从开源 WeKnora 到生产可用:一个垂直领域 RAG 系统的二开、调优与上线实录
这不是一篇"我搭了个 RAG demo"的文章。
这是一套真实跑在公网上、服务某专业垂直领域一线业务专家的系统,从选型、二次开发、十几轮对照实验调优,到迁移上线、再到 CI/CD 增量同步方案设计的完整工程记录。
我们做的事情,一句话概括:把腾讯开源的企业级 RAG 平台 WeKnora[1] 二次开发成一套面向某专业垂直领域的"专家助手",让一线业务人员可以像问一个资深同事那样,把专业研判、决策和查证类的问题直接抛给它。
对外客户端:按业务场景组织的对话入口
为了让方法论可迁移,下文会把具体业务场景做匿名化处理,统一称作"某垂直领域";但所有技术细节、配置参数、评测指标都是真实的工程记录。
全文按 RAG 流水线的顺序展开——先解析、再分块、然后检索召回、最后到智能体生成,每一站都讲我们踩过的坑和最终的选择:
-
整体架构
:一个开源平台是怎么被改造成对外产品的
-
二次开发
:怎么让"同一个实例"既服务管理员、又服务外部客户,且升级不冲突
-
解析
:材料切坏了,后面全白搭(PDF / Excel)
-
分块
:chunk 切多大、标题怎么不丢
-
检索与召回
:哪些调参有效、哪些是坑、最终配置
-
智能体
:从"4+1 个 Agent"收敛到"1 个总 Agent + 4 个 Skill"
-
评测尺子
:没有一把稳定的尺子,调优就是自欺欺人
-
增量更新
:企业 RAG 最难的不是召回率
-
CI/CD 与上线
:双轨发布方案
-
效果与诚实的边界
- 方法论小结
一、整体架构:编辑台与服务台分离
先看终局,再讲怎么走到这里。
我们最终的部署形态有一个核心设计原则:编辑台和服务台物理分离。
-
编辑台
(内网):跑完整的 WeKnora,包含文档解析器(docreader)、向量库、知识图谱、可观测(Langfuse)。所有知识的录入、解析、分块、调试都在这里做。
-
服务台
(公网生产机):只保留对客户服务必需的最小集合——前端、应用服务、PostgreSQL(向量 + 全文检索)、Redis。砍掉了文档解析器、知识图谱、可观测全套,因为这些是"生产内容"用的,不是"服务内容"用的。
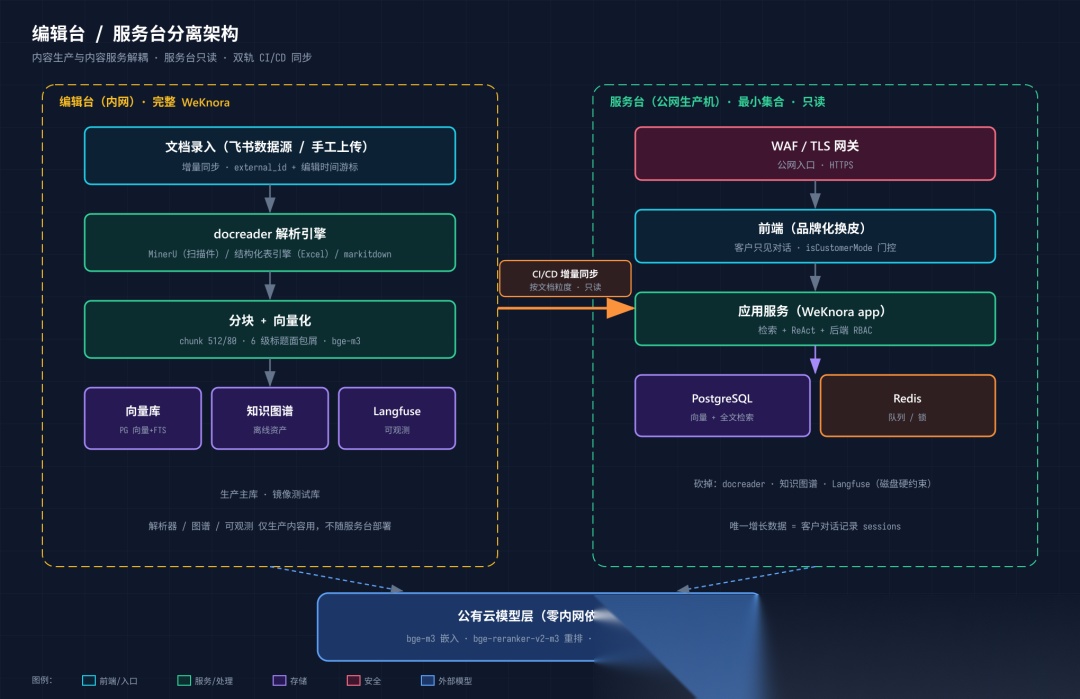
整体架构图
为什么要这么分?因为公网生产机的资源很紧张(核数、内存、磁盘都有限,尤其磁盘可用空间不多)。把解析器、图数据库、可观测栈全堆上去,磁盘直接撑爆。而这些组件在"服务"阶段根本用不到——客户只是来问问题的,不会在生产机上传文档。
于是内容生产与内容服务被彻底解耦:所有知识只在编辑台录入和解析,再通过 CI/CD 按文档粒度增量同步到服务台(第九节细讲)。服务台是只读的,唯一会增长的数据是客户的对话记录。
这个"编辑/服务分离"不是一开始就想清楚的,是被磁盘和"上游不装解析器就跑不了"逼出来的。但回头看,它恰好是企业 RAG 该有的样子。
二、二次开发:让一个实例服务两类人
开源 RAG 平台拿来直接用,最大的障碍不是功能,是权限边界。WeKnora 默认是个"内部工具":登录进去能看到知识库管理、智能体编排、组织设置、模型配置……这些东西绝不能让外部客户看到。
最直觉的做法是起两个实例:一个内部用、一个对外。但这意味着知识库、模型、运维全部双份,维护成本翻倍。我们选了另一条路:
同一个实例,按角色区分。客户只见对话,管理员维护后台,管理员侧零影响,且上游升级仍然好合并。
2.1 一个开关搞定一切:isCustomerMode
这里有个关键的克制决策:不新建 customer 角色。新增角色要改后端 Go 枚举、改数据库、改前端三处,每一处都跟上游分叉,升级就是灾难。我们直接复用平台现成的 viewer(只读)角色当"客户",所有门控收敛到前端一个计算属性上:
// 对外客户 = 在当前活动租户里是 viewer(只读)且不是平台系统管理员const isCustomerMode = computed(() => { return !isSystemAdmin.value && currentTenantRole.value === 'viewer'})
这个开关有一个数学上很优雅的性质——管理员永远不会被误伤:
| 用户 | 系统管理员 | 当前租户角色 | isCustomerMode |
|---|---|---|---|
| 管理员 | 是 | owner | !true && … → 恒 false |
| 内部普通成员 | 否 | 自己租户 owner | … && 非 viewer → false |
| 外部客户 | 否 | viewer | true && true → true ✅ |
只要"系统管理员 = 真",第一个条件直接短路,整个客户模式开关恒为 false。不管管理员切到哪个租户、什么身份,客户那套界面裁剪对他永不触发。这就是"管理员零影响"的底气。
2.2 前端门控是体验层,后端 RBAC 才是安全层
必须强调一句,免得被人喷"前端权限形同虚设":
前端门控 = 体验层(让客户看不到无关功能);后端 RBAC = 安全层(防越权)。
currentTenantRole 读的是 localStorage,可以被篡改,绝不能当安全边界。真正的授权在后端:每个请求的鉴权中间件都会从成员表重新解析角色。即使客户改了 localStorage 把自己伪装成 owner,后端照样拦。前端门控只对客户"做减法",对管理员是空操作——没有任何既有行为被改写或删除,这也是它升级安全的根本原因。
2.3 覆盖层:让"换皮 + 加门控"不污染上游源码
最头疼的是升级。WeKnora 还在快速迭代,我们的改动如果散落进它的源码 git 历史,每次上游更新都是一场 merge 噩梦。
解法是覆盖层(overlay)——所有定制都做成一个独立目录 + 两个幂等脚本,按"四种手段、能用前者绝不用后者"的优先级来改:
brand-overlay/├── overlay/│ ├── logo.png + favicon.ico ① 同名资产替换(零冲突)│ └── CustomerGuide.vue ② 新增独立组件(cp 进去,不动上游文件)├── apply-brand.sh 资产/组件 cp + 标题文案替换 + 调 apply-gate.py(幂等)├── apply-gate.py 十余段角色门控补丁(幂等;锚点找不到就直接 FAIL)└── README.md
四种手段优先级:① 同名替换 > ② 新增组件 > ③ 设计变量覆盖 > ④ 锚点补丁。补丁越少,升级越稳。
最妙的是补丁的幂等设计:每段补丁带一个 marker(已存在就跳过,保证幂等)和一个 anchor(在上游源码里找定位点)。一旦上游改版动了被打补丁的文件,anchor 失配会立即 FAIL 报错,而不是静默失效。 它把"需要人工对齐"的位置精确地、响亮地暴露出来,而不是让你在生产环境里慢慢发现某个门控悄悄漏了。
升级流程因此被压缩成三步:git pull 上游 → 跑 apply-brand.sh → 重新构建前端镜像。
三、解析:材料切坏了,后面全白搭
很多 RAG 项目效果不好,不是模型不够强、prompt 不够长、向量库不够高级,而是模型拿到的材料,从一开始就被切坏了。解析是流水线的第一站,它的质量是整条链路的天花板。
文档类型决定解析策略,解析质量决定最终答案质量。 业界有个公开案例:某专业领域知识库早期直接用 pdfplumber,约 30% 文档有结构性解析错误;分层路由(原生文本走 PyMuPDF、复杂版面走 MinerU、扫描件走 OCR)之后,解析错误率从 30% 降到 7% 左右,整体噪声文档比例从 15% 降到 3%。
所以我们在 docreader 里做的第一件事,就是按文档类型分层路由到不同解析引擎。除音频暂无业务需求外,其余常见文档类型全部覆盖:
| 文档类型 | 解析引擎 / 策略 | 处理方式 | 状态 |
|---|---|---|---|
| PDF(原生文本) | PyMuPDF 等原生抽取 | 直接提取文本 + 版面 | ✅ |
| PDF(扫描件 / 图文混排) | MinerU (OCR + 版面还原) | 纯 CPU OCR,表格/印章/数字完整还原(§3.1) | ✅ |
| 图片(png / jpg / 截图) | OCR 引擎 | 识别为文本 | ✅ |
| Excel(xlsx / xls) | 结构化表引擎 structured_table(自研) | 填合并单元格 + 两级分块 + 质量守门,内置解析兜底(§3.2) | ✅ |
| Word(docx) | 原生 / markitdown | 转 markdown 保留标题层级 | ✅ |
| PPT(pptx) | markitdown | 转 markdown | ✅ |
| Markdown / TXT | 直接读入 | 原样进分块 | ✅ |
| HTML / 网页 | 正文抽取 / markitdown | 去模板噪声留正文 | ✅ |
| 音频 | — | 暂无业务需求,未接入 | ⛔ |
其中两类最值得展开——扫描件 PDF 和 Excel 结构化表,因为它们是我们投入最多、踩坑最深、ROI 也最高的两个。
3.1 扫描件 PDF:从 markitdown 换到 MinerU
早期 PDF 走 markitdown,扫描件几乎失效,文字识别还会出错(把生僻字识别成形近字这种)。我们对比了 RapidOCR / MinerU / PaddleOCR-VL 几个引擎后,最终选 MinerU。
它之前"跑不起来"其实是个环境配置问题,解决之后部署成一个纯 CPU 的解析服务(不吃 GPU),接进 WeKnora 后,中文识别约 99%、表格完整还原、数字全对、印章不影响——全面碾压 markitdown 和 RapidOCR(后者会把表格拍扁)。
3.2 Excel:合并单元格不处理,召回准确率掉 15~25 个点
这个领域有大量结构化主数据 Excel:分类编码表、各地区标准表。这些表为人阅读设计,全是合并单元格、多级表头。WeKnora 内置的 Excel 解析是"一行转一条 列:值",碰到合并单元格直接歇菜:
合并的"顶层大类"只在左上角单元格有值,下面子行全是 NaN 被跳过。于是叶子行的 chunk 丢掉了顶层大类。你问"某末级条目属于哪个大类",它答不出来——因为那个 chunk 里压根没有大类的名字。
而模块/大类信息一旦丢失,metadata 过滤失效,回答准确率会显著下降(内部测试掉 15~25 个百分点)。
我们的解法是给 docreader 新增一个 structured_table(结构化主数据表)解析引擎(下拉可选,团队零脚本),核心三招:
-
先填合并单元格
:读每个合并区域左上角的值,回填整个区域;
-
两级分块
:父块 = 模块/功能域(只做锚点),子块 = 一行记录,且每行带完整层级路径;
-
两道质量守门
:表头指纹识别 + 列角色错配检测,识别不可靠就退回内置解析器——核心不变量是"永不输出比内置更差的结果,宁可不够好,绝不错乱造幻觉"。
修复后,扁平化的 chunk 自洽地带上全路径:
大分类:XX(08);中分类:XX(0804);末级条目:XXX(080437);类别:4 类
同一个 query 召回的条目全部自带顶层大类。
四、分块:chunk 切多大、标题怎么不丢
材料解析干净了,下一站是切分。chunk 是 RAG 召回质量和回答完整度之间的平衡器——切太大检索不准,切太小丢上下文。这一节两个结论,都是被自己场景的 Recall@K 实测筛出来的。
4.1 chunk size:768 → 512,细节题召回率从 0% 到 75%
最早我们的结论是"chunk 512/768/1024 召回率全 100%,没差异"。这个结论错在测试题选错了——用的是"强术语单文档题",答案里有明显关键词,向量召回有天花板效应,怎么切都能召回。
换成长文档内部细节题(答案藏在文档中段、要跨 chunk 才能拼出来)后,结论彻底翻转。同样 48 篇文档建三个对照库,12 道细节题:
| chunk size | Recall@1 | Recall@3 | MRR | 平均排名 |
|---|---|---|---|---|
| 512(新) | 75% | 87% | 0.844 | 1.5 |
| 768(原生产) | 0% | 50% | 0.335 | 3.5 |
| 1024 | 37% | 62% | 0.567 | 2.6 |
768 那行 R@1=0% 偏极端(含随机性),但 512 全面领先的趋势是稳定的。落地:生产库从 768 重切到 512,重灌四百多篇文档。 这是整个调优里 ROI 最高的一次落地改动。
4.2 标题面包屑:动到分块器源码,解决"跨 chunk 标识丢失"
有一类题我们一直答错:答案藏在一份标准文档的深层嵌套标题之下——某个四五级嵌套小标题底下的一条具体条目。
排查了好几轮,根因藏得很深:那一节按 512 切散后,包含答案的那个 chunk 本身不带它所属层级的关键标识词——它只有具体的描述文字,那个标识词在上面好几级标题里。向量召回拿到这个 chunk,根本不知道它属于哪一节,自然就和别的层级的条目混淆了。
最终修复是改 WeKnora 的分块器源码(0.6.2 起分块走 Go 实现),给它加上完整的 6 级 markdown 标题追踪:每个 chunk 在 embedding 时,临时把它所属的完整标题路径(# 一级标题 / ## 二级 / ### 三级 / #### 四级)拼到正文前面一起向量化,但存储和展示的还是纯正文。
这个设计 WeKnora 内部叫 ContextHeader,思路非常值得借鉴:
embedding 的是"面包屑 + 正文",召回时能借标题语境;但落库/展示的还是干净原文,不污染内容。这不是 prompt 技巧,而是索引阶段的语义增强。
改完之后那类深层条目题就答对了。这一招我们也提了 issue 反馈给上游。
五、检索与召回:哪些调参有效、哪些是坑
切好的 chunk 进了向量库,到了流水线最热闹、也最容易被"最佳实践"带偏的一站——检索召回。这一节把十几个对照实验的真实结论摊开。只想抄作业的,直接跳到 5.4 的最终配置表。
5.1 一个测量坑:references 默认不按 score 排
先提一个我们自己踩过的小坑(不重要,但很典型):评测一度显示开 rerank 后正确文档被排到后面,差点把 rerank 关了。复核才发现是消费端把 WeKnora 返回的 references数组顺序当成了相关性排名——它默认是 chunk 序、不是 score 序。rerank 本身没问题,加一行按 score 排序就好。
同一个 bug 还制造过另一个假象:“用 LLM 给召回片段二次重排,Recall@1 +50 个点”。其实那 +50 点约等于把 references 按 score 排一下而已,所以我们没上 LLM 二次重排(省了延迟和一次额外调用)。
小结:连自己的实验结论也要回查测量口径,漂亮的数字最值得怀疑。
5.2 业界"最佳实践"照搬都翻车:有的无效,有的得换用法
我们老老实实试了三个被各种博客吹爆的方法。结论是:有的在我们场景里无效甚至有害,有的则要换个用法才成立——照搬都不行。
-
Wiki 概念层 → 别把它塞进向量召回(没用),换成独立检索路由(很强)
:WeKnora 能把原文 LLM 编译成带反向链接的"概念导航页"。这里有个我们自己踩过、又被实测纠正的坑,要分清两层:
第一层(容易误判):wiki 页不进向量检索索引。 它独立存表、只反指原文。我们早期克隆同样文档建了 wiki on/off 两个库,chunks 字字相同——于是一度得出"开 wiki 提升召回是白开"的结论。但这个结论是被"智能体模式不对"带偏的:当时跑的是纯向量单步召回(quick-answer),它根本不会去调 wiki 工具,wiki 当然零参与。拿这个口径判 wiki 死刑,是冤案。
第二层(真相):在 ReAct(smart-reasoning)智能体里,wiki 是一条一等公民检索路由,而且贡献很大。 我专门在生产环境实测了 5 道题(4 道概念题 + 1 道精确取数题),盯着智能体到底调了哪些检索工具:
提问类型 智能体的检索行为 wiki 概念链接 原文 chunk 引用 概念题①:两个相近事物的区别 连开 6 次 wiki 工具 3 0 概念题②:一个专业术语的含义 4 次 wiki 工具 1 0 概念题③:一套分级体系怎么划分 4 次 wiki 工具 5 0 概念题④:某评定标准是什么 4 次 wiki 工具 5 0 精确题:某条文规定的具体时限 先 wiki 探概念,再切到 grep_chunks取条文0 1 结论一目了然:4 道概念题,智能体全部重度走 wiki、答案几乎完全由 wiki 概念页成文(chunk 引用为 0);唯一那道精确取数题,它先用 wiki 理解概念、再切回原文 chunk 取准确条文。 这就是"概念走 wiki、取数走 chunk"的智能路由,活生生跑出来给你看——同样这几道题,如果用纯向量单步召回的 quick-answer 智能体,wiki 工具一次都不会调。
那 wiki 路由检索到的"概念导航页"长什么样?就是下面这种——LLM 把原文编译成一个个实体/概念页,每页顶部带「被链接」反向链接(指回它的来源文档和相关概念),结构化、可点选、自成导航:
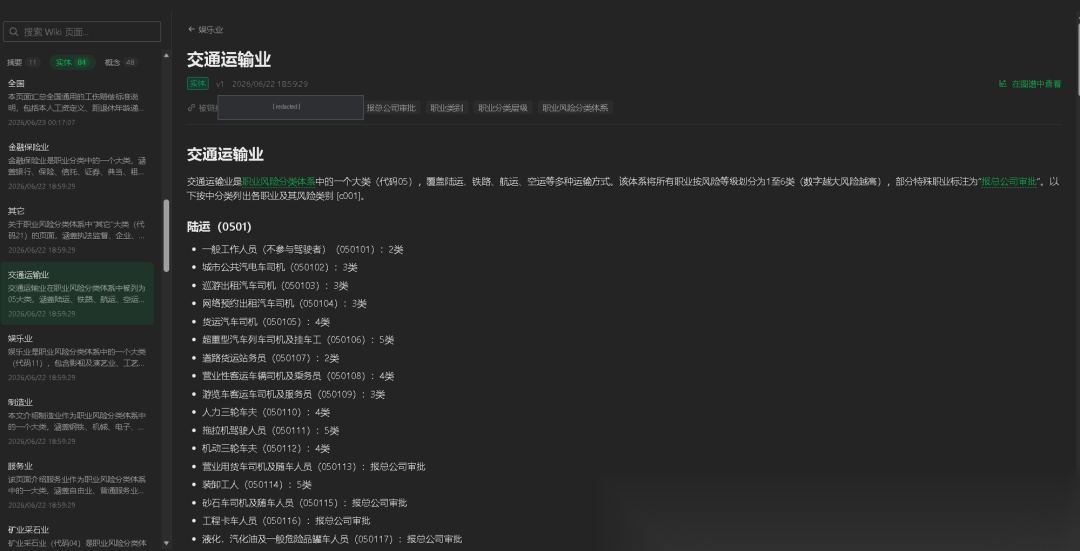
wiki 概念/实体导航页:每页带反向链接,结构化可导航
这些页之间的反向链接还会织成一张可视化的 wiki 图谱(注意:这张图谱存在 PostgreSQL 里、不依赖 Neo4j),概念之间怎么连、一个实体的邻居有哪些,一目了然:

wiki 图谱:概念页之间的反向链接织成可视化导航图
所以我们最终上线的总 Agent 就是 hybrid-rag-wiki 形态,wiki 检索是开着的、且权重很重:概念题走 wiki 路由,精确取数 / 条文题走原文 chunk 路由。一句话——wiki 不是"提升向量召回"的工具,而是"另一条互补的检索路"。用错位置(塞进向量召回)没用,用对位置(概念路由)很强。
-
GraphRAG 知识图谱 → 自动图扩展关,按需工具留
:当前版本 WeKnora 的"自动图谱检索"是"劫持/替代"向量召回,而不是业界那种"向量初召 + 图扩展 + rerank 增强"的范式。切
graph_enabled从 true 到 false,召回从"全错"立刻"恢复精准",而且没有融合权重可调。结论:检索阶段禁用自动图扩展;图谱本身作为离线关系资产保留,多跳推理时由 Agent 主动调query_knowledge_graph工具。 -
Contextual Retrieval
(Anthropic 那篇):给每个 chunk 前置一段 LLM 生成的背景标注。我们的数据本身上下文就比较完整,加了之后反而稀释——R@1 从 75% 掉到 66%,MRR 0.847 → 0.785。不采用。
一个反直觉但很重要的体感:渲染最猛的方法,照搬到你的具体场景里要么无效有害、要么得换个用法。 真正有效的改动(chunk 调小、标题面包屑、agentic 多跳、wiki 当独立路由),都是被自己场景的 Recall@K 和实测筛出来的,不是抄来的。
5.3 贯穿全程的工程难题:32K 上下文溢出
这个坑值得单独说,因为它直接决定了最终的 agent 模式选择。
症状是大模型报 400:maximum context length is 32768 tokens。根因链是这样的:
rerank 返回 top_k 个 child chunk → 每个 child 被替换为它的 parent chunk(约 4096 字符) → 重叠合并放大 → 逐个拼接,每个截 6000 字 → 10 × 6000 字 中文 ≈ 30K tokens → 爆
后来在"长条文/法规类问题"上又翻出第二个真凶:enable_query_expansion(查询扩展)会把同一批 10 个分片跨 5 个查询变体复制 5 份塞进上下文(在 Langfuse 里能直接数出来 system 里有 50 个 <context> 块 = 10×5),瞬间撑爆 32K。
修复是组合拳:关掉查询扩展 + rerank_top_k 砍到 5 + max_completion_tokens 设 4096 + 给一个总字符预算上限兜底。这套组合是后面 agent 模式能用上 smart-reasoning 的前提(详见第六节)。
5.4 最终上线的生产配置
把前面所有实验的结论汇成一张表(这是你真正可以抄的部分,横跨分块、检索、智能体三层):
| 配置项 | 值 | 来由 |
|---|---|---|
| WeKnora 版本 | 0.6.2 | 分块迁到 Go splitter,顺带修了上下文截断 |
| chunk_size / overlap | 512 / 80 | §4.1,细节题碾压 768 |
| 标题面包屑 | 开(源码改造,6 级标题追踪) | §4.2,解决跨 chunk 标识丢失 |
| embedding 模型 | bge-m3 (1024 维) | 中文 + 长编号已足够强 |
| embedding_top_k | 40 | 粗排候选池 |
| rerank 模型 | bge-reranker-v2-m3(保持开启,禁止关闭) | §5.1,别被假象误导关掉 |
| rerank_top_k | 5 | §5.3,压住 32K 上下文 |
| 阈值 | keyword 0.3 / vector 0.1 / rerank 0.3 | — |
| 对话模型 | DeepSeek-V4 系列 (早期 Qwen3.6-35B) | 推理与指令遵循更稳 |
| temperature | 0.3 | 防漂移又不至于死板 |
| max_completion_tokens | 4096 | §5.3,修长答案截断 |
| enable_query_expansion | 关 | §5.3,是上下文溢出主因、且对聚合题有害 |
| enable_rewrite | 关 (场景 agent) | 会把完整上下文一起替换、丢信息 |
| kb_selection_mode | selected(只查本库) | 默认 all 会检索租户下所有库,召回被废弃实验库污染 |
| agent 形态 | hybrid-rag-wiki(smart-reasoning) | wiki + 原文 chunk 双路由 + Skill |
| wiki 检索(ReAct 路由) | 开 | §5.2,概念题路由 wiki、取数题路由 chunk |
| 自动图扩展 | 关 | §5.2,自动图扩展负收益 |
kb_selection_mode=selected 这行是隐患修复级别的——默认配置会让召回被一堆废弃的老实验库污染,改成 selected 之后召回 100% 锁定在生产库。
六、智能体:从"4+1 个 Agent"到"1 个总 Agent + 4 个 Skill"
材料解析好了、切好了、检索召回也调对了,最后一站是让智能体把召回的材料组织成专业答案。
6.1 一次架构收敛
第一代是 5 个独立 agent,每个绑死一个业务子场景(4 个核心业务场景 + 1 个通用问答,即第十节的场景 A~D),全部跑 quick-answer(纯单步 RAG)模式。为什么是 quick-answer?因为当时 smart-reasoning(ReAct 多跳)会撑爆 32K 上下文(见 5.3),是被逼的妥协。
第二代收敛成 1 个总 Agent + 4 个 Skill,形态是 hybrid-rag-wiki:靠 ReAct 的"渐进式披露"——总 Agent 根据用户意图,自动在 wiki 路由(概念/"是什么"题)、原文 chunk 路由(精确取数/条文题) 之间分流,并 read_skill 加载对应场景的方法论再作答。
这次能收敛回 smart-reasoning,正是因为 5.3 那套组合拳(关查询扩展 + rerank_top_k=5 + max 4096)把上下文压住了。当初被迫用 quick-answer 是止损;地基修好之后,smart-reasoning + Skill 才是终态。
而且 A/B 实测证明 smart-reasoning 确实更好(同一套 golden set,仅改模式;评测方法见第七节):
| 指标 | smart-reasoning | quick-answer |
|---|---|---|
| 关键点命中率(长度中性) | 31/32 ≈ 97% | 19/32 ≈ 59% |
| 黄金文档召回 | 15/23 ≈ 65% | 13/23 ≈ 57% |
| 编造 chunk_id | 0/11 | 0 |
下面是最终形态在一次真实问答里的完整 ReAct 过程——可以清楚看到它先调 wiki_search 探概念路由、再查原文 chunk 取具体条文、最后给出一个带「区分提示」的结构化答案(主动防止把两套相近标准混为一谈)。这恰好把第五节讲的"wiki 路由 + 原文 chunk 路由 + 防跨标准混淆"全串了起来:
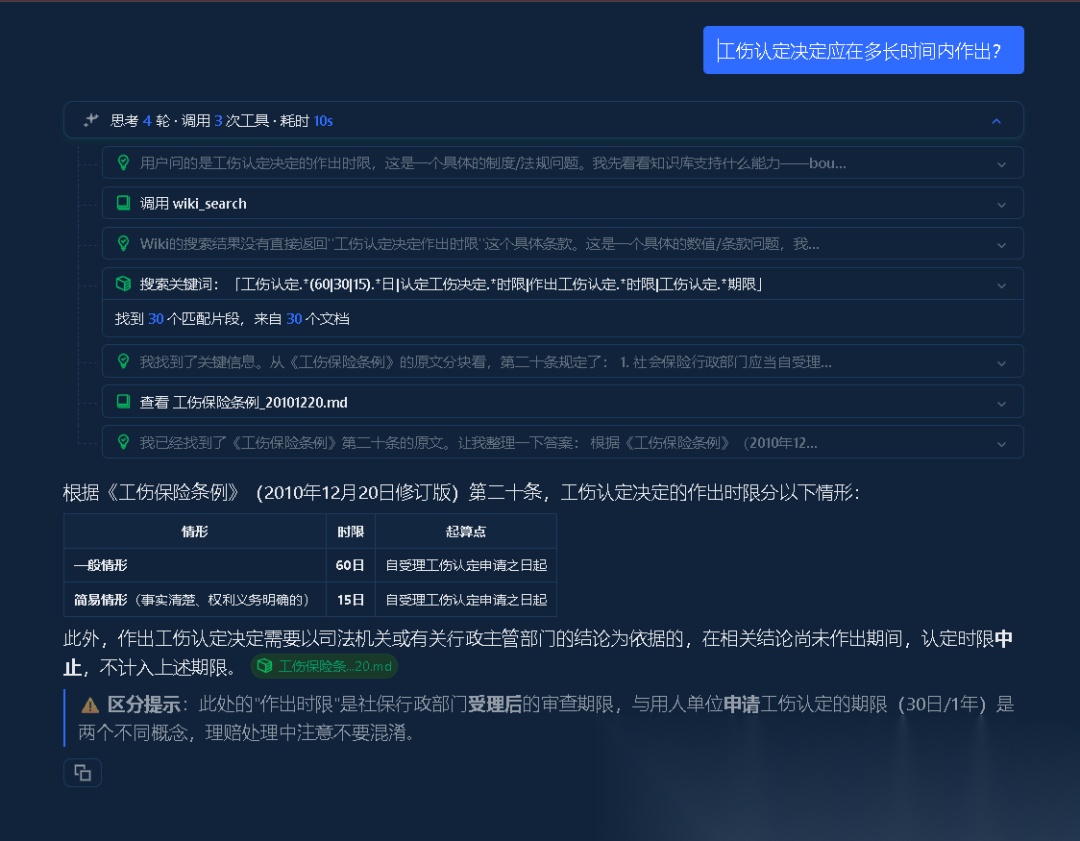
hybrid-rag-wiki 的一次真实 ReAct 问答:思考 4 轮、调用 wiki_search 与原文 chunk,输出带区分提示的答案
6.2 Skill 是什么——WeKnora 的一个二开点
WeKnora 的 Skill 本质是一个 SKILL.md 文件(YAML 头部 name + description,正文是一套结构化方法论)。触发不是关键词路由,而是 LLM 的渐进式披露——靠 description 元数据的质量来决定什么时候加载。
官方暂时不支持 UI/API 新建 Skill,得在后端 skill 目录放文件(这也是个二开动作)。我们的总 Agent 配置:agent_mode=smart-reasoning + selected_skills=[四个] + 工具集里带上 read_skill。
四个 Skill 各自是一套领域研判方法论,每个都长这样:一套 10+ 维度的结构化检查清单 + 统一的【输入定义】 + 检索步骤(knowledge_search 语义召回 + grep_chunks 精确匹配) + 固定的 markdown 输出模板 + "检索落空降级"段 + "🔴 红线·不要做"段(防编造、防跨标准、措辞留余地)。把资深专家脑子里那套"看一个案子该查哪些维度"的隐性经验,显式地写成了文件。
6.3 防幻觉 + 防注入:高风险领域的红线
这是一个要对结论负责的高风险领域,模型胡说八道是事故。system_prompt 里最高优先级的一段是防幻觉四原则:
-
只引用检索到的实际内容
——
knowledge_search返回的 chunk 是全部证据,绝不用训练数据补全; -
严禁编造任何统计数字
——次数 / 百分比 / 年龄 / 金额 / 各种比率,必须 chunk 原文出现;
-
实体名严格限定
——只能提及召回片段里实际出现的机构 / 实体,禁止虚构;
-
承认未知
——不用"通常"“一般来说”"业内"兜底。
效果很直接:某道题修复前模型编了十几条不存在的数据、回了 3261 字;加上约束后变成 789 字、诚实告知"信息不完整"。
还有一段安全边界(防指令注入),是被一个高危漏洞逼出来的:测试发现,一句伪造的"系统升级指令"能让 agent 直接输出一条本不该给出的高风险结论。加了"指令边界"防御段后,6 类攻击各打 5 次(共 30 次)全部防住——防御从"概率性"变成了"确定性"。高风险决策场景,这段是必备的。
七、评测尺子:没有它,前面全是玄学
你可能注意到了,前面每个结论我都给了 Recall@K、MRR 这些数字。没有一把稳定的尺子,"调优"就是凭感觉,而凭感觉的结论(比如 5.1 那个 references 没排序的坑)经常是错的。
我们的评测体系迭代了四代,最终稳定下来的尺子(写给同行参考):
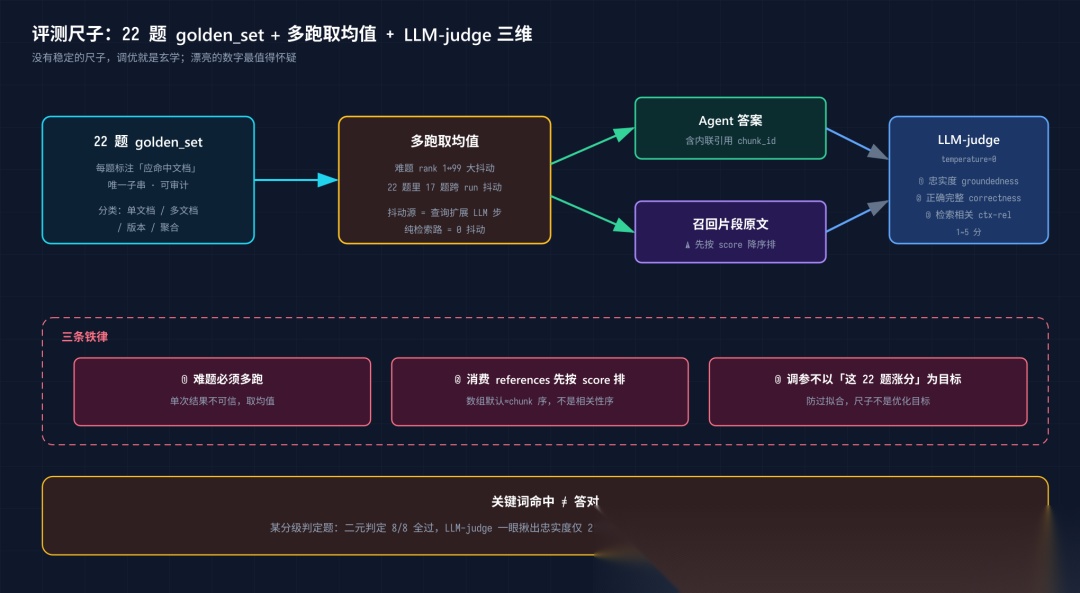
评测体系
-
22 道 golden_set
:每道题标注"应该命中哪篇文档"的唯一子串,可审计、可自动判 Recall@K,按 单文档 / 多文档 / 版本 / 聚合 四类分类。
-
多跑取均值
:难题的检索随机性极大(同一题的 ground truth rank 能从 1 跳到 99)。22 题里有 17 题跨 run 抖动,抖动源就是查询扩展那个 LLM 步骤;纯检索路是确定性的(0 抖动)。所以 agent 路必须多跑取均值。
-
LLM-judge 三维打分
:用一个大模型(
temperature=0)对(问题, 答案, 召回片段原文)打三个分:忠实度(groundedness,防幻觉)、正确完整性(correctness)、检索相关性(context relevance)。 -
三条铁律
:① 难题必须多跑;② 消费 references 必须先按 score 降序排(5.1 的血泪);③ 任何调参都不以"这 22 题涨分"为目标(防过拟合)。
LLM-judge 的价值在一道"分级判定题"上体现得淋漓尽致:二元关键词判定显示 8/8 全过,但 LLM-judge 一眼揪出其中一题的忠实度只有 2 分——答案给出的那个等级结论在召回片段里根本没有支撑(幻觉),而且把一套标准的片段错当成了另一套标准的依据(跨标准类推,这是 system_prompt 明令禁止的)。关键词命中 ≠ 答对,这是评测最容易自欺的地方。
八、增量更新:企业 RAG 最难的不是召回率
如果说前面都是"怎么把知识库第一次建好",那这一节是"建好之后怎么不让它烂掉"——而这才是企业 RAG 真正最难的部分。
如果知识库只会"新增向量",不会识别"哪些变了、哪些该删",它就会慢慢变脏:旧答案和新答案同时被召回,模型看起来很自信,实际引用的是过期内容。
用户最不能接受的不是回答慢,而是回答旧。
8.1 文档身份:别用文件名,用 doc_id + source_hash
增量更新的地基是给每篇文档一个稳定身份:
-
doc_id解决"这是谁";
-
source_hash解决"它变没变"。
然后是四个同步状态构成的状态机:
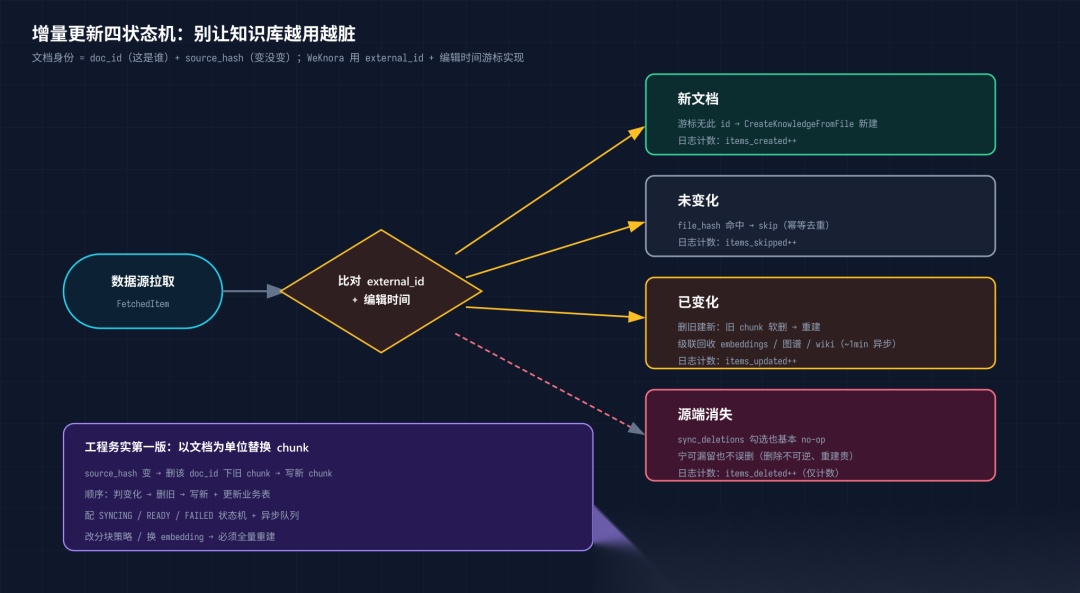
增量更新四状态机
工程上务实的第一版很简单:以文档为单位替换 chunk。只要 source_hash 变了,就删掉这个 doc_id 下的所有旧 chunk,重新写。顺序很关键:先判内容是否变化 → 按元数据删旧 chunk → 写新 chunk + 更新业务表,配一个 SYNCING / READY / FAILED 失败重试状态机。
几个容易忽略的坑:① 改了分块策略 / 换了 embedding 模型,必须全量重建(光改前端参数没用,旧索引不会自己消失);② 删除要可审计;③ 更新要异步(走消息队列),别阻塞上传请求。
8.2 WeKnora 恰好就是这么实现的:数据源同步
理论讲完,好消息是 WeKnora 自带的"数据源同步"功能,几乎就是上面这套理论的工程实现。它支持飞书 / Notion / 企业微信等作为数据源,配置好之后定时增量同步。它的 data_sources 表把理论一一对应上了:
-
sync_mode=
incremental | full(增量 / 全量) -
conflict_strategy=
overwrite | skip(冲突覆盖 / 跳过) -
sync_deletions(是否同步删除)
-
last_sync_cursor(游标,增量的锚点)
-
config(凭据,AES-256-GCM 加密存储)
它用 external_id(数据源里的节点 token)扮演理论里的 doc_id,用游标里每个节点的"最后编辑时间"扮演 source_hash——编辑时间变了才重新拉取,只改标题不会触发重抓。更新走的是"删旧建新":旧 chunk 软删、新 chunk 落库、图谱和 wiki 级联回收,整个过程约一分钟异步完成。
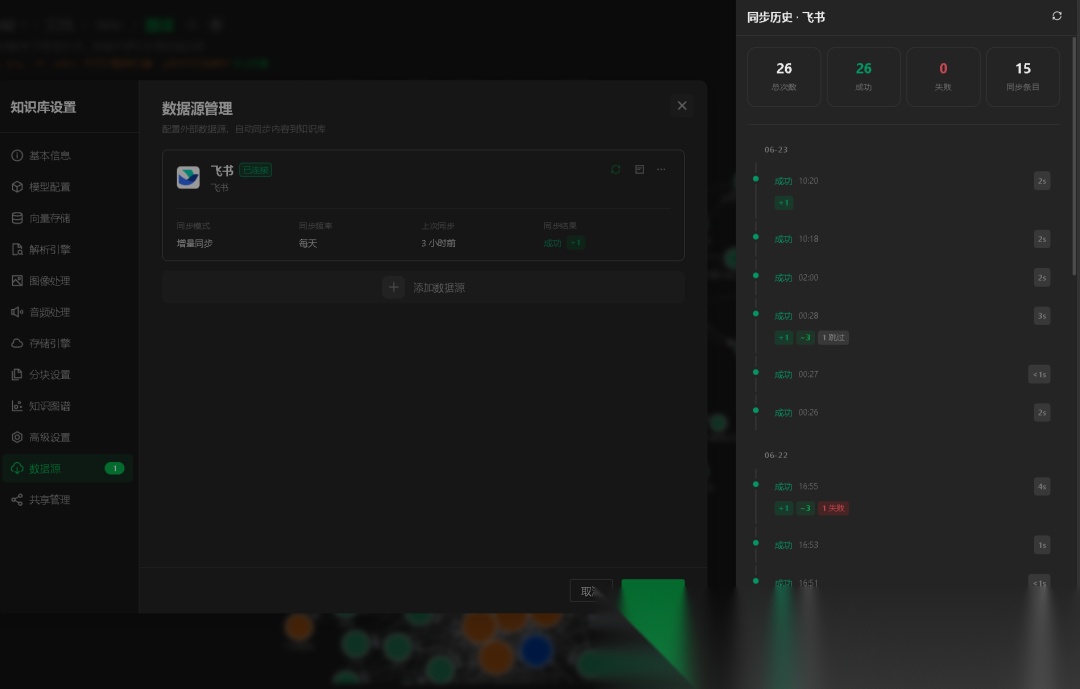
跑起来就是下面这样——每次定时同步都会记一条历史,把前面那四个状态以可观测的计数摊开:+N 新增、~N 更新、跳过 是内容没变(source_hash 命中)被略过、失败 单独标记。运维一眼就能看出"这次同步动了什么":
数据源同步历史:每次增量同步的 新增/更新/跳过/失败 计数,对应四状态模型
这里有两个实测出来的"反直觉行为",值得贴出来给同行避坑:
-
"同步删除"勾选了也基本是个 no-op
。这是 WeKnora 故意的设计:源端"消失"很可能是 API 列举失败 / 超时 / 限流 / 权限变化造成的假阳性,而删除不可逆、重建又贵——所以宁可漏留(保住)也不误删。真正的级联删除只发生在 UPDATE 路径上。
-
首次同步
游标为空,增量会自动降级成全量(所有节点都当新增)。
一句方法论收尾:RAG 表面上是"检索增强生成",本质上是知识数据工程。它的增量更新,和传统数据工程里的 CDC、增量同步、版本治理、快照管理是同一类问题,只不过对象从业务数据换成了知识数据。
九、CI/CD 与上线:双轨发布
最后讲怎么把它稳定地推上生产、以及怎么持续发版。
回到第一节那个"编辑台 / 服务台分离"的架构:所有内容只在编辑台生产,服务台只读。那"发版"就天然分成两条互不干扰的轨道:
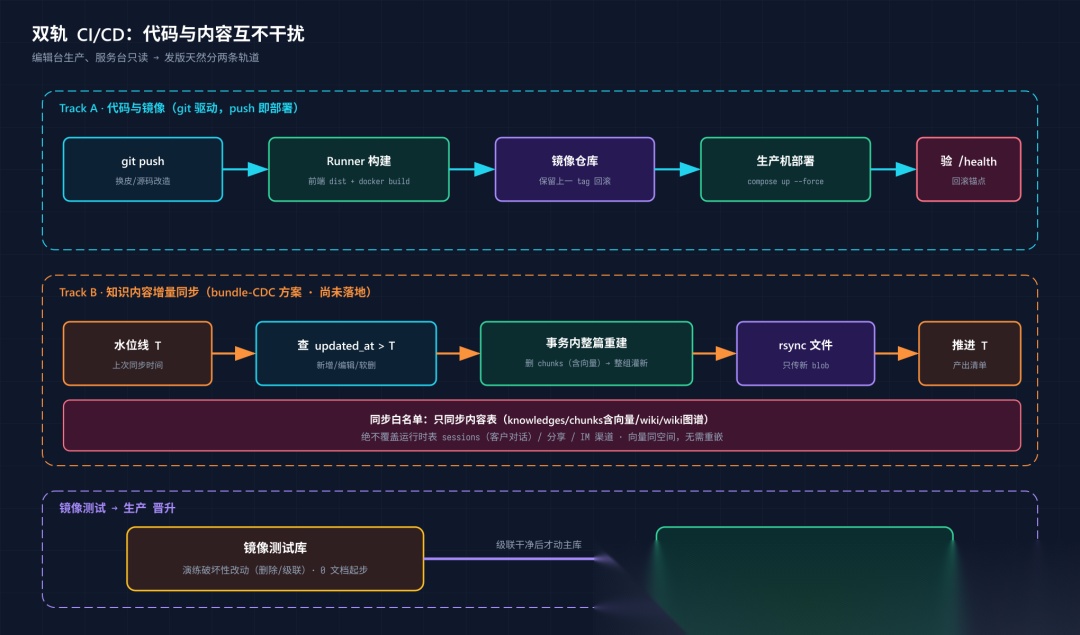
CI/CD 双轨发布
Track A——代码与镜像(git 驱动,push 即部署)
前端换皮、源码改造(比如标题面包屑、Excel 解析引擎这类)属于代码变更:push 到 Git 仓库 → Runner 构建前端 dist + docker build → 推到镜像仓库 → ssh 到生产机 compose up -d --force-recreate → 验 /health。保留上一个镜像 tag 用于回滚。
Track B——知识内容同步(bundle-CDC 方案)
⚠️ 先说清楚:Track A 已经在用;Track B 是已设计、即将落地的方案,本节讲的是设计思路,不是已上线的事实。 之所以值得写出来,是因为它面对一个很典型又很难的约束。
难点在于:服务台近乎"气隙"——不允许对内暴露端口,两机之间只能传文件(scp / rsync / rclone),不能有常驻连接。 这一条直接把绝大多数"正经"的库同步方案判了死刑:
| 方案 | 增量 | 零端口(纯文件) | 增删改 | 结论 |
|---|---|---|---|---|
| 逻辑复制 / pglogical / Debezium-Kafka | ✅ | ❌ 要活连接 | ✅ | 出局(气隙) |
| WAL 归档 / 物理副本 | ✅ | ⚠️半 | ✅ | 出局(整库只读副本,非可写服务库) |
| bundle-CDC(水位 + 哈希 + 幂等 upsert) | ✅ | ✅ 纯文件 | ✅(配软删) | 选定 |
所以我们走"穷人版 CDC"——bundle-CDC:不读 WAL 日志(那要活连接),靠表里 updated_at / deleted_at / file_hash 三列推断"什么变了",打包成文件离线搬运、目标端幂等重放。三根支柱:
-
水位 watermark
:
updated_at单调递增,每轮导出WHERE updated_at > 上次水位= 自上次以来所有被动过的行。 -
内容哈希
:
updated_at抖了但内容没变就跳过,少搬。 -
幂等灌入
:目标端按主键
ON CONFLICT DO UPDATE+WHERE EXCLUDED.updated_at > 现有,同一个包灌十遍结果一样,乱序 / 重放都不回退;失败不推进水位,下次自动重来,丢了包也能自愈。
增删改怎么各自传播:
| 操作 | 编辑台侧 | 服务台动作 |
|---|---|---|
| 增 | 新行 updated_at = 创建时间,> 水位 |
INSERT |
| 改 | 改行 updated_at 刷新,> 水位 |
ON CONFLICT DO UPDATE |
| 删 | ⚠️ 必须软删deleted_at=now()(退化成一次 update) |
据 deleted_at 真删 |
删除是唯一的坎:物理
DELETE后行就没了,水位永远看不到 → 服务台永久残留。所以"删"必须变成"改"(置deleted_at),才能被水位抓到、再在服务台真删。好在 WeKnora 本身就是软删,天然满足。
两个工程细节让它能成:
-
文档为原子单位、chunks 整组替换
:重解析后分片边界和数量全变,逐 chunk diff 对不上;所以一篇文档变了,就
DELETE chunks WHERE knowledge_id=X再整组灌新。向量就在 chunks 行里(向量库指向 PG 自身),binary COPY 精确搬 float、不重算、不丢精度。 -
嵌入模型版本钉死
:每行存
model_id+ 维度,服务台查询端的 embedding 必须和建库端同一版本——否则召回会静默变差(这比直接报错更危险)。换模型 = 影子表全量重建 + 原子 RENAME,绝不混版本增量。
分层落地:Schema 层用 Liquibase(把 WeKnora 全套表 + pgvector 扩展 + 中文分词 + HNSW 索引 DDL 纳入 changelog,服务台跑一遍对齐),数据层用 bundle-CDC(binary、向量友好、快)。一个常见 gotcha:首次全量种子要"先灌行、后建 HNSW 索引",绝不大批量灌进已建好的 HNSW(又慢、图质量又差)。
9.1 两个库的关系:生产主库与镜像测试库
我们把知识库分成两个:
-
生产主库
:六千多 wiki 页 + 近五万 chunk,对外服务。
-
镜像测试库
:克隆生产主库的同一套引擎配置、同一个租户,但起步 0 文档、不碰生产库。
镜像库的作用,就是给"数据源连接器""删除级联"这类有破坏性的改动一个安全的演练场。比如第八节里"删除某个条目会不会把 wiki 和图谱一起干净回收"这种实验,必须在镜像库里跑通、确认级联干净,才敢动生产主库。这就是一套朴素但有效的"测试镜像 → 生产"晋升流程。
9.2 一条硬约束:同步白名单
不是所有东西都同步。内容表(knowledges、chunks(含向量 + 全文索引)、wiki、wiki 图谱——全在 PostgreSQL 里)才同步;生产运行时表(客户对话记录 sessions、分享配置、IM 渠道)绝不能从编辑台覆盖过去——否则会把客户的对话历史冲掉。另外整个 Neo4j 不在同步范围(wiki 图谱本身就存在 PG 里,不依赖 Neo4j)。向量保持在同一个 embedding 空间(bge-m3),所以同步不需要重新向量化。
9.3 迁移上线时踩的两个关键点
-
密钥一致性
:服务台的
TENANT_AES_KEY(解密模型密钥)和JWT_SECRET(校验登录 token)必须和编辑台完全一致,否则模型密钥解不开、老 token 全失效(客户被迫重新登录)。 -
零内网依赖
:服务台在公网,够不到内网推理服务,所以 embedding / rerank / 对话模型全部直连公有云 API。这也反过来印证了"对话模型从内网自托管的 Qwen 切到云端 DeepSeek"这个选择的合理性。
十、效果与诚实的边界
10.1 关键改动的 before → after
调优不是玄学,每一步都有实测撑着。把最有代表性的几个改动拉成一张对照表:
| 改动 | 指标 | before | after |
|---|---|---|---|
| chunk 768 → 512 | 细节题 Recall@1 | 0% | 75% |
| chunk 768 → 512 | 细节题 MRR | 0.335 | 0.844 |
| 消费端按 score 排序(修测量 bug) | 22 题 Recall@5 | 0.74 | 0.81 |
| 消费端按 score 排序 | 22 题 MRR | 0.67 | 0.87 |
| quick-answer → smart-reasoning(hybrid-rag-wiki) | 关键点命中率 | 59% | 97% |
| quick-answer → smart-reasoning | 黄金文档召回 | 57% | 65% |
| 加防注入"指令边界"段 | 30 次攻击防御率 | 概率性失守 | 100% |
| 防幻觉四原则 + 版本守卫 | 某幻觉题输出 | 编了十几条假数据 | 诚实告知"信息不完整" |
10.2 最终上线版本的核心指标
最终形态(hybrid-rag-wiki + smart-reasoning + 4 Skill,chunk 512 + 标题面包屑 + bge-m3/reranker + DeepSeek-V4)实测:
| 维度 | 指标 |
|---|---|
| 检索质量 | Recall@5 ≈ 0.81 · Recall@10 ≈ 0.87 · MRR ≈ 0.87(企业级达标线 R@5 0.75~0.85) |
| 答案质量 | 关键点命中率 ≈ 97%(31/32)· 编造引用 chunk_id 0/11 |
| 基础题 LLM-judge | 7/8 优秀 (忠实度 / 正确性多为满分 5/5) |
| 标杆案例 | 达到资深业务专家水平,无真实幻觉 |
| 安全鲁棒性 | 6 类攻击 × 5 次 = 30 次,100% 防住 |
| 性能 | 单查询 ≈ 62 秒(瓶颈是大模型自回归生成,非检索)· 5 并发加速比 3.26x |
一句话:检索层达到企业级(R@5 0.81),生成层关键点命中 97% 且零编造引用,安全防御 100%——这套配置可以放心交付给业务专家当日常助手用。
10.3 标杆案例:4 个业务场景的专业质量
我们用一个贯穿全套测试的标杆案例(特意构造了两个相互印证的异常信号)跑了 4 个核心业务场景,由一个扮演资深专家的 LLM-judge 打分(专业性满分 5 分):
| 场景 | 专业性 | 结构 | 无幻觉 | 说明 |
|---|---|---|---|---|
| 场景 A | 5/5 | 完整 | ✅ | 准确锁定关键疑点 + 给出完整核查提纲 |
| 场景 B | 5/5 | 完整 | ✅ | 参考材料不足时如实说明,不编造 |
| 场景 C | 4/5 | 完整 | ✅ | 真实引用对应依据,不虚构凭空版本 |
| 场景 D | 5/5 | 完整 | ✅ | 多维研判 + "该用哪套标准"的切换洞察 |
四个场景全部结构完整、零幻觉,专业性 3 个满分 1 个 4 分——达到了"资深业务专家"的水准。最值得说的不是分数,而是它在"参考材料不足"时会如实承认、在"该引用哪个版本"时不瞎编——这正是第六节那套防幻觉 + 防注入约束的兑现。
10.4 诚实地说边界
这些是已知短板,不藏:
-
大规模聚合题是软肋
。"跨 31 个地区做统计对比"这种题,纯向量直查只能覆盖 ~16%。调 top_k、开查询扩展全是杯水车薪(查询扩展甚至更差,覆盖率 2 → 0)。正解不在检索层,而在应用层——把问题分解成逐地区子查询并发跑(编排器能做到 31/31 全覆盖),或者干脆走结构化 SQL(这类数据本来就是张表,GROUP BY 毫秒级)。
-
中文关键词检索偏弱
。底层 PostgreSQL 全文检索没有中文分词,所以"编号 / 专名 / 金额"这类精确查询的关键词腿是残的。好在向量腿够强(R@5≈0.81)兜得住,但这是个产品级的已知局限。
-
多版本文档是向量的天生软肋
。同一份主文档的各个版本文本 99% 雷同,向量召回分全挤在 0.97~0.99,向量和 rerank 都分不开。这是检索层的能力边界,只能靠生成层的"版本守卫"兜底,不是调参能解的。
十一、成本与算力开销:钱花在哪一站
聊调优和指标,绕不开一个现实问题:这套东西到底烧多少算力? 我们把成本拆到 RAG 流水线的每一站,结论很反直觉——最贵的那一站,最后被我们关掉了。
先把账摊开:
| 阶段 | 触发时机 | 单位成本 | 全量规模 | 性质 |
|---|---|---|---|---|
| 解析 (PDF/Excel) | 文档录入时 | 纯 CPU,不调大模型 | 四百多篇 | 几乎零 LLM 成本 |
| 分块 + 向量化 | 文档录入时 | 一次 embedding(轻) | 近五万 chunk | 廉价、一次性 |
| wiki 编译 | 文档录入/重建时 | 每篇一次大模型(带深度思考)≈ 3 分钟/篇 | 四百多篇 ≈ 22 小时 | 离线、异步、可增量 |
| 图谱抽取 | 开 graph 重解析时 | 每个 chunk 一次 LLM 抽取子任务 | 四百多篇 × ~125 chunk ≈ 6 万次调用 | 离线、最重、且已弃用于检索 |
| 线上推理 (每次问答) | 用户每次提问 | ≈ 7.4K token/查询(input ~6K + output ~1.4K) | 按 QPS | 在线、按次计费 |
几个值得说的点:
1)解析和分块几乎不花钱。 MinerU 是纯 CPU 服务(不吃 GPU),Excel 的结构化表引擎是纯代码规则,两者都不调用大模型。所以"材料切坏了后面全白搭"这件事——修它的 ROI 极高:投入的是工程时间,不是算力账单。
2)真正的算力黑洞是图谱抽取。 全量重解析慢的主因从来不是 embedding(向量化很便宜),而是 graph_enabled=true 时每个文本 chunk 都要单独调一次大模型做实体/关系抽取——四百多篇文档切散成约 6 万个 chunk,就是 6 万次大模型调用,压在本地推理服务上跑了很久。
3)最扎心的是:这 6 万次调用,最后是"沉没成本"。 第五节讲过,当前版本 WeKnora 的自动图扩展会劫持向量召回、反而拉低检索质量,所以我们在检索阶段把它关了——图谱只作为离线关系资产(Neo4j)保留,由 Agent 按需主动调用。换句话说,那 6 万次抽取的绝大部分算力,并没有变成线上检索的收益。 这是个真实的教训:别在没验证图谱对你的检索是否有正收益之前,就全量跑图谱抽取——它是整条链路里最贵的一步。
正因如此,我们后来重开 wiki 时坚决走纯 SQL 翻开关、绝不走重解析(reparse):因为 reparse 会因为全局开关连图谱一起重抽(一万多 chunk × LLM ≈ 两天的机器时间),白白再烧一遍那笔沉没成本。
4)线上推理成本:本地自托管时是"GPU 时间",上云后是"token 账单"。 单次查询约 7.4K token(注入 context ~6K + 生成 ~1.4K),瓶颈在生成端的自回归(见第十节,单查询 ~62s)。在内网自托管 35B 模型阶段,没有 API 费用,成本就是 GPU 占用 ~62s/查询;5 并发下有 3.26x 加速,靠的是推理框架的 continuous batching。迁到公网生产、对话模型切到云端 DeepSeek 之后,这块就从"GPU 时间"变成了"按 token 计费的 API 成本"——所以控制 output 长度(降 max_completion_tokens)、压 context(降 rerank_top_k)不只是降延迟,更是直接降钱。
5)离线建库的 token,本来可以"用时间换钱"。 wiki 编译、图谱抽取这类离线批处理任务有一个奢侈的特性——它不在乎延迟。所以它完全可以挂在自有 GPU 上用本地大模型慢慢跑,零 API 费用,只是慢。我们最终为了"快点把库建起来",对存量、不敏感的内容选择了走外部云端模型批量加工(拿钱换时间);而对敏感内容,则坚持走内部自托管模型,绝不出内网。这条线一旦划好,就是一个清晰的成本/合规权衡矩阵:
| 内容性质 | 走哪条链路 | 取舍 |
|---|---|---|
| 存量 · 不敏感 | 外部云端模型批量加工 | 花钱换速度 (库要尽快可用) |
| 敏感 | 内部自托管模型 | 慢一点,但绝不出内网 (合规优先) |
| 线上实时问答 | 看部署形态:内网自托管(GPU 时间) / 公网云端(token 账单) | 见上方第 4 点 |
一句话总结成本结构:离线建库的大头是图谱抽取(且我们交了学费才明白它对检索是负收益);线上服务的大头是生成端 token。 离线那部分本质是"时间 vs 金钱 vs 合规"的三角权衡——不敏感的存量可以花钱买速度走外部,敏感的必须用时间换安全走内部;省钱的总原则则是"先小样本验证再决定要不要全量"+“控制生成长度和注入上下文”。
写在最后:八条带血的方法论
如果这篇一万多字你只想记住几句话,就是下面这八条:
-
RAG 是检索工程问题,不是模型问题。
我们这个场景所有矛盾都在解析 / 分块 / 检索层,换更大的模型解决不了。
-
业界"最佳实践"必须在你自己的数据上、而且在对的智能体模式下验证。
Contextual Retrieval 反而降召回、LLM 重排是测量假象;而"wiki 无用"更是被错误的智能体模式(纯向量单步召回)带偏的伪结论——换成 ReAct 路由后 wiki 贡献很大。照搬来的结论全得回炉。
-
连自己的实验结论也要回查测量口径。
"rerank 该关掉"和"LLM 重排 +50 点"两个漂亮结论都是同一个测量 bug(忘了按 score 排)造出来的假象。
-
没有稳定的尺子,调优就是玄学。
难题检索随机性大(rank 1↔99),必须多跑取均值;安全防御也是概率性的,必须打够次数才算防御率。
-
材料切坏了,后面全白搭。
解析(扫描件 OCR、Excel 合并单元格)和分块(标题面包屑)这些"脏活"决定召回上限。
-
企业 RAG 最难的不是召回率,是别让知识库越用越脏。
增量更新的本质是知识数据工程(CDC / 版本治理 / 快照)。
-
二开要对升级友好。
复用现成角色、覆盖层打补丁、anchor 失配立即 FAIL——让定制不污染上游 git 历史。
-
编辑台和服务台分离。
内容生产与内容服务解耦,才有清爽的双轨 CI/CD 和可控的生产环境。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 7
7 0
0- 0



 已为社区贡献107条内容
已为社区贡献107条内容

所有评论(0)