【Python机器学习系列】一文教你建立LightGBM与XGBoost融合模型预测房价(案例+源码)
·
这是我的第429篇原创文章。
一、引言
LightGBM和XGBoost是两种高效的梯度提升决策树算法,常用于回归和分类任务,通过逐步优化模型来提升预测精度,并支持并行计算以加速训练过程,我们的组合模型通过分别训练LightGBM和XGBoost模型,然后对它们的预测结果取平均值,以进一步提高预测的准确性和稳健性。
二、实现过程
2.1 数据读取
核心代码:
filename = 'data.csv'
names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS',
'RAD', 'TAX', 'PRTATIO', 'B', 'LSTAT', 'MEDV']
dataset = pd.read_csv(filename, names=names, delim_whitespace=True)
df = pd.DataFrame(dataset)
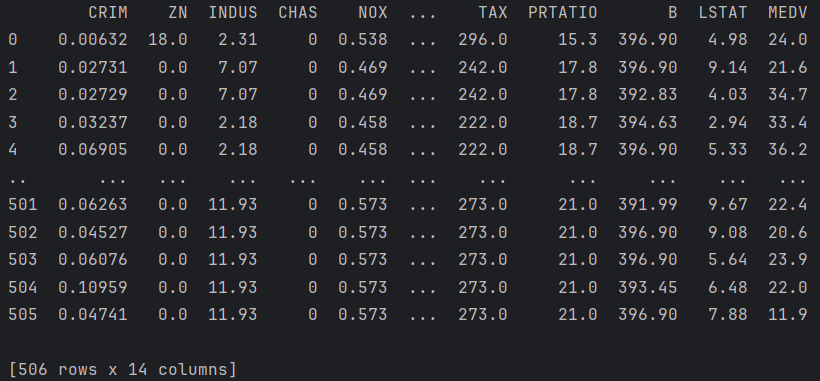
print(df)结果:
2.2 数据集划分
核心代码:
X_temp, X_test, y_temp, y_test = train_test_split(df.iloc[:,0:7], df['MEDV'], test_size=0.2, random_state=42)
# 然后将训练集进一步划分为训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X_temp, y_temp, test_size=0.125, random_state=42) # 0.125 x 0.8 = 0.1
# 输出数据集的大小
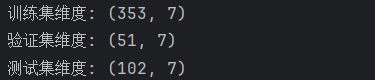
print(f"训练集维度: {X_train.shape}")
print(f"验证集维度: {X_val.shape}")
print(f"测试集维度: {X_test.shape}")结果:
2.3 数据预处理
核心代码:
train_y, val_y, test_y, scaler_y = normalize_dataframe(y_train, y_val, y_test)2.4 定义和训练模型
核心代码:
model_lgb = lgb.LGBMRegressor(**params_lgb)
model_xgb = xgb.XGBRegressor(**params_xgb)
# 定义平均模型
class AverageModel:
def __init__(self, models):
self.models = models
def fit(self, X, y, X_val, y_val):
for model in self.models:
if isinstance(model, lgb.LGBMRegressor):
model.fit(X, y, eval_set=[(X_val, y_val)], eval_metric='rmse', callbacks=[lgb.early_stopping(stopping_rounds=100)])
elif isinstance(model, xgb.XGBRegressor):
model.fit(X, y, eval_set=[(X_val, y_val)], eval_metric='rmse', early_stopping_rounds=model.get_params()['early_stopping_rounds'], verbose=False)
def predict(self, X):
predictions = []
for model in self.models:
predictions.append(model.predict(X))
return sum(predictions) / len(predictions)
# 创建平均模型
average_model = AverageModel([model_lgb, model_xgb])
# 训练模型
average_model.fit(X_train, train_y, X_val, val_y)代码定义了一个名为 AverageModel 的类,用于创建一个平均模型,通过集成LightGBM和XGBoost模型的预测结果来提升预测的稳定性和准确性,在 fit 方法中,该类可以同时训练传入的多个模型,并使用验证集进行早期停止策略来防止过拟合,在 predict 方法中,该类将多个模型的预测结果取平均作为最终的预测输出。
2.5 预测测试集
核心代码:
y_pred = average_model.predict(X_test)
print(y_pred)结果:
2.6 计算评估指标
核心代码:
y_pred_list = y_pred.tolist() # 或者 y_pred_array = np.array(y_pred)
mse = metrics.mean_squared_error(test_y, y_pred_list)
rmse = np.sqrt(mse)
mae = metrics.mean_absolute_error(test_y, y_pred_list)
r2 = metrics.r2_score(test_y, y_pred_list)
print("均方误差 (MSE):", mse)
print("均方根误差 (RMSE):", rmse)
print("平均绝对误差 (MAE):", mae)
print("拟合优度 (R-squared):", r2)结果:

2.7 可视化预测结果
核心代码:
# 反归一化
train_min = np.min(y_train)
train_max = np.max(y_train)
pred = y_pred * (train_max - train_min) + train_min
y_test = np.array(y_test)
# 计算预测值 真实值差值的绝对值
alpha_values = abs(pred-y_test.reshape(-1)) # 值越大alpha越大
# 确保 alpha 值在 0 到 1 之间
alpha_values = np.clip(alpha_values, 0, 1)
plt.scatter(pred, y_test, color='blue', edgecolor='k', s=50, alpha=alpha_values, label='预测值 vs 真实值')
plt.title('预测值与真实值对比图', fontsize=16)
plt.xlabel('预测值', fontsize=14)
plt.ylabel('真实值', fontsize=14)
max_val = max(max(pred), max(y_test))
min_val = min(min(pred), min(y_test))
plt.plot([min_val, max_val], [min_val, max_val], color='red', linestyle='--', linewidth=2, label='x=y')
plt.grid(True, linestyle='--', alpha=0.7)
plt.legend()
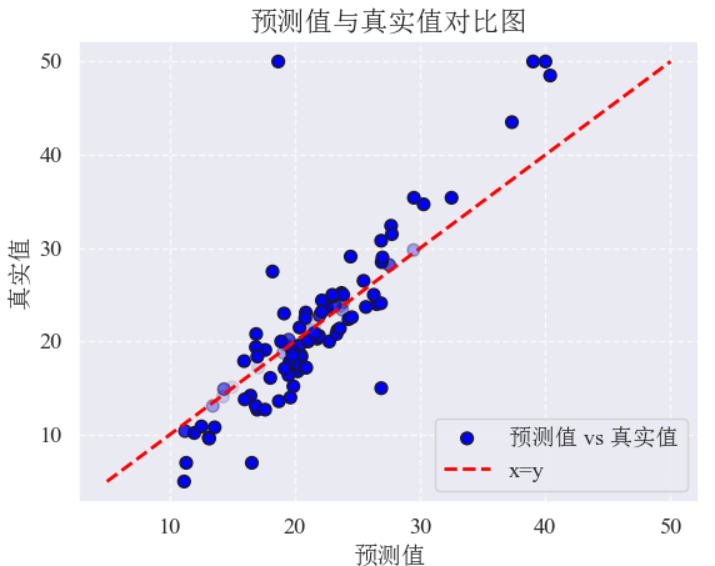
plt.show()结果:图中横轴表示模型预测的值,纵轴表示真实的标签值,每个点的透明度(alpha 值)根据预测值与真实值的差异大小动态调整,差异越大的点透明度越低,红色虚线表示理想情况下预测值等于真实值的对角线。
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 5
5 0
0- 0



 已为社区贡献127条内容
已为社区贡献127条内容

所有评论(0)