机器学习实战—预测数值型数据:回归
一、用线性回归找到最佳拟合直线
回归的目的是预测数值型的目标值,即依据输入写出一个目标值的计算公式。 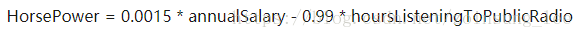
这个公式就是所谓的回归方程,此处的HorsePower是我们要求的目标值,0.0015和-0.99就是回归方程的回归系数,annualSalary和hourListingToPublicRadio是计算目标值所需要输入的值。
求这些回归系数的过程就是回归。
给定输入X矩阵,回归系数存放在向量W中,求解回归方程,现在已知数据为X和Y,只有回归系数W矩阵未知,所以现在求解回归方程的问题转化为求解系数矩阵W的问题,求解W可通过最小化误差平方和来解决,因为简单的误差累加会使得正差值和负差值相互抵消,所以采用平方误差。 


所以回归系数向量W的估计为 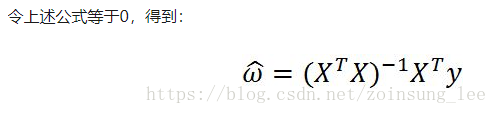
注:公式中包含有矩阵的逆计算,因此这个计算方程必须满足矩阵乘积可逆的条件,所以必须在程序中对这一条件进行判断。
标准回归函数和数据导入的函数:
import numpy as np
#数据加载函数
def loadDataSet(filename):
dataArr = []
labesArr = []
#数据集中除了最后一行是目标值外,其他的列都是输入特征值
featNum = len(open(filename).readline().strip().split('\t')) - 1
fp = open(filename)
#遍历文件内容,初始化数据集和目标集
for line in fp.readlines():
#把每行数据中的空格去掉,并且以制表符分割为数组,此时数组中既包含输入特征,也包括要预测的样本目标值
#需要将它们分别加入数据集数组和目标值数组中
curLine = line.strip().split('\t')
lineArr = []
for i in range(featNum):
lineArr.append(float(curLine[i]))
dataArr.append(lineArr)
labesArr.append(float(curLine[-1]))
return dataArr,labesArr
#标准回归函数回归系数求解函数
def standRegres(xArr,yArr):
#将两个数据集转换为矩阵形式
xMat = np.mat(xArr)
#将目标集数组转换为列向量矩阵,保证矩阵运算可以进行
yMat = np.mat(yArr).T
#计算数据矩阵的平方
xtx = xMat.T * xMat
#利用行列式值计算公式计算矩阵行列式值,以得知该矩阵是否可逆
#如果不可逆,立即返回;否则继续计算回归系数向量
if np.linalg.det(xtx) == 0:
print("该矩阵的行列式值为零,其矩阵不可逆")
return
ws = xtx.I * (xMat.T * yMat)
return ws绘制最佳拟合直线与绘制散点图函数:
#图像绘制函数
def plotFigure_stand(dataArr,labesArr,ws):
import matplotlib.pyplot as plt
#创建绘图对象
fig = plt.figure()
#固定画笔位置
ax = fig.add_subplot(111)
#绘制散点图
# 对训练集进行预测
xMat = np.mat(dataArr)
yMat = np.mat(labesArr)
# 需要对x排序,保证绘图正确
xCopy = np.copy(xMat)
xCopy.sort(0)
yHat = xCopy * ws
ax.scatter(xMat[:,1].flatten().A[0],yMat.T[:,0].flatten().A[0])
#绘制计算出的最佳拟合直线
#绘制直线,数据集第一列作为x轴的值,预测值作为y轴的值
ax.plot(xCopy[:,1],yHat)
plt.show()
计算两个两个序列的相关系数,用来衡量寻找到的最佳拟合直线的拟合效果:
#计算预测值和真实值两个序列的相关系数
def calCoef(dataArr,labesArr,ws):
xMat = np.mat(dataArr)
yMat = np.mat(labesArr)
yHat = xMat * ws
#利用函数计算两个行向量的相关系数
corrNum = np.corrcoef(yHat.T, yMat)
return corrNum二、局部加权线性回归
线性回归可能会出现欠拟合现象,因为它求的是具有最小均方误差的无偏估计,所以有时候需要引入一些偏差来降低预测的均方误差。其中一个方法就是局部加权线性回归(LWLR)。在该算法中,我们给待预测点附近的点赋予一定的权重,在这个附近点自己中基于最小均方差来进行普通回归。
该算法求解W的公式如下: 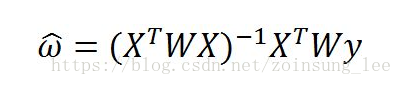
LWLR使用高斯核函数对附近点赋权重: 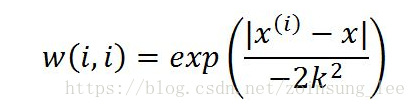
注:此处的权重矩阵是一个对称矩阵,这样才能保证在矩阵运算中给每个附近样本附上权重。临近点距离预测点越近,其样本权重越大;距离越远,权重越小。
局部加权线性回归函数:
#局部加权线性回归预测函数(对于单个测试样本点),k为用户自定义参数,是计算权重的高斯核函数的参数,影响每个样本的权重
def lwlr(testPoint, xArr, yArr, k = 1.0):
xMat = np.mat(xArr)
yMat = np.mat(yArr).T
#获得测试样本附近的样本点个数
m = np.shape(xMat)[0]
#创建临近点权重的对角矩阵,初始化元素为1
weightsMat = np.mat(np.eye((m)))
#遍历整个数据集,根据高斯核函数更新样本点权重,距离测试点越近的样本点的权重越大
for i in range(m):
#计算测试点与当前临近点的距离
diffMat = testPoint - xMat[i,:]
#根据距离计算该临近点的权重值,并将该值添加至对角矩阵的对应位置上
weightsMat[i,i] = np.exp(diffMat*diffMat.T/(-2.0*k**2))
xtx = xMat.T * (weightsMat * xMat)
if np.linalg.det(xtx) == 0.0:
print("矩阵不可逆")
return
#根据公式计算回归系数矩阵
ws = xtx.I * (xMat.T * (weightsMat * yMat))
#返回该测试点的预测值
return testPoint * ws
#对整个测试集的预测函数
def lwlrTest(testArr, xArr, yArr, k=1.0):
#获取测试集样本个数
m = np.shape(testArr)[0]
#定义预测值向量
yHat = np.zeros(m)
#遍历测试集,对每个数据点进行预测
for i in range(m):
yHat[i] = lwlr(testArr[i], xArr, yArr, k)
return yHat局部加权线性回归最佳拟合图像绘制函数:
#局部加权线性回归图像绘制
def plotFigure_lwlr(xArr, yArr, yHat):
xMat = np.mat(xArr)
yMat = np.mat(yArr)
#对矩阵第一列的值以升序排列并且返回排列索引值列表
srtInd = xMat[:,1].argsort(0)
#对整个矩阵一排序好的索引值顺序排序(升序)
xSort = xMat[srtInd][:,0,:]
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111)
#绘制最佳拟合直线
ax.plot(xSort[:,1],yHat[srtInd])
#绘制散点
ax.scatter(xMat[:,1].flatten().A[0],yMat.T.flatten().A[0],s=2,c='red')
plt.show()
注:局部加权线性回归存在计算量大的问题,因为它对每个点做预测的时候都必须调整整个数据集,因为每次的数据样本权重不一致,逻辑上可认为数据集在不断调整。
三、示例:预测鲍鱼年龄
计算预测误差函数:
#计算误差平方和来评判回归效果
def errSum(yArr, yHatArr):
return ((yArr - yHatArr)**2).sum()四、缩减系数理解数据
如果数据的特征比样本点多,即输入数据X矩阵不是满秩的,会出现非满秩矩阵在求逆时出现问题。为了解决这一问题,我们使用一种缩减的方法,将某些不重要的特征的系数置为0,逻辑上就是减少特征数量。这种方法就是岭回归算法。
岭回归就是在矩阵(X.T*X)上加上lambda*I从而使矩阵非奇异,继而使得矩阵可求逆,矩阵I是一个N*N的单位阵,在这种情况下,回归系数计算公式将变为: 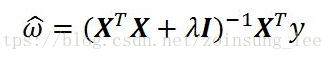
岭回归这里引入lambda来限制了所有回归系数的和,通过引入该惩罚项,能够减少不重要的参数,这种技术在统计学中叫做缩减技术。
1.岭回归:
#通过岭回归方法避免数据特征大于样本点数量而导致的矩阵不可逆问题
def ridgeRegres(xMat, yMat, lam=0.2):
xtx = xMat.T*xMat
m,n = np.shape(xMat)
# print("n:",n)
# print("np.shape(xMat)[1]:",np.shape(xMat)[1])
#!!!注意这里的单位矩阵是n*n的,不是m*m
#使用岭回归方法加入单位矩阵与lambda的乘积矩阵
denom = xtx + np.eye(np.shape(xMat)[1])*lam
if np.linalg.det(denom) == 0.0:
print("矩阵不可逆")
return
ws = denom.I * (xMat.T*yMat)
return ws
#在岭回归方法上的测试函数
def ridgeTest(xArr, yArr):
xMat = np.mat(xArr)
yMat = np.mat(yArr).T
#对每列数据进行标准化,使得每列数据的权重保持一致
yMean = np.mean(yMat,0) #对目标值一列求平均值
yMat = yMat - yMean
xMeans = np.mean(xMat,0)#对特征集中的每一列求平均值
xVar = np.var(xMat,0) #对特征集的每一列求方差
xMat = (xMat - xMeans)/xVar #将每个数据标准化
#定义测试样本数量为30个
numTestPts = 30
#定义回归系数矩阵
wMat = np.zeros((numTestPts,np.shape(xMat)[1]))
#遍历测试样本集,预测每个测试样本的回归系数,组成测试集的回归系数矩阵
for i in range(numTestPts):
ws = ridgeRegres(xMat,yMat,np.exp(i-10))
wMat[i,:] = ws.T
return wMat
注:在使用岭回归算法中,需要对数据集进行标准化处理。
可视化岭回归系数变化函数:
#绘制岭回归系数和lambda之间的关系
def ridgePlot(ridgeWeights):
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111)
#绘制三十个回归系数
ax.plot(ridgeWeights)
plt.show()2.向前逐步回归
向前逐步回归属于一种贪心算法,它的每一步都尽可能减少误差,一开始所有权重都设为1,然后每一步所做的决策是对某个权重增加或减少一个很小的值。
算法伪代码:
数据标准化,使其分布满足0均值和单位方差
在每轮迭代中:设置当前最小误差lowestError为正无穷
对每个特征:
增大或缩小:
改变一个系数得到一个新的W
计算新W下的误差
如果误差Error小于当前最小误差lowestError:设置Wbest等于当前的W
将W设置为新的Wbest
向前逐步线性回归:
#训练集标准化函数:
def regularize(xMat):
xMean = np.mean(xMat,0) #计算每一列均值
xVar = np.var(xMat,0) #计算每一列方差
xMat = (xMat - xMean)/xVar #对数据集中的每一个数据进行标准化
return xMat
#逐步向前回归计算权重函数
def stageWise(xArr, yArr, eps=0.01, numIt=100):
xMat = np.mat(xArr)
yMat = np.mat(yArr).T
#标准化数据集
yMean = np.mean(yMat,0)
yMat = (yMat - yMean)
xMat = regularize(xMat)
#获取数据集行列
m,n = np.shape(xMat)
#初始化权重矩阵,每一次迭代的权重向量,每一迭代的测试权重向量,以及每一迭代中最优权重向量
#每一次迭代都会一个权重向量
returnMat = np.zeros((numIt,n))
ws = np.zeros((n,1))
wsTest = ws.copy()
wsBest = ws.copy()
#开始迭代
for i in range(numIt):
print("第%d次迭代的权重向量:"%i,ws.T)
#初始化最小方差值
lowerError = np.inf
# 遍历每个特征
for j in range(n):
#对于每次优化是增加还是减小进行决策
for sign in [-1,1]:
wsTest = ws.copy()
#对权重向量中该位置的权重进行小值范围内的更新
wsTest[j] += eps * sign
#预测
yTest = xMat * wsTest
#计算误差
rssE = errSum(yMat.A, yTest.A)
#比较当前误差值是否小于最小误差值
if rssE < lowerError:
#当前误差值小于最小误差值,则更新最小误差值,记录此次最佳权重向量
lowerError = rssE
wsBest = wsTest
ws = wsBest.copy()
#将此次迭代得出的最佳权重向量添加至权重矩阵中
returnMat[i,:] = ws.T
return returnMat注:当应用缩减方法时,模型也就增加了偏差,与此同时却减小了方差。这就是所谓的偏差与方差折中。
六、示例:预测乐高玩具套装的价格
书中使用的谷歌API已经关闭,所以这里使用的是数据集的.html格式的文件,所以需要对html文件进行解析,以此来获得每次迭代的特征集,和回归真实集。
购物信息的获取函数:
#预测乐高玩具套装的价格
#使用谷歌api获取数据,并对返回的Json数据进行解析
#此API已经停止开放
# def searchForSet(retX,retY,setNum,yr,numPce,origprc):
# from time import sleep
# import json
# import urllib3
# sleep(10)
# myAPIstr = 'get from code.google.com'
# searchURL = 'https://www.googleapis.com/shopping/search/v1/public/products?key=%s&country=US&q=lego+%d&alt=json'%(myAPIstr,setNum)
# pg = urllib3.proxy_from_url(searchURL)
# pp = pg.urlopen(searchURL)
# retDict = json.load(pp.read())
# for i in range(len(retDict['item'])):
# try:
# currItem = retDict['item'][i]
# if currItem['product']['condition'] =='new':
# newFlag = 1
# else:
# newFlag = 0
# listOfInv = currItem['item']['inventories']
# for item in listOfInv:
# sellingPrice = item['price']
# if sellingPrice > origprc*0.5:
# print("%d\t%d\t%d\t%f\t%f"%(yr,numPce,newFlag,origprc,sellingPrice))
# retX.append([yr,numPce,newFlag,origprc])
# retY.append(sellingPrice)
# except:
# print("problem with item %d"%i)
#我们现在有数据集的.html文件,通过beautifulsoup模块对.html文件进行解析,获得数据集和预测值
def scrapePage(retX, retY, inFile, yr, numPce, origPrc):
# -*-coding:utf-8 -*-
from bs4 import BeautifulSoup
# 打开并读取HTML文件
f = open(inFile,encoding='utf-8')
#获取html文件的全局对象
html = f.read()
#将文件对象转换为页面树结构对象
soup = BeautifulSoup(html)
i = 1
# 根据HTML页面结构进行解析
#获取到页面中所有table标签内容
currentRow = soup.find_all('table', r = "%d" % i)
while(len(currentRow) != 0):
#遍历所有table标签
currentRow = soup.find_all('table', r = "%d" % i)
#获取a标签中的文本
title = currentRow[0].find_all('a')[1].text
#转换为小写
lwrTitle = title.lower()
# 查找是否有全新标签
if (lwrTitle.find('new') > -1) or (lwrTitle.find('nisb') > -1):
newFlag = 1.0
else:
newFlag = 0.0
# 查找是否已经标志出售,我们只收集已出售的数据
soldUnicde = currentRow[0].find_all('td')[3].find_all('span')
if len(soldUnicde) == 0:
print("商品 #%d 没有出售" % i)
else:
# 解析页面获取当前价格
soldPrice = currentRow[0].find_all('td')[4]
priceStr = soldPrice.text
priceStr = priceStr.replace('$','')
priceStr = priceStr.replace(',','')
if len(soldPrice) > 1:
priceStr = priceStr.replace('Free shipping', '')
sellingPrice = float(priceStr)
# 去掉不完整的套装价格,如果二手价小于原价的1/2,则可认为该套装有破损
if sellingPrice > origPrc * 0.5:
print("%d\t%d\t%d\t%f\t%f" % (yr, numPce, newFlag, origPrc, sellingPrice))
#将套装特征值赋值
retX.append([yr, numPce, newFlag, origPrc])
retY.append(sellingPrice)
i += 1
currentRow = soup.find_all('table', r = "%d" % i)
def setDataCollect(retX,retY):
# searchForSet(retX,retY,8288,2006,800,49.99)
# searchForSet(retX, retY,10030,2002,3096,269.99)
# searchForSet(retX, retY,10179,2007,5195,499.99)
# searchForSet(retX, retY,10181,2007,3428,199.99)
# searchForSet(retX, retY,10189,2008,5922,299.99)
# searchForSet(retX, retY,10196,2009,3263,249.99)
scrapePage(retX, retY, 'lego\lego8288.html',2006,800,49.99)
scrapePage(retX, retY, 'lego\lego10030.html',2002,3096,269.99)
scrapePage(retX, retY, 'lego\lego10179.html', 2007, 5195, 499.99)
scrapePage(retX, retY, 'lego\lego10181.html', 2007, 3428, 199.99)
scrapePage(retX, retY, 'lego\lego10189.html', 2008, 5922, 299.99)
scrapePage(retX, retY, 'lego\lego10196.html', 2009, 3263, 249.99)
训练算法:建立模型
交叉验证测试岭回归:
#利用交叉验证测试岭回归
def crossValidation(xArr, yArr,numVal=10):
import random
#获取样本数量
m = len(yArr)
#获取样本数量下标列表,python3中range函数返回的是迭代器对象,而不是python2中的列表
# 所以这里需要将返回值强制转化为列表
indexList = list(range(m))
#该矩阵存储每次迭代所获得的30个系数向量所预测的目标值的对应误差
errMat = np.zeros((numVal,30))
#创建错误矩阵
#开始交叉验证(迭代),每次迭代通过交叉验证调整数据集
for i in range(numVal):
#定义每次迭代的训练集容器和测试集容器
trainX = []
trainY = []
testX = []
testY = []
#交叉验证之前打乱数据集顺序(这里打乱数据集的下标列表),以保证随机抽取数据
random.shuffle(indexList)
for j in range(m):
#将数据集的前百分之90设置为训练集,后百分之10设置为测试集
if j < m*0.9:
trainX.append(xArr[indexList[j]])
trainY.append(yArr[indexList[j]])
else:
testX.append(xArr[indexList[j]])
testY.append(yArr[indexList[j]])
#获得此次迭代的数据集后,获取岭回归算法得到的包含有30个向量的系数矩阵
wMat = ridgeTest(trainX,trainY)
#遍历整个系数向量矩阵,寻找最佳系数向量
for k in range(30):
#这里需要测试集进行标准化之后(使用训练时的参数对测试集进行标准化),喂入函数中
matTestX = np.mat(testX)
matTrainX = np.mat(trainX)
meanTrainX = np.mean(matTrainX,0)
varTrainX = np.var(matTrainX,0)
matTestX = (matTestX - meanTrainX)/varTrainX
#预测回归值
yEst = matTestX * np.mat(wMat[k,:]).T + np.mean(trainY)
# 获得使用此系数向量所预测得到的目标值的误差
errMat[i,k] = errSum(yEst.T.A,np.array(testY))
#计算每一列的平均值shape(1*30)
meanErrors = np.mean(errMat,0)
#获取最小平均误差
minError = float(np.min(meanErrors))
#获得具有最小误差的回归系数向量
bestWeight = wMat[np.nonzero(meanErrors==minError)]
#因为进入岭回归测试中的数据都是标准化之后的,所以在输出时需要打印原始数据
#这里需要将标准化后的回归系数还原回来
xMat = np.mat(xArr)
yMat = np.mat(yArr).T
meanX = np.mean(xMat,0)
varX = np.var(xMat,0)
unReg = bestWeight/varX
print("the best model from Ridge Regression is :\n",unReg)
print("with constant term:",-1*sum(np.multiply(meanX,unReg))+np.mean(yMat))注:以上所有函数均在main函数中调用,注释掉的代码为测试函数语句,以下为main函数:
if __name__ == "__main__":
# dataArr, labesArr = loadDataSet('ex0.txt')
# ws = standRegres(dataArr,labesArr)
# print("数据集的前两行为:\n",dataArr[0:2])
# print("回归系数向量为:\n",ws)
# #绘制散点和最佳拟合直线
# plotFigure_stand(dataArr, labesArr,ws)
# corrNum = calCoef(dataArr,labesArr,ws)
# print("相关系数为:\n",corrNum)
#传递不同的k值,绘制图像
# yHat = lwlrTest(dataArr, dataArr, labesArr, 1.0)
# plotFigure_lwlr(dataArr, labesArr, yHat)
# yHat = lwlrTest(dataArr, dataArr, labesArr, 0.01)
# plotFigure_lwlr(dataArr, labesArr, yHat)
# yHat = lwlrTest(dataArr, dataArr, labesArr, 0.003)
# plotFigure_lwlr(dataArr, labesArr, yHat)
#预测鲍鱼的年龄
#加载数据,前99个样本用于训练,后99个样本用于测试,分别传入不同的核进行预测比较
#比较回归误差和在训练集和在测试集上的效果
# xArr, yArr = loadDataSet('abalone.txt')
# yHat01 = lwlrTest(xArr[0:99], xArr[0:99], yArr[0:99], 0.1)
# yHat1 = lwlrTest(xArr[0:99], xArr[0:99], yArr[0:99], 1)
# yHat10 = lwlrTest(xArr[0:99], xArr[0:99], yArr[0:99], 10)
#
# err01 = errSum(yArr[0:99],yHat01.T)
# err1= errSum(yArr[0:99], yHat1.T)
# err10 = errSum(yArr[0:99], yHat10.T)
#
# print("train_err01:",err01)
# print("train_err1:", err1)
# print("train_err10:", err10)
#
# #测试
# test_yHat01 = lwlrTest(xArr[100:199], xArr[0:99], yArr[0:99], 0.1)
# test_yHat1 = lwlrTest(xArr[100:199], xArr[0:99], yArr[0:99], 1)
# test_yHat10 = lwlrTest(xArr[100:199], xArr[0:99], yArr[0:99], 10)
#
# err01 = errSum(yArr[100:199], test_yHat01.T)
# err1 = errSum(yArr[100:199], test_yHat1.T)
# err10 = errSum(yArr[100:199], test_yHat10.T)
#
# print("test_err01:", err01)
# print("test_err1:", err1)
# print("test_err10:", err10)
#使用岭回归方法进行测试,并画出回归系数与lambda的关系
# xArr, yArr = loadDataSet('abalone.txt')
# ridgeWeights = ridgeTest(xArr, yArr)
# ridgePlot(ridgeWeights)
#逐步向前回归测试
# xArr, yArr = loadDataSet('abalone.txt')
# returnMat = stageWise(xArr, yArr, 0.01, 200)
# print("returnMat:\n")
# print(returnMat)
#乐高示例数据获取函数测试
lgX = []
lgY = []
setDataCollect(lgX,lgY)
# lgX1 = addCol(lgX)
# ws = standRegres(lgX1,lgY)
# print("ws:",ws)
#对岭回归进行交叉验证测试
crossValidation(lgX, lgY, numVal=10)
注:在标准回归算法中,向数据集第一列加入一列1用来计算常数项的回归系数,而在岭回归中通过回归方程Y-WX计算常数项b的值。
对于回归的相关内容,以下两篇文章解释的非常清楚:
https://zhuanlan.zhihu.com/p/31860100
https://zhuanlan.zhihu.com/p/32302772

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)