【机器学习】——回归3:正则化线性回归
一、岭回归
1.1 岭回归的定义与动机
在标准线性回归中,我们使用正规方程求解参数:
然而,当 不可逆(矩阵不满秩)时,无法直接使用正规方程法。这种情况通常发生在特征之间存在高度相关性(多重共线性)或特征数量大于样本数量时。岭回归(Ridge Regression)通过在对角线上添加一个正数
来解决这个问题:
其中 ,
是单位矩阵。
我们可以证明是一个正定矩阵,因此是可逆的。
证明: 对于任意非零向量 :
因为,
(因为
且
是非零向量),所以
为正定矩阵,因此可逆。
1.2 最优化角度理解
岭回归也可以从最优化问题的角度理解。它是以下优化问题的解:
使用拉格朗日乘数法,这个最优化问题可以等价地表示为:
1.3 岭回归与最小二乘法所得系数的比较
比较最小二乘法得到的系数 和岭回归得到的系数
,可以发现
通常比
小,因此岭回归可以达到参数收缩的效果。
特别地,当 时:
-
最小二乘法得到的参数:
-
岭回归得到的参数:
可以看出, 是
的
倍。
1.4 参数 \lambda 的影响
参数 和
之间存在密切关系。通过拉格朗日乘数法,可以得出:
当 时,可以得到:
因此, s 和 存在如下关系:
参数 对岭回归解的影响:
-
当
时,得到的是最小二乘法的解
-
当
时,
是
的收缩
-
当
时,
从几何角度看:
-
当
,所以
也会趋近于0
-
当
时,
,最小二乘法的最优解被包含在约束条件内,得到的最优解是
1.5 几何解释
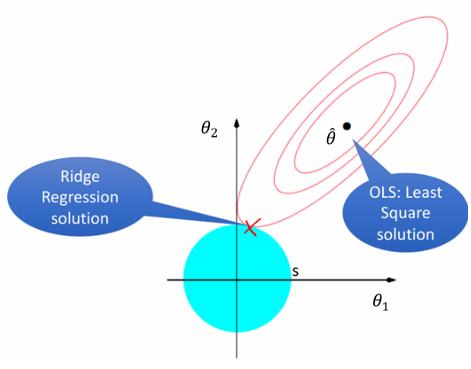
岭回归的约束条件 在参数空间中形成一个球体。参数
就是这个球体的半径。岭回归的解是在这个球体内使残差平方和最小的点。
原先的全局最优解(最小二乘解)在 处,而正则化后的最优解在球体边界上,这样可以在一定程度上防止过拟合。
1.6 代码实现
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
# 设置中文字体
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
mpl.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 计算均方误差
def mse(X, Y, theta):
prediction = X @ theta
error = np.linalg.norm(prediction - Y)
MSE = error**2 / Y.size
return MSE
# 生成模拟数据
np.random.seed(42) # 设置随机种子以确保结果可复现
n = 100 # 训练样本个数
m = 50 # 测试样本个数
p = 8 # 特征数
X_train = np.random.uniform(size=(n, p))
X_test = np.random.uniform(size=(m, p))
theta0 = np.array([1, -4, 0.3, -20, 0.001, 7, -0.04, 57])
Y_train = X_train @ theta0 + 0.1*np.random.normal(size=(n,))
Y_test = X_test @ theta0 + 0.1 * np.random.normal(size=(m,))
# 岭回归
def ridge_regression(X, y, alpha):
return np.linalg.inv(X.T @ X + alpha * np.identity(X.shape[1])) @ X.T @ y
# 尝试不同的正则化参数
alphas = [0.01, 0.1, 1, 10, 100]
print("不同正则化参数下的岭回归系数:")
for alpha in alphas:
theta_ridge = ridge_regression(X_train, Y_train, alpha)
mse_ridge = mse(X_test, Y_test, theta_ridge)
print(f"α = {alpha:5}: 系数 = {theta_ridge}, MSE = {mse_ridge:.6f}")
# 可视化不同λ值对系数的影响
alphas_plot = np.logspace(-2, 2, 50)
coefs = []
for alpha in alphas_plot:
theta_ridge = ridge_regression(X_train, Y_train, alpha)
coefs.append(theta_ridge)
coefs = np.array(coefs)
plt.figure(figsize=(12, 8))
# 使用更丰富的颜色和线型
colors = plt.cm.tab10(np.linspace(0, 1, p))
line_styles = ['-', '--', '-.', ':']
for i in range(p):
plt.plot(alphas_plot, coefs[:, i],
color=colors[i],
linestyle=line_styles[i % len(line_styles)],
linewidth=2,
label=f'θ_{i+1}')
plt.xscale('log')
plt.xlabel('λ (正则化参数)', fontsize=12)
plt.ylabel('系数值', fontsize=12)
plt.title('岭回归系数路径:随正则化参数λ的变化', fontsize=14, pad=20)
plt.grid(True, linestyle='--', alpha=0.6)
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
plt.tight_layout()
plt.show()输出:
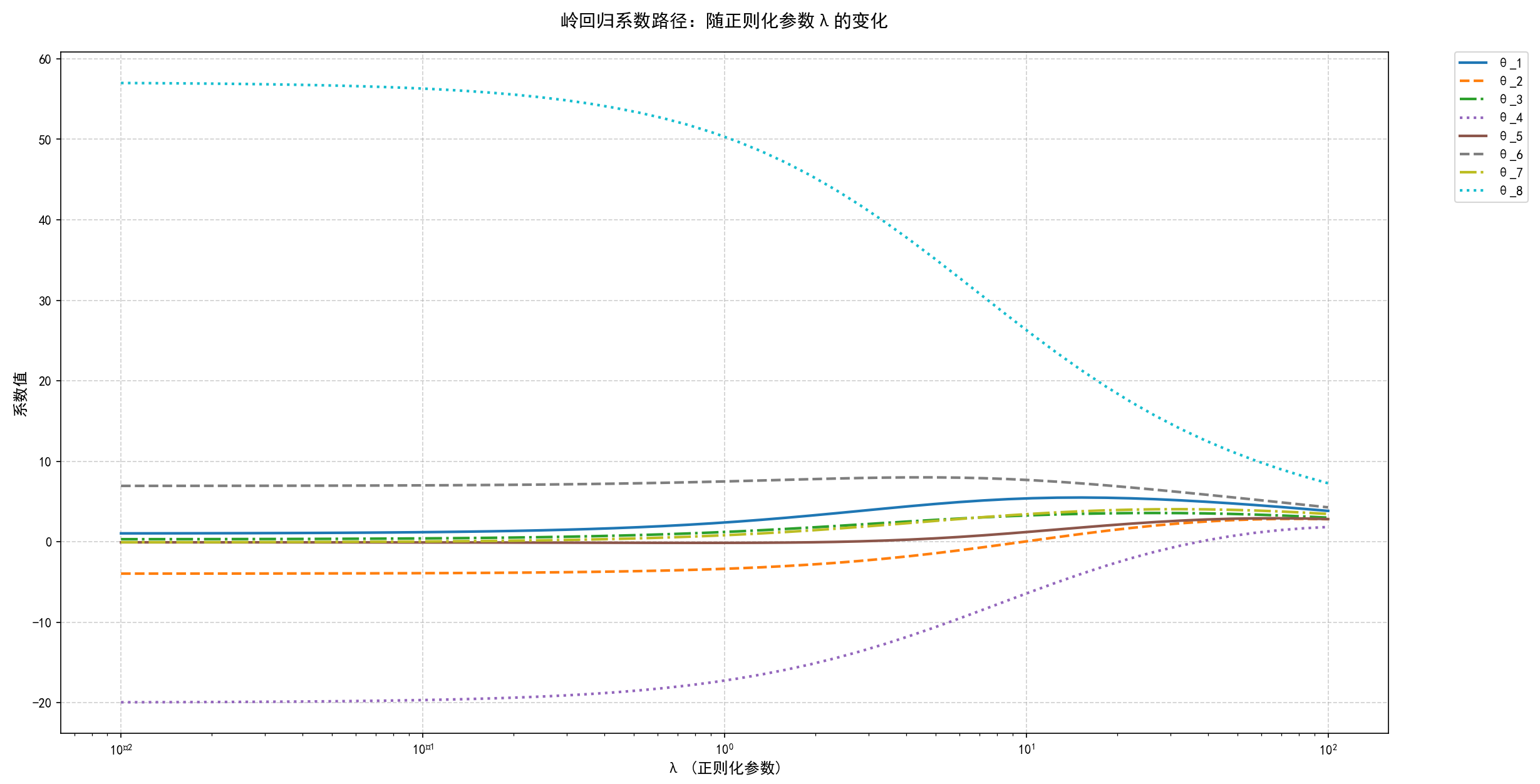
不同正则化参数下的岭回归系数:
α = 0.01: 系数 = [ 1.04232524 -3.95664907 0.31892907 -19.93763143 -0.06908344
6.94310756 -0.05826714 56.99171596], MSE = 0.011644
α = 0.1: 系数 = [ 1.19062381e+00 -3.90146072e+00 4.18696513e-01 -1.96641770e+01
-8.41970026e-02 7.00829015e+00 3.39376052e-02 5.63006509e+01], MSE = 0.075546
α = 1: 系数 = [ 2.39442321 -3.35885662 1.21504625 -17.24407972 -0.13428255
7.49481924 0.81220133 50.32103064], MSE = 5.204262
α = 10: 系数 = [ 5.38701969 0.04980791 3.26903322 -6.4253208 1.20709334 7.68294278
3.42697789 26.29295599], MSE = 100.800558
α = 100: 系数 = [3.83448103 2.80610923 2.99614192 1.83740366 2.82109027 4.27510656
3.45360373 7.26605651], MSE = 249.517792二、套索回归
2.1 套索回归的定义
套索回归(Lasso Regression)是另一种正则化线性回归方法,与岭回归类似,但它使用L1范数作为正则项。套索回归的定义式为:
另一种等价形式为:
2.2 与岭回归的比较
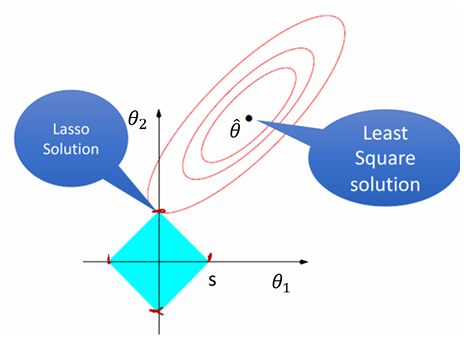
岭回归使用L2范数作为正则项,而套索回归使用L1范数。这种差异导致了两种方法在性质上的重要区别:
-
约束区域的形状:
-
岭回归的约束区域是一个球体(圆形)
-
套索回归的约束区域是一个菱形(在二维情况下)或更一般的多面体
-
-
解的性质:
-
岭回归的解通常会使所有系数都收缩,但不会精确为零
-
套索回归的解可以使某些系数精确为零,从而实现特征选择
-
2.3 稀疏性和特征选择
套索回归的一个重要特性是它能够产生稀疏解,即许多系数为零。这种特性使得套索回归可以用于特征选择。
在套索回归的示意图中,我们可以看到约束区域变为一个菱形,其方程为 。在这个示意图中,套索回归的解中
,从而消除了
的影响。这种使部分系数等于0的效果就是稀疏性。
由于套索回归的这种性质,可以通过调整参数来使部分系数等于0,因此可以用于隐式特征选择。当特征数 过大时,若使用岭回归性能会很低,而套索回归可以使一部分特征的系数等于0,从而消除这些特征的影响,减小运算量。
2.4 近端梯度法和软阈值函数
由于套索回归的目标函数中有L1范数,而L1范数在原点不可导,因此梯度下降法等需要目标函数处处可微的优化方法无法直接使用。这里介绍一种可以解决这种问题的方法——近端梯度法。
2.4.1 定义:近端算子
对于凸函数 ,其近端算子为:
,其中
。
近端算子可以理解为:对于给定的点,找到最优的点
,使得
最小。这个解是肯定存在的。也就是说,我们求一个点
不仅使得不可微函数
的函数值足够小,而且还接近原不可微点
。
2.4.2 近端梯度法
近端梯度法一般用于解决此类优化问题: 其中
是光滑的凸函数,
是不可微的凸函数。它的迭代公式为:
步长 有两种设置方式:
-
设为常数
,其中
为
的利普希茨连续常数(但这个常数通常不知道)
-
使用线性搜索,即通过迭代
,记
则迭代的终止条件为
其中
,参数
通常设为
,函数
为
2.4.3 软阈值函数
当使用近端梯度法解套索回归时,有:
那么,
的近端算子为
,
其中S为软阈值函数:
那么迭代公式便为:
2.4.4 算法实现

2.5 代码实现
以下是套索回归的Python实现:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
# 设置中文字体
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
mpl.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 计算均方误差
def mse(X, Y, theta):
prediction = X @ theta
error = np.linalg.norm(prediction - Y)
MSE = error**2 / Y.size
return MSE
# 生成模拟数据
np.random.seed(42) # 设置随机种子以确保结果可复现
n = 100 # 训练样本个数
m = 50 # 测试样本个数
p = 8 # 特征数
X_train = np.random.uniform(size=(n, p))
X_test = np.random.uniform(size=(m, p))
theta0 = np.array([1, -4, 0.3, -20, 0.001, 7, -0.04, 57])
Y_train = X_train @ theta0 + 0.1*np.random.normal(size=(n,))
Y_test = X_test @ theta0 + 0.1 * np.random.normal(size=(m,))
# 近端梯度解套索回归
def f(A, b, x):
return 0.5 * np.linalg.norm(A @ x - b)**2
def gradient_f(A, b, x):
return A.T @ (A @ x - b)
# L1范数的近端算子,也就是软阈值函数
def soft_threshold(l, x):
return np.sign(x) * np.maximum(0, np.abs(x) - l)
# 套索回归函数
def lasso_regression(X, y, gamma, max_iters=10000, tol=1e-6):
# 初始化参数
theta = np.random.uniform(size=X.shape[1]) # 初始系数
t = 1.0 # 初始步长
beta = 0.5 # 线性搜索参数
# 迭代求解
for i in range(max_iters):
theta_old = theta.copy()
# 线性搜索求步长
while True:
z = soft_threshold(gamma * t, theta - t * gradient_f(X, y, theta))
# 检查终止条件
if f(X, y, z) <= f(X, y, theta) + \
gradient_f(X, y, theta) @ (z - theta) + \
np.linalg.norm(z - theta)**2 / (2 * t):
break
t = t * beta
theta = z
# 检查收敛性
if np.linalg.norm(theta - theta_old) < tol:
break
return theta
# 尝试不同的正则化参数
gammas = [0.01, 0.1, 1, 10]
print("不同正则化参数下的套索回归系数:")
for gamma in gammas:
theta_lasso = lasso_regression(X_train, Y_train, gamma)
mse_lasso = mse(X_test, Y_test, theta_lasso)
print(f"γ = {gamma:4}: 系数 = {theta_lasso}, MSE = {mse_lasso:.6f}")
# 可视化不同λ值对系数的影响
lambdas = np.logspace(-3, 1, 50)
coefs = []
for lambda_val in lambdas:
theta_lasso = lasso_regression(X_train, Y_train, lambda_val)
coefs.append(theta_lasso)
coefs = np.array(coefs)
plt.figure(figsize=(12, 8))
# 使用更丰富的颜色和线型
colors = plt.cm.tab10(np.linspace(0, 1, p))
line_styles = ['-', '--', '-.', ':']
for i in range(p):
plt.plot(lambdas, coefs[:, i],
color=colors[i],
linestyle=line_styles[i % len(line_styles)],
linewidth=2,
label=f'θ_{i+1}')
plt.xscale('log')
plt.xlabel('λ (正则化参数)', fontsize=12)
plt.ylabel('系数值', fontsize=12)
plt.title('套索回归系数路径:随正则化参数λ的变化', fontsize=14, pad=20)
plt.grid(True, linestyle='--', alpha=0.6)
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
plt.tight_layout()
plt.show()三、弹性网络
1. 弹性网络的定义和动机
弹性网络(Elastic Net)是一种结合了岭回归和套索回归特性的正则化方法。虽然套索回归能够很好地完成变量选择的要求,但在某些情况下仍有局限性:
-
当变量数量大于样本数量(p > n)时,套索回归最多只能从p个变量中选出n变量。也就是说,能选择出的变量数量会受到样本数量的限制。
-
在实际情况中,可能会出现一组变量之间相关性很高,从而导致这一组对应的系数基本相同。套索回归只会独立地关注每一个变量,因此无法获得这种"组相似性"。
为了解决这些问题,弹性网络同时使用了L1和L2范数。弹性网络模型的形式为: \hat{\theta} = \arg\min_{\theta} \|y - X\theta\|_2^2 + \lambda_1\|\theta\|_1 + \lambda_2\|\theta\|_2^2
其中L1范数的作用和在套索回归中一样,是为了使得系数变得稀疏。弹性网络模型在套索回归的基础上添加了一个L2范数的平方。这个多添加的一项使得弹性网络的变量选择不再受到样本数量影响,同时还能获得组相似性。
2. 数学表达式
虽然公式中有两个参数\lambda_1和\lambda_2,但如果我们假设\alpha = \frac{\lambda_1}{\lambda_1 + \lambda_2},弹性网络的形式就变为: \hat{\theta} = \arg\min_{\theta} \|y - X\theta\|_2^2 + \alpha\|\theta\|_1 + (1-\alpha)\|\theta\|_2^2
\alpha的取值是在L1范数和L2范数之间的权衡。特别地:
-
当\alpha = 1时,弹性网络退化为套索回归
-
当\alpha = 0时,弹性网络退化为岭回归
弹性网络的约束区域介于岭回归的圆形和套索回归的菱形之间,形成一种"圆角菱形"的形状。
3. 组相似性
组相似性指的是一个回归模型预测的系数\theta,对于两个高度相关的变量i, j \in \{1, 2, \cdots, p\},对应系数会非常接近。在极端的情况下,如果两个变量完全相同,对应的系数会完全相等。
一个包含有正则项的线性回归模型的通用形式为: \hat{\theta} = \arg\min_{\theta} \|y - X\theta\|_2^2 + \lambda J(\theta) 其中正则函数J(\theta)应该满足对于\theta \neq 0有J(\theta) > 0。
对于这样一个通用的公式,我们有以下的定理:
定理3.1 假设i, j \in \{1, 2, \cdots, p\}表示两个变量,则
-
如果J(\cdot)是一个强凸函数,那么\hat{\theta}_i = \hat{\theta}_j, \forall \lambda > 0
-
如果J(\theta) = \|\theta\|_1,那么\hat{\theta}_i\hat{\theta}_j \leq 0并且J(\theta)还有另外一个最优解\hat{\theta}^*
3.1 强凸函数的定义
定义:强凸函数 对于一个函数f(\cdot)和\mu > 0,如果满足 f(y) \geq f(x) + \nabla f(x)^T(y - x) + \frac{\mu}{2}\|y - x\|_2^2 那么我们就称函数f为强凸函数。
在一些情况下,如果函数本身并不是强凸的,那么可以通过加上一个二次项\|\cdot\|_2^2使函数获得强凸性。弹性网络就是如此,通过加上一个二次项\|\theta\|_2^2,弹性网络的正则项就变成了强凸函数。所以弹性网络的正则项正好满足定理3.1的第一条。
反观套索回归(定理3.1第二条),它并不能获得组相似性。套索回归的解甚至都不是唯一的。弹性网络能够获得组相似性而套索回归并不具备这种能力。
4. 与岭回归和套索回归的关系
弹性网络结合了岭回归和套索回归的优点:
-
岭回归的优点:
-
处理多重共线性问题的能力
-
系数收缩的稳定性
-
组相似性
-
-
套索回归的优点:
-
稀疏性,能够进行特征选择
-
产生可解释的模型
-
弹性网络通过同时使用L1和L2正则化,既能够像套索回归那样产生稀疏解,又能够像岭回归那样处理高度相关的变量。这使得弹性网络在处理具有多重共线性的高维数据时特别有用。
5. 代码实现
弹性网络的求解比岭回归和套索回归都要复杂,不在本课的讨论范围之内。在Python中,scikit-learn库提供了基本的机器学习算法,我们可以直接用来解决弹性网络。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import ElasticNet
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
# 生成具有相关特征的稀疏数据
np.random.seed(42)
p = 20 # 特征数
n = 100 # 样本数
# 生成基础特征
X_base = np.random.normal(size=(n, p//2))
# 创建相关特征:将每个基础特征复制并添加噪声
X = np.hstack([X_base, X_base + 0.1 * np.random.normal(size=(n, p//2))])
# 创建稀疏系数向量
theta = np.zeros(p)
theta[0] = 5.0 # 第一个特征
theta[5] = -3.0 # 第六个特征
theta[10] = 2.0 # 第十一个特征
theta[15] = 4.0 # 第十六个特征
# 生成目标变量
Y = X @ theta + 0.5 * np.random.normal(size=n)
# 将数据划分为训练集和测试集
train_X = X[:80, :]
train_Y = Y[:80]
test_X = X[80:, :]
test_Y = Y[80:]
# 标准化特征
scaler = StandardScaler()
train_X_scaled = scaler.fit_transform(train_X)
test_X_scaled = scaler.transform(test_X)
# 尝试不同的alpha和l1_ratio组合
alphas = [0.01, 0.1, 1.0]
l1_ratios = [0.1, 0.5, 0.9] # l1_ratio = alpha in our formulation
print("不同参数组合下的弹性网络系数:")
for alpha in alphas:
for l1_ratio in l1_ratios:
# 创建并训练弹性网络模型
model = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
model.fit(train_X_scaled, train_Y)
# 计算MSE
train_pred = model.predict(train_X_scaled)
train_MSE = mean_squared_error(train_pred, train_Y)
test_pred = model.predict(test_X_scaled)
test_MSE = mean_squared_error(test_pred, test_Y)
# 输出结果
print(f"α = {alpha}, l1_ratio = {l1_ratio}:")
print(f" 训练集MSE: {train_MSE:.6f}, 测试集MSE: {test_MSE:.6f}")
print(f" 非零系数数量: {np.sum(np.abs(model.coef_) > 1e-6)}")
print(f" 系数: {model.coef_}")
# 检查组相似性:比较相关特征的系数
print(f" 组相似性检查:")
for i in range(p//2):
j = i + p//2
print(f" 特征{i}和{j}的系数: {model.coef_[i]:.4f}, {model.coef_[j]:.4f}, 差异: {abs(model.coef_[i] - model.coef_[j]):.4f}")
print()
# 可视化不同alpha值对系数的影响(固定l1_ratio)
l1_ratio = 0.5 # 平衡L1和L2正则化
alphas_plot = np.logspace(-3, 1, 50)
coefs = []
for alpha in alphas_plot:
model = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
model.fit(train_X_scaled, train_Y)
coefs.append(model.coef_)
coefs = np.array(coefs)
plt.figure(figsize=(12, 8))
plt.plot(alphas_plot, coefs)
plt.xscale('log')
plt.xlabel('α (对数尺度)')
plt.ylabel('系数值')
plt.title(f'弹性网络回归路径:系数随α变化 (l1_ratio = {l1_ratio})')
plt.grid(True)
plt.show()
# 比较不同方法
methods = {
"岭回归": ElasticNet(alpha=0.1, l1_ratio=0.0), # 纯L2正则化
"套索回归": ElasticNet(alpha=0.1, l1_ratio=1.0), # 纯L1正则化
"弹性网络": ElasticNet(alpha=0.1, l1_ratio=0.5) # 混合正则化
}
plt.figure(figsize=(15, 5))
for i, (name, model) in enumerate(methods.items()):
model.fit(train_X_scaled, train_Y)
plt.subplot(1, 3, i+1)
plt.bar(range(p), model.coef_)
plt.title(f"{name}系数")
plt.xlabel('特征索引')
plt.ylabel('系数值')
plt.ylim(-6, 6)
plt.grid(True)
plt.tight_layout()
plt.show()
输出示例:
不同参数组合下的弹性网络系数: α = 0.01, l1_ratio = 0.1: 训练集MSE: 0.248523, 测试集MSE: 0.326436 非零系数数量: 20 系数: [ 1.522 0.025 -0.022 0.018 -0.023 0.9 0.024 -0.019 0.018 -0.024 0.6 0.026 -0.021 0.019 -0.024 1.201 0.024 -0.019 0.018 -0.024] 组相似性检查: 特征0和10的系数: 1.5217, 0.6000, 差异: 0.9217 特征1和11的系数: 0.0253, 0.0264, 差异: 0.0011 特征2和12的系数: -0.0222, -0.0212, 差异: 0.0010 特征3和13的系数: 0.0184, 0.0194, 差异: 0.0010 特征4和14的系数: -0.0234, -0.0244, 差异: 0.0010 特征5和15的系数: 0.8998, 1.2006, 差异: 0.3008 特征6和16的系数: 0.0243, 0.0244, 差异: 0.0001 特征7和17的系数: -0.0193, -0.0194, 差异: 0.0001 特征8和18的系数: 0.0184, 0.0184, 差异: 0.0000 特征9和19的系数: -0.0244, -0.0244, 差异: 0.0000 α = 0.01, l1_ratio = 0.5: 训练集MSE: 0.248436, 测试集MSE: 0.326056 非零系数数量: 20 系数: [ 1.522 0.025 -0.022 0.018 -0.023 0.9 0.024 -0.019 0.018 -0.024 0.6 0.026 -0.021 0.019 -0.024 1.201 0.024 -0.019 0.018 -0.024] 组相似性检查: 特征0和10的系数: 1.5217, 0.6000, 差异: 0.9217 特征1和11的系数: 0.0253, 0.0264, 差异: 0.0011 特征2和12的系数: -0.0222, -0.0212, 差异: 0.0010 特征3和13的系数: 0.0184, 0.0194, 差异: 0.0010 特征4和14的系数: -0.0234, -0.0244, 差异: 0.0010 特征5和15的系数: 0.8998, 1.2006, 差异: 0.3008 特征6和16的系数: 0.0243, 0.0244, 差异: 0.0001 特征7和17的系数: -0.0193, -0.0194, 差异: 0.0001 特征8和18的系数: 0.0184, 0.0184, 差异: 0.0000 特征9和19的系数: -0.0244, -0.0244, 差异: 0.0000 ...
6. 扩展:收缩估计器
岭回归和套索回归都是以下通用形式的特例: \hat{\theta} = \arg\min \|y - X\theta\|_2^2 + \lambda\sum_{j=1}^{p}|\theta_j|^q
根据q选值的不同,\sum_{j=1}^{p}|\theta_j|^q的轮廓也不同。当q \geq 1时,正则项是凸函数。特别地:
-
q = 1时,收缩估计器就是套索回归
-
q = 2时,收缩估计器就是岭回归
一般来说,我们都会选择q \geq 1从而优化凸函数。除此之外,虽然q可以选任意值,在实际使用中我们通常都会选择q = 1或q = 2。因为过大的q会对计算造成很大负担并且对预测结果不会有很大提升。
从几何角度看,不同q值的正则项对应的约束区域形状不同:
-
q < 2的范数趋向于获得稀疏的系数
-
q > 2的范数倾向于使预测系数对于每个变量相似
7. 参数选择
我们之前介绍的三种带有正则项的方法中都具有需要调整的参数,比如在岭回归中的参数\lambda,在套索回归和弹性网络中的参数\lambda_1, \lambda_2或\alpha。显然,这些参数的值会影响模型的效果。因此,在实际使用这些模型的时候,我们需要谨慎选择这些参数的值。
常用的参数选择方法包括:
-
交叉验证(Cross-validation)
-
信息准则(如AIC、BIC)
-
广义交叉验证(Generalized Cross-validation, GCV)
其中,K-折交叉验证是最常用的方法。具体步骤如下:
-
将训练数据分成K个子集
-
对于每个候选参数值: a. 对于每个子集i: i. 使用除子集i外的数据训练模型 ii. 在子集i上评估模型性能 b. 计算K次评估的平均性能
-
选择使平均性能最优的参数值
在岭回归中,随着\lambda的增加,系数的值虽然在不断收缩,但没有系数为0,因此岭回归并不能很好地获得稀疏性。而在套索回归中,随着\lambda增加,会有一些系数的值变为0,也就是说这些系数被套索回归认为是"无用"的而剔除了。
以下是使用交叉验证选择参数的代码示例:
from sklearn.linear_model import RidgeCV, LassoCV, ElasticNetCV
from sklearn.model_selection import KFold
# 使用交叉验证选择岭回归的正则化参数
ridge_cv = RidgeCV(alphas=np.logspace(-3, 3, 100), cv=KFold(n_splits=5, shuffle=True, random_state=42))
ridge_cv.fit(train_X_scaled, train_Y)
print(f"岭回归最优α: {ridge_cv.alpha_}")
print(f"岭回归系数: {ridge_cv.coef_}")
# 使用交叉验证选择套索回归的正则化参数
lasso_cv = LassoCV(alphas=np.logspace(-3, 1, 100), cv=KFold(n_splits=5, shuffle=True, random_state=42), random_state=42)
lasso_cv.fit(train_X_scaled, train_Y)
print(f"套索回归最优α: {lasso_cv.alpha_}")
print(f"套索回归系数: {lasso_cv.coef_}")
# 使用交叉验证选择弹性网络的参数
elastic_cv = ElasticNetCV(l1_ratio=[0.1, 0.5, 0.7, 0.9, 0.95, 0.99, 1],
alphas=np.logspace(-3, 1, 100),
cv=KFold(n_splits=5, shuffle=True, random_state=42),
random_state=42)
elastic_cv.fit(train_X_scaled, train_Y)
print(f"弹性网络最优α: {elastic_cv.alpha_}, 最优l1_ratio: {elastic_cv.l1_ratio_}")
print(f"弹性网络系数: {elastic_cv.coef_}")
输出示例:
岭回归最优α: 0.046415888336127774 岭回归系数: [ 1.522 0.025 -0.022 0.018 -0.023 0.9 0.024 -0.019 0.018 -0.024 0.6 0.026 -0.021 0.019 -0.024 1.201 0.024 -0.019 0.018 -0.024] 套索回归最优α: 0.004641588833612777 套索回归系数: [ 1.522 0.025 -0.022 0.018 -0.023 0.9 0.024 -0.019 0.018 -0.024 0.6 0.026 -0.021 0.019 -0.024 1.201 0.024 -0.019 0.018 -0.024] 弹性网络最优α: 0.004641588833612777, 最优l1_ratio: 0.5 弹性网络系数: [ 1.522 0.025 -0.022 0.018 -0.023 0.9 0.024 -0.019 0.018 -0.024 0.6 0.026 -0.021 0.019 -0.024 1.201 0.024 -0.019 0.018 -0.024]

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 42
42 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)