国科大高级人工智能期末复习(三)联结主义(上)——机器学习
这部分内容过多,所以主要参考往年题目进行复习。
联结主义的代表是机器学习和深度学习。本文主要讨论机器学习(考虑到往年只考过选择,而选择题又基本不怎么变。。。)
一、决策树
决策树本质就是层层闯关式判断—— 像玩 “是 / 否” 答题游戏一样,从 “根节点”(最开始的判断条件)出发,按实际情况选分支,一步步走到 “叶子节点”(最终结论),全程只做简单的 “符合 / 不符合” 判断,最后给出明确结果。下面用一个经典的 “判断顾客是否会购买电脑” 的实例,来一步步构建决策树。
准备数据集
用ai简单生成了一个数据集,目标:用这些数据构建决策树,输入一个顾客的所有特征,就能判断他 “是否会买电脑”。
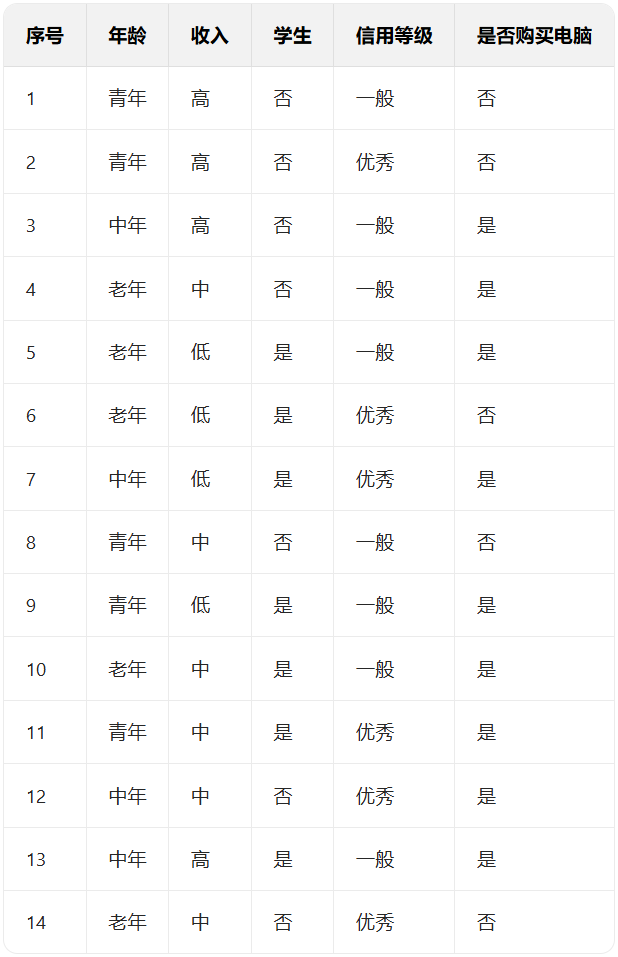
分类标准
决策树的每一步,都要选最能区分 “买 / 不买” 的特征作为当前节点。我们用「信息增益」来衡量每个特征的区分能力:
- 熵(Entropy):表示数据集的 “混乱度”(比如 14 个样本里 8 个买、6 个不买,混乱度较高)。
- 信息增益(Information Gain):“初始熵” 减去 “用某特征划分后的条件熵”,值越大说明这个特征越能减少混乱度,越适合当判断节点。
步骤 1:计算整个数据集的初始熵
整个数据集共 14 个样本,其中8 个买(是)、6 个不买(否)。
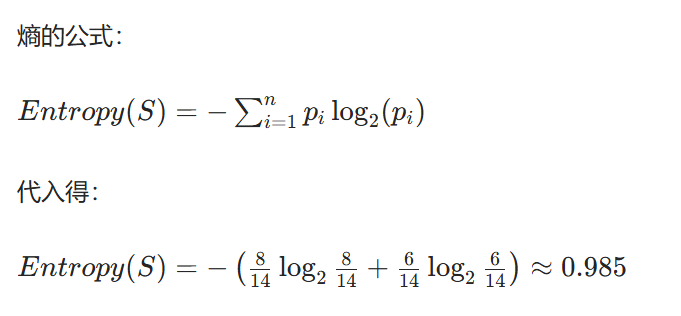
步骤 2:计算每个特征的信息增益,选最大的作为根节点
我们分别计算「年龄、收入、学生、信用等级」的信息增益:
(1)特征:年龄(分为青年、中年、老年 3 个子集)
- 青年子集(5 个样本):2 买、3 不买 → 熵≈0.971
- 中年子集(4 个样本):4 买、0 不买 → 熵 = 0
- 老年子集(5 个样本):2 买、3 不买 → 熵≈0.971
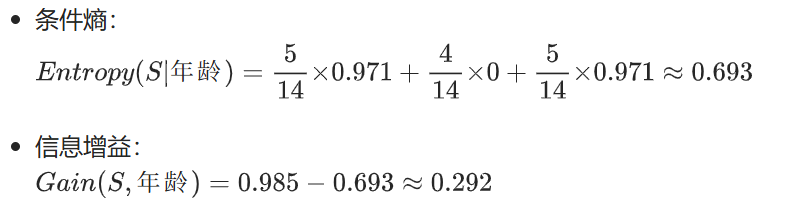
(2)特征:收入(高、中、低 3 个子集)
同理计算得:![]()
(3)特征:学生(是、否 2 个子集)
学生:![]()
(4)特征:信用等级(一般、优秀 2 个子集)
信用等级:![]()
步骤 3:确定根节点
比较信息增益:年龄(0.292)> 学生(0.151)> 信用等级(0.048)> 收入(0.029)。因此,根节点选 “年龄”,按 “青年、中年、老年” 分成 3 个分支。
步骤 4:对每个分支递归构建子节点
分支 1:中年(4 个样本,全部 “买”)
这个子集已经是 “纯的”(所有标签都是 “是”),直接设为叶子节点(结论:买),无需再判断。
分支 2:青年(5 个样本:2 买、3 不买)
对剩下的特征(收入、学生、信用等级)计算信息增益,发现 **“学生” 的信息增益最大 **(能区分 “买 / 不买”),因此子节点选 “学生”,分为 “是”“否”:
- 学生→是(2 个样本,全部 “买”)→ 叶子节点(买)
- 学生→否(3 个样本,全部 “不买”)→ 叶子节点(不买)
分支 3:老年(5 个样本:2 买、3 不买)
对剩下的特征计算信息增益,发现 **“信用等级” 的信息增益最大 **,因此子节点选 “信用等级”,分为 “一般”“优秀”:
- 信用等级→一般(3 个样本,全部 “买”)→ 叶子节点(买)
- 信用等级→优秀(2 个样本,全部 “不买”)→ 叶子节点(不买)
用决策树做预测
比如有一个顾客:青年、高收入、不是学生、信用一般
- 根节点 “年龄”→青年
- 子节点 “学生”→否
- 叶子节点→不买(符合数据集中的规律:青年且不是学生的顾客都没买电脑)
回归树
决策树是分类模型,即待预测的变量是离散型的随机变量;但是现实中需要预测的事情不一定都是离散变量,比如说预测明天的最高气温是多少度、预测一年后的房价。这时我们希望计算机能够给我们一个准确的数值作为答案。通常来说,我们把预测值为离散值的任务称为分类任务,而预测值为连续值的任务称为回归任务。
回归树 (Regression Tree) 适用于回归任务,其输出为连续值。其每一 条训练数据都包含若干条件属性,和一个连续的输出值。整体上看,回归树 很像是用于预测一个连续数值类型输出的决策树,只不过回归树会在优化 目标和训练方法上有所不同。
回归树的本质是:把复杂的连续预测问题,拆成 “层层判断→分组→用组内平均值作为预测结果” 的简单过程。
举个例子:预测你家小区房子的价格,我们有 3 个特征:
- 面积(小:<50㎡;中:50-100㎡;大:>100㎡)
- 房龄(新:<5 年;老:≥5 年)
- 是否学区房(是 / 否)
回归树的思路是:
- 先找一个最能区分房价的特征(比如 “面积”),把房子分成 “小、中、大” 三组;
- 对每组再找下一个最能区分房价的特征(比如 “是否学区房”),继续细分;
- 当小组里的房价足够 “整齐”(波动很小)时,就用这个小组的平均房价作为该组的预测值。
下面用这个例子来构建回归树并预测
准备数据集
目标:用这些数据构建回归树,输入房子的特征就能预测房价。
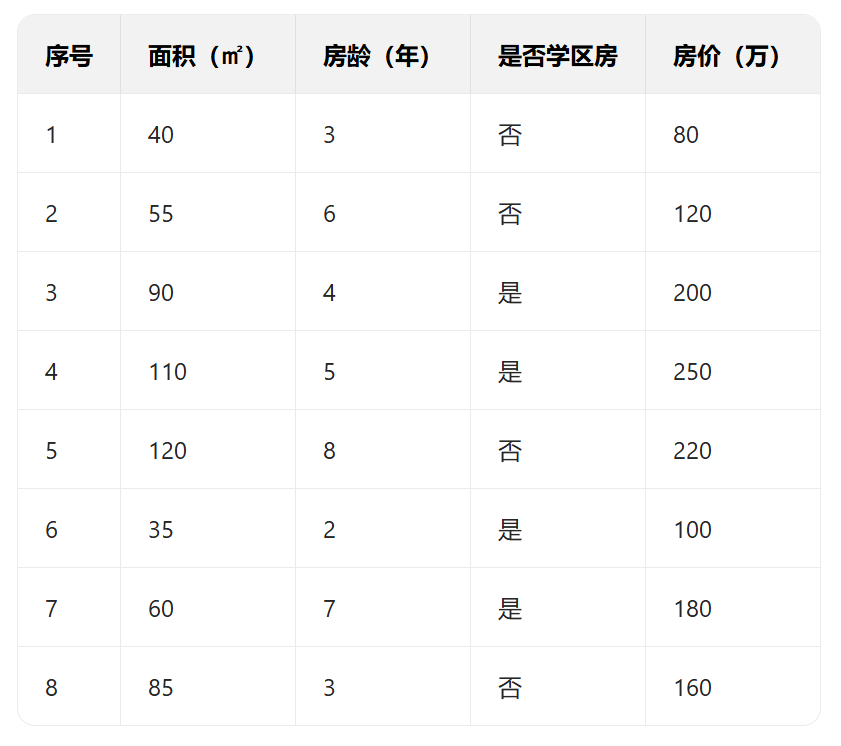
步骤 1:怎么选第一个分裂特征?(核心:减少数值波动)
分类树用 “信息增益” 选特征,回归树用 **“均方误差(MSE)的减少量”**——MSE 越小,说明小组内的房价越接近,预测越准。
-
整个数据集的房价 MSE:先算所有房价的平均值((80+120+200+250+220+100+180+160)/8 = 161.25),再算每个房价与平均值的差的平方的平均,得到初始 MSE≈3514。
-
我们分别用 “面积”“房龄”“是否学区房” 分裂,看哪个分裂能让 MSE 下降最多:
① 用 “面积” 分裂(<50、50-100、>100):
- <50㎡组(样本 1、6):房价 80、100 → 平均 90 → MSE=100
- 50-100㎡组(样本 2、3、7、8):房价 120、200、180、160 → 平均 165 → MSE=800
- 100㎡组(样本 4、5):房价 250、220 → 平均 235 → MSE=225
- 分裂后的总 MSE = (2/8)×100 + (4/8)×800 + (2/8)×225 = 456.25
- MSE 减少量 = 3514 - 456.25 = 3057.75
② 用 “是否学区房” 分裂(是 / 否):
- 是组(样本 3、4、6、7):房价 200、250、100、180 → 平均 182.5 → MSE=3281.25
- 否组(样本 1、2、5、8):房价 80、120、220、160 → 平均 145 → MSE=2750
- 分裂后的总 MSE = (4/8)×3281.25 + (4/8)×2750 = 3015.625
- MSE 减少量 = 3514 - 3015.625 = 498.375
显然,“面积” 分裂后 MSE 下降更多(3057.75 > 498.375),所以根节点选 “面积”。
步骤 2:对每个分支继续分裂
- <50㎡组(样本 1、6):房价 80、100,MSE=100(已经很小,不用再分裂)→ 叶子节点:预测值 = 90 万。
- 50-100㎡组(样本 2、3、7、8):用 “是否学区房” 分裂,“是” 组(3、7)房价 200、180→平均 190;“否” 组(2、8)房价 120、160→平均 140→MSE 下降明显,所以子节点选 “是否学区房”。
- >100㎡组(样本 4、5):房价 250、220,MSE=225(波动小)→ 叶子节点:预测值 = 235 万。
用回归树做预测
比如有一套房子:面积 70㎡、房龄 5 年、是学区房
- 根节点 “面积”→50-100㎡
- 子节点 “是否学区房”→是
- 叶子节点→预测 190 万(和数据集中 “50-100㎡+ 学区房” 的平均房价一致)
决策树和回归树是机器学习预测的基础,针对不同任务,选择不同的目标函数进行优化,就可以解决很多问题。后续的几种模型,基本都是建立在它们之上的,因此只做知识点上的总结。
GBRT(梯度提升回归树)
- 基本假设:多个回归树预测值相加,逐树修正前序模型残差。
- 优化目标:最小化训练误差 + 模型复杂度惩罚。
- 训练方法:迭代训练回归树,每棵树拟合前序模型的残差。
- 预测方法:加总所有树的预测结果。
概率模型:逻辑回归
- 基本假设:用 sigmoid 函数将线性组合映射到 [0,1] 概率空间,本质是线性分类器。
- 优化目标:最大化数据似然,转化为最小化 Logistic Loss,支持 L1/L2 正则化。
- 训练方法:随机梯度下降法(SGD)更新参数。
- 预测方法:选择概率最大的类别作为输出。
集成学习
| 模型 | 样本调整方式 | 预测方法 |
|---|---|---|
| Bagging | 可放回重复采样生成不同训练集 | 分类投票、回归取均值 |
| 随机森林 | 随机选择属性构建决策树,随机分裂连续属性 | 类别投票 |
| AdaBoost | 基于前序模型预测结果调整样本权重 | 加权投票,错误率低的模型权重更高 |
特征工程
- 核心目标:降低数据维度、提升模型泛化能力,减少过拟合。
- 关键技巧:结合 GBRT 与线性模型,将树模型输出作为新特征输入线性模型。
例题

D并不是条件熵,而是初始熵” 减去 “用某特征划分后的条件熵”,即信息增益


C 前面已经证明过了。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 8
8 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)