【每日一更】<吴恩达-机器学习>多变量线性回归&学习率&特征值
·
目录
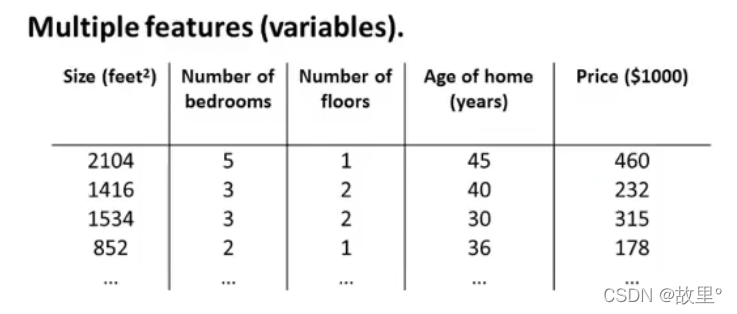
一、Linear Regression with multiple variable - 多变量线性回归:
二、Gradient descent for multiple carables - 多变量梯度下降:
五、Features and polynomial regression:
一、Linear Regression with multiple variable - 多变量线性回归:

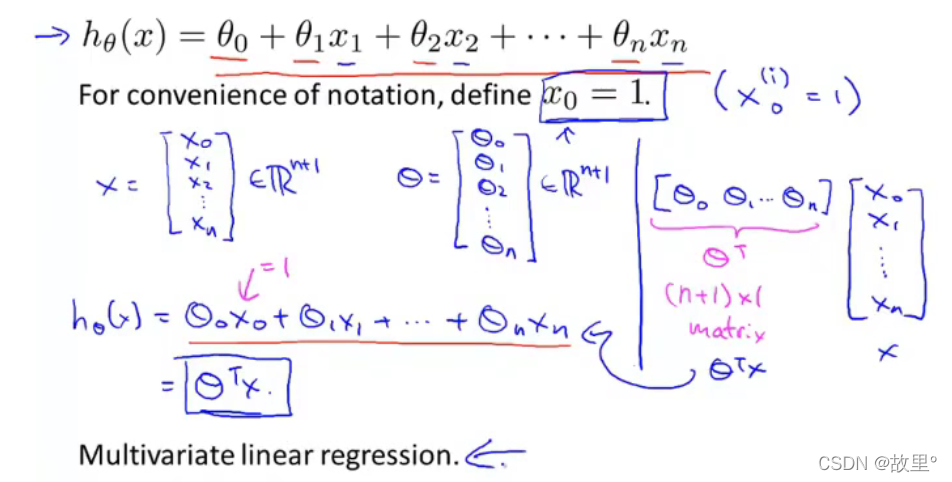
Multivariate linear regression:
二、Gradient descent for multiple carables - 多变量梯度下降:
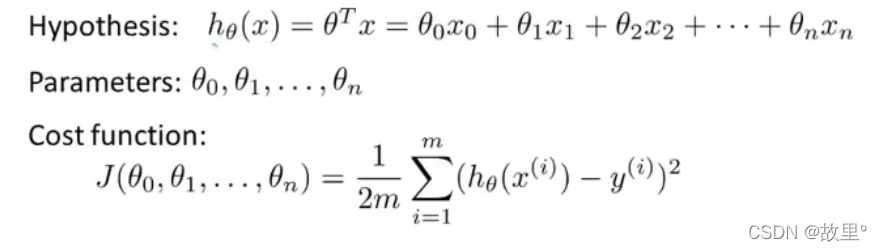
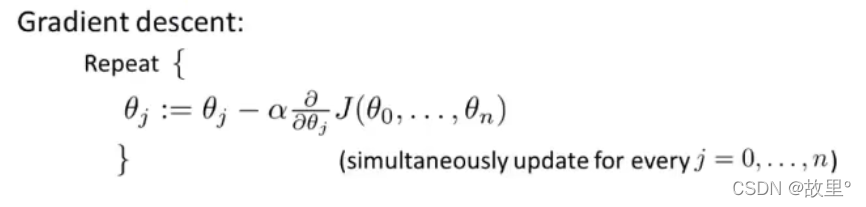


三、Feature Scaling - 特征缩放:

1.特征缩放方法:

有一些时候,只对数据进行中心化和缩放是不够的,还需对数据进行白化(whitening)处理来消除特征间的线性相关性。
2.归一化和标准化的区别:
- 归一化(normalization):归一化是将样本的特征值转换到同一量纲下,把数据映射到[0,1]或者[-1, 1]区间内。
- 标准化(standardization):标准化是将样本的特征值转换为标准值(z值),每个样本点都对标准化产生影响。
四、Learning rate - 学习率:
首先我们简单回顾下什么是学习率,在梯度下降的过程中更新权重时的超参数,即下面公式中的:
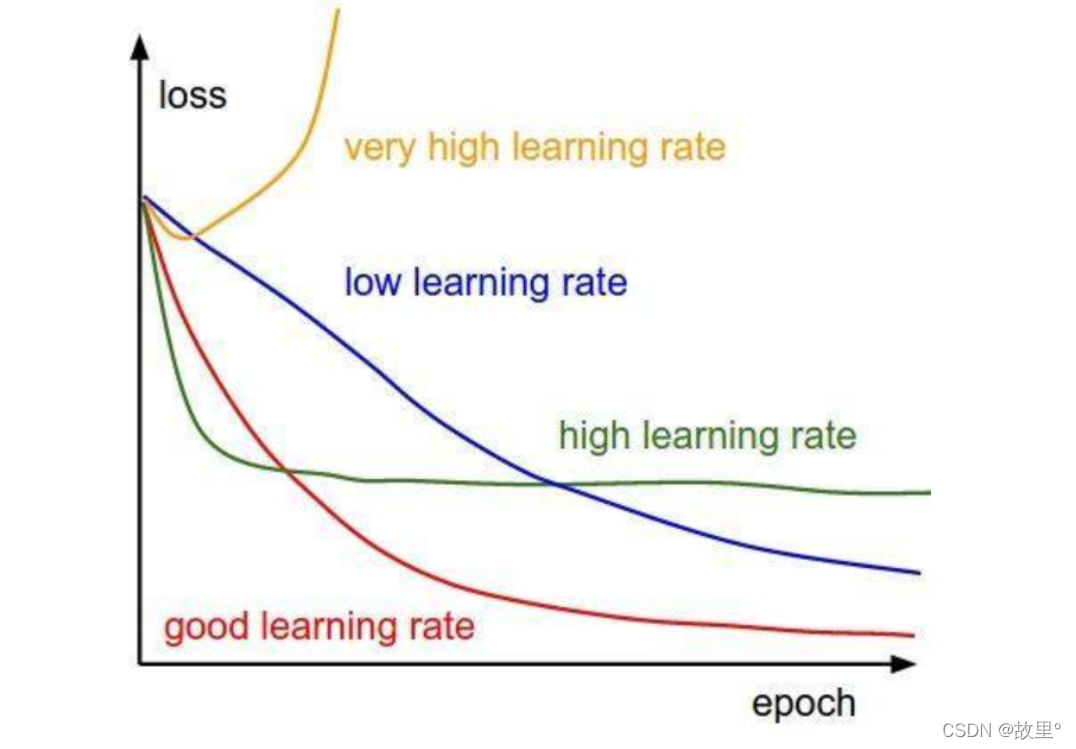
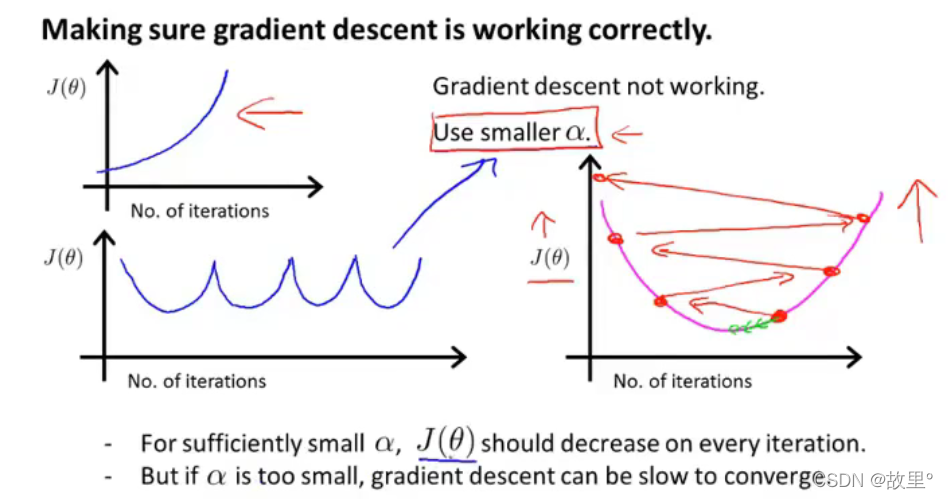
学习率越低,损失函数的变化速度就越慢,容易过拟合。虽然使用低学习率可以确保我们不会错过任何局部极小值,但也意味着我们将花费更长的时间来进行收敛,特别是在被困在局部最优点的时候。而学习率过高容易发生梯度爆炸,loss振动幅度较大,模型难以收敛。下图是不同学习率的loss变化,因此,选择一个合适的学习率是十分重要的。


五、Features and polynomial regression:

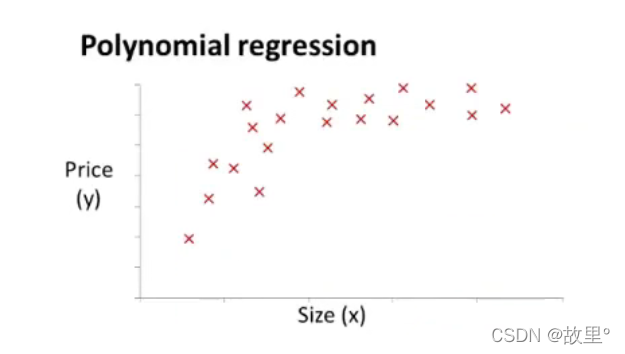
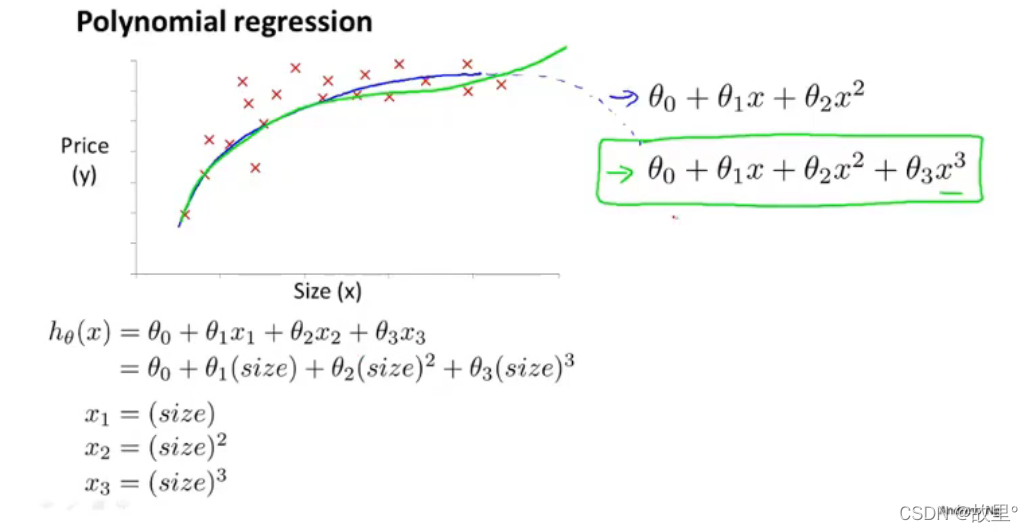
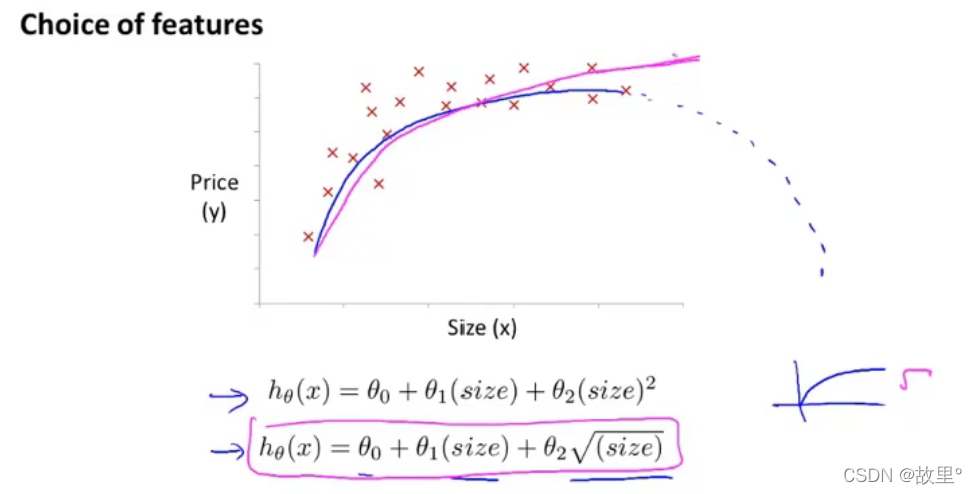
可以通过选择不同的特征值,来对数据进行拟合!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)