机器学习-----------------决策树(代码实现)
1.1决策树的概述
1.1.1决策树的定义
决策树:是一种基于树形结构的机器学习模型,用于解决分类和回归问题。它通过对输入数据进行一系列的判断和分支,最终得出一个决策或预测结果。
1.1.2决策树的节点
决策树的每个内部节点代表一个特征或属性,每个叶节点代表一个类别或数值。
1.1.3决策树的构建
在构建决策树时,通过选择合适的特征和划分规则来最大程度地减少数据集的不纯度,从而使得决策树能够更好地进行分类或回归。
1.1.4决策树的优缺点
优点:决策树具有易于理解和解释、能够处理离散和连续特征、能够处理多分类问题等优点,因此在实际应用中被广泛使用。
缺点:可能会产生过度匹配问题.
1.2决策树的构造
1.2.1决策树的一般流程
(1) 收集数据:可以使用任何方法。
(2) 准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化。
(3) 分析数据:可以使用任何方法,树构造完成后,应该检查决策树图形是否符合预期。
(4) 训练算法:构造树的数据结构。
(5) 测试算法:使用经验树计算错误率。
(6) 使用算法:此步骤可以使用适用于任何监督学习算法,而使用决策树可以更好地理解数据的内在含义。
1.2.2信息增益
定义:在划分数据集之前之后信息发生的变化称为信息增益.
作用:将信息增益最高的特征作为根节点是最好的选择
熵定义:熵常用于衡量数据集的混乱程度或不确定性,用于选择最优的特征进行划分。
信息增益表示在划分前后,熵的减少程度。熵越大,表示数据的不确定性越高,信息增益越大,表示使用该特征进行划分可以获得更多的信息。
具体公式:

创建一个函数计算给定数据集的香农熵 如下:
# 计算给定数据集的熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
#获得数据集的行数
labelCounts = {}
#用于保存每个标签出现次数的字典
for featVec in dataSet:
currentLabel = featVec[-1]
#提取标签信息
if currentLabel not in labelCounts.keys():
#如果标签未放入统计次数的字典,则添加进去
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
#标签计数
shannonEnt = 0.0
#将熵初始化
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
#选择该标签的概率
shannonEnt -= prob*log(prob, 2)
#以2为底求对数
return shannonEnt
#返回经验熵得到熵之后,就可以按照获取最大信息增益的方法划分数据集.
1.2.3划分数据集
# 按照给定特征划分数据集
def splitDataSet(dataSet,axis,value):
#dataSet:待划分数据集 axis:划分数据集的特征 value:需要返回的特征的值
retDataSet=[]
#创建新的list对象
for featVec in dataSet:
#遍历数据集
if featVec[axis] == value:
#符合条件的,抽取出来
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet选择最好的数据集划分方式
# 选择最好的数据集划分方式
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
#特征数量
baseEntropy = calcShannonEnt(dataSet)
#计数数据集的香农熵
bestInfoGain = 0.0
#信息增益
bestFeature = -1
#最优特征的索引值
for i in range(numFeatures):
#遍历数据集的所有特征
featList = [example[i] for example in dataSet]
#获取dataSet的第i个所有特征
uniqueVals = set(featList)
#创建set集合{},元素不可重复
newEntropy = 0.0
#信息熵
for value in uniqueVals:
#循环特征的值
subDataSet = splitDataSet(dataSet, i, value)
#subDataSet划分后的子集
prob = len(subDataSet) / float(len(dataSet))
#计算子集的概率
newEntropy += prob * calcShannonEnt((subDataSet))
infoGain = baseEntropy - newEntropy
#计算信息增益
if (infoGain > bestInfoGain):
#计算信息增益
bestInfoGain = infoGain
#更新信息增益,找到最大的信息增益
bestFeature = i
#记录信息增益最大的特征的索引值
return bestFeature
#返回信息增益最大特征的索引值1.3决策树的实现
决策树的构建过程包括选择最优的特征进行数据集划分,递归地构建子树,直到满足停止条件。
在上面的条件中我们已经已经对数据集进行最优划分,现在还差一个函数来实现递归的构建子树,完成决策树的实现
函数递归实现:
def createDecisionTree(dataSet, features):
classList = [example[-1] for example in dataSet] # 获取数据集中的类别列表
# 如果数据集中的所有样本都属于同一类别,则创建一个叶节点,并将该类别作为叶节点的类别标签
if classList.count(classList[0]) == len(classList):
return classList[0]
# 如果数据集中的特征集为空,则创建一个叶节点,并将样本中最多的类别作为叶节点的类别标签
if len(dataSet[0]) == 1:
return majorityCount(classList)
# 选择最优的特征进行数据集划分
bestFeature = chooseBestFeatureToSplit(dataSet)
bestFeatureLabel = features[bestFeature]
# 创建一个内部节点,并将该特征作为内部节点的划分特征
decisionTree = {bestFeatureLabel: {}}
del(features[bestFeature]) # 从特征集中删除已使用的特征
# 根据划分特征的不同取值,将数据集划分为多个子集
featureValues = [example[bestFeature] for example in dataSet]
uniqueValues = set(featureValues)
for value in uniqueValues:
subFeatures = features[:] # 创建一个新的特征集
subDataSet = splitDataSet(dataSet, bestFeature, value) # 划分子集
decisionTree[bestFeatureLabel][value] = createDecisionTree(subDataSet, subFeatures) # 递归构建子树
return decisionTree1) 如果数据集中的所有样本都属于同一类别,则创建一个叶节点,并将该类别作为叶节点的类别标签。
2) 如果数据集中的特征集为空,即所有特征都已经被使用过,但是样本仍然属于不同的类别,则创建一个叶节点,并将样本中最多的类别作为叶节点的类别标签。
3) 否则,选择最优的特征进行数据集划分,创建一个内部节点,并将该特征作为内部节点的划分特征。
4) 根据划分特征的不同取值,将数据集划分为多个子集。
5) 对于每个子集,递归地调用构建决策树的函数,将子集作为输入数据,得到子树。
6) 将子树连接到当前节点,并返回当前节点。
接下来,使用pydotplus库创建一个空的图形,并又定义了一个递归函数add_nodes_edges来将决策树的节点和边添加到图形中。
函数代码展示:
def add_nodes_edges(tree, parent=None):
for index, (feature, subtree) in enumerate(tree.items()):
if isinstance(subtree, dict):
# 创建一个节点
if parent is None:
node = pydotplus.Node(str(feature), fontname="SimSun")
else:
node = pydotplus.Node(str(feature) + ': ' + parent.get_name(), fontname="SimSun")
if parent is not None:
# 添加边
edge = pydotplus.Edge(parent, node)
graph.add_edge(edge)
# 递归地添加子节点和边
add_nodes_edges(subtree, parent=node)
else:
# 创建一个叶节点
node = pydotplus.Node(str(subtree), fontname="SimSun")
if parent is not None:
# 添加边
edge = pydotplus.Edge(parent, node)
graph.add_edge(edge)
# 添加节点到图形中
graph.add_node(node)
然后,给出数据集,并将数据集转换为列表的形式,并把特征集存储为一个列表
# 将数据集转换为列表的形式
dataSet = []
for i in range(len(data['色泽'])):
sample = [data[feature][i] for feature in data]
dataSet.append(sample)
# 将特征集存储为一个列表
features = list(data.keys())
features.remove('好瓜')最后调用createDecisionTree和dd_nodes_edges函数,生成决策树并把节点添加到图形中
decisionTree = createDecisionTree(dataSet, features)
# 添加决策树节点和边到图形中
add_nodes_edges(decisionTree)
最后,将图形保存为PDF文件,并使用Image函数显示图形。
graph.write_pdf("decision_tree.pdf")
# 显示图形
Image(graph.create_png())最后结果展示:
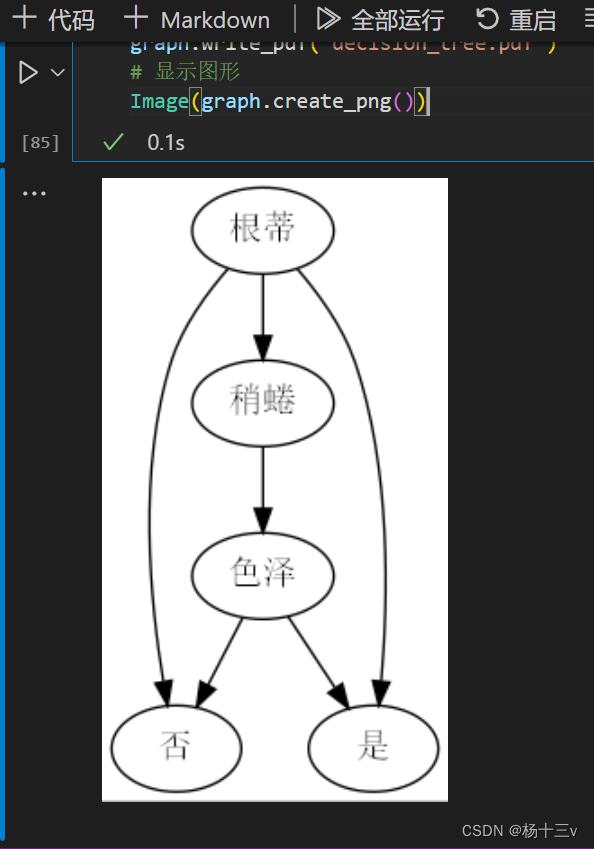
所有代码展示:
from math import log
import pydotplus
from IPython.display import Image
# 计算给定数据集的熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
#获得数据集的行数
labelCounts = {}
#用于保存每个标签出现次数的字典
for featVec in dataSet:
currentLabel = featVec[-1]
#提取标签信息
if currentLabel not in labelCounts.keys():
#如果标签未放入统计次数的字典,则添加进去
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
#标签计数
shannonEnt = 0.0
#将熵初始化
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
#选择该标签的概率
shannonEnt -= prob*log(prob, 2)
#以2为底求对数
return shannonEnt
#返回经验熵
# 按照给定特征划分数据集
def splitDataSet(dataSet,axis,value):
#dataSet:待划分数据集 axis:划分数据集的特征 value:需要返回的特征的值
retDataSet=[]
#创建新的list对象
for featVec in dataSet:
#遍历数据集
if featVec[axis] == value:
#符合条件的,抽取出来
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
# 选择最好的数据集划分方式
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
#特征数量
baseEntropy = calcShannonEnt(dataSet)
#计数数据集的香农熵
bestInfoGain = 0.0
#信息增益
bestFeature = -1
#最优特征的索引值
for i in range(numFeatures):
#遍历数据集的所有特征
featList = [example[i] for example in dataSet]
#获取dataSet的第i个所有特征
uniqueVals = set(featList)
#创建set集合{},元素不可重复
newEntropy = 0.0
#信息熵
for value in uniqueVals:
#循环特征的值
subDataSet = splitDataSet(dataSet, i, value)
#subDataSet划分后的子集
prob = len(subDataSet) / float(len(dataSet))
#计算子集的概率
newEntropy += prob * calcShannonEnt((subDataSet))
infoGain = baseEntropy - newEntropy
#计算信息增益
if (infoGain > bestInfoGain):
#计算信息增益
bestInfoGain = infoGain
#更新信息增益,找到最大的信息增益
bestFeature = i
#记录信息增益最大的特征的索引值
return bestFeature
#返回信息增益最大特征的索引值
def createDecisionTree(dataSet, features):
classList = [example[-1] for example in dataSet] # 获取数据集中的类别列表
# 如果数据集中的所有样本都属于同一类别,则创建一个叶节点,并将该类别作为叶节点的类别标签
if classList.count(classList[0]) == len(classList):
return classList[0]
# 如果数据集中的特征集为空,则创建一个叶节点,并将样本中最多的类别作为叶节点的类别标签
if len(dataSet[0]) == 1:
return majorityCount(classList)
# 选择最优的特征进行数据集划分
bestFeature = chooseBestFeatureToSplit(dataSet)
bestFeatureLabel = features[bestFeature]
# 创建一个内部节点,并将该特征作为内部节点的划分特征
decisionTree = {bestFeatureLabel: {}}
del(features[bestFeature]) # 从特征集中删除已使用的特征
# 根据划分特征的不同取值,将数据集划分为多个子集
featureValues = [example[bestFeature] for example in dataSet]
uniqueValues = set(featureValues)
for value in uniqueValues:
subFeatures = features[:] # 创建一个新的特征集
subDataSet = splitDataSet(dataSet, bestFeature, value) # 划分子集
decisionTree[bestFeatureLabel][value] = createDecisionTree(subDataSet, subFeatures) # 递归构建子树
return decisionTree
# data = {'色泽': ['青绿', '乌黑', '乌黑', '青绿', '浅白', '青绿', '乌黑', '乌黑', '乌黑', '青绿'],
# '根蒂': ['蜷缩', '蜷缩', '蜷缩', '蜷缩', '蜷缩', '稍蜷', '稍蜷', '稍蜷', '稍蜷', '硬挺'],
# '敲声': ['浊响', '沉闷', '浊响', '沉闷', '浊响', '浊响', '浊响', '沉闷', '浊响', '浊响'],
# '纹理': ['清晰', '清晰', '清晰', '清晰', '清晰', '稍糊', '稍糊', '稍糊', '稍糊', '模糊'],
# '脐部': ['凹陷', '凹陷', '凹陷', '凹陷', '凹陷', '稍凹', '稍凹', '稍凹', '稍凹', '平坦'],
# '触感': ['硬滑', '硬滑', '硬滑', '硬滑', '硬滑', '软粘', '软粘', '硬滑', '硬滑', '硬滑'],
# '好瓜': ['是', '是', '是', '是', '是', '是', '否', '否', '否', '否']}
# # 将数据集转换为列表的形式
# dataSet = []
# for i in range(len(data['色泽'])):
# sample = [data[feature][i] for feature in data]
# dataSet.append(sample)
# # 将特征集存储为一个列表
# features = list(data.keys())
# features.remove('好瓜')
# # 调用 createDecisionTree 函数,生成决策树
# decisionTree = createDecisionTree(dataSet, features)
# # 打印决策树
# print(decisionTree)
# 创建一个空的图形
graph = pydotplus.Dot()
# 递归地将决策树添加到图形中
def add_nodes_edges(tree, parent=None):
for index, (feature, subtree) in enumerate(tree.items()):
if isinstance(subtree, dict):
# 创建一个节点
if parent is None:
node = pydotplus.Node(str(feature), fontname="SimSun")
else:
node = pydotplus.Node(str(feature) + ': ' + parent.get_name(), fontname="SimSun")
if parent is not None:
# 添加边
edge = pydotplus.Edge(parent, node)
graph.add_edge(edge)
# 递归地添加子节点和边
add_nodes_edges(subtree, parent=node)
else:
# 创建一个叶节点
node = pydotplus.Node(str(subtree), fontname="SimSun")
if parent is not None:
# 添加边
edge = pydotplus.Edge(parent, node)
graph.add_edge(edge)
# 添加节点到图形中
graph.add_node(node)
data = {'色泽': ['青绿', '乌黑', '乌黑', '青绿', '浅白', '青绿', '乌黑', '乌黑', '乌黑', '青绿'],
'根蒂': ['蜷缩', '蜷缩', '蜷缩', '蜷缩', '蜷缩', '稍蜷', '稍蜷', '稍蜷', '稍蜷', '硬挺'],
'敲声': ['浊响', '沉闷', '浊响', '沉闷', '浊响', '浊响', '浊响', '沉闷', '浊响', '浊响'],
'纹理': ['清晰', '清晰', '清晰', '清晰', '清晰', '稍糊', '稍糊', '稍糊', '稍糊', '模糊'],
'脐部': ['凹陷', '凹陷', '凹陷', '凹陷', '凹陷', '稍凹', '稍凹', '稍凹', '稍凹', '平坦'],
'触感': ['硬滑', '硬滑', '硬滑', '硬滑', '硬滑', '软粘', '软粘', '硬滑', '硬滑', '硬滑'],
'好瓜': ['是', '是', '是', '是', '是', '是', '否', '否', '否', '否']}
# 将数据集转换为列表的形式
dataSet = []
for i in range(len(data['色泽'])):
sample = [data[feature][i] for feature in data]
dataSet.append(sample)
# 将特征集存储为一个列表
features = list(data.keys())
features.remove('好瓜')
# 调用createDecisionTree函数,生成决策树
decisionTree = createDecisionTree(dataSet, features)
# 添加决策树节点和边到图形中
# add_nodes_edges(decisionTree)
# 保存图形为PDF文件
graph.write_pdf("decision_tree.pdf")
# 显示图形
Image(graph.create_png())1.4小结
本次实验粗糙地实现了简单的决策树的绘制,存在的问题还比较多,感觉数据集做得还不太合理,最后的决策树没有很好的展示西瓜属性的取值。
后续还需要修改错误,将数据集中存在的特征标签进行补全,以及完成预剪枝.连续数据的离散化等内容。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)