超越代码生成:为何“元数据”才是氛围编程下,打通研发与交付实施的命门?
·
一、到底什么是“低/无一体”?
定义(一句话): 把低代码(面向工程师的可扩展开发)与无代码(面向业务的可视化装配)统一到同一套元数据与同一运行时/治理体系之下,让两类人群围绕“同一个事实源(Single Source of Truth)”协同产出可版本化、可复用的产品与方案。
它不是“两个工具拼在一起”,而是四个统一:
- 模型统一:数据模型、关系、权限、视图、流程、规则、行为等都以元数据描述;
- 引擎统一:同一运行时执行模型,减少“配置/代码双轨”带来的不可预期;
- 扩展统一:无代码装配遇到边界,可用低代码在同一扩展点继续深化(组件、脚本、服务、Hook/事件);
- 治理统一:同一套版本、差异、审计、发布、回滚、合规与可观测体系。
可以把“低/无一体”理解为自动挡(无代码)+ 手动挡(低代码)共用一台发动机(元数据引擎)与同一套变速箱(治理/交付流水线)。
示意图
业务人员 ──[无代码建模/编排]──┐
├── 同一套 元数据/运行时/治理 ──> 应用/模块/版本
工程人员 ──[低代码扩展/插件]───┘
⚡ 直达演示环境
☕ 账号:admin
☕ 密码:admin | 🎬 1. [数式Oinone] #产品化演示# 后端研发与无代码辅助
🎬 2. [数式Oinone] #产品化演示# 前端开发
🎬 3. [数式Oinone] #个性化二开# 后端逻辑
🎬 4. [数式Oinone] #个性化二开# 前端交互
🎬 5. [数式Oinone] #个性化二开# 无代码模式 |
二、在“低/无一体”下,研发与实施的关系怎么变?
传统分工的痛点
- 研发做“标品”,实施做“定制”。交付多了就分叉,回不去主干,升级成本爆炸;
- 业务侧改配置,工程侧改代码,双栈脱节导致质量不可控、难以回溯;
- 实施产出不能资产化,下一单还得重来。
“低/无一体”后的新分工(结合 Oinone)
上游/下游同源模型 + 模块化沉淀 + 版本化治理:
[ 上游:产品主干(标品) ] ←— 实施共性回流沉淀
│ 多模式继承 / Upstream 合并
↓
[ 下游:行业版/区域版/客户化变体 ]
- 研发(上游):负责产品主干、通用模块与域模型(高质量、可扩展、可复用);
- 实施(下游):在同一元数据与扩展点上做行业/客户化变体;
- 回流机制:实施中沉淀的共性能力可回流上游形成通用模块;
- 统一治理:版本基线、差异比对、冲突合并、灰度/回滚一体化。
Oinone 的对应能力
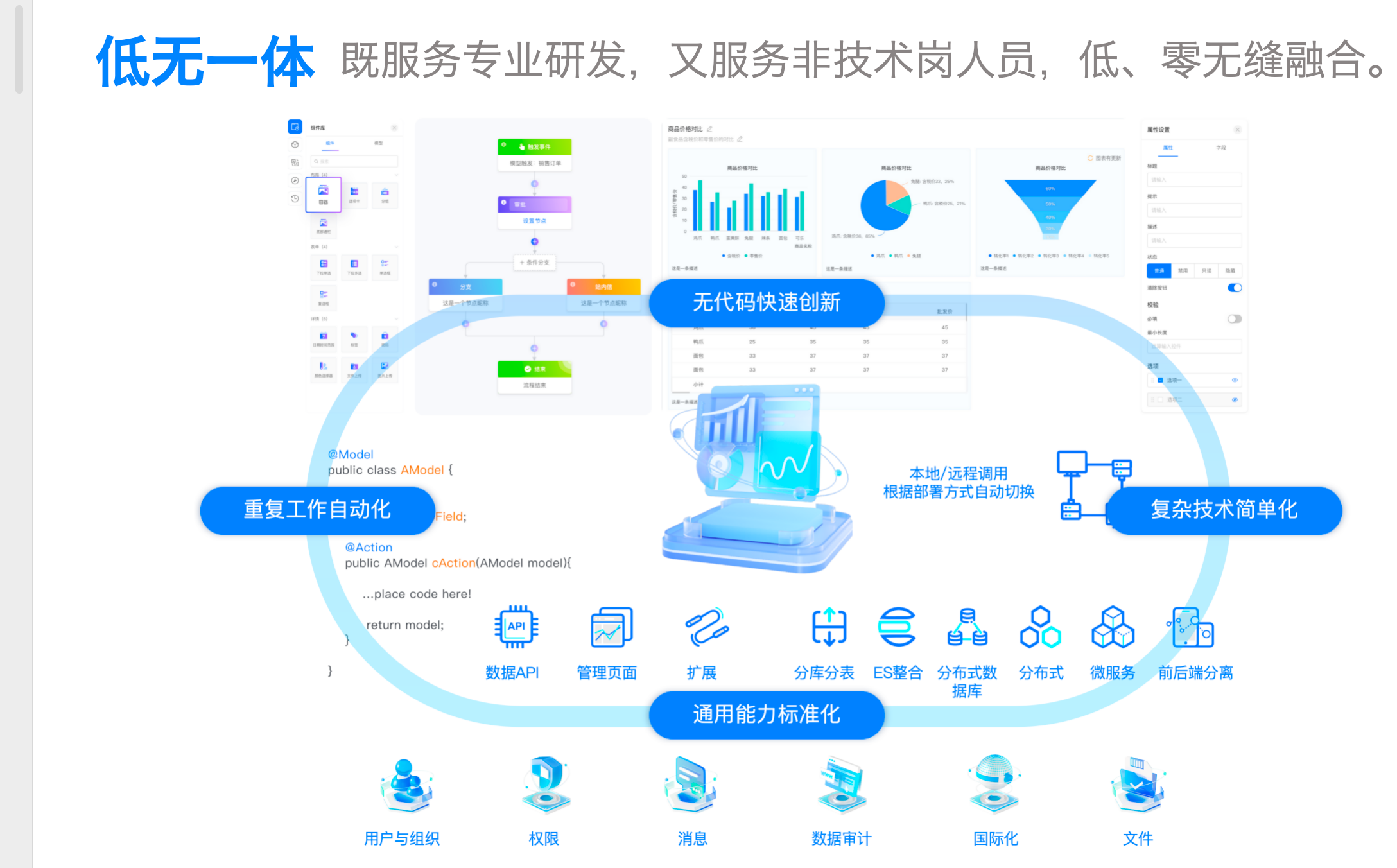
- 多模式继承 + Upstream 架构:让标品升级与个性化共存,每个需求都可模块化沉淀;
- 被集成原则:在 Oinone 能力之外,仍可复用企业原有系统与三方开源框架;
- 可分可合部署:单体/分布式按阶段演进;
- 100% 元数据化:模型、关系、行为、视图、流程、逻辑统一建模,便于回溯与治理;
- 国产生态适配:满足信创环境与大规模落地(你方已提供的客户实践可为背书);
- 核心框架开源 + Codelab 社区:便于二次开发与最佳实践沉淀。
三、氛围编程下,能否把“研发 + 交付实施”真正合一?
短答:可以大幅收敛距离,但需要“AI‑Native + 元数据先行 + 人在回路(HITL)”。 AI 不是魔法棒,它需要“可被理解的结构化描述”。这正是 Oinone 100% 元数据化的价值所在——AI 能读懂、能生成、还能解释与回写。
现在 AI 能稳定做的
- 需求到模型草案:把自然语言需求转为领域对象/字段/关系/校验候选;
- 页面/流程生成:基于模型生成列表/表单/审批/编排蓝图,并输出可读差异;
- 规则与接口样板:验证规则、API 壳、测试用例、Mock 数据、变更影响面分析;
- 可解释/可审计:生成内容溯源到元数据,支持审阅、评论、回滚与再训练提示词;
- 知识注入:引入企业字典、合规条款、风控规则,指导生成更贴近场景。
仍需工程与实施把关的
- 跨域复杂约束与非功能性指标(性能、并发、弹性、成本)权衡;
- 黑天鹅边界(稀有业务场景、历史遗留系统互操作);
- 上线责任:安全、合规、可观测、SLA 与容量规划。
可落地的“AI‑in‑the‑Loop”闭环
自然语言需求 → AI 解析 → 元数据草案
↑ ↓
运行日志/缺陷 ← 审阅/约束/修订 ← 生成页面/流程/API/测试
└────────── 持续回流与再训练(提示词/约束模板) ─────────┘
和 Oinone 的契合点
- 因为一切皆元数据,AI 有“看得懂”的载体;
- 生成的变更可走 Oinone 的版本/差异/回滚治理;
- 上游/下游继承关系与模块依赖,可为 AI 提供约束边界,避免“乱改动”。
四、如何评估你们的“创造+实施一体化”成熟度(可直接自测)
| 维度 | 关键问题 | 目标值(可参考) |
|---|---|---|
| 元数据完备度 | 模型/关系/视图/流程/规则/权限是否统一建模 | 覆盖 ≥ 90% |
| 资产沉淀率 | 新项目功能中来自“已沉淀模块”的比例 | ≥ 60% |
| 升级冲突率 | 上游升级引发的合并冲突占比 | ≤ 10% 且可自动化合并 |
| 实施回流率 | 实施中识别为“共性”的功能成功回流上游的比例 | ≥ 30% |
| AI 命中率 | AI 自动生成后人工只需微调即可发布的改动占比 | ≥ 50% |
| 交付可观测 | 从需求到上线的端到端可追溯(含审计/回滚) | 100% 受控 |
五、常见误区与规避
- 误把“能拖拽”当“能产品化”:没有继承与版本治理的,无论多快,最后都被分叉拖垮。
- 双轨模型(配置一套、代码一套)不打通:请优先选“元数据单源”的平台。
- AI 只做代码补全:要以元数据为核心做“生成—解释—回写—审计”闭环。
- 被集成忽视:务必在 POC 中同时验证对接 SSO/网关/监控与单体↔分布式切换。
最后我想说
- 低/无一体的关键不在“两个入口”,而在“同一元数据 + 同一引擎 + 同一治理”。
- 在这种范式下,研发与实施从“割裂的角色”转为“同一产品线的上/下游”,通过 Oinone 的多模式继承 + Upstream + 被集成原则 + 100% 元数据化,实现标准化、规模化与可持续升级。
- AI 能否解决“创造+实施一体”?有前提:AI‑Native + 元数据先行 + 人在回路。在 Oinone 这样的元数据平台上,AI 已能把从“需求→模型→页面/流程→测试”的大量工作自动化,并在统一治理下可解释、可回滚、可回流,创造与实施的距离被切实缩短。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)