXml(self):
try:
self.tree = ET.parse(self.xml_file_path)
self.root = self.tree.getroot()
except Exception as e:
print(f"Parse XML failed for {self.xml_file_path}! Error: {e}")
return None
return self.tree
def parse_dimension(value, file_name, field_name):
"""解析尺寸字段,确保其为浮点数,并打印调试信息"""
try:
value = value.strip()
return float(value)
except ValueError:
print(f"Warning: Could not parse dimension '{field_name}' with value '{value}' in file {file_name}.")
return None
def xml2txt(xml, labels, name_list, unmatched_xml_dir):
xml_files = sorted(os.listdir(xml))
if not os.path.exists(labels):
os.mkdir(labels)
if not os.path.exists(unmatched_xml_dir):
os.mkdir(unmatched_xml_dir)
total_files = len(xml_files)
for i in tqdm(xml_files, total=total_files, desc="Processing files", unit="file"):
p = os.path.join(xml, i)
xml_file = os.path.abspath(p)
parse = XmlParse(xml_file)
tree = parse.ReadXml()
# 如果 XML 解析失败,直接移动文件到 unmatched_xml_dir 文件夹
if tree is None:
shutil.move(xml_file, os.path.join(unmatched_xml_dir, i))
continue
root = tree.getroot()
# 解析宽度和高度
W = parse_dimension(root.find('size').find('width').text, i, "width")
H = parse_dimension(root.find('size').find('height').text, i, "height")
# 如果尺寸解析失败,直接移动文件到 unmatched_xml_dir 文件夹
if W is None or H is None:
shutil.move(xml_file, os.path.join(unmatched_xml_dir, i))
continue
fil_name = os.path.splitext(i)[0]
out_path = os.path.join(labels, fil_name + '.txt')
with open(out_path, 'w+') as out:
objects_found = False
has_unmatched = False
for obj in root.iter('object'):
objects_found = True
class_name = obj.find('name').text
# 检查类别名是否在 name_list 中
if class_name not in name_list:
has_unmatched = True
print(f"Class '{class_name}' not in name list in file {i}, moving XML to unmatched folder.")
break
# 解析边界框坐标
x_min = parse_dimension(obj.find('bndbox').find('xmin').text, i, "xmin")
x_max = parse_dimension(obj.find('bndbox').find('xmax').text, i, "xmax")
y_min = parse_dimension(obj.find('bndbox').find('ymin').text, i, "ymin")
y_max = parse_dimension(obj.find('bndbox').find('ymax').text, i, "ymax")
# 如果边界框解析失败,移动文件到 unmatched_xml_dir 文件夹
if None in [x_min, x_max, y_min, y_max]:
has_unmatched = True
break
# 计算中心点和宽高,并写入标签文件
xcenter = x_min + (x_max - x_min) / 2
ycenter = y_min + (y_max - y_min) / 2
w = x_max - x_min
h = y_max - y_min
xcenter = round(xcenter / W, 6)
ycenter = round(ycenter / H, 6)
w = round(w / W, 6)
h = round(h / H, 6)
class_dict = dict(zip(name_list, range(len(name_list))))
class_id = class_dict[class_name]
out.write(f"{class_id} {xcenter} {ycenter} {w} {h}\\n")
# 如果有未匹配类别或解析错误,将文件移动到 unmatched_xml_dir
if has_unmatched or not objects_found:
shutil.move(xml_file, os.path.join(unmatched_xml_dir, i))
def folder_Path():
xml_path = 'D:/Desktop/play_phone_labels'
labels = 'D:/Desktop/labels'
unmatched_xml_dir = 'D:/Desktop/unmatched_xml'
name_list = ['play_phone']
xml2txt(xml_path, labels, name_list, unmatched_xml_dir)
if __name__ == '__main__':
folder_Path()

转换后格式如下:
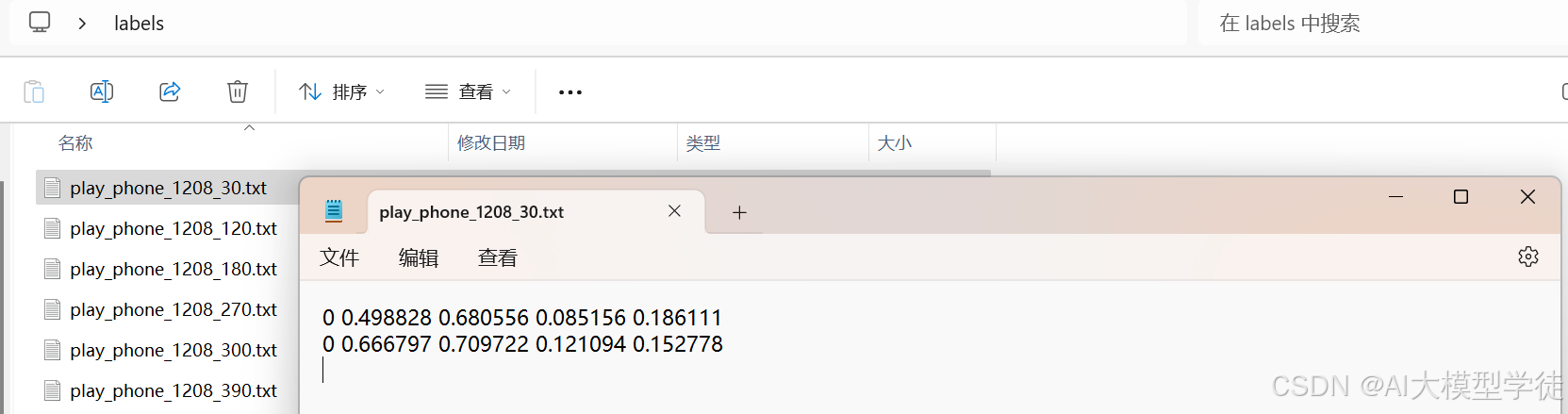
6.训练集验证集划分
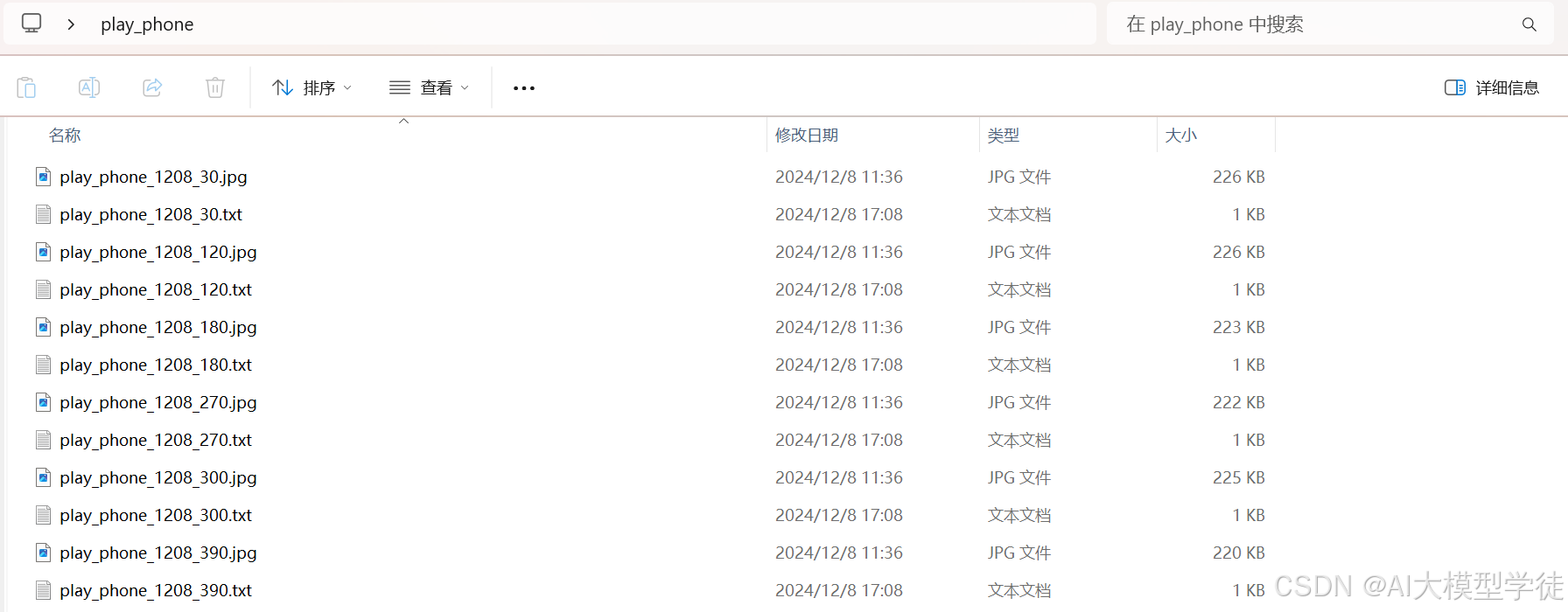
(1)准备好图片和标签
将图片和标签放到一个文件夹中
(2)运行切分脚本
import os
import random
import shutil
def split_dataset(srcDir, trainDir, valDir, split_ratio=0.9):
"""
将数据集划分为训练集和验证集,并保存到相应的文件夹中。
"""
os.makedirs(os.path.join(trainDir, 'images'), exist_ok=True)
os.makedirs(os.path.join(trainDir, 'labels'), exist_ok=True)
os.makedirs(os.path.join(valDir, 'images'), exist_ok=True)
os.makedirs(os.path.join(valDir, 'labels'), exist_ok=True)
# 获取数据集中所有文件的列表
file_list = os.listdir(srcDir)
random.shuffle(file_list)
print(file_list)
split_index = int(len(file_list) * split_ratio)
train_files = file_list[:split_index]
val_files = file_list[split_index:]
for file in train_files:
#print(train_files)
#print(file)
if file.endswith('.jpg'):
#print('3ok')
img_src = os.path.join(srcDir, file)
label_src = os.path.join(srcDir, file[:-4] + '.txt')
#print('ok')
#print(img_src)
shutil.move(img_src, os.path.join(trainDir, 'images', file))
if os.path.exists(label_src):
shutil.move(label_src, os.path.join(trainDir, 'labels', file[:-4] + '.txt'))
if file.endswith('.png'):
img_src = os.path.join(srcDir, file)
label_src = os.path.join(srcDir, file[:-4] + '.txt')
shutil.move(img_src, os.path.join(trainDir, 'images', file))
if os.path.exists(label_src):
shutil.move(label_src, os.path.join(trainDir, 'labels', file[:-4] + '.txt'))
for file in val_files:
if file.endswith('.jpg'):
img_src = os.path.join(srcDir, file)
label_src = os.path.join(srcDir, file[:-4] + '.txt')
shutil.move(img_src, os.path.join(valDir, 'images', file))
if os.path.exists(label_src):
shutil.move(label_src, os.path.join(valDir, 'labels', file[:-4] + '.txt'))
if __name__ == '__main__':
# 输入文件夹路径
srcDir = 'D:/Desktop/play_phone'
trainDir = 'D:/Desktop/datesets/train'
valDir = 'D:/Desktop/datesets/val'
# 调用函数划分数据集
split_dataset(srcDir, trainDir, valDir)
成功转换如下图
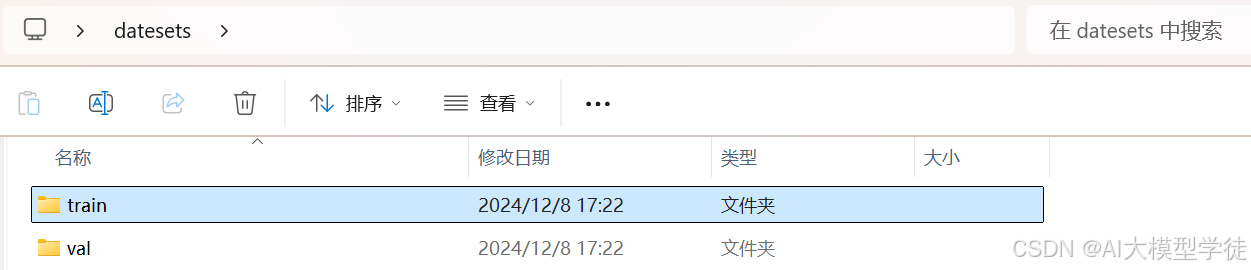
恭喜你成功制作了自己的数据集!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)