Ray分布式计算框架原理学习和异构GPU的支持
·
文章目录
相关实战
一 分布式计算框架Ray
- Ray是一个开源的分布式计算框架,专为Python和机器学习应用设计,能够将应用从单机扩展到多节点集群。
Ray采用集群架构,包含:- 头节点(Head Node):单个节点,运行集群管理进程。
- 工作节点(Worker Nodes):多个节点,执行实际任务。
1.1 核心进程组件
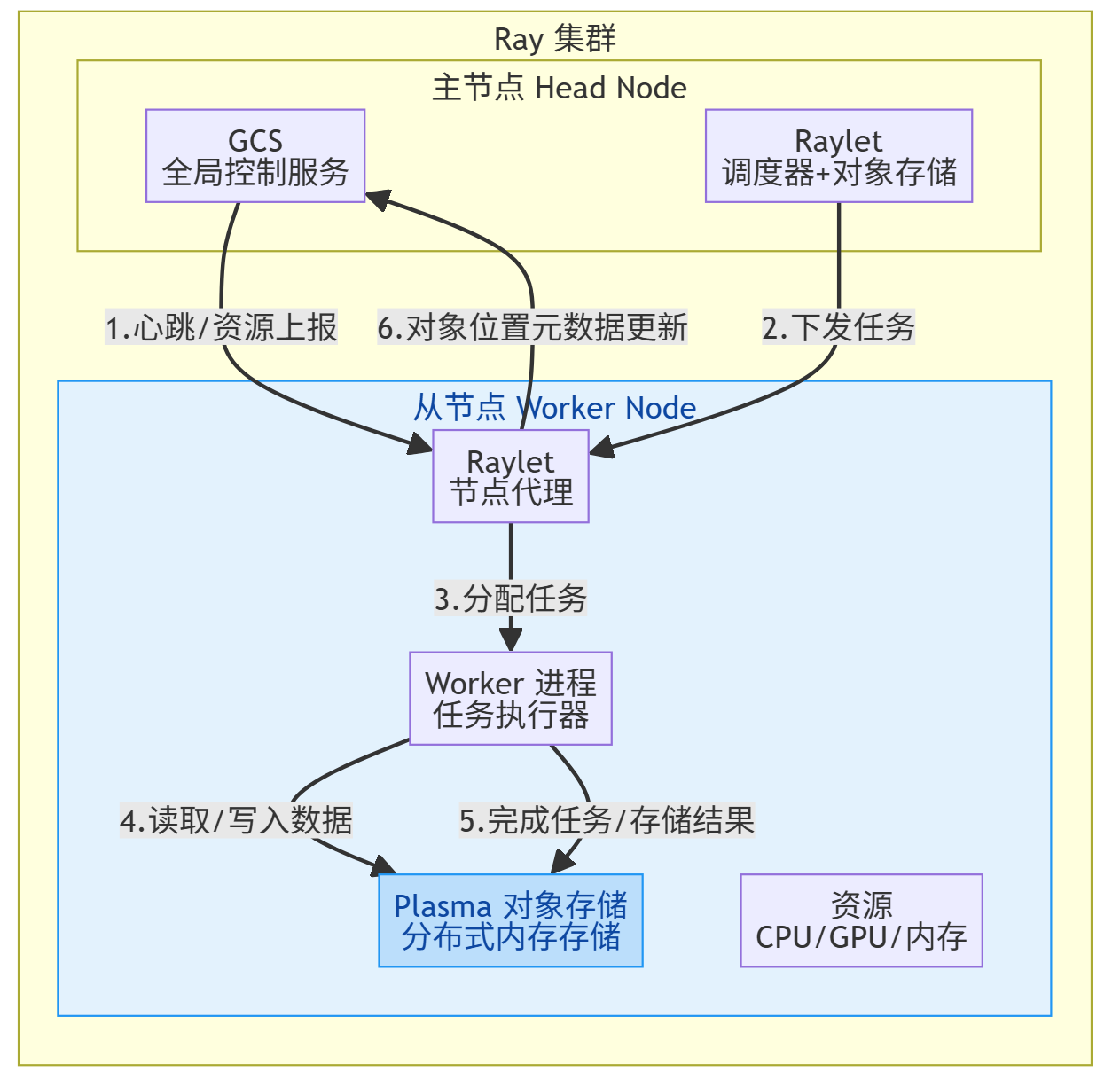
- Raylet:Raylet是Ray在每个节点上的核心代理进程,包含两个主要组件:调度器(Scheduler)和对象存储(Object Store)。
- 调度器(Scheduler):负责资源管理和任务调度,决定worker进程执行的任务,管理CPU、GPU、内存等资源分配。
- 对象存储(Object Store):基于Apache Arrow的Plasma对象存储,使用共享内存存储大型对象,实现零拷贝数据共享(同节点内)。
- GCS(Global Control Store):运行在头节点上的全局控制服务,键值存储,保存系统级元数据(存储对象位置、Actor信息等),接收节点心跳信号。
- Worker进程:执行实际的Ray任务和Actor方法,每个CPU核心通常对应一个worker进程。
1.2 主节点的作用
- Ray 的 Head Node(主节点)不强制要求必须拥有 GPU 资源。它的核心职责是集群管理、调度和元数据服务,而非计算任务本身。
- 集群引导和服务发现:维护所有Worker节点的地址信息,新节点加入时的注册中心,提供节点间的服务发现能力。
- 资源调度和任务分发:维护全局资源状态(CPU、GPU、内存使用情况),决定应该执行新任务的节点,实现负载均衡和资源优化。
- 分布式对象存储的元数据管理:记录分布式对象存储对应节点的存储位置,管理对象的引用计数和生命周期,协调跨节点的数据传输。
- 全局状态同步:收集各节点的健康状态,处理节点故障和恢复,维护全局的命名空间。
1.3 从节点的作用
- 从节点是 Ray 集群中实际执行计算任务和存储数据的“干活的”节点,它们构成了集群的算力基石。
| 作用维度 | 核心功能 | 简单理解 |
|---|---|---|
| 任务执行 | 运行 @ray.remote 定义的普通任务 和 Actor 方法。 |
真正的“工人”,负责把代码跑起来,完成计算。 |
| 对象存储 | 本地节点上的 Plasma 对象存储,分布式存储计算结果和中间数据。 | 本地“仓库”,数据存在这儿,存取快,不用老跑主节点。 |
| 资源提供 | 向主节点(GCS)上报并提供 CPU、GPU、内存、自定义资源(如 TPU, custom_resource)。 |
提供“生产资料”,告诉主节点我有几把“锤子”和“螺丝刀”。 |
| 分布式协调 | 与主节点(GCS)心跳通信,参与全局资源调度和故障恢复。 | 听从指挥,向主节点报到,接受任务分配,保持在线。 |
| 负载均衡 | 根据主节点的调度策略,合理分配任务,避免某些节点过载。 | 干活的“平摊”,确保活儿分得均匀,大家都不累垮。 |
- 从节点通过以下几个关键机制紧密协作,支撑起整个分布式系统。
-
🖥️ 任务执行(Task Execution):编写的
@ray.remote函数或类,最终都会被封装成任务,由从节点上的 Worker 进程执行。- 普通任务(Tasks):无状态函数,执行完就结束,比如数据处理、模型推理。
- Actor 任务:有状态类,可以保持内部状态,比如强化学习中的环境、模型服务实例。一个 Actor 通常会始终运行在一个特定的从节点上,多次方法调用都在同一节点执行。
-
💾 本地对象存储(Local Object Storage):每个从节点都运行着一个基于 Apache Arrow Plasma 的对象存储服务(Object Store)。这是 Ray 实现高效数据共享的秘密武器。
- 本地存储:Worker 进程将任务执行的结果(对象)优先存储在所在节点的 Plasma Store 中。这就像每个工人旁边都有一个自己的小仓库。
- 零拷贝(Zero-Copy):当同一节点上的另一个任务需要这个对象时,可以直接通过共享内存读取,无需数据拷贝,速度极快。
- 分布式存储:当其他节点的任务需要这个对象时,Ray 会自动将对象通过网络传输到目标节点的对象存储中。GCS 会维护每个对象的位置信息(对象ID -> 节点IP),方便任务知道去哪里取数据。
-
🚀 资源提供与隔离(Resource Provisioning & Isolation):从节点最重要的职责之一就是向主节点“报备”和“提供”资源,并确保任务按分配的资源运行。
- 资源上报:从节点启动时,会通过 Raylet 向 GCS 上报自己拥有的 CPU、GPU、内存等资源总量。
- 资源分配与隔离:当主节点的调度器决定将某个任务调度到此从节点时,会指定该任务所需的资源(例如,
num_gpus=1)。从节点的 Raylet 会预留相应的资源给该任务,确保任务在运行时能独占或公平使用这些资源,避免不同任务争抢。
-
📡 分布式协调与故障恢复(Distributed Coordination & Fault Tolerance):从节点不是孤立的,它必须与主节点和其他从节点紧密协作,并具备一定的容错能力。
- 心跳通信(Heartbeat):从节点的 Raylet 会定期向 GCS 发送心跳,报告自己的状态(如“我还活着”、“我的任务执行情况”、“我的对象存储有哪些数据”)。如果 GCS 在超时时间内未收到某从节点的心跳,会判定该节点失效。
- 故障恢复:一旦 GCS 判定某从节点失效,它会将该节点上运行的 Actor 任务(有状态)在其他健康节点上重建。将该节点上存储的 对象(数据)从其副本(如果配置了对象复制)或源头重新恢复到其他节点。重新调度那些因节点失效而失败的任务。这个过程对用户是透明的,保证了系统的容错性。
-
🔄 负载均衡(Load Balancing):虽然主节点的调度器负责全局调度,但从节点自身也会配合实现一定的负载均衡。
- 任务队列:每个从节点的 Raylet 都维护着一个任务队列。当它接收到主节点分配的任务后,会将其放入队列。
- Worker 线程/进程:Worker 进程中的多个线程(每个核心一个)会从队列中获取任务并执行。这种模型确保了同一节点上的计算资源被充分利用。
- 数据本地性:调度器在调度任务时,会优先将任务调度到拥有其依赖数据的从节点上,以减少网络传输开销。从节点通过上报其对象存储中的数据信息,帮助调度器做出智能决策。
- 从节点的启动:一个从节点要加入 Ray 集群,通常在机器上执行以下命令:
# 在从节点机器上执行,指定头节点的 IP 地址
ray start --address='<头节点IP>:6379' --resources='{"custom_resource": 1}'
--address:指定头节点(GCS)的地址,以便与其建立连接并注册。--resources:可选,声明该节点上除 CPU/GPU 外的自定义资源(例如,一块特定的硬件、一个数据库连接等),方便更精细的调度。
- 从节点 vs. 主节点(Head Node)
| 特性 | 主节点 (Head Node) | 从节点 (Worker Node) |
|---|---|---|
| 核心角色 | 集群“指挥官” (管理、调度、元数据) |
集群“士兵” (执行、存储、提供资源) |
| 运行组件 | GCS, Raylet, Driver Script, Dashboard, Worker | Raylet, 多个 Worker 进程, Plasma Store |
| 职责重点 | 全局协调、元数据管理、调度决策、提供用户接口 | 任务执行、数据存储、提供计算资源、本地调度 |
| 资源需求 | 对稳定性和网络要求高 | 对计算性能(CPU/GPU)和内存要求高 |
| 故障影响 | 致命,整个集群无法工作 | 可容忍,通过故障恢复机制重新调度任务 |
1.4 Ray的调度算法
- 任务调度流程:用户调用
task.remote(),向本地Raylet申请worker租约,Raylet检查资源需求和依赖,分配合适的worker,通过gRPC发送ExecuteTask RPC,Worker执行任务并返回结果。 - 调度优化策略
- 调度决策缓存:相同类型任务重用之前的调度决策。
- 局部性优化:优先在有数据的节点上调度任务。
- 负载均衡:任务分布到多个节点以最大化资源利用率。
- 跨节点调度:如果本地没有可用资源:本地Raylet重定向请求到有资源的远程Raylet,通过gRPC直接向远程worker发送任务,支持透明的多节点扩展。
1.5 多种通信后端
| 协议/后端 | 主要特点 | 适用场景 |
|---|---|---|
| NCCL | GPU 原生优化,支持 AllReduce、AllGather、Broadcast 等;多 GPU 节点下性能最优 | 深度学习训练的模型并行、数据并行、流水线并行等需要高频集合通信的场景 |
| Gloo | 跨 CPU/GPU、跨平台;支持 TCP、InfiniBand;部署简单 | 通用的分布式计算、参数服务器、分布式强化学习等 |
| Ray 内置协议 | 基于 Plasma 对象存储 + gRPC/消息队列;支持任务间对象传递、Actor 间通信 | 日常任务调度、Actor 间数据共享、小/中等规模对象传输 |
| 直接 TCP 连接 | 自定义流式传输,可控制缓冲、分块、断点续传 | 大文件、数据集、模型检查点的跨节点分发 |
- 根据任务类型自动选择 Ray 后端通信协议
| 任务类型 | 使用的通信协议/后端 | 说明 |
|---|---|---|
| 深度学习张量并行 | NCCL | NVIDIA Collective Communications Library,专为 GPU 集群优化,适合高带宽、低延迟的 AllReduce、AllToAll 等集合通信操作,常用于深度学习训练的张量并行场景。 |
| 一般分布式计算 | Gloo | Facebook 开发的集合通信库,支持 CPU 和 GPU,跨平台性好(Linux、macOS、Windows),适合常规的分布式计算任务,不依赖特定硬件加速。 |
| 对象传输 | Ray 内置协议 | Ray 自带的序列化与传输协议,用于在节点间传递 Python 对象(如参数、结果数据),支持零拷贝、共享内存等优化,适用于一般的对象传递场景。 |
| 大文件传输 | 直接 TCP 连接 | 针对大文件(GB 级别以上)的直接 TCP 传输,可绕过 Ray 的对象存储层,减少序列化与复制开销,适合数据集、模型权重的批量传输。 |
- 优先自动选择:可以在 Ray 任务调度层根据任务类型自动选择通信协议(例如:检测到张量并行任务则使用 NCCL,否则回退到 Gloo)。
- 显式指定:对于性能关键任务,建议在应用层显式指定后端(如
ray.init(runtime_env={"env_vars": {"NCCL_DEBUG": "INFO"}})或在任务中调用相应的通信库)。 - 混合场景:复杂流程中可能同时使用多种协议(如用 Gloo 做控制面协调,用 NCCL 做数据面集合通信,用 Ray 内置协议传递小对象,用 TCP 传输大文件)。
1.6 子节点间通信机制
- Ray的Worker节点间可以直接通信,无需通过主节点。
- 从节点之间的建立通信一建立,后续通信会复用此连接,提升通信效率。
- Worker A需要与Worker B通信。
->>表示同步请求(实线箭头)。-->>表示响应(虚线箭头)。
二 Ray对异构GPU的支持
- Ray的设计天然支持异构集群,充分允许利用不同节点的硬件特性。不同GPU资源的Ubuntu从节点(如NVIDIA显卡和AMD核显)可以在同一个Ray集群中协同工作,但需要正确配置资源管理和任务调度。
2.1 Ray对异构GPU的支持机制
- Ray通过资源调度系统和自定义资源标签来管理异构硬件,其核心机制如下:
| 机制 | 说明 | 实现方式 |
|---|---|---|
| 预定义资源 | Ray原生支持CPU、GPU、内存等基本资源类型 | 直接在任务中指定num_gpus |
| 自定义资源 | 为特殊硬件(如AMD GPU)定义专属资源标签 | 在节点启动时通过--resources参数指定 |
| 资源亲和性 | 确保任务在拥有合适资源的节点上运行 | 通过@ray.remote(resources={...})声明需求 |
2.2 实际影响与挑战
虽然Ray支持异构集群,但不同GPU架构混用会带来一些实际挑战:
| 影响方面 | NVIDIA GPU节点 | AMD核显节点 | 潜在问题与解决方案 |
|---|---|---|---|
| 深度学习框架兼容性 | 完全支持(PyTorch, TensorFlow等) | 部分支持(需通过ROCm或特定后端) | 代码兼容性问题:确保你的深度学习代码同时支持CUDA和ROCm,或使用兼容层如HIP |
| 性能表现 | 高性能计算能力 | 性能较低,适合轻量任务 | 性能不均衡:合理分配任务,避免将计算密集型任务分配给核显节点 |
| 驱动与运行时环境 | 需NVIDIA驱动+CUDA Toolkit | 需AMD驱动+ROCm运行时 | 环境配置复杂:需为不同节点准备不同的运行时环境(Runtime Environments) |
| 并行计算效率 | 高效支持多GPU并行 | 并行能力有限 | 集群效率瓶颈:核显节点可能成为整个计算集群的短板,影响整体吞吐量 |
| 调试与监控 | 成熟工具链(NVIDIA-SMI等) | 监控工具相对较少 | 运维难度增加:需要同时掌握两套监控体系,故障排查更复杂 |
2.3 异构GPU集群指南
要实现NVIDIA和AMD GPU节点协同工作,需遵循以下配置流程:
- 节点注册与资源声明:在启动Ray节点时,需明确声明各节点的硬件资源。
# NVIDIA GPU节点启动命令(假设有4块NVIDIA显卡)
ray start --num-gpus=4 --address=<head_node_ip>:6379
# AMD核显节点启动命令(使用自定义资源)
ray start --resources='{"AMD_GPU": 1}' --address=<head_node_ip>:6379
- 定义自定义资源标签:对于AMD GPU,需使用自定义资源标签进行声明。
# 在代码中为不同GPU类型的任务指定资源需求
@ray.remote(num_gpus=1) # NVIDIA GPU任务
def nvidia_task():
# NVIDIA GPU代码
pass
@ray.remote(resources={"AMD_GPU": 1}) # AMD GPU任务
def amd_task():
# AMD GPU代码(使用ROCm等)
pass
- 设置运行时环境隔离:为不同GPU类型准备隔离的运行时环境。
# 定义NVIDIA节点的运行时环境
nvidia_runtime_env = {
"pip": ["torch", "tensorflow"],
"env_vars": {"CUDA_VISIBLE_DEVICES": "0"}
}
# 定义AMD节点的运行时环境
amd_runtime_env = {
"pip": ["torch", "tensorflow-rocm"], # 使用ROCm版本的框架
"env_vars": {"HIP_VISIBLE_DEVICES": "0"}
}
# 在任务中使用运行时环境
@ray.remote(runtime_env=nvidia_runtime_env, num_gpus=1)
def nvidia_task():
pass
@ray.remote(runtime_env=amd_runtime_env, resources={"AMD_GPU": 1})
def amd_task():
pass
- 编写资源感知任务:在任务中正确处理不同GPU架构。
import torch
@ray.remote(num_gpus=1)
def gpu_aware_task():
# 检测当前使用的GPU类型
if torch.cuda.is_available():
device_name = torch.cuda.get_device_name(0)
if "NVIDIA" in device_name:
# NVIDIA GPU特定代码
print(f"Running on NVIDIA GPU: {device_name}")
elif "AMD" in device_name:
# AMD GPU特定代码(通过HIP兼容层)
print(f"Running on AMD GPU: {device_name}")
# 可能需要使用torch.hip等特定API
else:
raise RuntimeError("Unknown GPU type")
else:
raise RuntimeError("No GPU available")
# 通用计算代码(框架兼容层处理差异)
result = torch.randn(1000, 1000).cuda()
return result.sum().item()
2.4 异构集群的性能优化策略
在异构GPU集群中,优化资源利用率是关键:
- 任务分层调度策略
| 任务类型 | 推荐运行节点 | 资源需求 | 理由 |
|---|---|---|---|
| 深度学习模型训练 | NVIDIA GPU节点 | num_gpus=1-4 |
充分利用高性能计算能力 |
| 批量推理 | AMD核显节点 | resources={"AMD_GPU": 1} |
核显足以处理轻量推理任务 |
| 数据预处理 | CPU节点 | 无GPU需求 | 解放GPU资源用于计算密集型任务 |
| 参数服务器 | CPU或低GPU节点 | 少量CPU资源 | 减少GPU资源竞争 |
- 资源监控与动态调整:使用Ray Dashboard监控不同节点的资源使用情况,并动态调整任务分配策略。
# 获取集群状态
from ray import serve
cluster_resources = ray.cluster_resources()
available_resources = ray.available_resources()
# 根据资源可用性动态调度任务
if available_resources.get("GPU", 0) > 0:
# 调度NVIDIA GPU任务
result = nvidia_task.remote()
elif available_resources.get("AMD_GPU", 0) > 0:
# 调度AMD GPU任务
result = amd_task.remote()
else:
# 调度CPU任务
result = cpu_task.remote()
2.5 总结
NVIDIA和AMD GPU节点完全可以在同一个Ray集群中协同工作,但需要:
- ✅ 正确声明资源:使用自定义资源标签区分不同GPU类型
- ✅ 隔离运行环境:为不同GPU准备专用的运行时环境
- ✅ 智能任务调度:根据任务需求选择合适的GPU节点
- ✅ 编写兼容代码:确保代码支持不同的GPU架构
这种异构集群配置特别适合渐进式升级(逐步替换旧节点)或混合工作负载(同时需要高性能计算和轻量推理)的场景。通过合理配置,你可以显著提高硬件资源的整体利用率,同时保持投资回报率。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 20
20 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)