机器学习03-特征工程(一)-->特征抽取
·
目录
1.1 特征工程
1.1.1 意义及内容
“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”——吴恩达
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程,在很大程度上影响着机器学习的效果
包括了:
- 特征抽取
- 特征预处理
- 特征降维
1.1.2 特征工程的位置与数据处理的比较
- pandas:数据清洗、数据处理
- sklearn:特征工程
1.2 特征抽取
1.2.1 内容
将任意数据(包括文本或图像)转换为可用于机器学习的数字特征,以便于计算机更好地理解数据
包括:
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取(深度学习介绍)
1.2.2 特征提取API
sklearn.feature_extraction
1.3 字典特征提取
1.3.1 目的
对字典数据进行特征值化
1.3.2 方法
sklearn.feature_extraction.DictVectorizer(sparse=True,...)- DictVectorizer.fit_transform(X) X:字典或者包含字典的迭代器(本例中是包含了字典的列表)返回值,返回sparse矩阵(稀疏矩阵)
- DictVectorizer.inverse_transform(X)X:array数组或者sparse矩阵 返回值:转换之前数据格式
- DictVectorizer.get_feature_names() 返回特征名称(表头)
- 例如:有一个有三个样本两个特征的字典
[{'child':'小红','age':12},
{'child':'小明','age':15},
{'child':'大壮','age':14}]
经过转换后:三个类别都变成了特征
['child'='小红','child'='小明','child'='大壮','age']
[[ 1. 0. 0. 12.]
[ 0. 1. 0. 15.]
[ 0. 0. 1. 14.]]
注:这种表示方法也叫做one-hot编码/热编码/one-hot-vector
1.3.3 过程
data = [{'city': '北京', 'temperature': 100}, {'city':'上海', 'temperature': 60}, {'city': '深圳', 'temperature': 20}]
from sklearn.feature_extraction import DictVectorizer
transfer = DictVectorizer()# 此处默认返回sparse稀疏矩阵,(省略的是sparse=True)
data_new = transfer.fit_transform(data)
print(data_new)
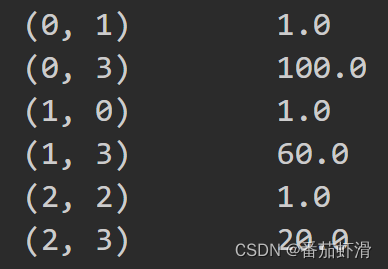
这里出现的结果,是将稀疏矩阵中的0省略,只显示1在矩阵中的坐标,以此来节省内存的,表示方式,我们转换一下成二维数组就好:只需要把True变False
transfer = DictVectorizer(sparse=False)# 返回二维数组
data_new = transfer.fit_transform(data)
print(transfer.get_feature_names())
print(data_new)

思考:如果我们想把一些不同类别的样本用1,2,3,4…这种数字来表示,那么不同的类别就有了不同权重,也就不再“平等”,之间有了“大小关系”,所以我们采用稀疏矩阵的方式
1.3.4 什么时候用
(1)数据集中,表示类别的特征比较多的时候
(2)拿到的数据就是字典类型时

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)