【机器学习】——回归2:非线性回归
线性回归模型形式简单,可解释性强,有着大量的理论支撑,但是在实际问题中,很多关系往往不能用线性模型简单地概括。因此需要引入非线性回归模型。
对于一些典型的非线性回归模型,通过变量代换,我们可以将其转化为线性回归模型来解决。
一、多项式回归(Polynomial Regression)
1.1多项式回归函数
✅ 1.1.1 当自变量和因变量都为一维时:
通常多项式回归模型函数的形式为:
为了方便表达,我们可以将上式写为矩阵形式:
即:
-
是预测值向量,包含所有样本的预测结果。
-
是设计矩阵,每一行对应一个样本的特征值及其高次幂。
-
是参数向量,包含所有模型参数。
✅ 1.1.2 当自变量和因变量都为多维时:
当自变量变为 维,因变量变为
维时,多项式回归模型将变得更加复杂,但基本原理仍然相同。我们可以通过扩展设计矩阵来处理多维自变量的情况,同时因变量的多维性意味着我们需要预测多个目标值。
多维自变量和单维因变量的情况:
一共有 个样本,对于第
个样本
,假设自变量
是一个
维向量,即
,因变量
是一个标量。
多项式回归模型可以表示为:
矩阵形式可以表示为:
其中:
-
模型参数
是
维列向量。
-
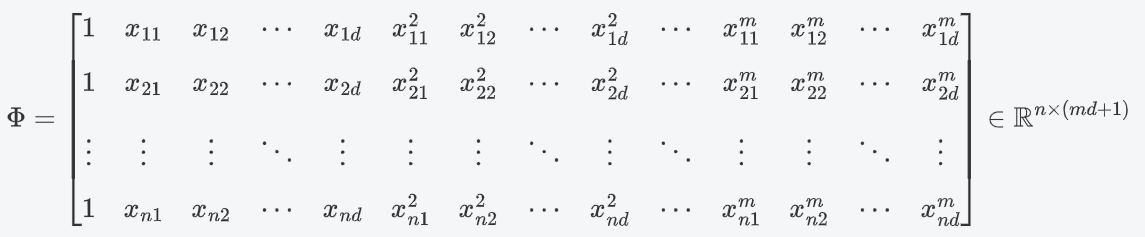
设计矩阵
:(每一行对应一个样本,每一列对应一个特征或特征的高次幂)(以
为例)
多维自变量和多维因变量的情况:
一共有 个样本,对于第
个样本
:
-
自变量
,即
;
-
因变量
,即
。
对每个输出维度 分别建立多项式回归模型:
将所有 个模型写成矩阵形式:
其中:
-
,第
行为
;
-
,第
列为第
-
设计矩阵
1.2 标准方程法求解
在多项式回归中,由于自变量的指数增大,写出损失函数后,对每个参数进行求导等操作的运算量也随之变大,对此我们希望能够将一些线性回归的知识迁移运用,简化计算公式,减少计算成本。
损失函数(对于因变量为一维的情形):
对 求梯度:
整合之前学过的知识,我们要解决的凸优化问题为 ,若损失函数图像具有强凸性,则
为正定矩阵,那么最小二乘法同样适用,最优解为:
1.3 Python实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
# 生成含高斯噪声的训练集,含50个样本,并作出散点图
X = 5 * np.random.rand(50, 1) - 2.5 # 这里减去2.5是为了方便我们看到整个散点图轮廓
noise = np.random.rand(50, 1)
y = 0.6 * X**2 + 2 * X + 1 + noise
plt.scatter(X, y)
'''
从散点图判断用二次函数或可拟合,
我们要用原有的数据集X生成方便非线性转为线性解决的新数据集,
这里我们可以用sklearn库中现成的PolynomialFeatures模块函数
'''
pf = PolynomialFeatures(degree=2, include_bias=True)
# 该函数用于构建设计矩阵
# degree=2表示多项式的阶数m为2,include_bias为True代表包含x_0=1的项
train_X = pf.fit_transform(X)
# 标准方程法
theta = np.zeros([3, 1])
theta = np.linalg.inv((train_X.transpose()) @ train_X) @ train_X.transpose() @ y
# @符号为python运算中的矩阵点乘符号
# 现在我们已经得到了参数,绘制函数,查看拟合效果
x = np.linspace(-3, 3, 100)
hypothesis_function = theta[0] + theta[1] * x + theta[2] * x * x
plt.plot(x, hypothesis_function, color='darkorange')
plt.show()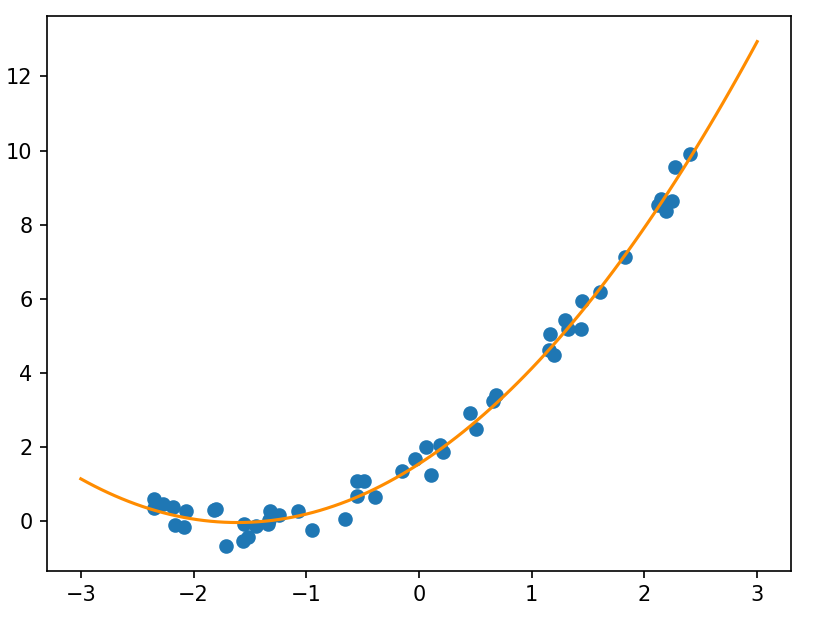
二、径向基回归(Radial-basis Regression)
径向基函数是一个取值仅依赖于到原点距离的实值函数,即:
任一满足上式的函数都可称作径向函数。最常用的径向函数为高斯函数。
2.1 高斯核函数(Gaussian Kernel)
2.1.1 公式定义
最常用的高斯核函数表达式为:
其中 :
-
为第 i 个中心点(均值)
-
为带宽参数(方差)
使用矩阵形式表示:
即:
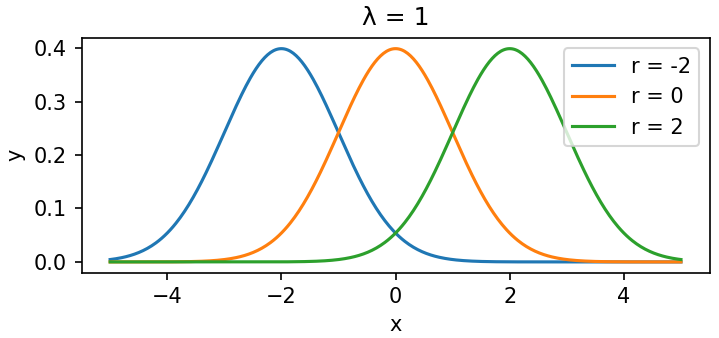
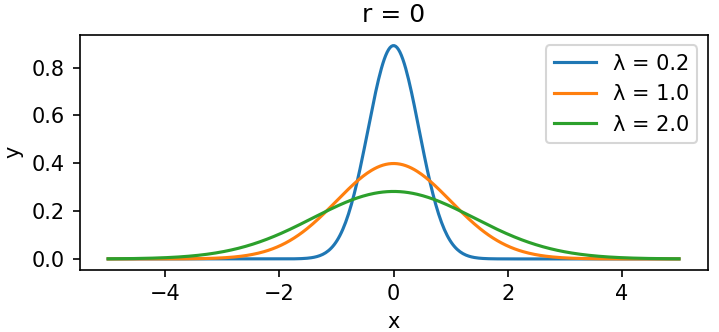
2.1.2 一维特征下的图像特点
-
固定
,改变 r:曲线整体左右平移,形状不变。
-
固定
,改变
:
'''使用pyhton作图'''
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-5, 5, 400)
# --------------------------------------------------
# 1) 固定 λ = 1,改变 r
# --------------------------------------------------
plt.figure(figsize=(5, 2.5))
for r in [-2, 0, 2]:
y = np.exp(-(x - r) ** 2 / 2) / np.sqrt(2 * np.pi)
plt.plot(x, y, label=f'r = {r}')
plt.title('λ = 1')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.tight_layout()
plt.show()
# --------------------------------------------------
# 2) 固定 r = 0,改变 λ
# --------------------------------------------------
plt.figure(figsize=(5, 2.5))
for lam in [0.2, 1.0, 2.0]:
y = np.exp(-(x ** 2) / (2 * lam)) / np.sqrt(2 * np.pi * lam)
plt.plot(x, y, label=f'λ = {lam}')
plt.title('r = 0')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.tight_layout()
plt.show()| 图1 | 图2 |
|---|---|
 |
 |
2.1.3 二维特征下的图像特点
'''使用Python作图'''
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # noqa: F401 仅用于激活 3D
# 1) 网格
x = np.linspace(-4, 4, 200)
y = np.linspace(-4, 4, 200)
X, Y = np.meshgrid(x, y)
pos = np.dstack((X, Y)) # (N,N,2)
# 2) 二维高斯函数
def gauss_2d(pos, r, lam1, lam2, theta=0):
"""
pos : (N,N,2) 坐标网格
r : (2,) 均值向量 [rx, ry]
lam1 : x 方向方差
lam2 : y 方向方差
theta : 旋转角 (rad),默认 0
"""
Σ = np.array([[lam1, 0],
[0, lam2]])
# 旋转协方差矩阵
c, s = np.cos(theta), np.sin(theta)
R = np.array([[c, -s],
[s, c]])
Σ = R @ Σ @ R.T
Σ_inv = np.linalg.inv(Σ)
det = np.linalg.det(Σ)
diff = pos - r # (N,N,2)
# 向量化计算 (x-μ)^T Σ^{-1} (x-μ)
Z = np.einsum('...k,kl,...l->...', diff, Σ_inv, diff)
Z = np.exp(-0.5 * Z) / (2 * np.pi * np.sqrt(det))
return Z
# 3) 绘图
r = np.array([0, 0])
lam1, lam2 = 1.5, 0.5
theta = np.pi/6
Z = gauss_2d(pos, r, lam1, lam2, theta)
fig = plt.figure(figsize=(6, 4.5))
ax = fig.add_subplot(111, projection='3d')
surf = ax.plot_surface(X, Y, Z, cmap='viridis',
linewidth=0, antialiased=True)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('G(x,y)')
ax.set_title(f'2D Gaussian\nr={r}, λ₁={lam1}, λ₂={lam2}, θ={np.degrees(theta):.0f}°')
fig.colorbar(surf, shrink=0.5, aspect=8)
plt.tight_layout()
plt.show()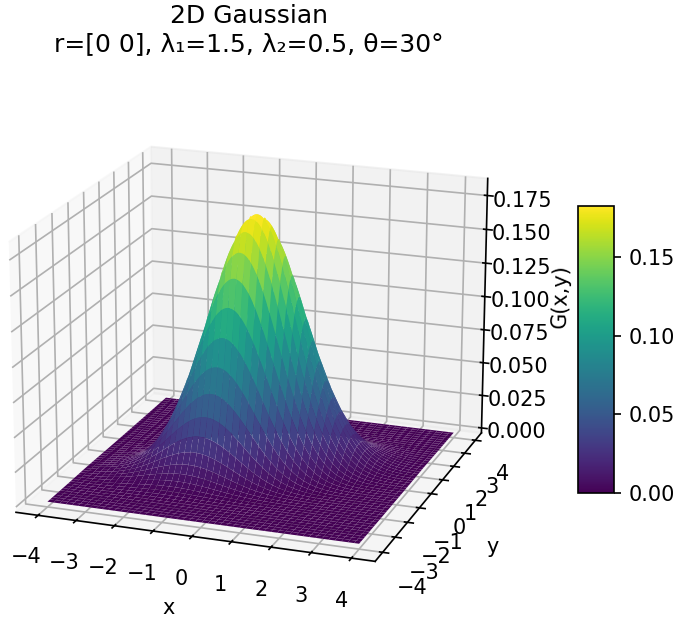
2.1.4 最优解
数据的拟合函数曲线是这些均值方差不同的高斯分布函数即的加权叠加。此外,由于
本身是指数函数,所以它的值必大于 0,
,可用标准方程法,得其最优解为:
2.2 参数的选取
-
中心点 (
-
带宽 (
好的 RBF 模型要求
-
中心点分布合理
-
带宽足够覆盖足够多的样本点,以提高泛化能力。
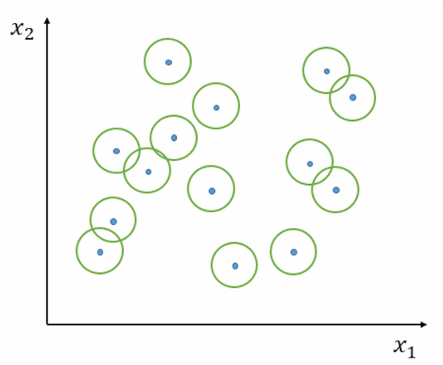
例:二维特征空间
若圆心(中心点)选择过少或半径(带宽)过小,模型易出现“群山耸立”现象,泛化能力弱。
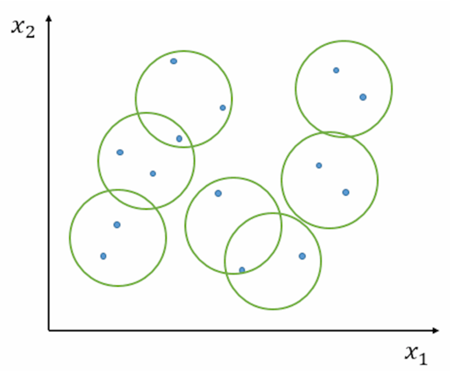
通过适当调整中心点和半径,可获得更平滑且泛化性能更好的拟合曲面。
| 拟合极差的 RBF 模型平面投影图像 | 拟合较好的 RBF 模型平面投影图像 |
|---|---|
 |
 |

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 37
37 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)