Spark+Hadoop+Hive 大数据 深度学习 机器学习基于机器学习的B站在线学习用户行为分析
前言
本课题旨在通过 Python 实现 B 站在线学习用户行为的分析与可视化,以帮助市场参与者深入了解用户行为特点和学习趋势,从而提供准确、全面的用户信息,辅助教育工作者和平台管理者做出明智的决策。研究主要分为数据采集与处理、数据分析与建模、数据可视化三个模块。
在数据采集与处理模块中,使用 Python 编程语言从 B 站爬取用户评论数据和课程信息,并对数据进行清洗和预处理,确保数据的准确性和完整性。通过合理的数据预处理,为后续的分析奠定了基础。在数据分析与建模模块中,对采集到的数据进行统计和分析,细分为用户行为分析、内容分析和情感分析。用户行为分析通过统计用户的评论数量和质量,评估用户的活跃度和参与度,识别高活跃用户和高质量评论。内容分析通过中文分词提取关键词和热门话题,生成词云图展示,并分析评论时间分布,识别用户在不同时间段的活跃情况。情感分析利用自然语言处理技术对评论进行情感倾向分析,计算正面、负面和中性评论的比例,为课程改进提供依据。在数据可视化模块中,将数据分析结果以图表、仪表盘等形式进行展示,直观地呈现用户行为和课程受欢迎程度的信息。使用 ECharts 或 Matplotlib 生成评论趋势图、用户活跃度分析图和情感分析结果展示。
通过本研究,成功揭示了B站在线学习用户的行为特点和趋势,为教育工作者和平台管理者提供了决策参考,并对未来可能的研究方向进行了展望。
一、项目介绍
开发语言:Python
python框架:Django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
开发软件:PyCharm/vs code
1、requests+DrissionPage 爬B站视频
2、pandas 数据去重清洗等
3、matplotlib 图表展示
4、sklearn机器学习:多元线性回归模型、随机森林模型
5、NLP自然语言处理分析评论情感状态
6、wordcloud 词云图
二、功能介绍
爬取数据,进行数据分析与可视化,然后进行数据挖掘,最后建立一个模型。
1、使用requests爬取B站课堂学习视频播放、分享、收藏等信息和用户评论信息、评论时间等
2、使用pandas对数据进行去重、清洗等预处理
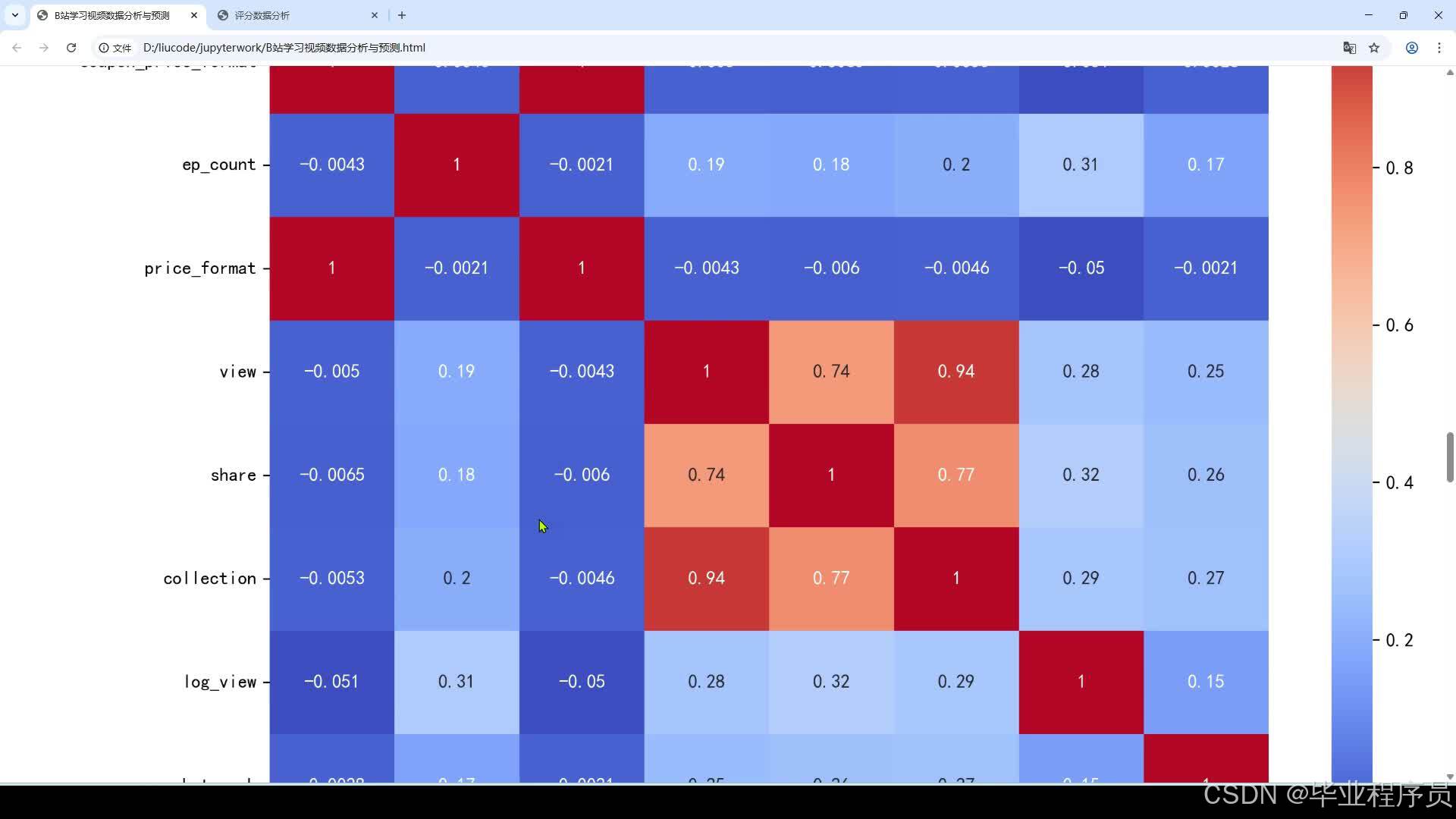
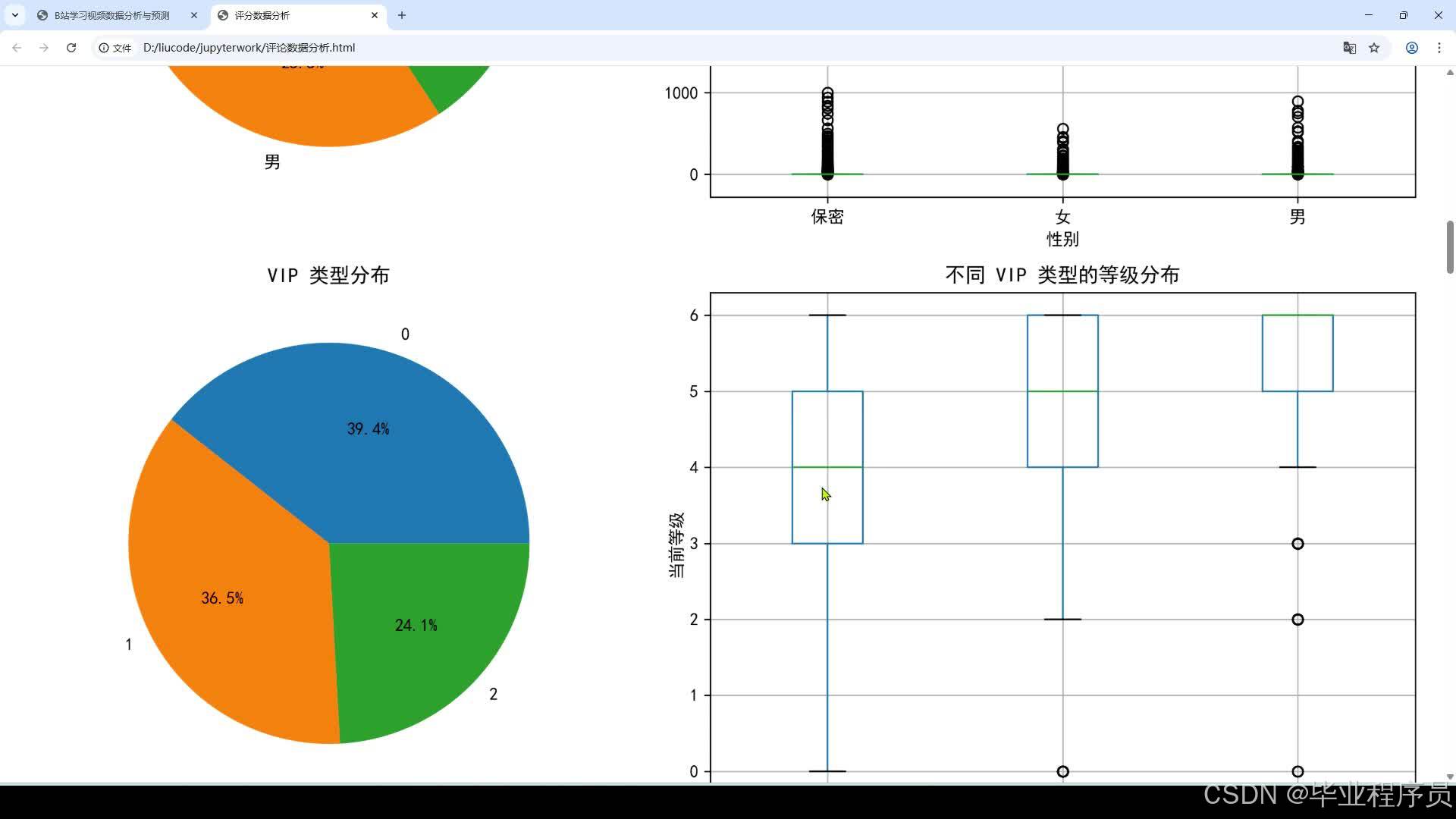
3、图表展示(播放数/收藏数/评论数等柱状图和饼状图展示,评论数和时间的折线图展示,各类型排名展示等)
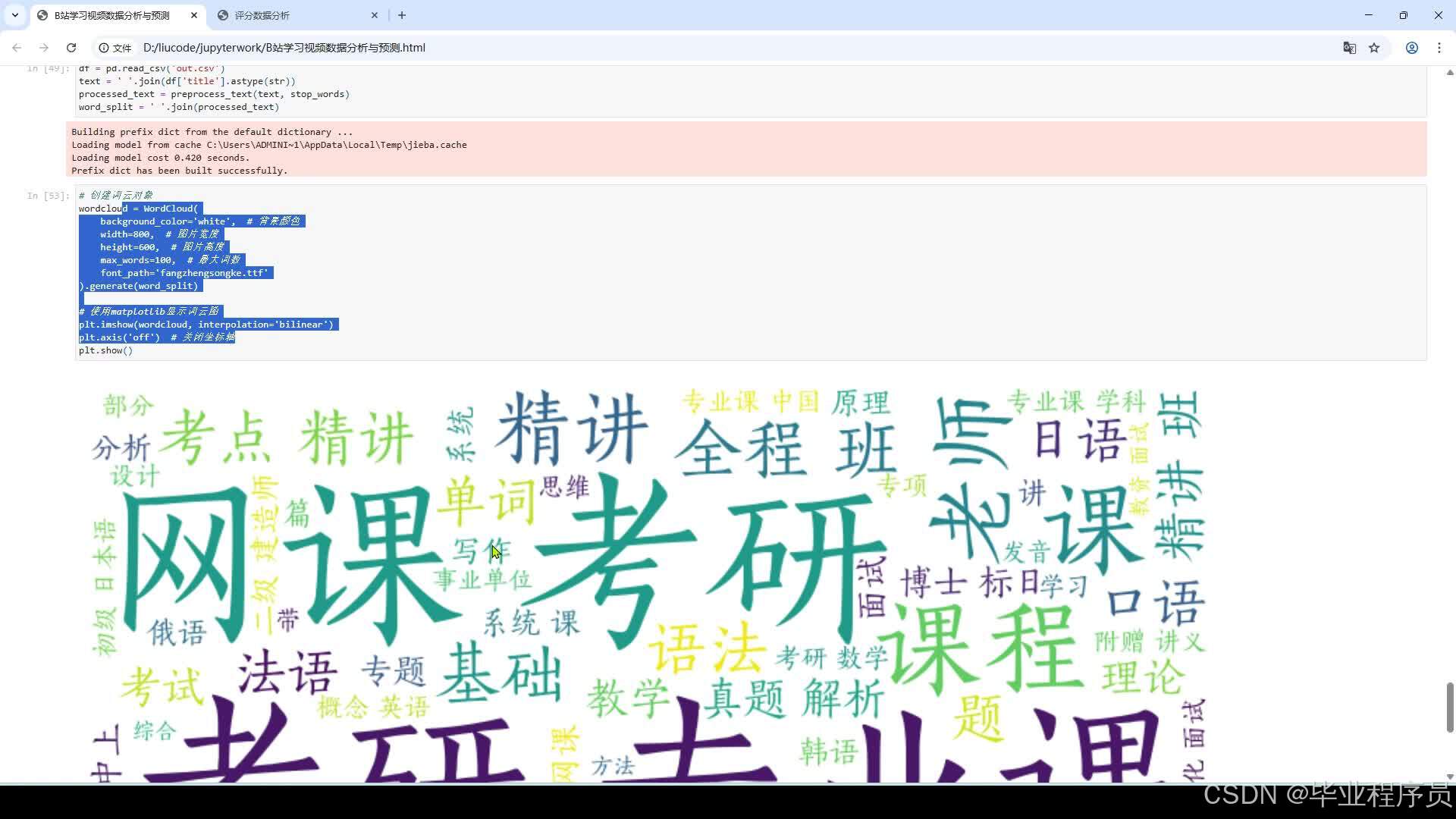
4、词云图展示(标题词云图和评论词云图)
5、分析评论数量、自然语言处理技术,对评论进行情感倾向分析及图表展示
6、使用随机森林模型对播放量预测
计算收藏数与播放数的比例、分享数与播放数的比例,评估视频内容对用户的吸引力和价值,高收藏率和分享率的视频通常具有较高的质量和独特性。分析评论数量、评论内容的情感倾
本课题旨在通过 Python 实现 B站 在线学习用户行为的分析与可视化,帮助市场参与者深入了解用户行为特点和学习趋势,以提供准确、全面的用户信息,辅助教育工作者和平台管理者做出明智的决策。
根据需求,本项课题研究主要分为数据采集与处理、数据分析与建模、数据可视化三个模块。
数据采集与处理:使用 Python 编程语言从 B站 爬取用户评论数据和课程信息,并对数据进行清洗和预处理,确保数据的准确性和完整性。
数据分析与建模: 对采集到的数据进行统计和分析,细分为用户行为分析、内容分析和情感分析。
(1)用户行为分析:分析评论行为,评估用户的活跃度和参与度。统计用户的评论数量和
质量,识别高活跃用户和高质量评论。
(2)内容分析:对评论内容进行中文分词,提取关键词和热门话题,生成词云图展示。进行评论时间分布分析,识别用户在不同时间段的活跃情况。
(3)情感分析:使用自然语言处理技术,对评论进行情感倾向分析,计算正面、负面和中
性评论的比例,为课程改进提供依据。
数据可视化
将数据分析结果以图表、仪表盘等形式进行展示,直观地呈现用户行为和课程受欢迎程度的信息。使用 ECharts 或 Matplotlib 生成评论趋势图、用户活跃度分析图和情感分析结果展示。
结果与展望
根据数据分析和可视化的结果,得到 B站 在线学习用户的行为特点和趋势,为教育工作者和平台管理者提供相应的决策参考,并对未来可能的研究方向进行展望。
三、核心代码
部分代码:
四、效果图

五、文章目录
五、文章目录
目 录
1 绪论 1
1.1 研究背景与意义 1
1.1.1 研究背景 1
1.1.2 研究意义 2
1.2 预计研究成果 2
1.3 主要研究内容 2
2 相关理论基础 4
2.1 机器学习 4
2.2 机器学习算法 4
2.2.1 随机森林 4
2.2.2 支持向量机 5
2.2.3 贝叶斯网络 6
2.3 模型评估 7
3 数据探索和分析处理 9
3.1 数据来源与预测目标 9
3.1.1 数据来源 9
3.1.2 预测目标 9
3.2 数据预处理 9
3.2.1 数据清洗 10
3.2.2 去停用词 10
3.2 数据探索和可视化分析 11
3.2.1 数据探索 11
3.2.2 性别分布 11
3.2.3 VIP类型分布 13
3.2.4 不同地区的评论数量分布 14
3.2.5 情感分析结果分布 17
4 构建预测模型 21
4.1 训练数据准备 21
4.2 基于随机森林的用户行为预测 21
4.2.1 参数设置与优化器选择 21
4.2.2 训练过程 22
4.3 实验结果 23
4.4 算法对比 26
4.5 模型的应用 26
5 结论 28
5.1 研究总结 28
5.2 研究展望 28
参考文献 30
致谢 32
附录 33
源码获取
源码获取
下方名片联系我即可!!
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 11
11 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)