【Python机器学习系列】sklearn机器学习模型的保存---joblib法
·
这是我的第247篇原创文章。
一、引言
joblib包是由scikit-learn外带的,是一个用于将Python对象序列化为磁盘文件的库,专门用于大型数组,常用于保存机器学习模型。它可以高效地处理大型数据集和模型。对于大数据和大型机器学习模型,使用joblib可能比pickle更快更加高效。
二、实现过程
2.1 数据准备与划分
将数据划分为训练集和测试集:
# 准备数据
data = pd.read_csv(r'Dataset.csv')
df = pd.DataFrame(data)
## 数据基本信息
cat_cols = [col for col in df.columns if df[col].dtype == "object"] # 类别型变量名
num_cols = [col for col in df.columns if df[col].dtype != "object"] # 数值型变量名
# 提取目标变量和特征变量
target = 'target'
features = df.columns.drop(target)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)2.2 模型训练与保存
利用训练集进行训练模型:
# 模型的构建与训练
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 使用 joblib 保存模型
with open('./random_forest_model.joblib', 'wb') as file:
joblib.dump(model, file)模型保存为joblib文件:
![]()
2.3 模型推理与评价
加载训练好的模型(文件),输入测试集进行预测:
# 加载保存的模型
with open('./random_forest_model.joblib', 'rb') as file:
loaded_model = joblib.load(file)
print(loaded_model)
# 模型推理与评价
y_pred = loaded_model.predict(X_test)
y_scores = loaded_model.predict_proba(X_test)
acc = accuracy_score(y_test, y_pred) # 准确率acc
cm = confusion_matrix(y_test, y_pred) # 混淆矩阵
cr = classification_report(y_test, y_pred) # 分类报告
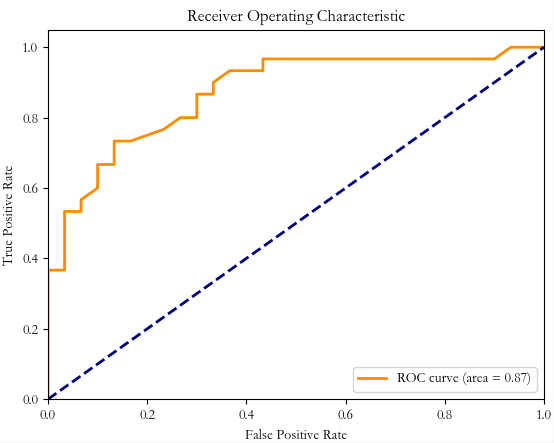
fpr, tpr, thresholds = roc_curve(y_test, y_scores[:, 1], pos_label=1) # 计算ROC曲线和AUC值,绘制ROC曲线
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()结果:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 5
5 0
0- 0



 已为社区贡献131条内容
已为社区贡献131条内容

所有评论(0)