机器学习-逻辑回归与KNN
一、逻辑回归
1)Logistic模型
逻辑回归是今经典的机器学习分类算法。广泛用于分类问题的统计学方法,特别是用于二分类问题。通过建立一个输入变量与输出类别之间的关系模型,来预测类别标签。尽管名为回归,但它实际上是一个分类算法,主要用于预测概率。

2)Logistic模型优势
(1)优势
简单易懂,易于解释:模型相对简单且易于实现,模型的解释性强,可以直接解释每个特征对于预测结果的影响。
计算效率高:数据量较小或特征维度较低情况下,逻辑回归计算效率高,训练速度快。
较少的参数调优:相比一些复杂模型,其对数据的要求较低,且训练过程中需要的调参较少。
不易过拟合:模型本身较简单,容易避免过拟合,尤其是当维度特征低时。
适用于线性决策边界:当数据特征之间的关系呈线性时,逻辑回归表现良好,尤其在一些简单的分类任务中非常有效。
(2)劣势
线性可分性限制:Logistic本质上是线性模型,对于非线性分布的数据表现较差。
特征工程依赖性强:需要对输入特征进行合理的选择和预处理。
无法处理大量类别特征:对于多分类或大类别的特征,需要改造模型或使用其他方法。
过拟合风险:在高维数据中,如果未进行正则化,模型容易过拟合。
3)R语言实现逻辑回归

二、KNN
K近邻法是一种比较成熟也是最简单的机器学习算法,可以用于基本的分类与回归方法。
基本思想:通过计算样本与训练数据集中所有样本的距离,选取距离最近的k个邻居,根据邻居的标签来进行预测。
基本形式:对于分类任务,选择K个邻居中出现最多的类别作为预测结果。对于回归任务,预测K个邻居的平均值作为预测结果。
1)Knn工作原理
Knn算法依赖于距离度量来判断样本的相似性。
距离度量对模型性能有较大影响,不同任务中选择不同的度量方法。
常见的距离度量方法:欧式,连续数值特征。曼哈顿,高维稀疏特征。闵可夫斯基距离:文本或向量表示。
2)Knn算法步骤
1*.计算距离。给定一个新样本,计算该样本与所有训练数据点的距离。
2*.选择K个最近邻居。按距离从小到大排序,选择前k个最近的样本。
3*.投票或平均。分类问题选择k个邻居中最多的类别作为预测结果。回归问题,计算k个邻居的平均值作为预测结果。
4*.输出结果。返回预测的类别标签或数值。
3)超参数k值的影响
1*.K值过小。问题:模型可能会过于敏感于噪声,容易出现拟合 即模型对训练数据拟合得过于紧密。
现象:模型可能会对每个数据点产生不同的预测,导致测试误差较大。
2*.K值过大。问题:模型可能会变得过于简单,忽略数据中的细节,从而导致欠拟和。
现象:模型对训练数据的适应性较差,且预测值受大范围邻居影响,可能会影响结果的准确性。
4)Knn优劣
优势:
简单直观:懒惰学习算法,即在训练阶段没有显著的学习过程,所有的训练数据都保留用于预测。
非参数模型:不需要显式的训练过程,没有复杂的参数需要调节(只有k值和距离度量方式),无需假设数据的分布。
适用于多类别问题:Knn可以自然地处理多类别分类问题。他在选择K个邻居时,会考虑所有类别适用于多类别的任务。
非线性决策边界:能够生成非线性的决策边界,因此对于数据的分布没有假设,可以灵活应对复杂的模式。
劣势:
计算开销大:基于实例的算法,在每次预测时都需要计算新样本与所有训练样本的距离。因此计算复杂度较高,在大规模数据集上预测过程可能变得非常慢。
对高维数据的表现差(维度灾难):在高维空间中,距离度量可能失去效果,导致knn的性能大幅下降。
对噪声敏感:容易受到训练数据中的噪声和异常值的影响,特别是当k值较小或数据不平衡时,噪声可能导致不准确的预测。
需要选择合适的k值:选择合适的配K值,对于k nn的表现至关重要,配置过小可能导致模型对噪声敏感。K值过大,可能使模型过于平滑,忽视局部的模式。
无法提供明确的模型解释:Knn是基于实例的算法,缺乏全局的数学表达式,解释性较差。
5)R语言实现

三、R语言实践
# 加载所需R包 ----
library(caret) # 机器学习建模与调参
library(rms) # 列线图绘制(regplot函数)
library(kknn) # 加权K近邻算法
library(ggplot2) # 数据可视化
library(regplot) #绘制列线图
#tlog <-read.csv("tlog.csv",row.names = 1)#此处tlog是数据转换与分割后的tlog,如果是接着数据转换与分割做的,就不需要导入。
#接着数据转换和分割做
# 定义筛选特征集合 ----
selected_vars <- c("exercise", "hyperlip", "pregnant",
"age", "glucose", "bmi", "pedigree") # 原始特征
selected_vars_scaled <- c("exercise", "hyperlip", "pregnant", "age_scaled",
"glucose_scaled", "bmi_scaled", "pedigree_scaled") # 标准化特征
# 将结局变量因子化 ----
tlog$diabetes <- factor(tlog$diabetes, levels = c(0,1), labels = c('No','Yes'))
valdata$diabetes <- factor(valdata$diabetes, levels = c(0,1), labels = c('No','Yes'))
### 注意: 构建模型时,自变量中的分类自变量没有因子化,原因是后续shap法无法识别因子变量
#################### 3. 二分类机器学习模型建模 ####################
###### 3.1 Logistic回归模型 #########
# 拟合模型
lr_model <- glm(
diabetes ~ exercise + hyperlip + pregnant + age + glucose + bmi + pedigree,
data = tlog,
family = binomial # 使用二项分布,适用于二分类因变量
)
# 显示模型信息
summary(lr_model)
## 绘制列线图
regplot(
lr_model,
title = "Logistic回归列线图",
points = TRUE, # 显示每个变量的点数贡献
axis.text.size = 12, # 调整刻度字体大小
title.text.size = 14 # 调整标题字体大小
)
######################## 3.2 KNN模型 ###########################
# 将结局变量因子化(3.1因子化过的不需要再因子化)
#tlog$diabetes <- factor(tlog$diabetes,levels = c(0,1),labels = c('No','Yes'))
# 基于默认参数,构建基础 knn 模型
knn_model0 <- train(diabetes ~ exercise + hyperlip + pregnant + age_scaled +
glucose_scaled + bmi_scaled + pedigree_scaled,
data = tlog,
method = "kknn" # 指定使用加权K近邻算法
)
# 设置交叉验证控制
train_control <- trainControl(method = "cv", number = 5)
# 设置超参数网格,核函数和 k 值
tune_grid<-expand.grid(kmax = seq(1, 20, by = 2), # 调整 k 值
distance = 2, # Minkowski距离,2表示欧几里得距离
kernel=c("rectangular","triangular","gaussian")) # 核函数,计算邻居的权重
# 训练 KNN 模型并调优
set.seed(123)
kknn_model <- train(diabetes ~ exercise + hyperlip + pregnant + age_scaled +
glucose_scaled + bmi_scaled + pedigree_scaled,
data = tlog,
method = "kknn",
trControl = train_control,
tuneGrid = tune_grid)
# 查看调参结果
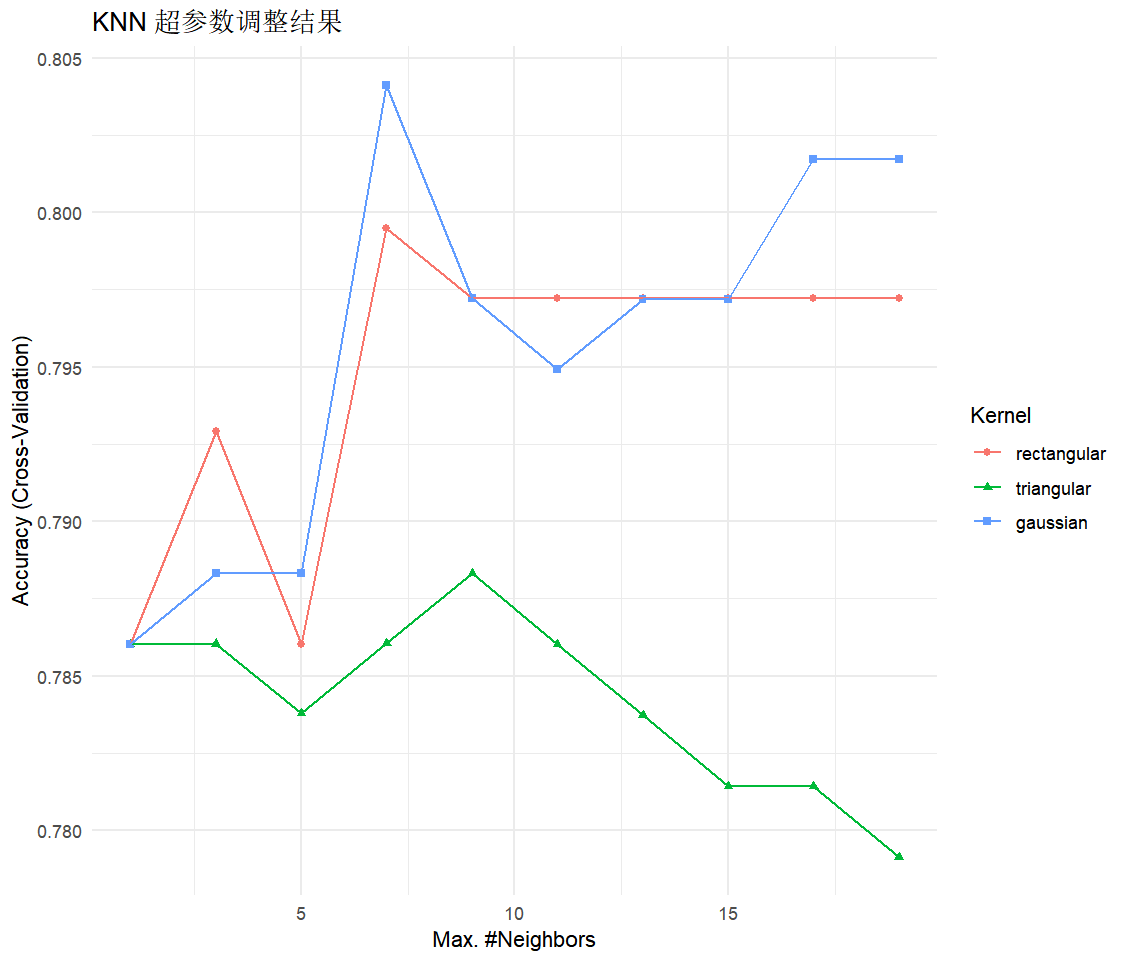
print(kknn_model)
# 提取最佳参数组合
best_params <- kknn_model$bestTune
print(best_params)
# 绘制可视化调参结果
ggplot(kknn_model) +
theme_minimal() +
ggtitle("KNN 超参数调整结果")
# 使用最佳参数构建最终模型
knn_model <- train(diabetes ~ exercise + hyperlip + pregnant + age_scaled +
glucose_scaled + bmi_scaled + pedigree_scaled,
data = tlog,
method = "kknn",
trControl = train_control,
tuneGrid = expand.grid(kmax = best_params$kmax,
distance = best_params$distance,
kernel = best_params$kernel))
# 查看最终模型
print(knn_model)
四、图片展示


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)